
基于局部聚合描述符的视点不变视觉位置识别
2020-11-17 06:55:38刘靖
计算机工程与设计 2020年11期
刘 靖
(吉林大学 吉林吉大通信设计院股份有限公司,吉林 长春 130012)
0 引 言
视觉地点识别系统可用于识别机器人是否曾经访问过它当前的位置[1]。即使场所的外观发生变化,或从不同的角度观察场景,视觉识别(检测)系统[2]都应该能识别场景。随着智能机器人的快速发展,该方面的研究逐渐成为热门研究课题。
很多位置识别的研究着重关注视点不变性、条件不变性及效率。如Mactavish等[3]提出了在同一视角下利用记忆功能进行长时间的视觉定位方法。Liu等[4]设计了一种基于形状匹配的视觉定位算法,算法在速度和精度两个方面均达到与国外商业软件相当的水平,可部分替代商业软件使用。Yan等[5]提出的“视觉-词语”将特征空间量化成一组集群,由二进制串描述图像,将图像简化为二进制串匹配,匹配效率高。在保持高效性能的同时,还可以通过局部聚合描述符(vector of locally aggregated descriptor,VLAD)等技术来增强BOW模型的性能[6]。文献[7]中提出了农业机器人视觉定位方法,即:基于目标的颜色、形状和位置特征。Gao等[8]提出的FAB-MAP、文献[9]提出的 SeqSLAM 均采用图像过滤方法进行视点及条件不变的位置识别,但这类方法计算代价非常大。
与以上方法不同,本文提出了一个位置识别系统,将条件不变的特征和轻量级的图像描述机制结合起来,采用VLAD[10]向量。即使在外观和视点发生变化的情况下,也可以进行位置识别。但当每个位置分配的内存数量减少时,基于VLAD系统的性能就会下降。VLAD的计算效率类似于一个BOW模型,但所提VLAD系统在相同内存占用情况下,具有更高的性能。
1 本文方法
在变换的环境下,本文的目标是将用于视觉位置识别的鲁棒描述符与低内存要求和有特征量化的技术(如BOW和VLAD模型)相结合,以提供更快的图像匹配。由于VLAD模型已被证明性能优于BOW模型,所以本文选用VLAD。本文方法的基本流程如图1所示。

图1 本文方法的基本流程
1.1 特征检测
相比于其它特征检测算法,SURF算法的鲁棒性及检测出的特征的视点不变性较好,其稳键性高,效率也表现优秀[11],所以本文选用SURF算法检测特征。为了计算描述符,本文将每个关键点的感兴趣区域定义为大小为20s×20s 的区块,其中s是检测到的SURF关键点尺度。
1.2 特征描述
所选描述符采用梯度直方图[12](histogram of gradient,HoG),可以在变换的环境中有效识别特征,具有良好的鲁棒性和效率。
将由SURF算法选择的每个图像块分为N×N个单元,并使用水平 (1,0,1) 和垂直滤波器 ((1,0,1)T) 卷积计算每个点的梯度矢量,得到矢量的大小和方向。根据矢量的大小和方向,将每个梯度矢量添加到直方图区域,该直方图区域分为0°和180°之间的b个区段,则特征的维度为d=N2b。然后,本文使用主成分分析(principal component analysis,PCA)[13]和预先训练好的PCA基础降低所提特征的维度。
1.3 词袋模型
词袋模型使用余弦距离通过k均值聚类将HOG描述符的特征空间划分为k个视觉词。将每个描述符划分到特征空间内与其最接近的质心。这样,图像可以由长度为k的二进制串表示,当且仅当第j个视觉单词出现在图像中时,第j位是1。
1.4 局部聚合的描述符(VLAD)
类似于词袋模型,VLAD将每个特征划分到特定单词,词袋模型只包含该单词是否在图像中出现的二进制信息,但VLAD同时存储与位置有关单元的特征信息。如果可以在同一个单元格中找到多个特征,则VLAD将相对位置相加(或“聚合”)在一起。
具体来说,VLAD矢量v是子矢量v1,v2,…,vk的连接,每个子矢量代表一个特定的视觉单词。对于任何i≤k,与质心ci相关的子矢量vi定义为
(1)

1.5 降维处理
由于VLAD描述符的大小是d×k,其中d是特征维数,k是词袋模型中词的数量,所以VLAD描述符会变得非常大。因此,需对VLAD描述符进行降维处理。本文使用基于局部敏感散列[14](local sensitive hash,LSH)的数据降低维数,将特征随机投影到低维的二进制签名,该过程通过二进制签名之间的汉明距离近似保留原始向量之间的余弦相似度。
本文对每个单词使用相同的随机投影。这种简化操作减少了存储需求,但要求词汇表中的单词数量k必须小于一个因子B。投影平面的数量是p=B/k,每个描述符的维数为d。p平面P的值是从单位正态分布中随机抽取的。对于VLAD描述符v,二进制签名计算为
b=vTP≥0
(2)
其中,二进制签名b的大小为k×p,b的总比特数是B。
1.6 图像比较
本文通过计算二进制图像签名上的汉明距离实现图像比较。如果使用包含k个单词的BOW模型,则两个签名b1和b2的汉明距离为
(3)
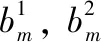
(4)
汉明距离H在b1到b2之间的距离为每个子向量的汉明距离之和
(5)
视觉位置相对于当前位置的最佳匹配位置,可定义为具有最小二进制签名的汉明距离所处的方位。
2 实验结果与分析
所提系统在Matlab2014b上实现,使用matlab平台内置的函数计算SURF关键点、PCA分解和HOG描述符。使用Yael库实现BOW和VLAD模型。在商用笔记本电脑上使用英特尔i7-4810MQ CPU的单核进行时序比较。
实验评估视觉位置识别系统对每个图像存储的信息量以及图像处理计算时间进行比较。将所提VLAD系统也与其它特征识别方法进行比较,即BOW、SeqSLAM、FAB-MAP和全特征匹配。
2.1 实验数据集
在5个公开的数据集上评估了可视位置识别系统,每个数据集包含两个或更多不同条件下的场景。图2给出了每个数据集的样本图像。Nordland数据集为不同季节从列车上得到的分辨率为640×360的图像组成,如图2(a)所示,实验中使用了Nordland数据集的250幅图像。Gardens Point数据集包含一条某大学校园的道路,路径之间有侧向视角变化,分为白天和黑夜获取的图片,如图2(b)所示。白天获得的图像使用双三次插值进行调整,生成分辨率为640×360的图像。SFU Mountain数据集为一条森林小径的图像,如图2(c)所示。该数据集包含239个在不同天气条件下和不同时段得到的图像。来自Mapillary图像共享服务[15]的分辨率为640×480的图像,包括汽车、自行车和巴士的顶部获得的图像,如图2(d)和图2(e)所示。数据集内的照明和天气条件也有所不同。

图2 实验数据集的样本图像
2.2 实验的训练阶段
所提系统对Nordland数据集的500张照片进行了训练,从中提取了441 538个特征。这些训练特征用于计算HOG描述符上初始降维的PCA基础,并通过k-means聚类为词袋生成词汇模型。所有测试数据集都使用相同的PCA基础和词汇模型,以确保系统是广泛通用的,且不需要对每个场景做特殊调整。
2.3 参数设置
实验参数见表1。特征检测算法和HOG描述符的参数保持不变,同时使用了特征尺寸、词汇量和VLAD签名长度的多个参数值,并给出了测试值的范围。在大多实验中,从每幅图像中提取300个特征,除了评估检测效率的实验,其余实验使用100和2000个特征。

表1 实验参数
2.4 图像签名
特征识别系统的一个关键要求是存储的描述符应该尽可能小,本文实验主要研究位置识别的性能如何与每个图像存储的信息量有关。BOW、FAB-MAP和所提VLAD的性能如图3所示,每个图像使用相同数量的比特。

图3 不同方法的正确匹配结果
对于大多数位长和数据集组合来说,本文VLAD的性能优于BOW和FAB-MAP。除了图3(e)中使用16 384比特,FAB-MAP的正确匹配为43%,VLAD的正确匹配为39%。然而,在其它数据集中,VLAD的正确匹配比FAB-MAP高出10%。当每个图像的位数很小时,BOW优于VLAD和FAB-MAP。但是,图像存储的位数增加时,BOW一直优于VAD和FAB-MAP的性能。
当图像存储比特增加时,BOW的性能并不总是提高,并且在4个数据集中,16 384比特的词汇比256比特差(如图3(a)、图3(c)、图3(d))。相关研究表明[16],BOW模型中的单词聚类必须足够大才能够捕获由于外观和视点变化引起的描述符变化,但不能太大,因为太大会导致太多不同的特征聚集在一起。因此,中等大小的单词聚类较为合适。相比之下,VLAD的性能一直与图像的位数有关。
最后比较了使用16 384位的VLAD与以未编码形式存储相同特征的版本性能。每个特征是1764个维度,每个图像存储300个特征,因此存储的总字节数为1764×300×4字节或每个图像大约2 MB的数据。结果显示:未编码特征的性能比Nordland(D-1数据集)数据集上的2048字节VLAD描述符大2.7倍。然而,对于每个全局特征图像,大约有1000个位置可以存储VLAD的16 384字节。根据系统要求,如果必须存储大量图像,可以使用更小的VLAD描述符。
2.5 计算时间
在理想的情况下,一个特征识别系统应该在计算效率和匹配方面均表现优秀。该过程可以分为两个独立的阶段:图像处理阶段和图像比较阶段。
2.5.1 图像处理
对于BOW以及完整的特性匹配,执行以下步骤:①在图像中检测关键点;②基于关键点提取描述符;③使用PCA减少描述符。对于VLAD模型,还需执行以下步骤:①每个描述符通过查找最近的相邻集群质心匹配一个可视化的单词;②计算每个描述符和集群质心之间的差异;③归一化向量;④计算二进制签名。
使用Nordland数据集(D-1)的29 000张图像进行基准测试实验。表2给出了16 384位BOW和本文VLAD的每幅图像的平均处理时间。

表2 图像处理时间
虽然需要额外的处理步骤,但VLAD的性能实际上比BOW更高。BOW模型使用更大的词汇表,当特征分配给视觉词时,最近的邻近计算取决于聚类的数量。在这种情况下,与VLAD的128词汇相比,BOW的大小为16 384的词汇导致计算速度较慢,这比后续的VLAD处理花费的时间还长。
然而,计算时间是由特征提取过程决定的,并且这个过程主要取决于每个图像提取的特征数量,如图4所示,一个需要较少特征的系统,其效率一般会更高。

图4 描述符的特征提取时间
总的来说,数量较多的特征并不一定能够为BOW或VLAD提供更好的性能。此外,BOW对参数的选择更加敏感。如果特征和词群之间的关系发生了变化,那么对于词汇的选择,BOW的敏感度会非常大,对VLAD的影响较小。
2.5.2 图像比较
BOW和VLAD的图像比较非常相似,两个系统都使用海明距离比较图像。表3给出了使用Nordland数据集(D-1数据集)图像进行10 000次图像比较的平均时间。这两种方法之间几乎没有时差。相比之下,直接特征匹配则要慢两个数量级。

表3 图像比较时间
虽然BOW和VLAD具有相似的计算时间,但BOW具有优势,因为它比VLAD更稀疏,BOW签名通常包含比VLAD签名更多的零。在Nordland数据集中,每个BOW签名的中位数为237,而VLAD的中位数为1216。这种稀疏性为其它更有效的比较方法应用于BOW提供了可能。但是,由于VLAD比BOW具有更好的特征识别性能,因此这种额外的效率是以牺牲整体性能为代价。
2.6 词汇量的选择
VLAD的一个重要参数是词汇量的选择。图5给出了不同比特长度的图像签名在性能和词汇大小之间的关系。在所有数据集上,表现最好的词汇大小取决于签名长度。当签名长度很小时,较小的词汇表现良好;对于每个数据集,只有8或16个字的词汇表在64位签名上表现最佳。如果使用大签名,则较大的词汇表现更好。但是,即使对于16 384位的签名,最大的词汇(4096个单词)也会被较小的64或256个词汇表超出。这些结果表明:小词汇比较大词汇更好,特别是非常紧凑的图像签名。

图5 不同比特长度的图像签名在性能和词汇大小间的关系
2.7 召回与精度的比较
另一个常用的评价系统性能的指标是精确和召回。召回和精确定义为
(6)
(7)
其中,TP为真正匹配的数目;FP是假匹配的数目;FN是假负匹配的数目。
图6(a)是对D-1数据集进行了完全精确的召回率,图6(b)给出了正确匹配的性能。精确的召回受到了比特数减少的严重影响,在2048位或更短的时间内,该数字快速下降甚至接近零。相比之下,较小图像签名正确匹配的百分比会较少,在2048位上保持在20%左右。当添加一个序列滤波器时,VLAD的表现如图6(c)所示,由图可知,对于1024位或更小的签名来说,很难达到召回百分之百的精度。这个结果表明,在执行滤波操作时,对图像签名长度的完全恢复比找到正确的匹配更敏感。

图6 本文VLAD在D-1数据集不同长度的表现
3 结束语
在位置识别中,即使外观环境发生变化,识别系统也可以从不同的角度进行视觉识别。与其它视点不变和条件不变的位置识别系统不同,本文系统在存储和计算方面都表现优秀。当存储每个图像256位时,性能降低缓慢,在所有数据集中正确匹配至少10%的位置,并且在每个图像存储64位时仍然在所有数据集中匹配5%正确的位置。VLAD的性能优于全特征匹配方法,且所需时间更短,相差约两个数量级。由于VLAD保留的本地位置信息允许系统区分同一词组中的不同特征,从而提高了性能并降低了对词汇选择的敏感度。
猜你喜欢
测绘学报(2022年12期)2022-02-13 09:13:01
中等数学(2021年8期)2021-11-22 07:53:38
阅读(快乐英语高年级)(2020年8期)2020-01-08 02:21:16
数学大王·低年级(2019年10期)2019-11-25 08:23:26
中等数学(2019年4期)2019-08-30 03:51:44
智慧少年·故事叮当(2018年11期)2018-05-14 11:48:18
数字通信世界(2018年1期)2018-04-18 11:05:22
意林(绘英语)(2017年5期)2017-05-15 02:17:23
测绘科学与工程(2017年5期)2017-05-07 06:30:44
合肥工业大学学报(自然科学版)(2011年2期)2011-03-15 14:30:26
