
基于网页挖掘的网页作弊检测技术
2020-11-12 12:38聂韶华
韶关学院学报 2020年9期
焉 凯,聂韶华
(1.莱芜职业技术学院 信息工程系,山东 济南 271100;2.临沂大学 教育学院,山东 临沂 276000)
网页挖掘技术,就是采用数据挖掘技术来发现网页中的蕴含模式(包括文档、服务等).包括网页内容、网页结构和网页使用方法[1].
近年来基于社会网络的研究受到很多专家学者的重视,相关的研究也层出不穷.搜索引擎模仿了社会网络研究的算法技术,搜索引擎在商业上取得的庞大收益,意味着社会网络研究技术在网页挖掘中的巨大潜力.经进一步研究发现,当前的搜索引擎在处理用户查询之时,也存在一个比较严重的问题,即便搜索引擎能分析出用户的真是想法,它们仍然会返回一些与查询无关的网页信息[2].究其原因,一方面是搜索引擎自身的缺陷,确实找不到相关信息;另一方面就是网页作弊,它在一定程度上影响了用户的搜索意图.
1 网页作弊概述
网页作弊是指采用一些欺骗搜索引擎的的方法(如改变网页内容或者网页之间的结构等),而不是通过提高网页的信息含量的方式,来取得相对靠前的网页排名,增加网页的点击率.
为研究方便先界定2个相关概念.网页重要性:相对整个互联网而言,某个网页的受欢迎程度(与查询无关).网页相关性:网页与某个查询的相关程度.
1.1 基于内容的网页作弊
基于网页内容的作弊,也称为基于文本的作弊,是通过修改网页上的文本信息(包括背景色或者图像等)来增加网页相关性.此种作弊主要利用搜索引擎中文本相似性度量算法TFIDF的局限性来达到作弊的目的.TFIDF算法中的TF是指某个词在文本中呈现的频率.例如,“和平”在5 000个单词的文章中出现了 300次,那么 TF(“和平”)=300/5 000=0.06 . IDF 是倒排文档频率,例如在 1 000篇文章中,单词“和平”出现在其中200篇文章里.那么,IDF(“和平”)=1 000/200=5.因此,相对查询Q,网页P的TFIDF值的计算方法为:

上式中t代表查询Q和网页P共同出现的那个单词.根据这个公式,作弊者(Spammer)有2种方式来提高网页的访问率.一是让网页包含各种单词,从而对任何查询,这个网页的TFIDF值都不为零;二是针对特定的查询,重复某些关键字,提高网页的TFIDF值[3].
1.2 基于链接的网页作弊
基于链接的网页作弊是人为制造网页之间的关联性,以此来彰显网页的重要性.目前很多搜索引擎就是运用分析网页之间的关联性,来判定网页的重要性.基于链接的网页作弊手段,常见的有两种:(1)提高出度(out-degree),以增加Hub值.例如,把雅虎中一些网站的链接复制到当前网页中.(2)增加网页的入度(in-degree),以提高PageRank值或者Authority值.例如,制作一个蜜罐(honey pot)网站,吸引用户.其典型算法有PageRank算法、HITS算法两种[4].
1.3 基于隐藏技术的网页作弊
基于隐藏技术的网页作弊手段是把用户的关注点和搜索引擎的关注点区分开来,分别给两者提供不同的信息.例如,作弊网页提供给搜索引擎很多的关键字以使作弊网页能获得检索.当用户浏览网页的时候,作弊网页能巧妙地屏蔽这些关键字提供给用户与查询无关的广告信息.
2 基于内容的网页作弊检测技术
基于内容的网页作弊检测技术,主要是通过比较正常网页和作弊网页在某些统计值上的差异,再运用这些不同值来检测网页是否存在作弊.
2.1 常规统计分析
利用MSN搜索引擎抓取网页,使用了决策树、规则分类、神经网络和支持向量机等方法来区分作弊网页和正常网页,发现基于决策树的C4.5算法效果最好,网页作弊的召回率(Recall)和准确率(Precision)都在80%以上[5].接着融入了Bagging和Boosting算法来提高C4.5算法的效果,其中Boosting算法能够使得作弊网页的召回率(Recall)和准确率(Precision)提高到90%左右.而C4.5、SVM、Bagging和Boosting算法在开源软件Weka中都有,虽然思路明确,流程清晰,但用于检测作弊网页的文本特征不多,且没有考虑网页之间存在的这种关系.
2.2 语言特征分析
借助两个自然语言处理工具——Corleone和General Inquirer来计算网页的特征.使用的数据集是“Webspam-UK2006”和“Webspam-UK2007”,这两个数据集中大部分网页都是HTML格式,他们只标注了网站(Host)是否是作弊的,而没有具体到某个网页是否是作弊的.因此,利用广度优先数据搜索策略,分别从这两个数据集中的每个网站(Host)提取400个页面,然后以人工方式把各个网页标记为3类:作弊网页、正常网页和无法确定类标签(borderline).总共计算了208个语言属性特征,按照网页中标识符(token)的个数,抽取3类网页做实验:(1)在5万标识符以下的网页;(2)15万~20万标识符的网页;(3)400万 ~5 000 万标识符的网页[6].
实验发现某些语言属性对于区分作弊网页和非作弊网页还是很有帮助的.笔者提出两种用于评价区分(作弊网页和正常网页)能力好坏的指标.
(1)绝对值差异:对于属性h,定义代表属性h的取值范围,为作弊网页在属性h取值为i时表现出来的统计特征.相应地,代表正常网页在属性h取值为i时表现出来的统计特征.于是属性h区分作弊网页和正常网页的能力定义为:

语言特征分析虽然做了很多基础性的工作,却没有进一步讨论如何有效地利用这些统计值来检测作弊网页.笔者认为,可采用常规统计分析的分类方法来区分作弊网页和正常网页.综合采用常规统计分析和语言特征分析给出的统计指标,能够更准确地检测出作弊网页.
3 基于链接的网页作弊检测技术
基于网页链接的作弊行为,目标比较单一.一般都是通过增加网页的入度来获得较高的优先率.而且相关的研究也都集中在网页排名算法上面,试图提出一些改进措施,以减少基于链接的网页作弊不良行为[7].笔者主要探讨3种典型的基于网页排名的算法改进.
3.1 TrustRank算法
假设作弊网页的信息含量很低,正常网页通常不会引用作弊网页,于是如果刚开始挑选一批信誉良好的网页,沿着它们的超链接出发,寻找其它网页,由此找到的网页也就会是用户需要的网页.一种理想的情况是,如果知道某个网页是正常网页,那么它的信任指数T(p)就设置为1;否则就设置为0.然而有时候事情并不是那么绝对,在运用算法来判别某个网页是不是作弊网页时,通过设置一个阈值δ,如果某个网页的信任指数T(p)^δ,那么就可以认为这个网页是可信任的. PageRank算法的公式可以简写为:

其中r为N×1的矩阵,代表每个页面的网页排名,T为各节点出度的转移概率矩阵的转置,为每个项都是1的N×N矩阵,为调整因子(decay factor),一般取为0.85.而TrustRank 的形式为:

其中d为N×1的矩阵,代表每个网页的信任指数.
TrustRank算法的关键流程是:(1)选取种子:即选取一些信誉良好的网页,计算各个网页的信任指数;(2)结合各个网页的信任值,来计算各个网页的排名(即TrustRank值).
实验证明,TrustRank比PageRank更能识别那些信誉良好的网页.所以在TrustRank算法中,关键是挑选种子集合,如果种子集合的分布不够广泛或不具有代表性,那么这种算法会漏掉很大一部分正常的网页,这也是TrustRank算法常遭人指责的地方[8-9].
TrustRank会对大规模的网页社区有所偏重,因此把TrustRank算法中的种子集合按照不同的话题(topic),划分成多个种子集合,按照话题类别分别计算各个网页在不同话题下的信任指数,最后再给各个话题赋以不同的权重,获得每个网页综合的信任指数.实验结果发现,TrustRank算法能克服PageRank算法的不足,取得较好的效果.
3.2 类似BadRank算法
类似BadRank算法与TrustRank算法很相近,只是把TrustRank算法中的信任(Trust)指数改为危害(Bad)指数,即把公式(4)的d矩阵替换了一下.直观理解就是,如果某个网页是作弊网页,那么它会关联到其它的作弊网页,形成一个作弊网页群(spam farm).只要能够找出作弊网站群,不对它们建立索引或者把它们的网页排名值降低,就可以减少由它们带来的危害.
总体流程:(1)选取种子集合:即获取初始作弊网页集合;(2)扩充危害指数:把种子集合中的危害指数扩充到其它网页;(3)把危害指数整合到PageRank或者HITS排名中,获得各个网页的最终排名.笔者重点介绍流程(1)和(2).(1)选取种子集合.文献中认为作弊网站群内的网页之间会形成很稠密的相互引用关系,也就是某个作弊网页P指向的网页集合Do和指向作弊网页P的网页集合Di会包含很多相同的网页.于是,如果某个网页的Do和Di含有3个及3个以上相同的网页,则把网页P认为是作弊网页,否则暂时认为P是正常网页.(2)扩充危害指数.如果某个网页P指向的网页中有很大一部分是作弊网页,那么网页P是作弊网页的几率也不小.于是,类似BadRank算法设置一个阈值T=3,如果某个网页P指向的网页中有3个已经被认定为作弊网页,那么网页P也是作弊网页.
实验结果发现,类似BadRank算法中的方法确实能够有助于发现作弊网页.但也可能会把一些正常网页当成是作弊网页.例如,政府网站之间会存在较多的相互引用,根据类似BadRank算法,很可能就把政府的某些网页当成是作弊网页了[10].
3.3 Truncated PageRank 算法
Truncated PageRank算法的假设是:通常没有正常网页会指向作弊网页,作弊网页主要是通过与作弊网页群(spam farm)内的其它网页形成强联通关系获得较高的PageRank.于是,Truncated PageRank算法提出若临近网页之间的引用关系不对网页的排名产生效益,就可极大地消除作弊网页群的影响.
Truncated PageRank算法先定义了网页之间引用的距离.例如,网页A指向了网页B,网页B指向了网页C,那么A和B都算作是网页C的支持者(supporter),并且B到C的距离为1,A到C的距离为连接这两个网站的最短距离,若A只能经过B网页到达C,那么A到C的距离就为2.
若想让距离在T之内的网页间引用产生的效果尽可能地小,那么就不记录PageRank算法在前T次迭代形成的Rank值,而把第T+1次及其以后各步计算得到的Rank增益值添加到各个页面的Rank值中.在迭代过程中,每执行一步,Rank增益值就乘以一个调整因子α(α值小于1).此时Truncated PageRank算法有不足之处.例如:存在3个网页A、B、C,它们两两之间相互引用,并且不连接其它任何网页,那么它们最终的Rank值与T毫无关系.相比PageRank算法,Truncated PageRank算法有一定的优越性[11].
4 基于用户行为的网页作弊检测技术
基于用户行为的网页作弊检测技术,就是通过比较用户在浏览正常网页和作弊网页时的行为特征,发现差异,从而提取一些规则用于检测作弊网页.这种作弊检测技术跳出了基于内容或者基于链接的检测分析框架,能够检测出各种类型的网页作弊手段(包括基于内容、链接和隐藏技术),是一种新颖的方法[12].用户是浏览网页的发起者,同时又是接收者,用户会根据自己的需要打开合适的网页.因此,可以通过用户行为表露出来的对网页的评价,来判断某个网页是否存在作弊(见图1~图4).其中,图1~图4的纵轴代表百分比,对应的蓝色条形图代表正常网页的百分比,红色条形图代表作弊网页的条形图;横轴随各图表达的含义略有不同.
4.1 基于搜索引擎的访问率
用户访问网页一般有以下几种方式:朋友或者信誉度比较好的广告告知某个网站,浏览器的标签或历史记录,当前网页内用户感兴趣的链接,或者搜索引擎.如果是作弊网页,那么用户一般也只有通过搜索引擎去访问.因此定义某个网页P基于搜索引擎的访问率SEOV(Search Engine Oriented Visiting Rate)为:搜索引擎访问网页P的次数/页面P被访问的次数.可以想象,如果某个网页是作弊网页,那么它的SEOV也越大,见图1.
4.2 源网页概率
某个网页P作为源网页SP(Source Page)的概率,定义为通过网页P访问其它网页的次数/网页P出现在网页访问rizhi日志中的次数.一般情况下,用户一旦发现某网页是作弊网页,那么恨不得马上关闭网页,也就不会再去点击作弊网页中的超链接,见图2.
4.3 短期导航率
如果某网站是作弊网站,那么用户一般不会在这个网站内部访问太多的网页.所以,定义网站s的短期导航率SN(Short-time Navigation rate)为:在网站s内访问了少于N个网页的会话次数/访问网站s的会话次数.容易理解,如果SN越大,网站s是作弊网站的可能性也就越大,见图3.

图1 搜索引擎访问率

图2 源网页概率
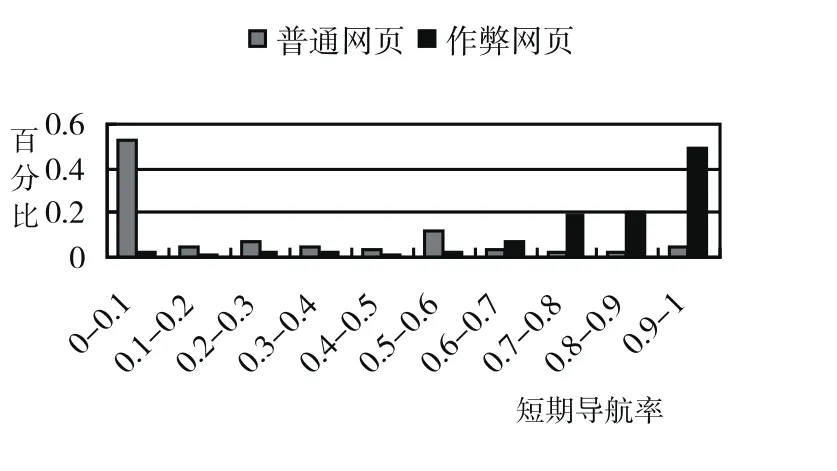
图3 短期导航率
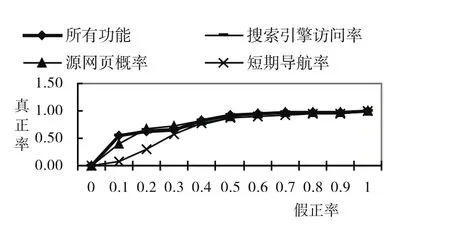
图4 ROC曲线
选取以上3个指标(SEOV,SP和SN),采用朴素贝叶斯分类方法,构造ROC曲线.发现如果综合这3个指标,得到的AUC的值为79.26%,也就是说可以以79.26%的概率使得正常网页获得比作弊网页更好的排名[13],见图4(其中深蓝线代表了3个指标,灰线代表SP,粉红线代表SEOV,红线代表SN).
总之,从用户行为角度研究作弊网页的方法值得重视.由于分析的指标很少(只有3个),这也预示着今后还有不少相关工作.
5 结语
目前,存在各种类型的网页作弊手段,同时,也有相应的反作弊手段.有从网页内容着手分析的、有从网页链接着手分析的,也有从用户行为着手分析的.然而这些都只是从技术方面来抵御网页作弊.网页作弊行为能带来潜在的商业价值,并且互联网市场没有一个统一的监管体系,各个商家各自为政,若能采取相应的惩罚措施,削减网页作弊的商业价值,那么应该可以铲除不少的作弊网页.
猜你喜欢
汉字汉语研究(2021年4期)2021-11-26
成都信息工程大学学报(2021年6期)2021-02-12
疯狂英语·新阅版(2020年11期)2020-12-21
小学阅读指南·低年级版(2018年5期)2018-11-02
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
故事作文·低年级(2017年12期)2017-12-13
电子制作(2017年2期)2017-05-17
中国卫生(2015年12期)2015-11-10
科学导报·学术论坛(2013年5期)2013-06-26
