
多角度视频的驾驶人员行为识别
2020-11-17 03:30:04沈柏杉
吉林大学学报(信息科学版) 2020年3期
赵 维, 沈柏杉, 张 宇, 孔 俊
(1.吉林警察学院 信息工程系, 长春130117; 2.东北师范大学 信息科学与技术学院, 长春130117)
0 引 言
行车安全已成为目前我国威胁公共安全、 建设平安中国的主要因素之一。 作为道路交通的主导者, 很多驾驶人员会觉得没有严重的交通违法行为, 行车就一定安全。 其实许多的交通事故正是因为平常状态下的一些难以察觉的驾驶行为习惯造成的。 基于车载监控视频的驾驶员行为分析是新兴科研与应用的结合。 国内外众多学者基于计算机视觉对辅助安全驾驶进行了大量研究[1-3],一些研究机构开发了脸部疲劳状态检测系统用于辅助安全驾驶[4-5], 另一些学者也从观察驾驶员身体活动状态的角度出发, 对驾驶员行为进行识别检测[6]。 随着大数据、 云计算、 “ 互联网+” 时代的到来, 利用人工智能与机器视觉自动检测与分析驾驶人员异常行为以减少交通事故的研究越来越多[7]。 但还是面临一些困难, 现实的环境中, 不同的场景存在杂乱背景、 阻挡和视角变化等情况,而目前方法都是基于一些具体且固定的应用场景假设上的, 如目标只有小的尺度变化或视觉改变等, 而这在现实世界中是很难满足的。 以往的报道研究只使用了单独的一个角度, 或从疲劳驾驶,手持电话等单一行为进行编码, 普适性较低。 为此笔者提出了一种多角度行为识别方法, 从3 个角度同步捕捉驾驶人员行为的视频, 构建多角度驾驶行为的视频和数据集, 利用深度卷积神经网络,构建了2 维, 3 维, 混合卷积等网络架构对视频数据进行分类实验, 在2 加1 维网络中对多角度驾驶人员行为识别精度达到87% 。
1 驾驶危险行为特点
驾驶危险行为指的是在驾驶过程中驾驶人员的一些可能造成交通事故的行为, 如接打电话、 抽烟等会对驾驶过程造成一定的影响。 对危险的驾驶行为进行识别和检测, 需要对其特征进行建模。 在日常驾驶中, 驾驶员大多存在以下几种危险的驾驶习惯: 1) 接打电话; 2) 与乘车人员交谈; 3) 疲劳驾驶;4) 车外抛物; 5) 抽烟。 根据这些行为的特点, 可将驾驶人员行为识别归为场景单一情况下的行为识别。目前针对视频中的行为典型的识别方法步骤如图1 所示, 首先对视频进行剪辑或抽取随机帧的预处理,然后进行目标检测, 运动追踪, 特征提取和描述, 最后进行识别分类或行为理解。
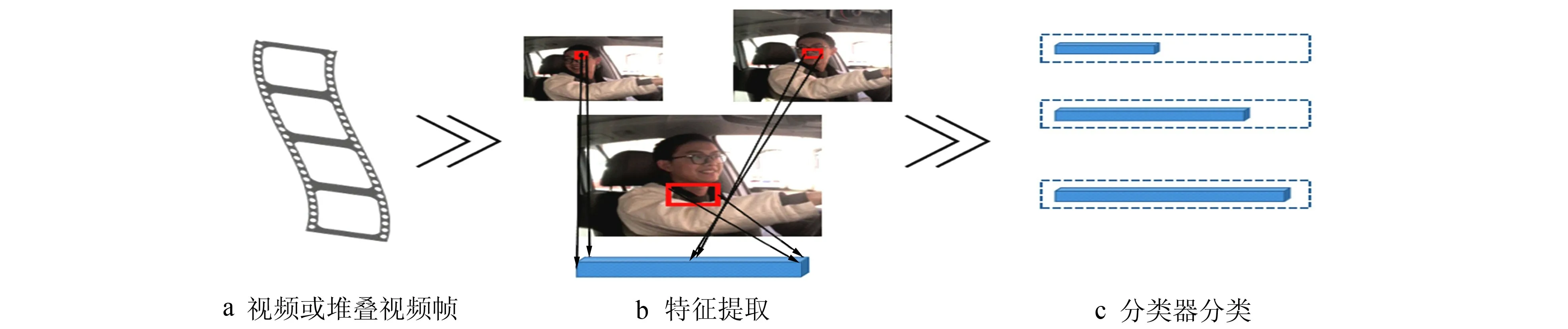
图1 视频中行为识别基本流程图Fig.1 Basic flow of behavior recognition in video
2 多角度驾驶员行为识别卷积网络
2.1 深度残差网络
在构建卷积网络时, 网络的深度越高, 可抽取的特征层次就越丰富。 所以一般人们都会倾向于使用更深层次的网络结构, 以取得更高层次的特征。 但是在使用深层次的网络结构时会遇到两个问题, 即梯度消失、 爆炸和网络退化问题。 He 等[8]实验证明, 时间复杂度相同的两种网络结构, 深度较深的网络性能会有相对的提升。 然而, 网络并非越深越好。 抛开计算代价问题, 在网络深度较深时, 继续增加层数并不能提高性能, 训练误差也随着层数增加而提升。 基于此问题He 等[8]提出了深度残差网络结构。 残差网络更容易优化, 并且能通过增加相当的深度提高准确率。 核心是解决了增加深度的副作用( 退化问题), 这样能通过单纯地增加网络深度提高网络性能。 残差在数理统计中是指实际观察值与估计值( 拟合值) 之间的差, 可将残差看作误差的观测值。 多层的神经网络理论上可以拟合任意函数, 但是直接让一些层去拟合一个潜在的恒等映射函数H( x) = x 比较困难, 如果把网络设计或H( x) = F( x) + x, 可转换为学习一个残差函数F( x)= H( x)-x。
如图2 所示, x 代表输入, F(x) 为表示残差块在第2 层激活函数前的输出。 对于一个堆积层结构(几层网络堆积而成) 当输入为x 时其学习到的特征记为H(x), 现在希望其可以学习到残差F( x)=H(x)-x, 即原始的学习特征是F(x)+x。 当残差为0 时, 此时堆积层仅仅做了恒等映射(shortcut), 至少网络性能不会下降, 实际上残差不会为0, 这也会使堆积层在输入特征基础上学习到新的特征, 从而拥有更好的性能。

图2 残差单元示意图Fig.2 Shortcut connection
F(x)由下式给出
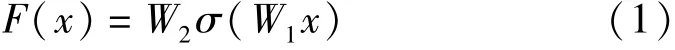
其中W1,W2为第1 层和第2 层的权重,σ为Relu 激活函数。 然后通过一个shortcut 和第2 个Relu 激活函数, 获得输出y为

当需要对输入和输出维数进行变化时(如改变通道数目), 可在shortcut 时对x做一个线性变换Ws

2.2 网络模型
2.2.1 2 维卷积(R2D)
处理输入为视频的R2D CNN[9]是将其输入尺寸为3 ×L×H×W( RGB 通道数, 帧数, 高, 宽) 的4D 张量x 调整为尺寸为3L×H×W的3D 张量。 所以没有考虑视频中的时间排序并且将L帧作为通道数。 每个滤波器都是3D 的, 其尺寸为Ni-1×d×d, 其中d表示空间宽度和高度。 因此, 第i个残差块的输出zi也是3D 张量, 其大小为Ni×Hi×Wi, 其中Ni表示在第i个块中应用的卷积滤波器的数量,Hi,Wi是空间维度。 尽管滤波器是3 维的, 但它仅在zi-1 的空间维度上以2D 进行卷积。 每个滤波器产生单通道输出。 R2D 中的卷积层将视频的整个时间信息堆叠到单通道特征图中。 这种类型的CNN 架构如图3a 所示。
2.2.2 混合卷积MCx(Mixed 3D-2D Donvolutions)
针对视频中对运动的建模有一种假设是运动建模(3D 卷积)在早期层中可能特别有用, 而在较高级别的语义抽象(后期层)中, 运动或时间建模不是必需的。 因此, 合理的架构可以从3D 卷积开始并切换到在顶层中使用2D 卷积。 这项工作中考虑的3D ResNets(R3D)有5 组卷积, 第1 个设计是用2D 卷积替换5 组中的第3 组到第5 组中的3D 卷积, 用MC3(混合卷积a)表示这种架构, 并且设计了在第2 组到第5 组中使用2D 卷积, 将此模型命名为MC2(意思是从第2 组到更深层的所有卷积都是2D 卷积), 如图3b,图3c 所示。
2.2.3 3 维卷积(R3D)
基于残差的3D 卷积神经网络(R3D CNN)[10-11]是利用3D 的卷积核对视频序列进行卷积, 每个滤波器都是4 维的, 它的大小为Ni-1×t×d×d, 其中t表示滤波器的时间范围(在本文中, 设置t= 3)。 张量zi在这种情况下是4D 的, 尺寸为Ni×L×Hi×Wi, 其中Ni是在第i个块中使用的滤波器的数量。 R3DCNN 保留了全部的时间信息。 这种类型的CNN 架构如图3d 所示。
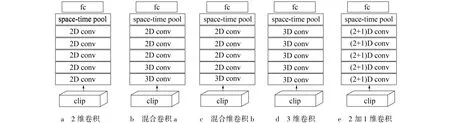
图3 卷积神经网络架构Fig.3 The architecture of convolutions
2.2.4 2 加1 维卷积(R(2+1)D)

图4 R3D / R(2+1) D 卷积操作示意图Fig.4 Diagram of R3D / R(2+1) D convolution operation
R(2+1) D 模型为R3DCNN 的一种变形, 是将3DCNN 的卷积过程分解为2D 卷积和1D 卷积。将空间和时间建模分解为两个单独的步骤。 该网络将大小为Ni-1×t×d×d的Ni个3D 卷积核替换成大小为Ni-1×1 ×d×d的Mi个二维卷积滤波器和尺寸为Mi×t×1×1的时间卷积滤波器。 这种时空分解可以应用于任何3D 卷积层。 图4 给出了R3D 和R(2+1 ) D 卷积过程的简单示意图, 其中输入张量Zi-1包含单个通道( 即Ni-1= 1), 图4a 中使用尺寸为t×d×d的滤波器进行全3D 卷积, 其中t表示时间范围,d是空间宽度和高度。 图4b 中R(2+1) D卷积块将计算分成空间2D 卷积, 然后是时间1D卷积。 令2D 滤波器的数量为Mi, 使得R(2 +1) D块中的参数数量与完整的3D 卷积块的参数数量相同, 则有

3 实验与结果分析
3.1 多角度驾驶员行为数据集
笔者创建了一个用于驾驶员不良驾驶行为分类的数据集。 录制这个数据集主要是针对不良驾驶行为可能造成交通事故等问题, 并可以促进多角度下行为识别方面的研究。 数据由35 个受试者执行。 每个动作持续大概20 s, 并且有3 个镜头同时录制, 如图5 所示。 把录制好的样片进行剪辑, 得到每个类别里3 个角度下的100 个左右的视频样本, 共计489 个视频。 由于类间差异比较小, 因此该数据集具有一定的挑战性。 其中部分视频样例如图6 所示。
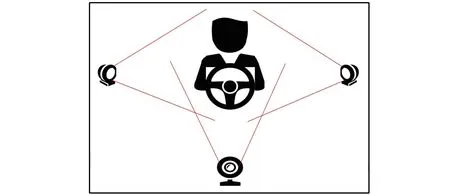
图5 摄像头设置示意图Fig.5 Schematic diagram of camera setting

图6 多视角驾驶员行为数据集视频样例Fig.6 Multi-view driver behavior data set
3.2 网络架构计
近年来, 为了验证视频中人类行为识别方法的性能, 许多研究者制作并且公开了大量的数据集。 早期的有KTH[12]、 Weizmann[13-15], 近期的则有HMDB51[16]。 笔者使用Kinetics[17]作为预训练数据集, 因为他们足够大, 可以从头开始训练深层模型。 由于良好的视频模型还必须支持对其他数据集进行有效的迁移学习, 因此将预训练好的模型在UCF101[18]和多视角驾驶员数据集上对它们进行微调。
3.2.1 训练过程
将所有网络设置为18 层, 并用Kinetics 从头开始训练。 视频帧被缩放到128×171 的大小, 然后通过随机裁剪大小为112×112 的窗口生成每个剪辑。 在训练时随机划取视频中的L 个连续帧, 尝试了两种设置: 模型在8 帧剪辑(L = 8) 和16 帧剪辑(L = 16) 上进行训练。 批量标准化应用于所有卷积层。 尽管Kinetics 只有大约240 kByte 的训练视频, 但将时间尺寸设置为1 min。 初始学习率设置为0.01 并且每10 个时期减小10 倍, 使用caffe2 在GPU 上使用SGD 进行训练, 最后将预训练好的参数保存, 并且在UCF 和驾驶人员数据集上进行微调。
3.3 实验结果与分析
3.3.1 时空卷积及输入剪辑的帧数比较
表1 给出了Kinetics 数据集上的分类准确度。 所有的模型都基于18 层的残差结构, 且具有相同的输入并处理每个剪辑中的所有帧(输入分为8×112×112 和16×112×112)。
与通过剪辑执行时间推理的3D 或MCx 模型相比, R2D 在第1 个残差块后堆叠时间信息, 而R2Df计算来自各个帧的静止图像特征。 从这些结果可以推断出2D、 ResNets( f-R2D 和R2D) 的性能与R3D或混合卷积模型(MC2 和MC3)的性能之间存在明显差距。 在8 帧输入设置中, R2D 和R3D 精度相差2.3% ~3.8%, 当模型在16 帧剪辑上作为输入进行训练时, 该差距变大(即5.3% ~8.9%)。 这表明运动建模对于动作识别很重要。 在不同的3D 卷积模型中, R(2+1) D 显然表现最佳。 在8 帧设置中,比R3D 高出3.0% ~4.8%, 比MC2 高出2.3% ~3.6%, 在16 帧输入设置中比R3D 和MC2 高出3.8% ~5.9%, 表明在单独的空间和时间卷积中分解3D 卷积比通过混合3D-2D 卷积建模时空信息更好。

表1 Kinetics 数据集上动作识别精度Tab.1 Action recognition accuracy on Kinetics dataset

表2 UCF101 数据集上动作识别精度Tab.2 Action recognition accuracy on UCF101 dataset
表2 给出了UCF101 在Kinetics 数据集上预训练后的模型上的动作识别精度, 在预训练模型上UCF 的训练时间大幅减小, 得到的结论也与上述一致, R( 2 + 1 ) D 模型的表现最好。 根据Varol 等[19]的研究发现, 使用长期卷积( LTC) 在较长的输入剪辑( 例如, 100 帧) 上训练视频CNN, 可以获得准确度增益。 笔者也对输入剪辑的帧数进行了比较, 如图12 和图13 所示, 大部分模型在将8 帧为一个剪辑设置成16 帧为一个剪辑后, 识别精度均有提升。 针对此问题做了2 个实验, 在第1 个实验中, 采用8 帧的剪辑训练的模型, 并使用32 帧的剪辑作为输入进行测试。 结果发现, 与8 帧剪辑相比, 识别精度下降5.8% 。 在第2 个实验中, 使用在8 帧的剪辑预训练后的模型参数微调32 帧模型。 在这种情况下, 网络实现的结果几乎与在32 帧剪辑中从头学习(68.0% 对比69.4% ) 时的结果相同。 然而, 从8 帧预训练参数中微调32 帧模型大大缩短了总训练时间。 上述2 个实验表明, 对较长剪辑进行训练会产生不同( 更好) 的模型, 因为模型会学习更长的时间信息。 表3 给出了Kinetics 数据集上在不同长度的剪辑上训练和评估的18 层R(2 +1) D 的总训练时间和准确度。
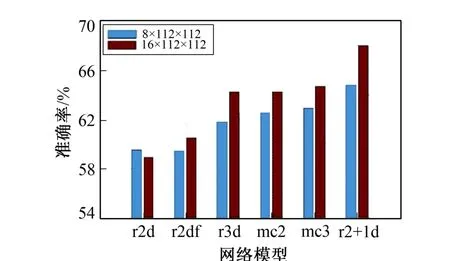
图7 Kinetics 数据集不同模型下不同 输入的识别精度Fig.7 The identification accuracy of different inputs in different Kinetics data sets under different models

图8 UCF 数据集不同模型下不同 输入的识别精度Fig.8 The identification accuracy of different inputs in different UFC data sets under different models

表3 Kinetics 数据集上不同剪辑在18 层R(2+1)D 模型上的训练时间与识别精度Tab.3 Training time and recognition accuracy of different clips on 18-layer R(2+1)D model in Kinetics data set
3.3.2 多角度驾驶人员行为识别
使用Kinetics 上预训练的参数在多角度驾驶人员数据集上进行微调, 在不同模型中, 仍然是R(2+1)D模型表现最好。 在加深网络层数的基础上, 设置32 帧为一剪辑输入。 这是当前环境下(单个1 080 GPU)的极限, 可以达到87% 的精度。 虽然精度随着层数的增加而增加, 但模型复杂度也随着层数的增加而变大, 计算代价也随着帧数的增多而变大。 在考虑到上述问题后, 将R(2+1)D 模型最终的层数定为34 层, 输入为32×112×112。 如表4 所示, 多角度的识别率可达到87.00%。 显著优于单独视角下的实验结果。

表4 单独角度和多角度的驾驶人员行为识别精度Tab.4 Single angle and multiple angle driver behavior recognition accuracy
4 结 语
笔者针对视频中行为识别的问题出发, 着手于驾驶员驾驶真实场景, 构建了一个多角度的驾驶人员行为数据集, 对驾驶员行车过程中可能出现的危险行为进行检测捕捉, 分别在2 维卷积神经网络、3 维卷积神经网络、 混合卷积神经网络和2 加1 维卷积神经网络上进行实验检验, 并在2 加1 维神经网络上得到了87% 的识别效果。
实验结果表明, 3 维卷积神经网络在视频中的行为识别优于2 维卷积神经网络的性能, 随着网络层数的增加精度会提升, 但模型复杂度同样会增大。 同样, 网络输入的剪辑数越大, 精度提升越高, 计算量也会随之增加。 在多个视角的数据集下、 复杂度和精度的平衡中, 2 加1 维卷积神经网络性能最优。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
科技与创新(2021年21期)2021-11-29 03:08:58
就业与保障(2021年9期)2021-11-22 15:01:07
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
汽车实用技术(2019年9期)2019-11-25 22:35:04
自动化学报(2019年6期)2019-07-23 01:18:32
电子制作(2019年11期)2019-07-04 00:34:38
农村百事通(2018年16期)2018-09-29 08:39:30
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
