
基于多模态融合的人脸反欺骗技术
2020-11-13 08:57穆大强
图学学报 2020年5期
穆大强,李 腾
(安徽大学电气工程与自动化学院,安徽 合肥 230601)
近年来,人脸识别系统被广泛应用在各种场合,例如上班打卡考勤、小区门禁等。然而,在传统的人脸识别系统中存在着较大的安全隐患。主要是因为其不能识别摄像头获取到的人脸区域图像究竟是来自真实的人脸还是攻击类型的人脸(如人脸照片攻击、人脸视频攻击、人脸合成攻击等)。因此如何阻止这种恶意身份欺骗是人脸识别过程中一项关键的技术。
为了解决上述人脸欺骗的问题,人脸反欺骗技术应运而生。与传统的人脸识别系统相比,加入人脸反欺骗的系统更具安全性。回顾现有的人脸反欺骗手段可分为3类:①基于手工特征的人脸反欺骗方法,该方法是人脸反欺骗早期常用的手段。其主要使用到的手工特征有:HOG[1-2],LBP[3-5],DoG[6-7],SIFT[8]和SURF[9]等,再利用支持向量机(support vector machine,SVM)进行分类[10-11]。②基于卷积神经网络(convolutional neural network,CNN)的人脸反欺骗方法,该方法中CNN被用作特征提取器[11],再使用SVM进行分类。③基于深度信息的人脸反欺骗方法,其主要通过提取人脸的深度信息[12-13]来进行分类。
上述方法中多为使用单一面部特征进行决策,因此获得的模型鲁棒性有待提高。为了尽可能提升人脸反欺骗模型的鲁棒性,本文提出融合多种模态人脸活性特征的方法。即通过融合不同颜色空间(HSV与YCbCr)与时序上人脸活性特征来提升模型的鲁棒性。为了验证多模态融合方法的有效性,本文利用REPLAY_ATTACK和CASIA-FASD 2个基准数据集来测试模型的性能。与先前的工作相比较,该方法具有以下创新与贡献:
(1) 设计了一种新颖的多输入CNN结构,融合多种模态上的人脸特征,以提升人脸反欺骗模型的鲁棒性。
(2) 从基于人脸图像的多色彩空间以及用于面部反欺骗的时序信息中自动学习最佳特征表示。
(3) 在2个基准数据集上实现了最先进的性能。
1 基于多模态融合的人脸反欺骗方法
从提取不同模态上人脸特征为出发点,展开了多模态融合的人脸反欺骗方法的探索,通过提取多种模态上人脸特征并融合以提升人脸反欺骗的鲁棒性。包括:不同颜色空间(YCbCr与HSV)上完整人脸与局部人脸patch制作、时序图制作、不同模态上特征提取与融合和多级水平特征联合的决策网络构建。最后,通过大量实验证明该方法的有效性。
1.1 多模态数据制作
1.1.1 颜色空间上数据的制作
在HSV与YCbCr颜色空间上制作了2种不同的人脸图像:完整的人脸图像和局部人脸patch图像。使用局部人脸的patch图像的原因如下:
(1) 为了增加CNN学习训练样本的数量和解决训练过程中可能出现的过拟合现象,对于所有可用的人脸反欺骗数据集,仅有限数量的样本可用于训练。例如,CASIA-FASD仅采集20个人的真假面孔,每个人有12个短视频。即使可以从每个视频中提取数百张面孔,由于跨帧的高度相似性,在CNN学习时,模型容易出现过拟合现象。
(2) 当使用全脸图像作为输入时,传统的CNN由于脸部图像分辨率的变化而需要调整脸部的大小,由于缩放比例的变化可导致判别信息的减少。相反,使用局部人脸patch图像可以保持面部图像的原始分辨率,从而保留判别能力。
(3) 假设欺骗特有的区分性信息在空间上存在于整个面部区域中,则patch级别的输入可以强制CNN发现此类信息,从而更有效地学习到人脸中有鉴别力特征。
对于完整人脸图像的获取。
(1) 利用人脸检测器MTCNN[14]获取到视频中RGB颜色空间上的人脸图像,同时,可以得到5个人脸关键点,利用这5个关键点对人脸进一步地校正,以降低人脸姿态的影响。可利用仿射变换将检测到的人眼关键点旋转至同一水平位置,使得2个眼睛中心点到两嘴角中心点的距离是24个像素,且2个眼中心点的Y轴坐标是24像素,将人脸区域大小缩放至128×128。校正前后的人脸区域图像对比如图1所示。

图1 校正前后人脸对比Fig. 1 Face comparison before and after alignment
(2) 通过调用opencv工具将RGB颜色空间转换到HSV与YCbCr颜色空间上。
对于局部人脸的patch图像获取,一种简单而有效的方式为将得到的完整人脸图像进行随机的裁剪,得到2组数量为10,大小分别为72×72和56×56的人脸patch图像,如图2所示。
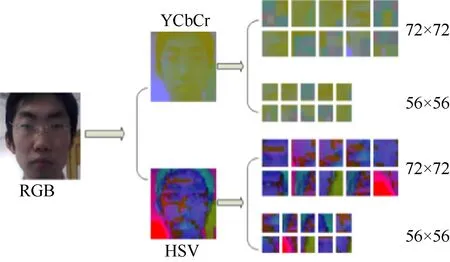
图2 不同颜色空间上的完整人脸图像与patch图像Fig. 2 Complete face image and patch image in different color spaces
1.1.2 时序图数据制作
利用视频序列中图像帧间时间信息的策略。首先将3幅不同时间位置的彩色图像转换成3幅灰度图像,然后将灰度图像作为一个整体叠加得到时序图,并将时序图输入到CNN中学习人脸特征。图3为3幅灰度图像叠加的示例(也可采用多幅图片进行叠加,此处以3幅图片为代表说明该方法)。

图3 时序图制作过程Fig. 3 Temporal images production process
1.2 网络设计
网络设计分为融合网络和决策网络2部分,融合网络用于提取各模态上的特征,并进行融合得到深度特征。最后将深度特征输入到决策网络中进行最终的预判。
1.2.1 融合网络设计
融合网络的设计是根据特征图可视化的效果所设计,其包含5个卷积层,一个最大池化层,而且每个卷积层后均跟着BatchNorm层与Relu层。图4描述了融合过程。
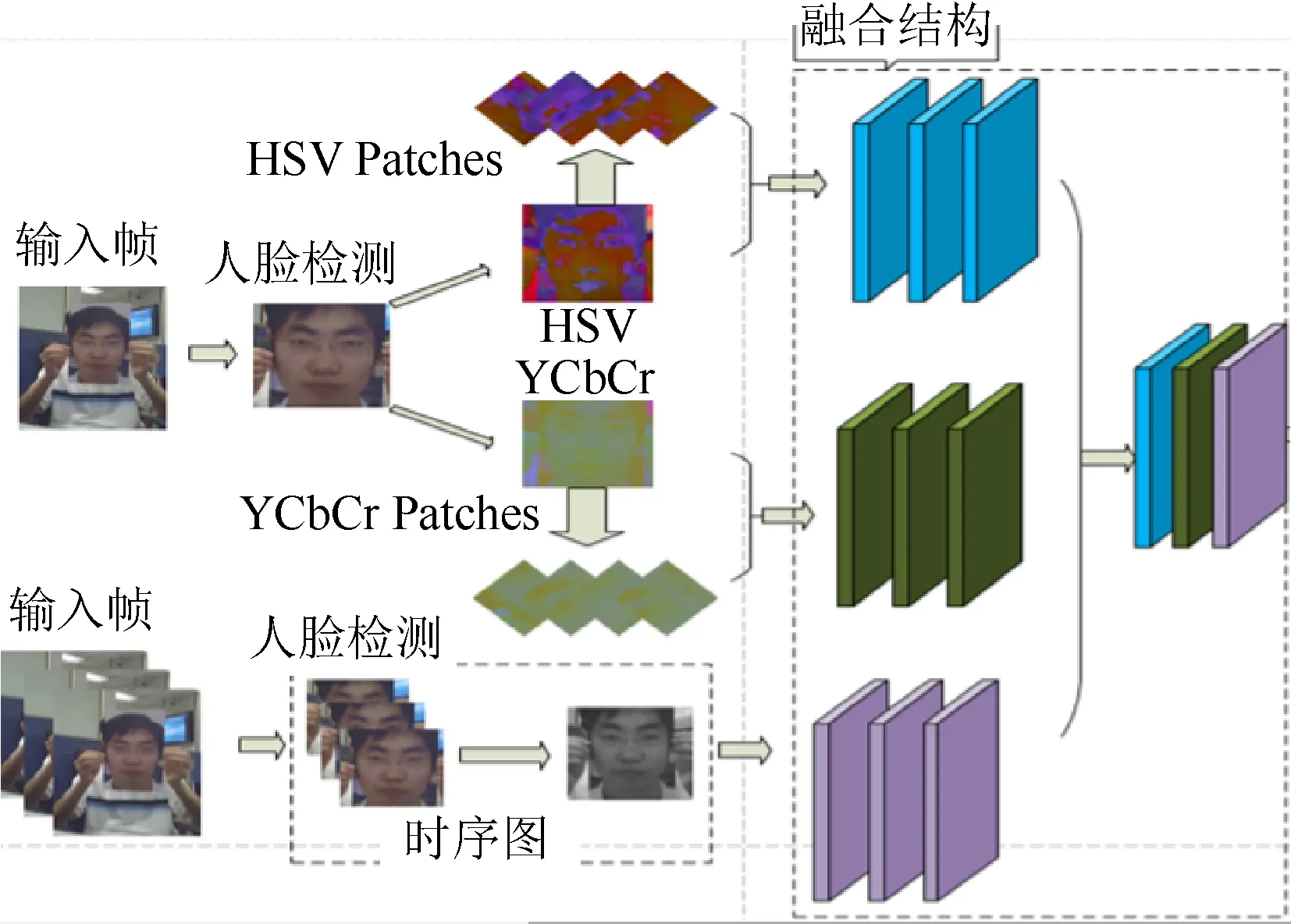
图4 多模态特征融合过程Fig. 4 Multi-modal feature fusion process
为了展示融合网络的细节,表1介绍了融合网络的参数设置。
由表1可知,第4层卷积核的大小为1×1,之所以使用1×1的卷积核,主要考虑以下3个作用:
(1) 将特征图的数量进一步地扩展到144。
(2) 使用1×1的卷积层替换到全连接层,可不限制输入图片大小的尺寸,使网络更灵活。
(3) 实现跨通道的交互和信息整合,提高网络的表达能力。
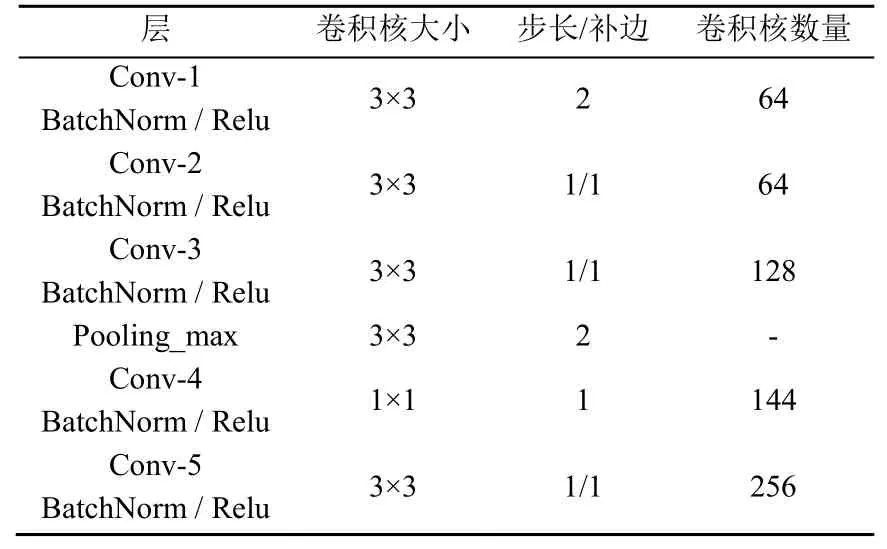
表1 融合网络细节展示Table 1 Fusion network details display
其他4个卷积层使用3×3卷积核。这是由于较小的滤波器会揭示输入图像的更多详细信息,因此使用3×3代替较大的卷积核。在前2层中,使用了内核大小为3×3的64个过滤器,这是最低的。对于第3层,过滤器的数量增加了一倍,达到128个。此外,ReLU封装在每个级别,以加快网络训练速度,且提高了其性能以实现更快的收敛。
1.2.2 决策网络设计
决策网络的设计用于对输入深度特征图做出最终的判断。其借鉴了inception结构的思想,包含了3种不同水平的特征,即高水平、中水平和低水平特征,通过联合3种不同水平的特征进行决策。之所以要融合不同水平的特征,是因为人脸反欺骗是一种特殊的细粒度图像识别任务,网络应该更多地关注图像的细节。3个级别的特征融合可以提供更详细的特征,从而提高模型性能。具体网络结构设计见表2。
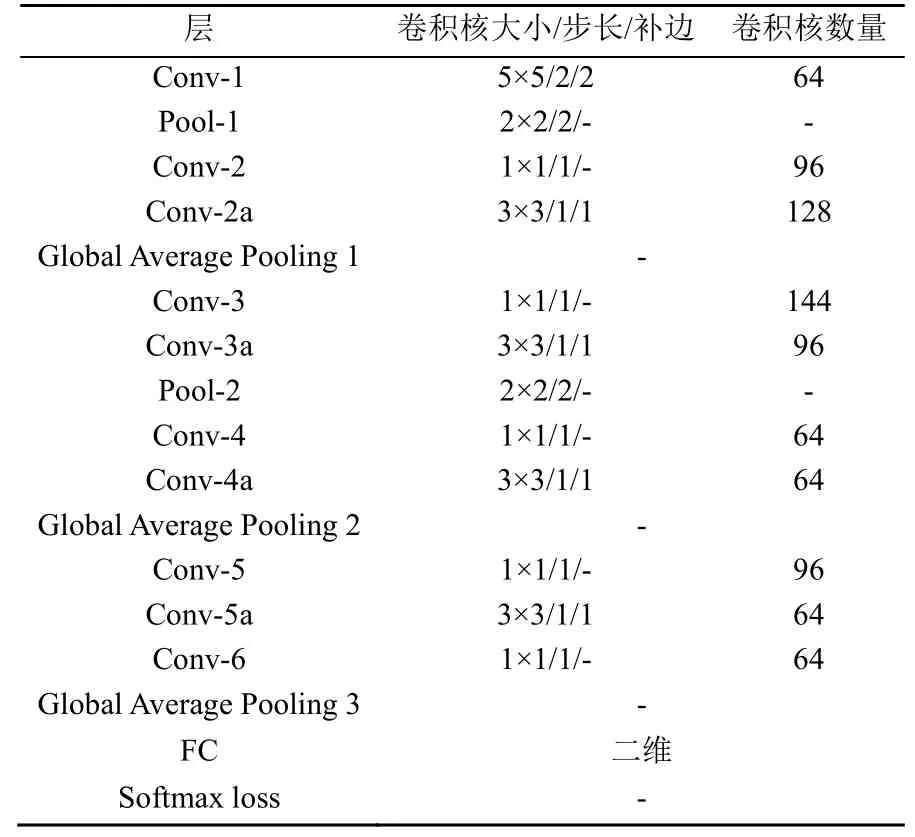
表2 决策网络细节展示Table 2 Decision network details
在表2中,将Lobal Average Pooling 1之后Conv-3之前的特征称为低水平特征,将Lobal Average Pooling 2之后Conv-5之前的特征称为中水平特征,将Lobal Average Pooling 3之后FC之前的特征称为高水平特征,联合这3种不同水平的特征经过全连接FC得到一个二维的特征向量,最后经过Softmax函数得到分类概率。图5展示了利用决策网络进行分类的过程。

图5 融合不同水平特征的决策网络Fig. 5 Decision network combining different levels of features
在整个决策网络的设计中,对原有的残差网络进行了改进。残差结构是被HE等[15]提出用来解决深度网络在训练时出现梯度爆炸、梯度弥散等问题。残差网络对模型的准确有了大幅度的提高,其残差模块设计如图6所示,主要利用恒等映射连接来解决深度网络中出现的梯度消失的问题。

图6 残差网络改进对比Fig. 6 Comparison of residual network improvement
2 实验设计与结果分析
为保证评估的公平性与客观性,本文使用人脸反欺骗方法中最常用的2个评价指标(ERR与HTER)进行评测,在2个基准数据集上(REPLAY_ATTACK与CASIA-FASD)对所提出的模型进行了验证。
REPLAY_ATTAC数据集:其包含50个采集对象,共有1 300个活体与假体视频。对于数据集中的每个采集对象,均在2种光照条件下录视频。每个对象在2种环境下收集了4个活体视频序列。假体序列则是在固定支持攻击(攻击设备设置在固定支架上)和手持条件(攻击设备由操作员持有)下捕获的。攻击类型分为打印攻击、移动攻击和高清晰度攻击3种,所有视频集被划分为训练集(15个采集对象),开发集(15个采集对象)和测试集(20个采集对象)。
CASIA-FASD数据集:包含600个视频,共50个采集对象,每个采集对象采集了12个视频(3个真实视频和9个欺骗视频)。每个主题包含3种不同的欺骗攻击:视频攻击、扭曲照片攻击和剪切照片攻击。该数据集中训练集包括20个采集对象和测试集包括30个采集对象。
以下介绍2个评价指标的具体定义:
ERR:是分类错误的样本数占样本总数的比例。对样例集D,分类错误率为
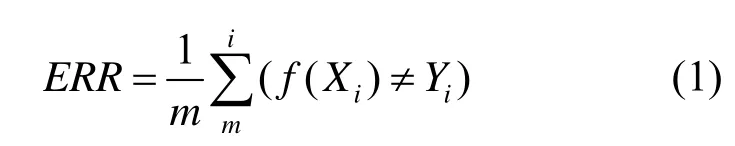
其中,统计分类器预测出的结果与真实结果不相同的个数,然后除以总的样例集D的个数。
HTER:是衡量人脸活体检测性能的重要指标,其计算式为
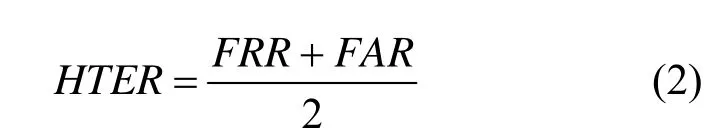
其中,FRR为错误拒绝率,是把真实面孔分类为假面孔;FAR为错误接受率,是把假面孔分类为真实面孔。
实验软硬件环境、损失函数及模型训练设置如下:
软硬件设置:Mxnet框架;CPU为E5-2620 V3;内存64 G;GPU为GTX TITAN X (12 G)。
损失函数:损失函数采用的是softmax loss,其表达式为
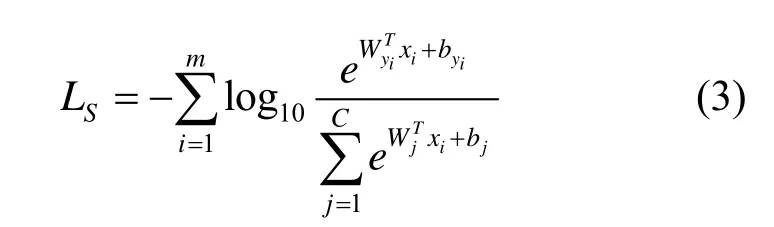
其中,Wj为网络最后一个全连接层的权重W的第j列;b为偏置项。
模型训练设置:在训练网络时,使用随机梯度下降的方式(stochastic gradient descent,SGD)去更新网络中每层的权重。在本次训练中,由于数据量较大,所以在设置初始学习率时选择为0.1,并且每20个epoch降低50%的学习率。经过6次学习率降低后,网络达到最优化。
2.1 多颜色空间特征实验
对于不同的颜色空间上提取的人脸活性特征,在人脸反欺骗模型的性能上有着较为显著的差异。RGB是用于传感,表示和显示彩色图像的最常用的色彩空间。但是,由于3种颜色成分(红色、绿色和蓝色)之间的高度相关性以及亮度和色度信息的不完美分离,其在图像分析中的应用受到了很大的限制。还需考虑除RGB外的另外HSV和YCbCr 2个颜色空间上人脸活性信息。
首先在CASIA-FASD数据集上进行实验,将该数据集中的训练集作为训练样本,并在测试集进行性能测试,统计测试集错误率。表3记录了3种颜色空间上进行人脸反欺骗的实验结果。从表3中可看出,当实验使用单一的颜色空间特征进行人脸反欺骗时,HSV与YCbCr颜色空间的模型性能要优于RGB颜色空间。最后实验进一步地融合HSV与YCbCr颜色空间特征以提升模型的性能,结果显示融合后的特征更具有鉴别力。

表3 不同颜色空间上人脸活体检测错误率对比(%)Table 3 Comparison of error rate of face liveness detection in different color spaces (%)
此外其他颜色空间也被用来进行人脸活体检测,并尝试融合更多颜色空间进行人脸反欺骗,实验结果见表4。由表4可知,在Lab颜色空间上提取人脸特征进行人脸反欺骗时,其错误率为5.47%;当融合RGB,HSV和YCbCr 3种颜色空间时,错误率虽有下降,但模型速度下降明显,若在不考虑检测速度的前提下,可通过融合更多颜色空间上的特征来提升模型的精度。
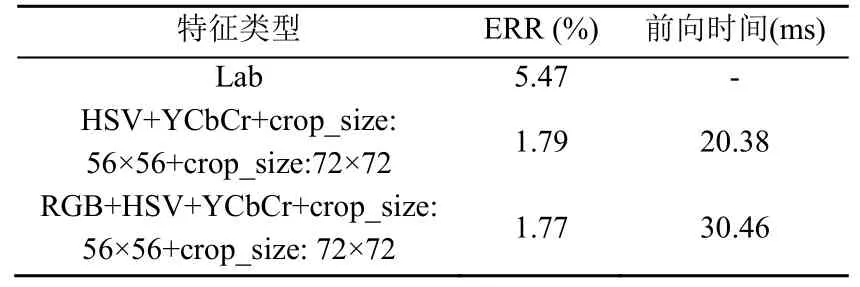
表4 其他颜色空间与多颜色空间融合对比试验Table 4 Contrast test of fusion between other color spaces and multi-color spaces
2.2 时序特征实验
表5为在数据集CASIA-FASD上执行融合时序特征的实验结果。为融合时序特征时,模型的错误率从1.79%降低到1.76%,表明模型的性能得到了进一步提升。其次,时序特征也可单独用于人脸反欺骗,其错误率为5.23%,远超YCbCr和HSV颜色空间上的实验错误率。导致此结果的原因:可能是由于数据集中前后帧间的相似性较高,所以堆叠过后的时序图没有包含丰富的动态特征,以至于实验结果显得差强人意。但是,通过比较表3,时序特征要比在RGB颜色空间上的特征更具有鉴别力,因此,本文决定融合时序特征以进一步优化模型的性能。

表5 时序特征实验(%)Table 5 Time series characteristic experiment (%)
2.3 不同水平特征融合实验
在决策网络中融合了高、中、低3种水平特征进行预判,主要是由于人脸反欺骗是一种特殊的细粒度图像识别任务,所以网络应较多地注重图像的细节。联合3个级别的特征可以提供更详细的人脸信息,从而提高模型性能。为了证明这一点,本文进行了不同水平特征融合实验(表6)。由表6可知,在联合3种水平特征后模型性能达到最优化。

表6 不同水平特征融合对比实验(%)Table 6 Contrast test of feature fusion at different levels (%)
2.4 多指标测试与对比
REPLAY_ATTACK也是一个具有挑战性的人脸反欺骗数据库,该方法同样在其上进行性能测试。除了测试错误率之外,另外一个重要评判指标HTER也被测试记录。
表7为近年来具有代表性的人脸反欺骗方法及其错误率。表8展示了各个方法的半错误率,与之相比,本文所提出的多模融合的方法取得了非常具有竞争力的结果。

表7 在错误率上的对比(%)Table 7 Comparison of error rates (%)
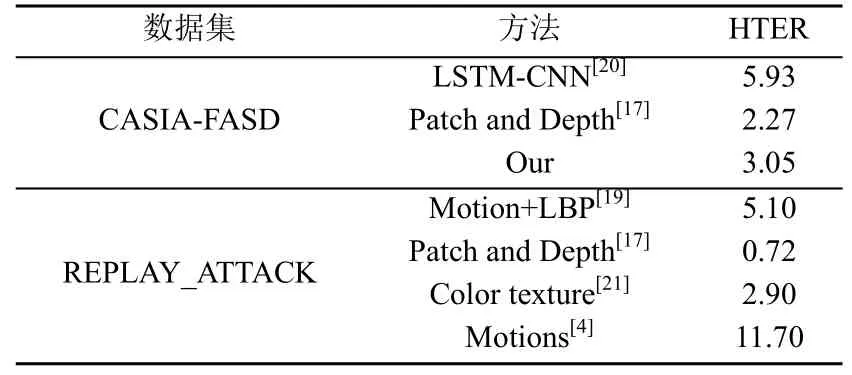
表8 半错误率对比(%)Table 8 Comparison of half error rate (%)
2.5 泛化能力测试
为了深入了解多模融合人脸反欺骗方法的泛化能力,本文进行了跨数据库的评估。在此实验中,利用一个数据库对网络进行训练,然后在另一个数据库上进行了测试。实验结果见表9。
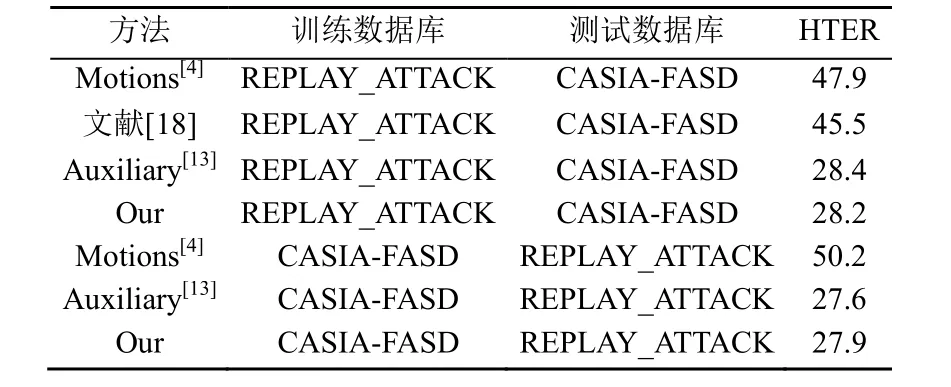
表9 跨数据库实验结果及方法对比(%)Table 9 Cross-database experiment results and method comparison (%)
在REPLAY_ATTACK数据集上优化的模型略微优于基于CASIA-FASD数据集上优化的模型。其原因可能是,与REPLAY_ATTACK数据库相比,CASIA-FASD数据集在收集的数据中包含更多的变化(如,成像质量和相机与人脸之间的接近度)。因此,针对重放攻击数据库优化的模型在新的环境条件下表现略显逊色。不过可以通过联合2个数据库的训练集进行训练网络,以使模型拥有更好的泛化能力。
3 小 结
本文提出了一种基于多输入CNN的新型人脸反欺骗技术。CNN被用于从时序图和2个颜色空间中学习区分性的多个深度特征,以防止面部欺骗。由于这些类型的特征彼此互补,因此进一步提出了一种将所有模态特征融合在一起以提高性能的策略。在2个最具挑战性的面部反欺骗基准数据库中评估了该方法,实验结果证明,该方法优于先前的面部防欺骗技术。另外,由2个数据库间评估表明,本文所提出的方法具有良好的泛化能力。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
小猕猴智力画刊(2022年3期)2022-03-28
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
铁道建筑技术(2020年11期)2020-05-22
新课程·上旬(2019年1期)2019-03-18
动漫星空(2018年9期)2018-10-26
电子制作(2017年13期)2017-12-15
教师·中(2017年3期)2017-04-20
试题与研究·教学论坛(2016年27期)2016-08-11
