
基于校园无线网络的时空轨迹相似性度量
2020-11-17 06:54:42方敏佳刘漫丹
计算机工程与设计 2020年11期
方敏佳,刘漫丹
(华东理工大学 信息科学与工程学院,上海 200237)
0 引 言
目前,全国各大高校正相继推进校园信息化建设,实现了校园无线网络全覆盖,为学生在校园区域内上网提供了便利[1-3]。校园无线网络不仅记录下了学生的大量上网数据,还通过无线网络接入点的位置实时反映出了学生的位置信息,这为开展以校园无线网络为背景的时空轨迹挖掘工作提供了可能。
针对时空轨迹挖掘的研究内容主要包括轨迹聚类、轨迹分类、频繁序列分析、轨迹模式挖掘、轨迹数据可视化等方面[4]。轨迹相似性计算是进行各类时空轨迹挖掘研究的基础工作,相似性计算结果的准确性将会对后续挖掘工作产生极大影响,因此根据不同轨迹特点和应用场景选择合适的相似性度量模型显得尤为重要。目前的时空轨迹相似性度量研究大多是基于全球定位系统(global positioning system,GPS)获得的时空轨迹数据,轨迹点之间时间间隔稳定,地理位置信息详细。然而,校园无线网络中的时空轨迹数据是通过用户登录无线网络接入点(access point,AP)获得的,轨迹数据具有时间间隔不稳定、地理位置信息重复冗余等特点。因此目前已有的轨迹相似性度量方法并不能很好适用于该场景。此外,目前已有的相关研究中,通常只关注了时空轨迹时间或者空间某一方面数据特征信息,或者只是将另一方面的数据作为约束条件,并没有将两者很好地进行结合。针对以上问题,本文提出了一种基于最短时间距离子序列的时空轨迹相似性度量模型。该模型同时考虑了时空轨迹的时间相似性和空间相似性,以建筑物编号表示轨迹点地理位置信息,在空间相似性度量模型中引入连续因子以强化轨迹序列特征,消除冗余轨迹数据带来的影响。另外,在计算过程中利用并行时间滑动时间窗对用户轨迹进行划分以提高计算效率。
1 相关工作
经典轨迹相似性度量方法通常利用位置距离来表征轨迹相似性,例如欧氏距离(Euclidean distance)、动态时间规整(dynamic time warping,DTW)、编辑距离(edit distance,ED)、弗雷歇距离度量(Fréchet distance)、豪斯多夫距离(Hausdorff distance)等[5]。最长公共子序列(longest common subsequences,LCSS)也是一种研究者常用的经典轨迹相似性度量方法,该方法是从轨迹序列的角度分析轨迹相似性。基于经典轨迹相似性度量方法,研究者们开展了大量相关改进工作。王培等[6]针对经典Hausdorff距离容易受空间目标局部分布影响的缺陷,在进行时空轨迹相似性度量时改为求单位时间内最大最小距离的平均值距离;张晓滨等[7]则为Hausdorff距离引入时间约束,以弥补只着重关注于位置信息的不足。Zheng Zhang等[8]通过限制两条轨迹点的连接总数以减少传统DTW方法中产生的不合理连接,提高算法鲁棒性。
由于时空轨迹数据的来源非常广泛,轨迹相似性度量方法需要根据应用场景和轨迹数据的自身特点进行优化调整。王雅楠等[9]结合空间、时间、位置语义的影响将相似性转化为位置语义关系的计算,提出了一种适用于室内的轨迹相似性度量方法。Mei Yeen Choong等[10]结合k均值和模糊c均值(FCM)聚类算法,并基于LCSS的相似度函数进行车辆流量分析。Mengke Yang等[11]提出了一个基于长期轨迹数据挖掘个体相似性的框架,在计算相似性时结合了个体访问重要地点的时空和语义属性。为了减少海量车辆数据的计算量,裴剑等[12]运用Ramer-Douglas-Peucker算法先对单条轨迹进行轮廓抽取,并在此基础上提出基于LCSS的轨迹相似性算法。周永[13]基于社交网络的签到数据对用户的签到兴趣点进行不同尺度和维度的划分,然后采用类似包围盒的思想进行相似度的计算。
无线网络也是轨迹相似性的重要数据来源和应用场景之一。利用无线网络获取的时空轨迹数据具有鲜明的数据特点,移动对象通常会位于某一限定区域,例如大型室内场所、学校、社区等,可以较稳定的反映出移动对象在一段较长时间内的周期性行为记录和行为偏好,缺点是轨迹数据量大、噪声干扰信息多、空间范围小。另外与利用GPS获取时空轨迹数据不同的是,无线网络并无法准确获取移动对象的实时地理位置信息,而是利用移动对象连接某个AP点从侧面反映出其位置信息。因此,上文中利用GPS获取轨迹点具体地理位置信息(经纬度)和地理轨迹图形进行轨迹相似性度量的方法并无法在无线网络数据场景下直接使用。针对上述问题,赵振邦[14]通过构建层次图来为每个用户的历史轨迹建模,将用户轨迹映射为层次图的一个子图,通过比较不同子图之间的相似性进行相似性度量。Fengzi Wang等[15]基于LCSS的思想结合轨迹点语义特征提出语义轨迹相似度量算法,并用于社会关系挖掘。Bonan Wang[16]建立基于地点相遇时间的决策树模型,计算出地点的相似性以得到用户间的相似性。但是上述这些方法仅仅是关注了轨迹时间或者空间某一方面数据特征信息,并没有将两者很好地进行结合。
在充分分析基于校园无线网络的时空轨迹数据特点后,本文建立综合时间序列与空间信息的轨迹相似性度量模型。时间序列方面,改进了文献[17]中的基于DTW思想的相遇时间距离模型,优化时间距离参数;从空间信息角度,提出了最短时间距离公共子序列的概念,在传统LCSS法的基础上利用最短时间距离剔除冗余数据,最大可能保留利用空间信息特征。在计算时参考文献[18]中轨迹连续性的表达方式引入连续因子,以体现连续性特征对轨迹空间位置信息的影响。针对轨迹序列数据多、时间跨度大的特点,本文进一步利用并行滑动时间窗口对轨迹进行划分,大大提高了轨迹相似性度量的计算速度。此外,本文提出的方法可以得出轨迹之间相似性的量化结果,从而反映出用户之间的相似性度量结果,拥有具体的量化数据结果更利于后续进行社区发现、用户关系挖掘等用户行为研究。
2 用户时空轨迹提取
用户在使用移动设备时会主动或被动地记录大量历史位置信息,将信息进行提取便形成时空轨迹。时空轨迹是一条位于多维空间的曲线,由一系列时空轨迹点构成,代表了用户在时空环境下的个体移动过程和行为历史。每个时空轨迹点均包含空间位置信息和时间信息,此外还可能包含移动方向、移动速度、连接设备以及用户的各类社会交互信息[19]。基于无线网络的时空轨迹序列是用户利用各类移动设备登录AP点产生的。假设某用户在校园中的真实移动路径如图1中所示,则该用户的移动设备连接行为会在无线网络中留下时空序列R
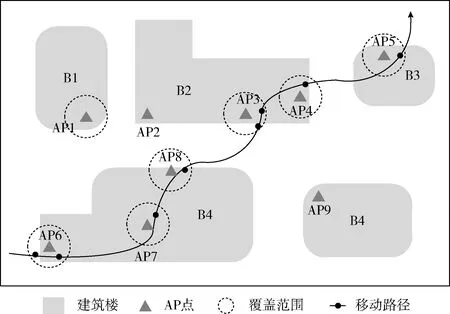
图1 基于校园无线网络的时空轨迹序列生成过程
R∶{(AP6,t1),(AP6,t2),(AP7,t3),(AP8,t4), (AP3,t5),(AP3,t6),(AP4,t7),(AP5,t8)}
其中,t1,t2,…,t8是连接行为发生的时间。
无线网络的AP点一般均安装部署在建筑楼内,可以将AP点与建筑楼进行关联映射。建筑楼一般具有功能型的语义信息,能够为轨迹分析带来更多的特征信息,提高人们对轨迹含义的解读能力。时空轨迹序列R可以被表示为
R∶{(B4,t1),(B4,t2),(B4,t3),(B4,t4),(B2,t5), (B2,t6),(B2,t7),(B3,t8)}
根据上文中对时空轨迹生成原理的介绍,可以定义整个校园无线网络中的N个用户的集合为
U={u1,u2,…,ui,…uN}
定义用户ui的轨迹序列集为
Ri={ri,1,ri,2,…ri,x,…ri,Ki}
其中,1≤x≤Ki,Ki为用户ui轨迹序列中行为记录总数,序列中的元素ri,x为轨迹记录点,其为二元组 (li,x,ti,x),li,x是发生行为记录的地点,ti,x则是发生行为记录的时间。
3 轨迹时空相似性度量模型
时空轨迹具有时间和空间两个维度的属性特征,且时间特征和空间特征是相互约束但又相互独立的。通常在研究相似性时,相似结果的值都会被定义在0至1之间。同样,本文定义任意两个轨迹序列之间的时间相似性TCor(Ri,Rj) 和空间相似性SCor(Ri,Rj) 变化范围均在0至1之间
TCor(Ri,Rj)∈[0,1]
SCor(Ri,Rj)∈[0,1]
根据时间特征和空间特征之间的关系,定义任意两轨迹的时空相似性为
TSCor(Ri,Rj)=TCor(Ri,Rj)×SCor(Ri,Rj)
(1)
通过对上式进行分析可以发现,任意两轨迹的时空相似性的变化范围仍然在0至1之间,当时间或空间任意特征的相似性为零时,则两轨迹的时空相似性为零。
本文提出的时空轨迹相似性度量模型根据上述思想从时间和空间角度进行相似性计算,时间相似性采用最短时间距离(shortest time distance,STD)模型,空间相似性采用基于LCSS的最短时间距离子序列(shortest time distance subsequences,STDSS)模型。为了提高度量模型的运算效率,轨迹相似性计算前先并行滑动窗口对用户轨迹进行轨迹划分,获得对应时间范围内的n组轨迹段,然后依次对每组轨迹段进行相似性计算,汇总得到轨迹整体相似性,即用户之间的相似性度量结果。以计算用户ui和用户uj之间的轨迹相似性为例,具体度量流程如图2所示。
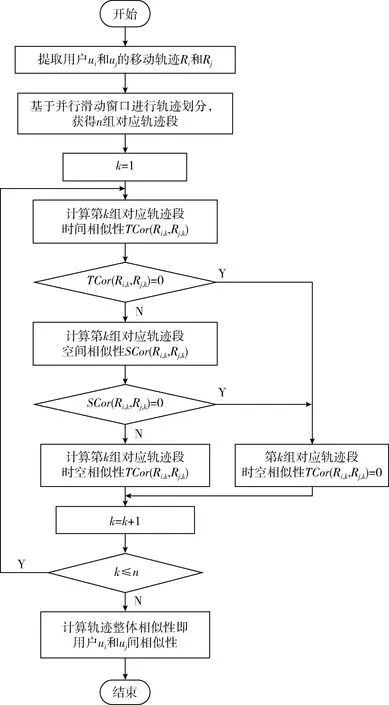
图2 轨迹时空相似性度量流程
下文将分别从时间相似性计算、空间相似性计算和窗口划分3个部分进行详细论述。
3.1 时间相似性计算
在实际生活中,两个用户前往同一地点区域并登陆校园无线网络,则会产生地点区域相同且时间间隔较小的轨迹点。从轨迹的时间属性角度分析,两个轨迹点之间的关联性与行为记录的时间距离有关,当时间距离较小时,关联性较高,随着时间距离的增大,关联性随时间距离的增大急剧衰减[17]。
对任意两个轨迹记录点ri,x和rj,y进行匹配计算:若li,x≠lj,y,表示两个用户并未出现在同一地点区域,则ri,x和rj,y之间不存在关联性;若li,x=lj,y,表示两个用户出现在同一地点区域,存在关联性。根据行为记录关联性随时间变化的规律,定义轨迹记录点ri,x和rj,y的时间距离Dis(ri,x,rj,y) 为
(2)
对于用户ui和用户uj,其时空轨迹序列分别为Ri={ri,1,ri,2,…ri,x,…ri,Ki} 和Rj={rj,1,rj,2,…rj,y,…rj,Kj}。对于轨迹序列Ri中的轨迹点ri,x,寻找轨迹Rj中所有轨迹点中与轨迹点rj,y时间距离最小的值,即最短时间距离STD,记为STD(ri,x,Rj),表达式为
STD(ri,x,Rj)=minDis(ri,x,rj,y),∀y∈Kj
(3)
基于DTW算法的思想可以认为,轨迹Ri对于轨迹Rj之间的关联性可以近似为Ri轨迹序列中所有轨迹点与Rj轨迹序列中对应STD匹配点的关联性总和,定义表达式为
(4)
从上式可以发现,STD相似性度量模型具有明显方向性,可以得出轨迹Rj对于轨迹Ri的关联性如式(5)所示,两轨迹之间基于STD模型得到时间序列相似性结果如式(6)所示
(5)
(6)
3.2 空间相似性计算
最长公共子序列(LCSS)算法是常用的从轨迹序列角度分析轨迹相似性的度量方法。轨迹序列的子序列是指,不改变序列的顺序,从序列中去掉任意的元素而获得新的序列。LCSS算法就是寻找两个给定序列的公共子序列中最长的子序列,该子序列在两个序列中以相同的顺序出现,但是不要求是连续的。可以认为最长公共子序列的长度越长,给定的两个序列相似程度越高。该方法较好反映出了时空轨迹的空间特征,因此本文考虑选择利用LCSS进行轨迹空间相似性计算。
对于用户ui和用户uj,其时空轨迹序列分别为Ri={ri,1,ri,2,…ri,x,…ri,Ki} 和Rj={rj,1,rj,2,…rj,y,…rj,Kj}。求取其LCSS序列Rθ
Rθ={rθ,1,rθ,2,…,rθ,z,…,rθ,Kθ}
轨迹Ri和轨迹Rj的空间相似性可以采用LCSS序列的长度分别占两条轨迹长度比例的平均值决定
(7)
利用LCSS模型求取时空轨迹的空间相似性时虽然能够体现出轨迹之间的重叠程度但是却无法体现出轨迹的连续性特征。例如,假设有
轨迹A:{餐厅→教学楼1→教学楼3→操场}
轨迹B:{餐厅→教学楼1→教学楼3→超市}
轨迹C:{餐厅→教学楼1→图书馆→教学楼3}
轨迹A分别与轨迹B、轨迹C求取LCSS的长度均为3,但是明显可以发现轨迹B与轨迹A出现了相同的移动模式,即可以认为轨迹A与轨迹B的相似程度比轨迹C要更高。由于校园用户的生活移动轨迹主要围绕寝室和教学区展开,因此基于校园无线网络的数据集中会更容易出现大量重复易混淆的轨迹点,这使得仅仅依靠LCSS来衡量轨迹的空间相似性不够合理。基于校园无线网络数据的特点,本文提出了一种基于最短时间距离子序列STDSS的用户轨迹相似性度量模型,参考文献[18]中轨迹连续性的表达方式在LCSS基础上引入连续因子,增加轨迹空间相似性的度量能力。
假设有两条轨迹Ri和Rj,将轨迹Ri中每个轨迹点根据式(3)对轨迹Rj求取最短时间距离,轨迹Rj中对应的最短时间距离点构成的子序列称为轨迹Rj属于轨迹Ri的最短时间距离子序列,记为SRi→j。同时还可以确定最短时间距离子序列SRi→j在轨迹Rj中的位置顺序分布,以确定地点连续因子γ。定义连续因子表达式
(8)
(9)
式中:γi→j表示SRi→j的连续因子,|SRi→j| 为SRi→j的序列长度,Kj为轨迹Rj的轨迹长度,u表示SRi→j序列中第z个序列点对应轨迹Rj中的顺序位置数,v表示SRi→j序列中第z-1个序列点对应轨迹Rj中的顺序位置数。
举例说明上述过程,例如存在两条轨迹为
R1={(A,8:20),(A,8:25),(C,10:55),
(D,11:12),(B,11:39)}
R2={(A,7:50),(E,8:18),(C,10:37),(D,11:05),
(D,11:23)(A,12:28)}
轨迹R1对于轨迹R2的最短时间距离计算结果如图3所示,所以轨迹R2属于轨迹R1的最短时间距离子序列为SR1→2:{A,C,D},该子序列在轨迹R2中对应位置顺序为{2,3,4}。
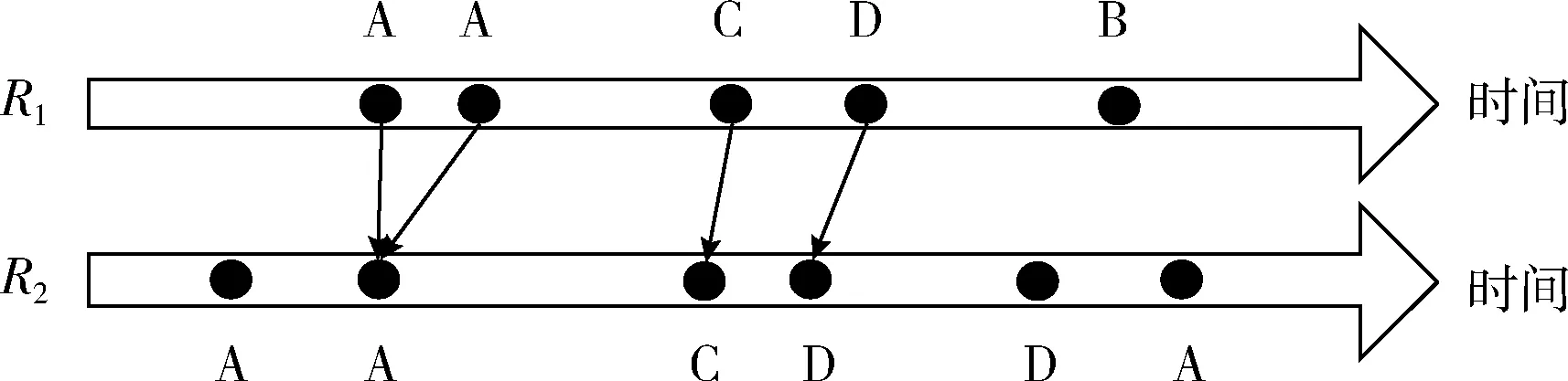
图3 最短时间距离子序列
轨迹连续因子的求取过程不具有对称性,可以定义两条轨迹之间的连续因子γi,j的表达式为
(10)
基于此,将式(7)进行修正,得到轨迹Ri和轨迹Rj基于STDSS的空间相似性计算结果为
(11)
至此,根据时间特征和空间特征之间的关系,本文中共提到了3种时空轨迹相似性度量模型:
(1)最短时间距离模型(STD模型)。该模型仅利用STD算法提取轨迹序列的时间特征进行计算,忽略空间相似性部分。
(2)最长公共子序列时空度量模型(STD-LCSS模型)。该模型结合了STD算法和LCSS算法同时从时间和空间角度对轨迹序列进行计算。
(3)最短时间距离子序列时空度量模型(STD-STDSS模型)。该模型是本文提出的优化模型,结合了STD算法和STDSS算法,针对校园用户的轨迹数据特征从时间和空间角度对轨迹序列进行计算。
3.3 时空轨迹的窗口划分
在实际应用过程中,用户在校园无线网络中的轨迹序列长度通常跨度非常大,这对进行轨迹相似性度量带来了一定的困难。而且,用户的轨迹序列通常呈现一种周期性变化,为了得到更准确的度量结果、提高运行速度,本文采用并行滑动时间窗口将两名用户完整的时空轨迹同时进行划分,分别计算对应窗口内轨迹段的时空相似性再进行汇总平均处理。定义符号w=(ls,le,ts,te) 来表示某一用户轨迹在某段连续时间中产生的用户轨迹序列段,其中ls和le分别表示时间窗内该轨迹的起止轨迹地点编号,ts和te分别表示时间窗的起止时间。起止时间之间的时间间隔定义为时间窗的长度,即
length(w)=|ts-te|
时间窗内包含轨迹序列的轨迹点数定义为时间窗的体积,即
volume(w)=|ls-le|
每个滑动窗口的长度和体积大小受到上限的约束
其中,lengthmax和volumemax分别表示最大窗口宽度和体积。
首先对两轨迹的起始轨迹点进行分析,选择时间参数较小的轨迹点作为时间窗的起始轨迹点,对应时间参数为滑动窗口的起始时间。窗口结束时间由两个约束的上限同时决定,若窗口内两用户的轨迹段同时满足时间和体积的约束上限,这将窗口标识为有效窗口。剩下的轨迹序列以相同的规则依次重复划分下去,便可得到两用户的滑动窗口序列。图4为并行滑动窗口的实现原理。
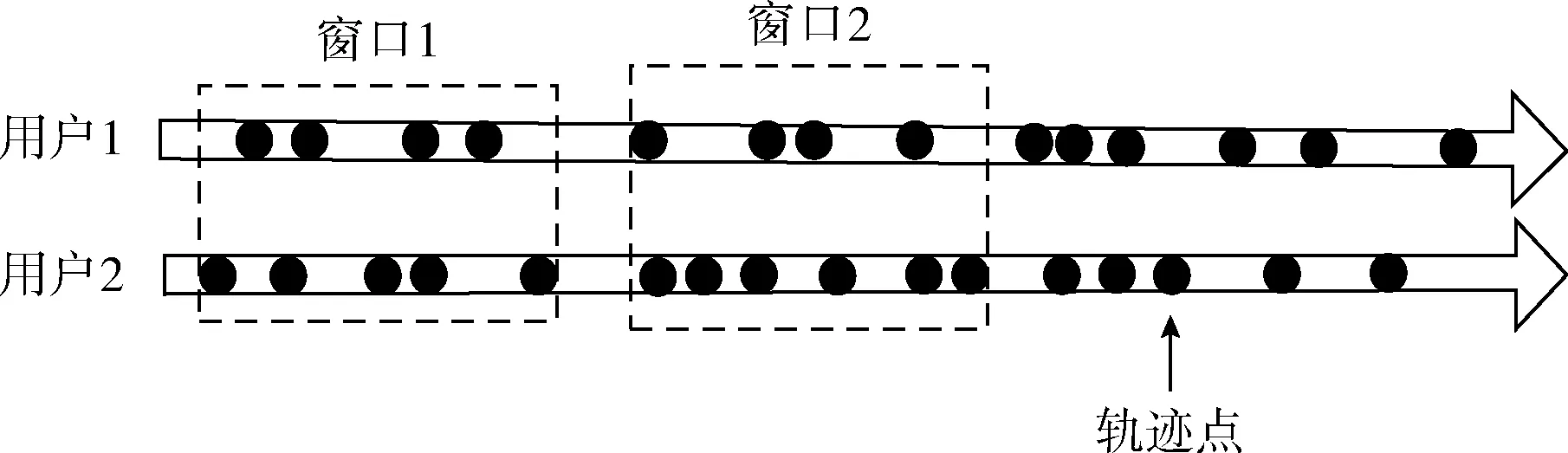
图4 并行滑动时间窗
并行滑动窗口提取出的轨迹段能够同时通过时间跨度和窗口内的轨迹点数目进行大小调整,较好地适应两个用户的轨迹点分布变化,平衡各个窗口内的轨迹点数量。该窗口滑动方法可以提取出位于相同时间范围内的轨迹段,将其对应进行时空相似性度量更具合理性。
假设存在某校园用户ui和uj,定义两用户某段时间内通过校园无线网络产生的总轨迹为Ti和Tj,通过并行滑动时间窗获得n个窗口内的轨迹段序列集合为
Ti={Ri,1,Ri,2,…,Ri,x,…,Ri,n}
Tj={Rj,1,Rj,2,…,Rj,x,…,Rj,n}
其中,n为轨迹划分的总窗口数。
结合上文的式(1)、式(6)和式(11)定义用户ui和uj之间的用户相似性可通过轨迹段的时空相似性获得,表达式为UCor(ui,uj)
(12)
4 实验分析
本文抽取某高校无线网络的真实登录记录作为实验数据集。该数据集时间跨度为30天,被统计用户共377名,涵盖全校区域范围的21个地点编号。该轨迹数据是由电子设备(如手机、笔记本电脑)接入无线局域网络的接入点获取的用户位置信息组成,因此在进行用户轨迹相似性计算之前,需要对数据集进行清洗,剔除重复和错误的数据。此外,还需对地点相同的数据点进行适当合并,减少密集轨迹点。本文在实际实验中,选择将时间间隔在5分钟内的相同地点的轨迹点进行合并,将两轨迹点动作时间的平均值作为合并后轨迹点的时间。将用户的轨迹点时间表示为数值形式,将24小时映射至区间[0,1],因此30天时间跨度应为区间[0,30]。表1中记录了完成数据预处理后数据集的数据格式。

表1 数据集轨迹序列
为验证最短时间距离模型(STD模型)、最长公共子序列时空度量模型(STD-LCSS模型),以及本文提出的最短时间距离子序列时空度量模型(STD-STDSS模型)3种轨迹相似性度量模型的特点以及STD-STDSS模型的优越性,将从局部轨迹段、数据集整体效果和运行时间3个方面进行分析。
4.1 局部轨迹段相似性结果
从数据集中提取出3名用户某天的轨迹序列见表2,其轨迹点在一天内的分布情况如图5所示,利用文中3种轨迹相似性度量方法分别计算出用户1与用户2之间的相似性和用户1与用户3之间的相似性见表3。
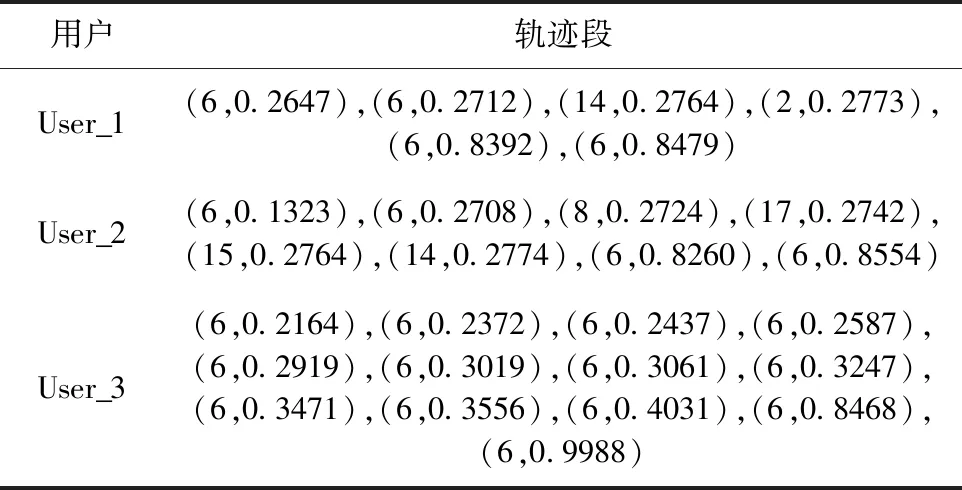
表2 3名用户某天内轨迹序列

图5 3名用户某日轨迹点分布情况
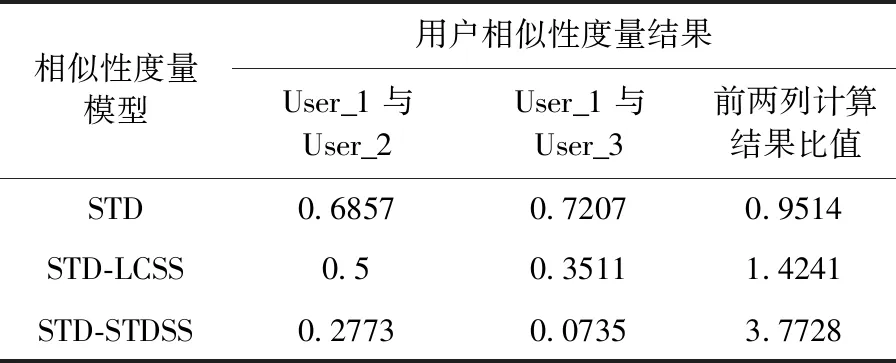
表3 不同相似性度量算法结果对比
从图5轨迹点的分布中可以发现,用户2与用户3的轨迹序列中,用户2的行为轨迹序列明显与用户1更为相似,但是STD模型却得出了相反的实验结果。STD-LCSS模型和STD-STDSS模型得出的计算结果更加具有合理性,并且STD-STDSS模型能够更明显区分出轨迹序列的差别。用户3的轨迹模式是校园无线网络数据集中经常出现的一种轨迹类型,用户的行为数据为大量重复的地点且通常为宿舍楼,这样容易对相似性度量的结果产生干扰,STD-STDSS模型则可以过滤这样的干扰信息,提高局部轨迹段计算的准确性。
4.2 整体轨迹数据集相似性结果
对整体轨迹数据集进行实验分析时,为更好地验证不同模型之间计算结果的有效性,需要将计算结果先进行归一化处理,得到任意两用户之间的关联性Urelation(ui,uj)
(13)
式中:UCormin和UCormax分别为整个数据集中任意两用户轨迹序列相似性计算值的最小值和最大值。
采用用户关联性有效性指标AFR(θ) (accuracy of fin-ding relationship)进行分析对比[17]。其含义为所有满足Urelation(ui,uj)≥θ的用户对和uj中含有相同用户标签(例如学院专业班级)的用户对所占的比例,表达式为

(14)
式中:θ为用户关联性阈值,有0≤θ≤1,|Urelation(ui,uj)≥θ| 为满足阈值范围的用户对总数,|Urelation(ui,uj)≥θ且ui与uj存在相同用户标签|为满足阈值范围且含有相同用户标签的用户对总数。通过对阈值的设置,可以分析不同度量方法下用户关联性的分布与变化情况。表4和图6分别记录了3种模型的AFR(θ) 随θ变化的数值和曲线。
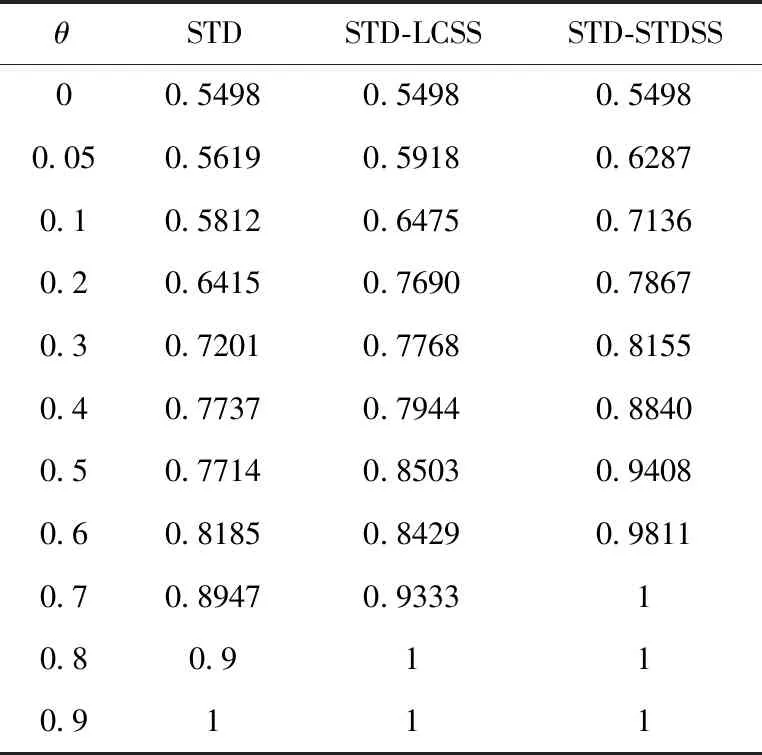
表4 不同模型下AFR(θ)随θ变化情况
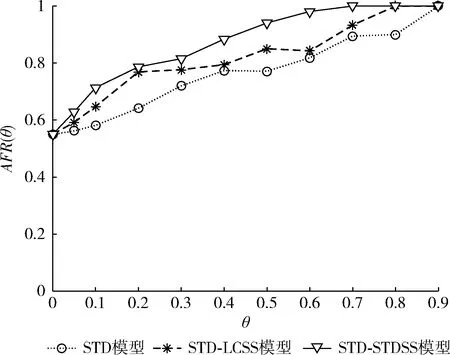
图6 不同模型下AFR(θ)随θ变化的曲线
从表4和图6中可以看出AFR(θ) 会随着阈值θ增大而增大,在相同θ的情况下,STD-STDSS模型的结果准确性最高,且准确率较早达到了100%。在AFR(θ) 随阈值θ增长的过程中,前两种模型在θ=0.5附近均出现了准确率波动的现象,但是STD-STDSS模型则未出现这样的状况。
4.3 运行时间比较
对整体数据集通过20次仿真实验求取运行时间平均值后发现,采用并行滑动窗口对轨迹进行先划分再进行用户相似性计算可以明显提高算法的运行时间。结合轨迹时空特征的算法比仅考虑轨迹时间序列的算法运行时间会有些许增加,但是可以提高度量结果的准确性,因此所需运行时间增长在可接受范围内。图7为未进行滑窗处理直接利用STD模型进行相似性度量与经过滑窗处理后再进行度量的3种模型所需运行时间的比较。

图7 不同模型运行时间比较/s
5 结束语
相似性度量是轨迹数据挖掘中的关键性步骤,也决定了后续推广应用成果是否可靠。针对目前相关轨迹相似性度量方法不能较好地应用于校园无线网络场景的问题,本文提出了最短时间距离子序列时空度量模型(STD-STDSS模型)。该模型基于校园无线网络的数据特点和应用场景,同时结合轨迹时间序列与空间信息,度量用户时空轨迹序列之间的相似程度,以反映校园无线网络用户之间的关联性。该模型利用最短时间距离(STD)求取轨迹的时间相似性,利用最短时间距离子序列(STDSS)的概念求取轨迹的空间信息相似性。STDSS模型能够在剔除干扰数据的同时保留轨迹空间信息的顺序特征,提高轨迹空间相似性度量的准确性。最后,文中利用真实的校园无线网络数据集对算法进行了实验验证,实验结果表明,基于最短时间距离子序列(STD-STDSS)的轨迹时空相似性度量模型的计算结果在局部和整体都具有较好的准确性,在基于校园无线网络的应用场景下有较好的实际效果。
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
数学物理学报(2022年5期)2022-10-09 08:56:44
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
河北画报(2020年8期)2020-10-27 02:54:20
铁道通信信号(2020年12期)2020-03-29 06:22:16
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
信息安全研究(2016年4期)2016-12-01 06:07:04
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
中国学术期刊文摘(2016年1期)2016-02-13 14:05:23
移动通信(2015年17期)2015-08-24 08:13:12
