
复杂场景下基于改进YOLOv3的口罩佩戴检测算法
2020-11-14 04:00:12王艺皓丁洪伟杨志军杨俊东
计算机工程 2020年11期
王艺皓,丁洪伟,李 波,杨志军,2,杨俊东
(1.云南大学 信息学院,昆明 650500; 2.云南省教育厅科学教育研究院,昆明 650223)
0 概述
2019年12月以来,新型冠状病毒肺炎(COVID-19)疫情[1]已经陆续蔓延到我国多个省份及境外多个国家,对人类健康和社会安全带来了巨大威胁。国家卫生健康委员会2020年6月29日发布新型冠状病毒肺炎疫情最新情况[2]:31个省(自治区、直辖市)和新疆生产建设兵团共累计报告了确诊病例83 531例,死亡病例4 634例,治愈出院病例78 469例,现有确诊病例428例(无重症病例)。最新研究发现,虽然新型冠状病毒的病死率低于SARS等病毒,但是其具有更强的传染性和更长的潜伏期[3]。新型冠状病毒主要通过呼吸道飞沫、密切接触等方式进行传播[4],目前认为人群普遍易感[5],并且随时存在大规模聚集性传染爆发的可能性[6]。当前,在采取了强有力的防疫措施后,我国抗击新冠肺炎已取得了空前成功,疫情态势趋好,多省实现“零增长”。在全国复工复学大势下,人们更应科学地对抗疫情,从疾病初期的以临床治疗为主到进一步强化、重视公共卫生工作[7],而公共场所正确佩戴口罩作为严防疫情反弹的最有效措施之一,不仅是对每个人日常行为的考验,也对相关技术的监督和管理提出了一定要求。
目前,专门应用于人脸口罩佩戴检测的相关算法[8]较少。多数的通用目标检测算法都适用于人脸口罩佩戴检测任务,但是由于复杂场景中存在目标遮挡、密集人群、小尺度目标检测等问题,导致通用目标检测算法直接应用于人脸口罩佩戴检测任务时效果不理想。为解决上述问题,学者们进行了大量的研究并取得了一定成果。SINDAGI等人[9]提出了一种上下文金字塔卷积神经网络(Contextual Pyramid CNN,CP-CNN)方法,其通过提取深度卷积特征得到了高质量的人群密度图。PANG等人[10]利用标注中的遮挡信息设计基于掩码的空间注意力机制模块,使得模型更加关注行人未被遮挡部分的特征,从而有效缓解了周围其他特征对行人检测的干扰。LIU等人[11]借鉴FCN与DCN的思想,采用位置敏感的可变形卷积[12]池化来提高模型特征编码的灵活性,使模型更多地从行人可见部分中学习相应特征,避免其他物体的遮挡干扰。QIN等人[13]对ShufleNet进行改进,通过增大浅层特征的通道数和感受野,以获得更有效的目标特征,并加入上下文信息增强模块和空间注意力模块来进一步促进多特征融合,从而在保证高速推理的同时提升模型的检测精度。
目前,基于深度学习的主流目标检测算法主要分为2种,一种是以RCNN[14-16]系列为代表的两阶段算法,另一种是以SSD[17]系列和YOLO[18-20]系列为代表的单阶段算法。其中,YOLOv3[20]是YOLO系列中应用最广泛的目标检测算法,其结合了残差网络、特征金字塔以及多特征融合网络等多种方法,具有较好的识别速度和检测精度。本文对YOLOv3算法进行改进和优化,以解决复杂场景下人脸口罩佩戴检测任务中存在的遮挡、密集人群、小尺度目标等问题。对YOLOv3中的DarkNet53骨干网络进行改进,结合跨阶段局部网络构造一种CSP DarkNet53网络,以降低内存消耗并提高训练速度。在YOLOv3网络中引入改进的空间金字塔池化结构,同时结合自上而下和自下而上的特征融合策略对多尺度预测网络进行改进,以实现特征增强。在此基础上,使用性能更好的CIoU损失函数替换原IoU损失函数,考虑目标与检测框之间的中心点距离、重叠率以及长宽比信息,以提高目标检测的准确性。
1 YOLOv3算法原理
YOLOv3是REDMON等人[20]于2018年提出的一种单阶段目标检测算法,网络结构如图1所示。YOLOv3的第一个优点是借鉴了ResNet[21]中的残差思想,提出全新的DarkNet53网络作为主干特征提取网络,DarkNet53网络中的残差结构如图2所示。首先经过一次大小为3×3、步长为2的卷积,将其记为特征层x,接着进行一次1×1的卷积将通道数压缩为原来的1/2,然后再进行一次3×3的卷积加强特征提取并将通道数扩张回原来的大小,得到F(x),最后通过残差结构将x和F(x)进行堆叠。该结构的最大优势就是能够通过增加网络深度来提高准确率,同时其内部的残差块使用跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。DarkNet53网络中的每一个卷积部分均使用了特有的结构DarknetConv2D,每次卷积时使用L2正则化,在完成卷积后,进行标准化处理(Batch Normalization,BN)并使用Leaky ReLU激活函数。相比ReLU函数中将所有负值均设为零,Leaky ReLU激活函数则是赋予所有负值一个非零斜率,如式(1)所示:
(1)

图1 YOLOv3网络结构

图2 DarkNet53网络中的残差结构
YOLOv3的第二个优点是使用了多尺度特征进行预测,即从DarkNet53网络中一共提取3个不同的特征层实现预测,shape分别为(52,52,256)、(26,26,512)和(13,13,1 024)。在这3个特征层均进行5次卷积处理,处理后的结果一部分用于输出该特征层对应的预测结果,另一部分用于上采样(UpSampling2D)操作后分别与对应的上一特征层进行融合。
此外,YOLOv3采用YOLOv2[19]中的方法来预测边界框的坐标位置,利用K-means聚类生成3种尺寸不同的先验框,每个预测边框会生成4个值,即左上角的坐标位置以及边框的宽、高。相比其他多数目标检测模型而言,YOLOv3虽然具有检测速度快、精度高的优势,但是其直接应用于复杂场景下的口罩佩戴检测任务时还存在一定不足。一是YOLOv3采用多尺度预测网络,虽然其充分利用感受野,有效缓解了卷积神经网络缺少尺度不变性的问题,但同时也提高了计算量,这对硬件设备和模型训练提出了更高的要求;二是YOLOv3虽然提高了对小目标的检测精度,但也出现了浅层特征提取不充分的问题;三是YOLOv3的预测准确性过分依赖IoU,随着IoU的增大,其对于目标位置的预测精度会有所下降;四是对于复杂场景下存在的遮挡、密集人群以及尺度变化等问题,YOLOv3表现出一定的性能下降。针对以上问题,本文对YOLOv3进行改进和优化。
2 改进的YOLOv3算法
本文主要从DarkNet53骨干网络、特征增强网络和损失函数3个方面对YOLOv3进行改进。
2.1 改进的骨干网络
为进一步改善YOLOv3的特征提取网络,本文引入跨阶段局部网络(Cross-Stage Partial Network,CSPNet)。CSPNet是WANG等人[22]提出的一种可增强CNN学习能力的新型骨干网络,其能够消除算力中损耗较高的计算结构,降低内存成本。本文将CSPNet结构应用于DarkNet53网络,进而构造一种CSP DarkNet53网络[23],DarkNet53网络和CSP DarkNet53网络结构如图3所示。

图3 DarkNet53和CSP DarkNet53网络结构
与DarkNet53网络相比,CSP DarkNet53网络将原来残差块的堆叠拆分成Shortconv和Mainconv 2个部分。Shortconv部分即为生成的一个大的残差边,经过1次卷积处理后直接连接到最后。Mainconv作为主干部分继续进行n(n的取值为1、2、8、8、4)次残差块堆叠,即先经过一次1×1的卷积对通道数进行调整,再通过一次3×3的卷积加强特征提取,接着将其输出和小的残差边进行堆叠,再经过一次1×1的卷积将通道数调整为与Shortconv部分相同。最后,CSP DarkNet53将Shortconv和Mainconv进行堆叠。本文对卷积块所用的激活函数进行优化,将DarknetConv2D中的激活函数由Leaky ReLU换成Mish,即卷积块由DarknetConv2D_BN_Leaky变成DarknetConv2D_BN_Mish。
Mish是由DIGANTA M[24]提出的一种新颖的自正则非单调的神经网络激活函数,其主要特点是无上界、有下界、平滑和非单调。其中,“无上界”有效避免了梯度消失问题,“有下界”增强了网络正则化效果,“平滑”有利于神经网络提取更高级的潜在特征,从而获得更好的泛化能力,“非单调”可以保留更小的负输入从而提升网络的可解释能力和梯度流。Mish激活函数如式(2)所示:
Mish=x×tanh(ln(1+ex))
(2)
在对DarkNet53网络进行改进后,本文引入特征增强网络模块,从而进一步强化网络特征表示。
2.2 特征增强网络
空间金字塔池化(Spatial Pyramid Pooling,SPP)是HE等人[25]提出的一种解决输入神经网络不同图像尺寸问题的方法,其主要思想是将任意大小的特征图通过多尺度的池化操作,拼接成一个固定长度的特征向量。SPP能够产生固定大小的特征表示,无需限定输入图像的尺寸或比例,因此,其对于图像形变具有较好的鲁棒性。本文引入SPP结构以获取多尺度局部特征信息,并将其与全局特征信息进行融合得到更丰富的特征表示,进而提升预测精度。由于CSP DarkNet53网络已经进行了一系列的卷积和下采样,其全局语义信息十分丰富,因此为了进一步获取更多的局部特征,本文在CSP DarkNet53网络最后一个特征层的卷积中加入SPP结构,改进的SPP网络结构如图4所示。

图4 改进的空间金字塔池化网络结构
从图4可以看出,改进的SPP网络具体步骤为:首先,对13×13的1 024通道特征层进行3次卷积(DarknetConv2D_BN_Mish)操作;然后,利用3个不同尺度的池化层进行最大池化处理,池化核大小分别为13×13、9×9和5×5,步长均为1;最后,将输入的全局特征图和3个经池化处理后得到的局部特征图进行堆叠,并继续进行3次卷积操作。SPP结构可以大幅增加最后一个特征层的感受野,分离出最显著的上下文特征,从而获得更加丰富的局部特征信息。低层级特征层的细节和定位信息一般较为丰富,但随着特征层的逐渐深入,其细节信息不断减少,而语义信息不断增加,即越高层级特征层所包含的语义信息就越丰富。因此,在加入空间金字塔池化结构后,本文又结合特征融合策略对多尺度预测网络进行改进,通过自上而下和自下而上的融合策略[26]增强特征表示,进一步实现特征复用。改进的多尺度预测网络结构如图5所示。

图5 改进的多尺度预测网络结构
从图5可以看出,本文对多尺度预测网络的具体改进为:首先,通过CSP DarkNet53骨干网络提取得到3个有效特征层(52,52,256)、(26,26,512)和(13,13,1 024),并分别记为大尺度特征层(Large Feature Layer,LFL)、中尺度特征层(Medium Feature Layer,MFL)和小尺度特征层(Small Feature Layer,SFL);其次,先对SFL0进行3次卷积(Conv_3)、空间金字塔池化(SPP)后再进行3次卷积(Conv_3)得到SFL1,将SFL1进行一次卷积(Conv_1)和上采样(UpSampling)得到的结果与MFL0进行一次卷积(Conv_1)得到的结果进行融合得到MFL1,接着再将MFL1进行一次卷积(Conv_1)和上采样(UpSampling)得到的结果与LFL0进行一次卷积(Conv_1)得到的结果进行融合得到LFL1,进而完成自下而上的特征融合;然后,先对LFL1进行5次卷积(Conv_5)得到LFL2,将对LFL2进行下采样得到的结果与MFL1进行5次卷积(Conv_5)得到的结果进行融合得到MFL2,接着将MFL2继续进行下采样得到的结果直接与SFL1进行融合得到SFL2,进而完成自上而下的特征融合;最后,将3个初始有效特征层LFL0、MFL0和SFL0利用自下而上和自上而下的融合方式得到的LFL2、MFL2和SFL2分别进行5次卷积(Conv_5),然后输入YOLO Head中进行预测。其中,Conv_1表示进行一次大小为1×1的卷积处理,Conv_3和Conv_5的网络结构如图6所示。
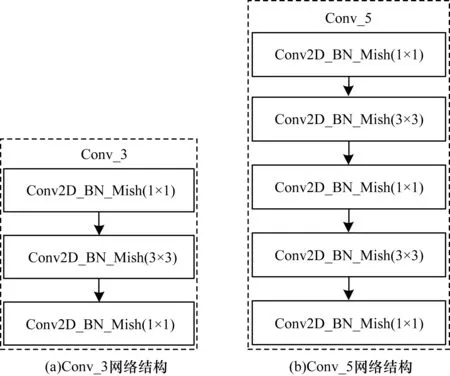
图6 Conv_3和Conv_5网络结构
从图5、图6可以看出,本文利用自上而下和自下而上的特征融合策略对多尺度预测网络进行改进,虽然在一定程度上提高了运算复杂度,但是其预测精度得到显著提升。
2.3 改进的损失函数
预测框与真实框的交并比(IoU)[27]是当前最常用的目标检测算法性能评估标准之一,其计算公式为:
(3)
其中,M=(x,y,w,h)表示预测框,N=(xgt,ygt,wgt,hgt)表示真实框。IoU虽然可以反映预测检测框和真实检测框的检测效果,但其仅能在边界框重叠时发挥作用,而对于非重叠部分,IoU不会提供任何调整梯度,即常用的先验框回归损失优化和IoU优化并非完全等价。针对该问题,本文引入CIoU[28]作为损失函数。CIoU考虑目标与检测框之间的中心点距离、重叠率以及长宽比信息,使得目标框回归更加稳定,解决了IoU在训练过程中出现的发散等问题。CIoU计算公式如下:
(4)
其中,m和n分别表示M(预测框)和N(真实框)的中心点,ρ2(m,n)表示预测框和真实框中心点的欧式距离,d表示能够同时包含预测框和真实框的最小闭包区域的对角线距离,α为权衡参数,β反映了长宽比的一致性。α和β的计算公式分别如下:
(5)
(6)
相应的损失函数为:
(7)
本文对骨干网络、特征增强网络、多尺度预测网络以及损失函数进行优化后,改进的YOLOv3整体结构如图7所示。

图7 改进的YOLOv3网络结构
3 实验结果与分析
3.1 数据集
由于目前没有公开的复杂场景人脸口罩佩戴数据集,本文从WIDER FACE、MAFA(Masked Faces)[29]和RMFD(Real-World Masked Face Dataset)[30]3种数据集中筛选提取6 000张人脸照片和4 000张人脸佩戴口罩照片,共包含416 968张人脸目标和103 576张人脸佩戴口罩目标,并对数据集进行手工标注。数据集示例如图8所示,RMFD是武汉大学于2020年3月免费开放的全球首个口罩遮挡人脸数据集,下载网址为https://github.com/X-zhangyang/Real-World-Masked-Face-Dataset。在图8(b)中,

图8 数据集标注示例
3.2 评价指标
本文通过以下指标[31]评价人脸佩戴口罩检测算法的性能:
1)查准率(Precision)和召回率(Recall):
(8)
(9)
其中,TP表示检测到的目标类别与真实目标类别一致的样本数量,FP表示检测到的目标类别与真实目标类别不一致的样本数量,FN表示真实目标存在但未被检测出的样本数量。
2)平均准确率(Average Precision,AP)和平均准确率均值(mean Average Precision,mAP):

(10)
(11)
其中,N表示所有目标类别的数量。在一般情况下,召回率的提升往往伴随着查准率的下降,为了更好地权衡两者,本文引入P-R曲线,P-R曲线下方的面积即为某类别的AP值。
3)检测速度:
检测速度是指目标检测网络每秒能够检测的图片数量(帧数),用FPS(Frames Per Second)表示。
3.3 结果分析
在Pycharm中编程实现本文算法,编程语言为Python3.6,深度学习框架为PyTorch1.2.0,实验硬件平台包括Intel®XeonTMW-2102 CPU@2.90 GHz处理器,以及GeForce RTX 2080ti GPU用于加速模型训练。在训练模型时,本文按照1∶9的比例划分测试集和训练集。模型训练方式采用Adam优化器对网络进行优化,共分为2个阶段:第1阶段将前249层冻结,仅对第250层~第369层进行训练,初始学习率设为0.001,batch_size为4,共训练50个轮次(epoch);第2阶段将前249层解冻后对所有层进行训练,batch_size为2,训练从第60个轮次开始,到第120个轮次结束。另外,在相同的实验环境下,使用相同的训练方式训练一个原始的YOLOv3网络模型用于分析比较。
3.3.1 YOLOv3与本文算法实验结果比较
YOLOv3和本文算法分别针对人脸目标和人脸佩戴口罩目标检测的P-R曲线如图9所示。

图9 YOLOv3和本文算法的P-R曲线对比
从图9可以看出,本文算法在人脸目标和人脸佩戴口罩目标检测中均取得了较好的性能。在人脸佩戴口罩目标检测中,YOLOv3只取得了80.5%的AP值,而本文算法的AP值高达95.4%,相比YOLOv3算法提高了约15个百分点。在人脸目标检测中,YOLOv3和本文算法的AP值分别为77.6%和84.9%,虽然本文算法的AP值与YOLOv3相比有一定程度的提升,但其仍低于人脸佩戴口罩目标检测时的AP值,这可能是由于YOLOv3本身作为一种通用目标检测算法,并非针对人脸提出的目标检测算法,人脸上的关键点特征信息较多,人脸佩戴口罩目标中人脸的一部分被口罩遮挡,相对完整的人脸而言,所需检测的特征信息明显减少,因此人脸佩戴口罩目标检测的识别精确度高于人脸目标检测。总体而言,本文改进的YOLOv3与原始YOLOv3相比检测精度更高。
为了进一步对检测效果进行分析比较,本文将检测目标分为大尺度目标(Large)、中尺度目标(Medium)和小尺度目标(Small),YOLOv3和本文算法对于3种尺度目标的检测结果如图10所示。从图10可以看出,YOLOv3对于大尺度目标、中尺度目标和小尺度目标检测的mAP值分别为85.7%、79.2%和72.4%,而本文算法在大尺度目标、中尺度目标和小尺度目标检测上的mAP值分别为96.4%、88.7%和85.5%,与YOLOv3相比,本文算法的mAP值分别提升了10.7个、9.5个和13.1个百分点。

图10 YOLOv3和本文算法对于3种尺度目标的实验结果对比
本文对复杂场景下的正常检测、遮挡检测、侧脸检测、密集人群检测和小尺度人脸检测5种情况,分别进行具体的检测效果示例展示,如图11~图15所示。

图11 正常人脸检测结果

图12 遮挡人脸检测结果

图13 侧脸检测结果

图14 密集人群检测结果

图15 小尺度人脸检测结果
从图11可以看出,对于正常人脸的检测识别,本文算法和YOLOv3均取得了较好的检测效果,两者都可以正确地识别出配戴口罩人脸和未佩戴口罩人脸,但在识别准确率上,特别是对于佩戴口罩人脸的识别准确率,本文算法相比YOLOv3有显著的性能提升。因此,后续本文主要对复杂场景中的佩戴口罩人脸检测效果进行分析,主要考虑复杂场景中遮挡、侧脸、密集人群以及小尺度人脸检测的情况。
从图12(a)可以看出,YOLOv3共检测出8个佩戴口罩人脸目标,最高预测准确率仅为93%,从图12(b)可以看出,本文算法共检测出13个佩戴口罩人脸目标,有6个检测框的预测准确率达到99%以上。
在图13的侧脸检测场景中,本文算法和YOLOv3同样取得了较好的检测效果,从图13(a)可以看出,YOLOv3共检测出10个佩戴口罩人脸目标,从图13(b)可以看出,本文算法共检测出15个佩戴口罩人脸目标,本文算法预测准确率也有显著提升。
从图14(a)可以看出,YOLOv3共识别出9个配戴口罩人脸目标,从图14(b)可以看出,本文算法共识别出16个佩戴口罩人脸目标,同时其预测准确率也有大幅提升,有半数以上检测框的预测准确率达到了95%以上。
从图15(a)可以看出,YOLOv3共检测出7个佩戴口罩人脸目标,从图15(b)可以看出,本文算法共检测出8个佩戴口罩人脸目标,同时预测准确率也有一定程度的上升。
综上,本文算法对于复杂场景下人脸佩戴口罩的检测效果明显优于YOLOv3算法。
3.3.2 本文算法与其他算法比较
为了进一步验证本文算法的有效性,将该算法与其他算法的性能进行比较,结果如表1所示。

表1 4种算法的性能比较结果
在表1中,Face指人脸目标检测的平均准确率,Face_Mask指人脸佩戴口罩目标检测的平均准确率。
从表1可以看出,对于人脸佩戴口罩目标检测而言,本文算法取得了较好的检测效果,与RetinaFace算法和Attention-RetinaFace算法相比,其AP值分别提升了18.9%和10.7%,mAP值分别提升了8.3%和2.5%。但是,对于人脸目标检测而言,RetinaFace算法和Attention-RetinaFace算法的AP值明显更高,原因是这2种算法均是专门用于人脸定位的单阶段检测算法,基于人脸对齐、像素级人脸分析和人脸密集关键点三维分析来实现多尺度人脸检测,因此,它们的检测精度更高。而同为单阶段检测算法,YOLOv3虽然对于通用目标有较高的检测精度和效率,但对于人脸这种特征信息丰富且复杂的目标而言,其性能低于专业的人脸检测算法。本文算法是基于YOLOv3的算法,虽然其人脸目标检测的AP值略低于RetinaFace算法和Attention-RetinaFace算法,但高于原始YOLOv3算法,而且本文算法的FPS相比RetinaFace算法和Attention-RetinaFace算法分别提升了20.1和19.7。总体而言,本文算法能在一定程度上提升复杂场景下人脸佩戴口罩的目标检测效果。
3.3.3 消融实验结果及分析
消融实验是深度学习领域中常用的实验方法,主要用来分析不同的网络分支对整个模型的影响[16]。为了进一步分析改进算法对于YOLOv3模型的影响,将本文算法裁剪成5组分别进行训练,第1组为原始的YOLOv3,第2组为特征提取网络结构改为CSP DarkNet53的YOLOv3,第3组在第2组的基础上加入改进的空间金字塔池化,第4组在第3组的基础上加入路径聚合网络,第5组在第4组的基础上使用损失函数CIoU,即第5组为本文算法。5组消融实验结果如表2所示,其中,“√”表示包括该结构,“×”表示未包括该结构。

表2 消融实验结果对比
从表2可以看出:对于第1组实验,原始YOLOv3在人脸目标检测和人脸佩戴口罩目标检测上的AP值分别为77.6%和80.5%,其mAP值为79.1%,FPS为32;对于第2组实验,由于引入了跨阶段局部网络,人脸目标检测和人脸佩戴口罩目标检测的AP值相对第1组分别提高了1.2%和3.2%,mAP值提高了2.2%,同时检测速度增加了3FPS,原因是跨阶段局部网络增强了卷积网络的学习能力,消除了大部分的计算瓶颈结构并降低了内存消耗,从而提高了推理速度和准确性;对于第3组实验,由于其在第2组的基础上加入了改进的空间金字塔池化结构,虽然FPS相比第2组降低了1,但各类AP值均有提升,特别是人脸佩戴口罩目标检测的AP值提升了约4个百分点,mAP值比第2组高出近3个百分点,这说明改进的空间金字塔池化结构能够提升模型性能;对于第4组实验,由于其在第3组的基础上加入了路径聚合网络,各类AP值以及mAP值又取得了一定程度的提升,这是因为该组在3个有效特征层中加入了自下而上的融合路径,从而进一步提升了预测网络的检测效果;第5组实验即本文算法,其在第4组的基础上改进了损失函数,选取CIoU替换IoU,mAP值相对于第4组提升了1.3%,特别是与原始YOLOv3相比,本文算法整体性能均有显著提升,同时也取得了更好的实时效果,其检测速度增加了6FPS。综上,本文针对YOLOv3的改进策略能够提升复杂场景下的人脸佩戴口罩检测效果。
4 结束语
为解决复杂场景下人脸口罩佩戴检测任务中存在的遮挡、密集人群和小尺度目标等问题,本文提出一种改进的YOLOv3算法。为减少网络计算消耗并提高训练速度,引入跨阶段局部网络,对DarkNet53进行改进以构造CSP DarkNet53网络。引入改进的空间金字塔池化结构,通过自上而下和自下而上的特征融合策略优化多尺度预测网络,从而实现特征增强。将IoU损失函数替换为CIoU损失函数,充分考虑目标与检测框之间的中心点距离、重叠率以及长宽比等信息。实验结果表明,该算法可以有效提升复杂场景下口罩佩戴检测的精度和速度,平均准确率达到90.2%,检测速度达到38FPS。由于本文所选数据集均来自理想光照环境,因此下一步将考虑光照变化等因素以扩充数据集,同时对网络结构进行优化和改进,以构造性能更优的轻量级网络结构用于模型训练,从而提升检测模型的准确性和实时性。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
意林(2020年9期)2020-06-01 07:26:22
海峡姐妹(2020年4期)2020-05-30 13:00:08
作文大王·笑话大王(2019年3期)2019-04-22 23:58:02
动漫星空(2018年9期)2018-10-26 01:17:14
作文评点报·低幼版(2017年8期)2017-03-11 20:44:08
太空探索(2016年5期)2016-07-12 15:17:55
发明与创新(2015年33期)2015-02-27 10:40:09
时代英语·高三(2014年5期)2014-08-26 17:01:17
