
使用面向目标的语义探索进行对象目标导航
2020-11-12 09:40
机器人产业 2020年4期


对于在不可见的环境中导航到给定对象类别的任务,使用基于端到端学习的导航方法是很难实现的。因此,来自卡内基梅隆大学的Devendra Singh Chaplot、Ruslan Salakhutdinov,来自Facebook人工智能研究实验室的Dhiraj Gandhi,以及卡内基梅隆大学机器人研究所副教授兼Facebook人工智能研究实验室科研管理Abhinav Gupta提出了“面向目标的语义探索”模块系统。该模型在CVPR 2020 Habitat ObjectNav挑战赛上获得了优胜。
本研究探索了对象目标导航的问题,该问题涉及在不可见的环境中导航到给定对象类别实例。基于端到端学习的导航方法在这个任务上很困难,因为它们在探索和长期规划方面效率低下。我们提出了一个模块系统,称为“面向目标的语义探索”,它构建了一个情景语义地图,并根据目标对象类别使用它来有效地探索环境。在视觉上逼真的仿真环境中的实证结果显示,所提出的模型性能优于许多不同的本研究探索了对象目标导航的问题,该问题涉及在不可见的环境中导航到给定对象类别实例。基于端到端学习的导航方法在这个任务上很困难,因为它们在探索和长期规划方面效率低下。我们提出了一个模块系统,称为“面向目标的语义探索”,它构建了一个情景语义地图,并根据目标对象类别使用它来有效地探索环境。在视觉上逼真的仿真环境中的实证结果显示,所提出的模型性能优于许多不同的基线,包括基于端到端学习的方法以及基于模块化地图的方法。消融分析表明,该模型学习了场景中对象相对排列的语义先验,并使用它们进行了有效的探索。与领域无关的(domain-agnostic)模块设计使我们能够将该模型迁移到移动机器人平台上,并在现实世界中实现类似的目标导航性能。
引言
自主導航是构建能够体现智能体智能性的核心要求。假设一个自主智能体被要求在不可见环境中导航到“餐桌”(如图1所示)。在语义理解方面,该任务不仅涉及到对象检测,即“餐桌”是什么样子的,而且涉及到场景理解,即“餐桌”在哪里更容易被找到。后者需要长期的情景记忆,也需要学习场景中对象相对排列的语义先验(semantic prior)。长期的情景记忆使智能体能够记录已探索和未探索的区域。学习语义先验使智能体能够使用情景记忆来决定下一步要探索哪个区域,以便在最短的时间内找到目标对象。
我们如何设计一个计算模型来建立情景记忆,并基于语义先验有效地使用它,以便在不可见的环境中高效地导航。一种流行的方法是通过循环神经网络使用端到端强化或模仿学习来建立情景记忆,并隐性地学习语义先验[1,2,3,4]。然而,基于端到端学习的方法存在样本复杂度大、泛化能力差的问题,因为它们会记忆对象在训练环境中的位置和外观。
最近,《学习探索使用主动神经SLAM》[5]中推出了一个基于模块化学习的系统,称为“主动神经SLAM”(Active Neural SLAM),该系统可以构建显性的障碍地图来维持情景记忆。显性地图还使分析路径规划成为可能,从而大大提高了探索和样本的复杂性。然而,旨在使探索覆盖面最大化的主动神经SLAM并没有在情景记忆中进行语义编码,因此也没有学习语义先验。在本文中,我们扩展了主动神经SLAM系统,以构建显性的语义地图,并使用语义感知的长期策略学习语义先验。
我们所提出的方法称为“面向目标的语义探索”(Goal-Oriented Semantic Exploration,SemExp)。与《学习探索使用主动神经SLAM》[5]相比,该方法进行了两个改进,以处理语义导航任务。首先,它构建了类似于《学习探索使用主动神经SLAM》[5]中自顶向下的度量映射,但是添加了额外的通道来显性地对语义类别进行编码。我们没有像该研究[5]中那样直接从第一人称图像(first-person image)预测自顶向下的映射,而是使用第一人称预测,然后进行可区分的几何投影。这使我们能够利用现有的经过预训练的对象检测和语义分割模型来构建语义地图,而不是从头开始学习。其次,我们没有使用仅基于障碍地图的覆盖面最大、目标不确定的探索策略,而是训练了一个面向目标的语义探索策略,该策略可以学习语义先验以实现高效的导航。这些改进使我们能够处理具有挑战性的对象目标导航任务。我们在视觉上逼真的仿真环境中进行的实验表明,SemExp的性能显著优于先前的方法。我们所提出的模型还赢得了CVPR 2020 Habitat ObjectNav挑战赛3。
相关研究
下面我们将简要讨论语义地图和导航的相关研究。
语义地图。有大量研究使用来自运动和即时定位与地图构建(Simultaneous Localization and Mapping,SLAM)的结构来构建2D和3D的障碍地图[6,7,8]。我们请感兴趣的读者参阅Fuentes-Pacheco等人[9]关于SLAM的调查。一些更相关的研究使用概率图模型(probabilistic graphical model)[10]或使用最近的基于学习的计算机视觉模型[11,12]在地图中加入语义。与这些研究不同的是,我们使用可区分的投影操作来学习地图空间中带有监督的语义地图。这限制了由于第一人称语义预测的小误差而造成的地图中的大误差。
导航。经典的导航方法使用显性的几何地图通过路径规划来计算到达目标位置的路径[13,14,15,16]。目标的选择是基于启发式方法的,如基于前沿的探索算法(Frontier-based Exploration algorithm)[17]。与此不同,我们使用基于学习的策略,根据对象目标类别,使用语义先验选择探索目标。
最近的基于学习的方法使用端到端强化或模仿学习来训练导航策略。这些方法包括使用循环神经网络[1,18,19,20,21,22,23,24]、结构化空间表征[2,25,26,27,28]和拓扑表征[29,30]。最近处理对象目标导航的研究包括[31,32,33,4]。Wu等人[31] 试图通过在语义信息(如房间类型)上构建概率图模型来探索环境之间结构的相似性。类似地,Yang等人[32]提出使用图卷积网络(Graph Convolutional Network)将语义先验加入深度强化学习框架。Wortsman等人[33]提出了一种元强化学习(meta-reinforcement learning)方法,在这种方法中,智能体学习自监督的交互损失(self-supervised interaction loss),从而鼓励有效的导航,甚至在测试环境中持续学习。Mousavian等人[4]使用在输入观测上运行先进的计算机视觉算法所获得的语义分割和检测掩膜,并使用深度网络在此基础上学习导航策略。在上述方法中,学习的表征都是隐性的,而且模型需要从目标驱动的奖励中隐性地学习避障、情景记忆、规划和语义先验。对于不同的导航任务,显性地图表征已经被证明比基于端到端学习的方法提高了性能和样本效率[5,34],然而它们是隐性地学习语义的。在本研究中,我们使用显性的结构化语义地图表征,这使我们能够学习语义感知的探索策略并处理对象目标导航任务。同时进行的研究考察在学习探索策略中使用类似的语义地图来改进对象检测系统[35]。
方法论
对象目标任务的定义。在对象目标任务[20,36]中,目标是导航到给定对象类别的实例,如“椅子”或“床”。智能体在环境中的一个随机位置进行初始化,并接收目标对象类别作为输入。在每个时间步骤,智能体接收视觉观测和传感器姿态读数,并采取导航操作。该视觉观测由第一人称和深度图像组成。动作空间由四个动作组成:向前移动、向左转、向右转、停止。当智能体认为它已经接近目标对象时,它需要执行“停止”动作。如果到目标对象的距离小于某个阈值,,当智能体执行“停止”动作时,那么该情景被认为是成功的。在固定的最大时间步值(=500)之后,该情景终止。
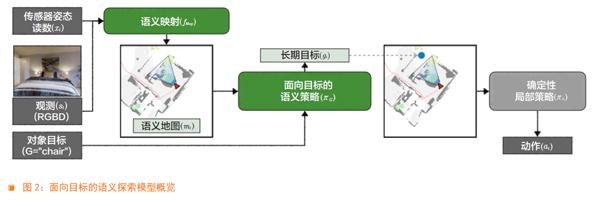
概述。我们提出了一个模块化模型,称为“面向目标的语义探索”(Goal-Oriented Semantic Exploration,SemExp),以处理对象目标导航任务(概览如图2所示)。它由两个可学习的模块组成,即“语义映射”(Semantic Mapping)和“面向目标的语义策略”(Goal-Oriented Semantic Policy)。语义映射模块随着时间推移构建语义地图;面向目标的语义策略根据语义地图选择长期目标,以高效地达到给定的对象目标。基于分析规划器(analytical planner)的确定性局部策略被用于执行低层次导航动作,以达到长期目标。我们首先对我们的模型所使用的语义地图表征进行描述,然后对各模块进行描述。
语义地图表征。SemExp模型在内部维持了语义度量映射和智能体的位姿。空间地图是一个矩阵,其中表示地图的大小,该空间地图中的每个元素对应物理世界中大小为25cm2 (5cm×5cm)的单元。为语义地图中的通道数,其中为语义类别的总数。前两个通道代表障碍和探索区域,其余通道分别代表一个对象类别。通道中的每个元素都代表对应的位置是障碍、已探索或者包含对应类别的对象。在一个情景开始时,地图被初始化为所有都是0,。姿态 表示该智能体在时刻的x、y坐标和方向。该智能体总是从地图的中心开始,在情景开始时朝向东,。
语义映射。为了构建语义地图,我们需要对在视觉观测中看到的对象的语义类别和分割进行预测。最好使用现有的对象检测和语义分割模型,而不是从头开始学习。主动神经SLAM(Active Neural SLAM)模型直接从的观测预测自顶向下的映射,因此,该模型没有任何机制来整合预训练的对象检测或语义分割系统。相反,我们在第一人称视角中预测语义分割,并使用可区分的投影将第一人称预测转换为自顶向下的映射。这使我们能够使用现有的预训练模型进行第一人称语义分割。然而,第一人称语义分割中的小误差会导致投影后的地图出现大误差。我们通过在第一人称空间之外增加地图空间的损失来克服这一限制。
图3是语义映射模块的概览。深度观测被用于计算点云。点云中的每个点都与预测的语义类别相关联。使用预训练的Mask RCNN[37]在观测上对语义类别进行预测。然后使用可区分的几何计算将点云中的每个点投影到3D空间中,以获得体素表征。再将体素表征转换为语义地图。将所有障碍、所有单元和每个类别的体素表征的高度维度相加,得到投影语义地图的不同通道。然后使该投影语义地图通过去噪神经网络,得到最终的语义地图预测。如《学习探索使用主动神经SLAM》[5]所述,该地图使用空间转换(spatial transformation)和通道智慧池化(channel-wise pooling)的方法随着时间聚合。在语义分割和语义地图预测上,使用带有交叉熵损失(crossentropy loss)的有监督学习方法训练该语义映射模块。该几何投影是使用可区分的操作实现的,这样一来,如果需要的话,在语义地图预测上的损失可以反向传播到整个模块。
面向目标的语义策略。面向目标的语义策略根据当前语义地图确定一个长期目标,以达到给定的对象目标。如果类别对应的通道有一个非零元素,即观测到对象目标,那么简单地选择所有非零元素作为长期目标。如果对象目标没有被观测到,那么面向目标的语义策略需要选择一个最有可能被找到的目标类别对象作为长期目标。这需要学习对象和区域的相对排列的语义先验。我们使用神经网络来学习这些语义先验。它将语义地图、智能体当前和过去的位置以及对象目标作为输入,并在自顶向下的地图空间中预测长期目标。
基于目标的语义策略使用强化学习的方法进行训练,并以距离缩短到最近的目标对象作为奖励。我们在一个粗略的时间尺度上对长期目标采样,每u=25步采样一次,类似于《学习探索使用主动神经SLAM》[5]中目标不确定的全局策略。这就将RL探索的时间范围指数化地减少,从而减少了样本的复杂度。
确定性局部策略。局部策略使用快速行进方法(Fast Marching Method)[16],根据语义地图的障碍通道,从当前位置规划出一条通往长期目标的路径。它只是沿着通往路径采取确定性的动作以达到长期目标。我们使用了确定性的局部策略与《学习探索使用主动神经SLAM》[5]中经过训练的局部策略作比较,因为它们在我们的实验中表现出了类似的性能。请注意,尽管上述语义策略在粗略的时间尺度内起作用,但局部策略在细小的时间尺度内起作用。在每一个时间步中,我们都会更新地图并重新规划通往长期目标的路径。
结论
在本文中,我们提出了一种基于语义感知的探索模型来处理大型现实环境中的对象目标导航任务。该模型与先前的方法相比有两个主要的改进:一是将语义加入显性的情景记忆;二是学习面向目标的语义探索策略。我们的方法在对象目标导航任务上实现了杰出的性能,并在CVPR 2020 Habitat ObjectNav挑战赛上获胜。消融研究表明,该模型可以学习语义先验,从而实现更高效的目标驱动导航。与领域无关的模块设计让我们成功地将该模型迁移到现实世界中。我们还分析了該模型的误差模式,并在未来的研究中沿着两个重要的维度(语义映射和面向目标的探索)量化改进的空间。该模型还可以被扩展以处理一系列的对象目标,通过利用情景地图为后续目标进行更高效的导航。
參考文献
[1] Piotr Mirowski,Razvan Pascanu,Fabio Viola,Hubert Soyer,Andrew J Ballard,Andrea Banino,Misha Denil,Ross Goroshin,Laurent Sifre, Koray Kavukcuoglu,et al. Learning to navigate in complex environments. ICLR,2017.
[2] Saurabh Gupta,James Davidson, Sergey Levine,Rahul Sukthankar,and Jitendra Malik. Cognitive mapping and planning for visual navigation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,pages 2616-2625,2017.
[3] Yuke Zhu,Roozbeh Mottaghi,Eric Kolve,Joseph J Lim,Abhinav Gupta,Li Fei-Fei, and Ali Farhadi. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In 2017 IEEE international conference on robotics and automation(ICRA),pages 3357-3364. IEEE,2017.
[4] Arsalan Mousavian,Alexander Toshev, Marek Fi?er,Jana Ko?eck,Ayzaan Wahid,and James Davidson. Visual representations for semantic target driven navigation. In 2019 International Conference on Robotics and Automation(ICRA),pages 8846-8852. IEEE, 2019.
[5] Devendra Singh Chaplot,Dhiraj Gandhi, Saurabh Gupta,Abhinav Gupta,and Ruslan Salakhutdinov. Learning to explore using active neural slam. In International Conference on Learning Representations(ICLR),2020.
[6] Peter Henry,Michael Krainin,Evan Herbst,Xiaofeng Ren,and Dieter Fox. Rgb-d mapping:Using depth cameras for dense 3d modeling of indoor environments. In Experimental robotics,pages 477-491. Springer, 2014.
[7] Shahram Izadi,David Kim,Otmar Hilliges,David Molyneaux,Richard Newcombe, Pushmeet Kohli,Jamie Shotton,Steve Hodges, Dustin Freeman,Andrew Davison,and Andrew Fitzgibbon. KinectFusion:real-time 3D reconstruction and interaction using a moving depth camera. UIST,2011.
[8] Noah Snavely,Steven M Seitz,and Richard Szeliski. Modeling the world from internet photo collections. International journal of computer vision,80(2):189-210,2008.
[9] J. Fuentes-Pacheco,J. Ruiz-Ascencio, and J. M. Rendón-Mancha. Visual simultaneous localization and mapping:a survey. Artificial Intelligence Review,2015.
[10] Sean L Bowman,Nikolay Atanasov, Kostas Daniilidis,and George J Pappas. Probabilistic data association for semantic slam. In 2017 IEEE international conference on robotics and automation(ICRA),pages 1722-1729. IEEE, 2017.
[11] Liang Zhang,Leqi Wei,Peiyi Shen,Wei Wei,Guangming Zhu,and Juan Song. Semantic slam based on object detection and improved octomap. IEEE Access,6:75545-75559,2018.
[12] Lingni Ma,J?rg Stückler,Christian Kerl,and Daniel Cremers. Multi-view deep learning for consistent semantic mapping with rgb-d cameras. In 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS),pages 598-605. IEEE,2017.
[13] Lydia E Kavraki,Petr Svestka,J-C Latombe,and Mark H Overmars. Probabilistic roadmaps for path planning in high-dimensional configuration spaces. RA,1996.
[14] Steven M Lavalle and James J Kuffner Jr. Rapidly-exploring random trees:Progress and prospects. In Algorithmic and Computational Robotics:New Directions,2000.
[15] John Canny. The complexity of robot motion planning. MIT press,1988.
[16] James A Sethian. A fast marching level set method for monotonically advancing fronts. Proceedings of the National Academy of Sciences,93(4):1591-1595,1996.
[17] Brian Yamauchi. A frontier-based approach for autonomous exploration. In cira, volume 97,page 146,1997.
[18] Guillaume Lample and Devendra Singh Chaplot. Playing FPS games with deep reinforcement learning. In Thirty-First AAAI Conference on Artificial Intelligence,2017.
[19] Devendra Singh Chaplot and Guillaume Lample. Arnold:An autonomous agent to play fps games. In Thirty-First AAAI Conference on Artificial Intelligence,2017.
[20] Manolis Savva,Angel X. Chang,Alexey Dosovitskiy,Thomas Funkhouser,and Vladlen Koltun. MINOS:Multimodal indoor simulator for navigation in complex environments. arXiv:1712.03931,2017.
[21] Karl Moritz Hermann,Felix Hill,Simon Green,Fumin Wang,Ryan Faulkner,Hubert Soyer,David Szepesvari,Wojtek Czarnecki,Max Jaderberg,Denis Teplyashin,et al. Grounded language learning in a simulated 3d world. arXiv preprint arXiv:1706.06551,2017.
[22] Devendra Singh Chaplot,Kanthashree Mysore Sathyendra,Rama Kumar Pasumarthi, Dheeraj Rajagopal,and Ruslan Salakhutdinov. Gated-attention architectures for task-oriented language grounding. arXiv preprint arXiv:1706.07230,2017.
[23] Manolis Savva,Abhishek Kadian, Oleksandr Maksymets,Yili Zhao,Erik Wijmans, Bhavana Jain,Julian Straub,Jia Liu,Vladlen Koltun, Jitendra Malik,et al. Habitat:A platform for embodied ai research. In Proceedings of the IEEE International Conference on Computer Vision, pages 9339-9347,2019.
[24] Erik Wijmans,Abhishek Kadian,Ari Morcos,Stefan Lee,Irfan Essa,Devi Parikh, Manolis Savva,and Dhruv Batra. Decentralized distributed ppo:Solving pointgoal navigation. arXiv preprint arXiv:1911.00357,2019.
[25] Emilio Parisotto and Ruslan Salakhutdinov. Neural map:Structured memory for deep reinforcement learning. ICLR,2018.
[26] Devendra Singh Chaplot,Emilio Parisotto,and Ruslan Salakhutdinov. Active neural localization. ICLR,2018.
[27] Joao F Henriques and Andrea Vedaldi. Mapnet:An allocentric spatial memory for mapping environments. In proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,pages 8476–8484,2018.
[28] Daniel Gordon,Aniruddha Kembhavi, Mohammad Rastegari,Joseph Redmon,Dieter Fox,and Ali Farhadi. Iqa:Visual question answering in interactive environments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,pages 4089-4098,2018.
[29] Nikolay Savinov,Alexey Dosovitskiy, and Vladlen Koltun. Semi-parametric topological memory for navigation. In International Conference on Learning Representations(ICLR), 2018.
[30] Nikolay Savinov,Anton Raichuk, Rapha?l Marinier,Damien Vincent,Marc Pollefeys,Timothy Lillicrap,and Sylvain Gelly. Episodic curiosity through reachability. In ICLR, 2019.
[31] Yi Wu,Yuxin Wu,Aviv Tamar,Stuart Russell,Georgia Gkioxari,and Yuandong Tian. Learning and planning with a semantic model. arXiv preprint arXiv:1809.10842,2018.
[32] Wei Yang,Xiaolong Wang,Ali Farhadi, Abhinav Gupta,and Roozbeh Mottaghi. Visual semantic navigation using scene priors. arXiv preprint arXiv:1810.06543,2018.
[33] Mitchell Wortsman,Kiana Ehsani, Mohammad Rastegari,Ali Farhadi,and Roozbeh Mottaghi. Learning to learn how to learn:Self-adaptive visual navigation using meta-learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,pages 6750-6759,2019.
[34] Devendra Singh Chaplot,Ruslan Salakhutdinov,Abhinav Gupta,and Saurabh Gupta. Neural topological slam for visual navigation. In CVPR,2020.
[35] Devendra Singh Chaplot,Helen Jiang, Saurabh Gupta,and Abhinav Gupta. Semantic curiosity for active visual learning. arXiv preprint arXiv:2006.09367,2020.
[36] Peter Anderson,Angel Chang,Devendra Singh Chaplot,Alexey Dosovitskiy,Saurabh Gupta,Vladlen Koltun,Jana Kosecka,Jitendra Malik,Roozbeh Mottaghi,Manolis Savva,et al. On evaluation of embodied navigation agents. arXiv preprint arXiv:1807.06757,2018.
[37] K. He,G. Gkioxari,P. Dollár, and R. Girshick. Mask r-cnn. In 2017 IEEE International Conference on Computer Vision (ICCV), pages 2980-2988,2017.
猜你喜欢
东疆学刊(2022年2期)2022-04-22
廉政瞭望·下半月(2021年5期)2021-07-20
少儿画王(3-6岁)(2020年4期)2020-09-13
东方教育(2018年20期)2018-08-22
意林(2018年3期)2018-03-02
汽车生活(2018年1期)2018-02-02
好家长·青春期教育(2014年7期)2014-07-05
微型计算机(2009年4期)2009-12-23
