
深度置信网络结合递归特征添加的网络入侵检测方法
2020-11-12 10:39赵荷盖玲
计算机应用与软件 2020年11期
赵 荷 盖 玲
1(成都东软学院计算机科学与工程系 四川 成都 611844) 2(上海大学管理学院 上海 200444)
0 引 言
在高速发展的信息时代中,网络安全是一个关键性的问题。网络入侵检测系统(Network Intrusion Detection Systems,NIDS)是解决网络安全问题的方案之一。针对不断出现的网络攻击,所有互联网参与者必须考虑构建安全可靠的防御系统。数据挖掘是一种可以与入侵检测一起使用的技术,在描述系统和用户行为的数据特征中用于检测特征模式,以及理想的恶意活动示例[1-3]。由于互联网每天都会产生称为“零日攻击”的新的攻击方式,且事先没有供应商发现或开发出有效的解决方案以应对该威胁。因此,传统的防御手段难以减轻零日攻击带来的损害,需要在零日攻击对网络造成巨大破坏之前抵御这些零日攻击。显然,研究网络入侵检测系统具有很好的现实意义和实用价值[4-5]。
国内外许多专家及学者围绕网络入侵检测系统进行了深入的研究。文献[6]采用类内相关系数和类间相关系数来获得特征的类特定子集,使用类内和类内相关系数分别测量特征的有效性和可靠性,但该方法并没有处理数据稀缺和相互依赖的特征。文献[7]使用基于签名的异常检测方案来检查包头,更准确地提取行为模式。将基于特征的检测系统和基于异常的检测系统相结合,克服前者因无法检测新型攻击而受到的限制以及由此产生的高误报率。但该方法没有考虑使用特征选择去除不相关和冗余的特征。文献[8]设计了一种新的多目标优化方法用于高效的入侵检测。该方法涉及编码提供最佳特征子集的染色体。这些特征可以在以后用于训练组合分类器的各种实例。然而,该模型的缺点是,在计算不同代中的适应度函数时计算成本非常高。文献[9]提出了一种将流量记录作为图像来处理,以使用计算机视觉技术检测拒绝服务攻击的方法。该方法涉及利用多变量相关分析来描述网络流量记录并将其转换为图像,但没有考虑图像可能有一些噪声来自不同的来源,这反过来会产生噪声特征,那些嘈杂的特征可能导致不符合需要的分类结果。
针对上述问题,本文提出深度学习结合递归特征添加的网络入侵检测系统以提升网络对零日攻击的抵抗性,主要创新点为:
(1) 现有的大多数检测系统中,网络入侵攻击特征由于长字符串特性无法直接采用机器学习。本文方法通过采用深度置信网络与二元组编码技术对网络攻击特征进行有效提取与二进制编码,从而提升入侵检测准确率。
(2) 现有大多数检测方法中,网络入侵攻击决策依据的特征存在相互依赖的问题。本文利用递归特征添加法(Recursive Feature Addition,RFA)进行特征选择,并综合考虑入侵检测的准确率、检出率和误报率,从而提升检测效率与精准率。
1 方法设计
1.1 基于DBN与二元组编码的网络攻击特征提取
图1为基于DBN的网络攻击特征提取算法的架构,其中:输入数据为I;输出数据为O(即为网络攻击特征)。为避免深度学习网络函数表达能力过强出现的过拟合情形,采用非监督预训练方式对深度学习网络进行训练,通过逐层学习获取输入数据的主要驱动变量,并利用多层映射单元提取出网络攻击中主要的结构信息。

图1 深度学习算法结构
对隶属于相邻两层(Si,Sj),i≠j的一组神经元(sli,smj),Si表示第i层特征,Sj表示第j层特征,sli和smj分别为Si和Sj的神经元,定义其能量函数为:
(1)
式中:δij、σl、υm为权重参数;θ表示3个权重参数的集合,即θ={δij,σl,υm}。
两层神经元间的联合概率分布为:
(2)

(3)
最优的模型参数θ,可通过最大化训练集上的对数似然函数得到[10]。
进一步地,选择使用二元组技术对这些特征进行编码。其优点在于避免了特征量因字符串过长而不利于在机器学习中直接使用的缺陷。二元组特征编码以构造字典的方式完成对所有特征的编码。
1.2 基于RFA的特征选择方法
1.2.1特征选择方法
相较于传统神经网络特征提取方法,深度学习网络中特征数量往往从数十个增加到数百个。这些特征往往具有高度的冗余性,从而导致最终入侵检测精度的下降[11-13]。针对这一问题,本文提出根据预定标准查找网络攻击特征的一个或多个信息子集的搜索算法,如图2所示。

图2 利用二元组技术提取ISCX数据集特征时的字典构建阶段
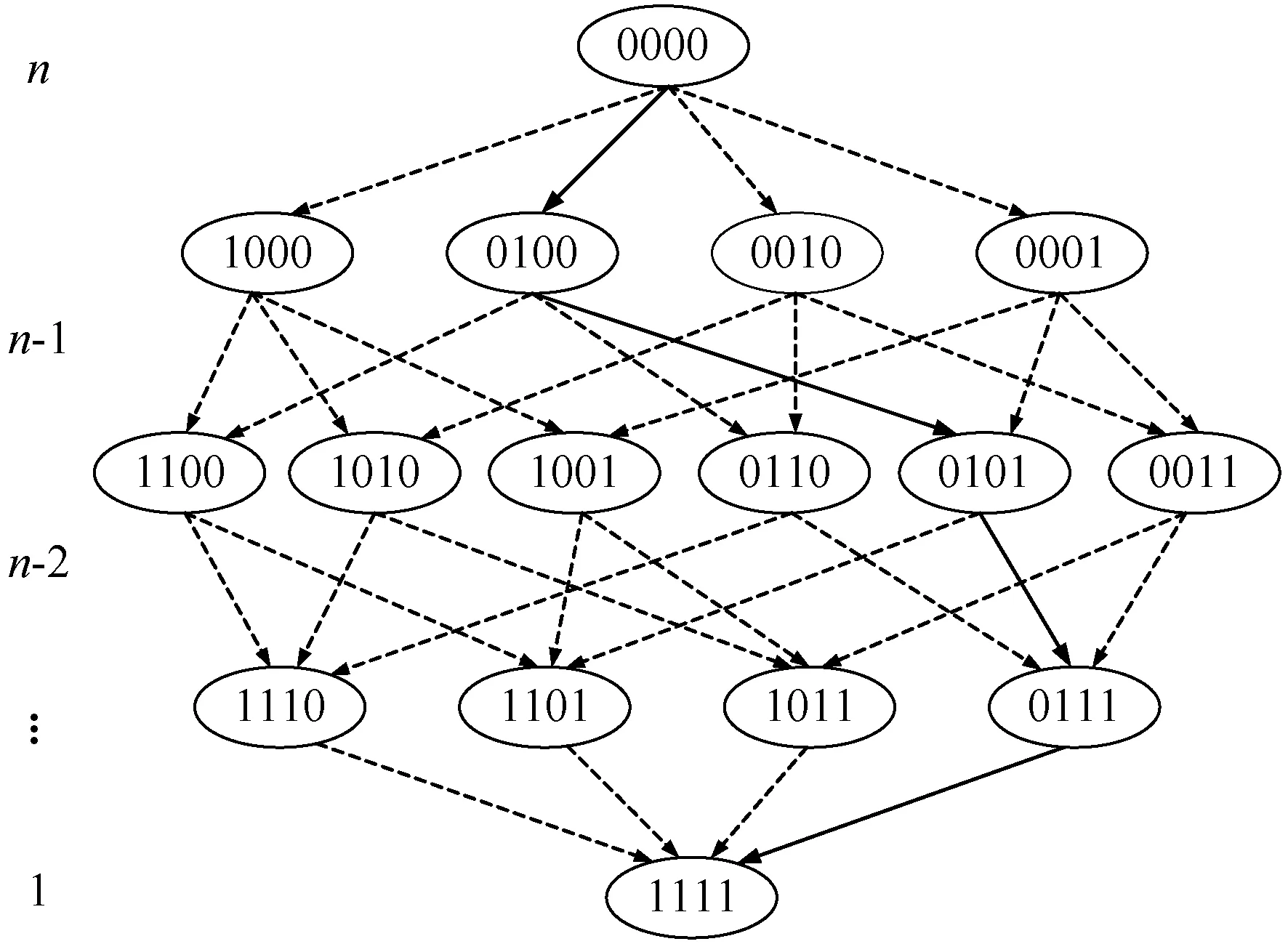
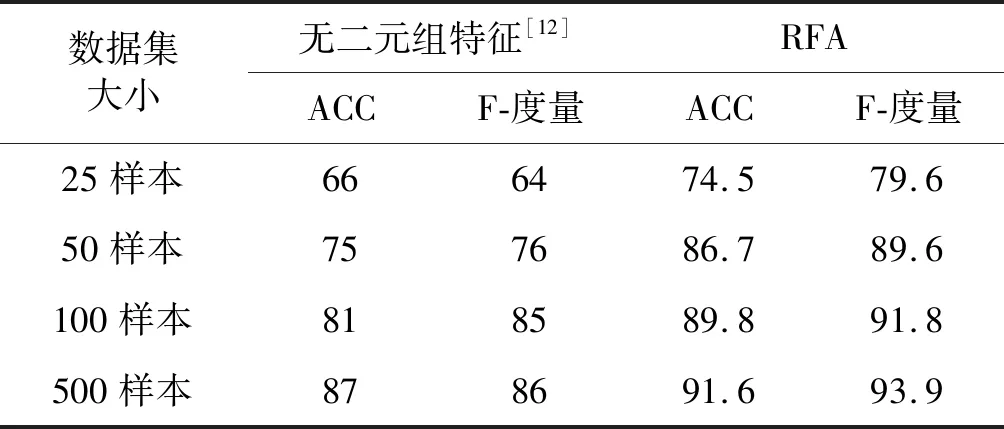
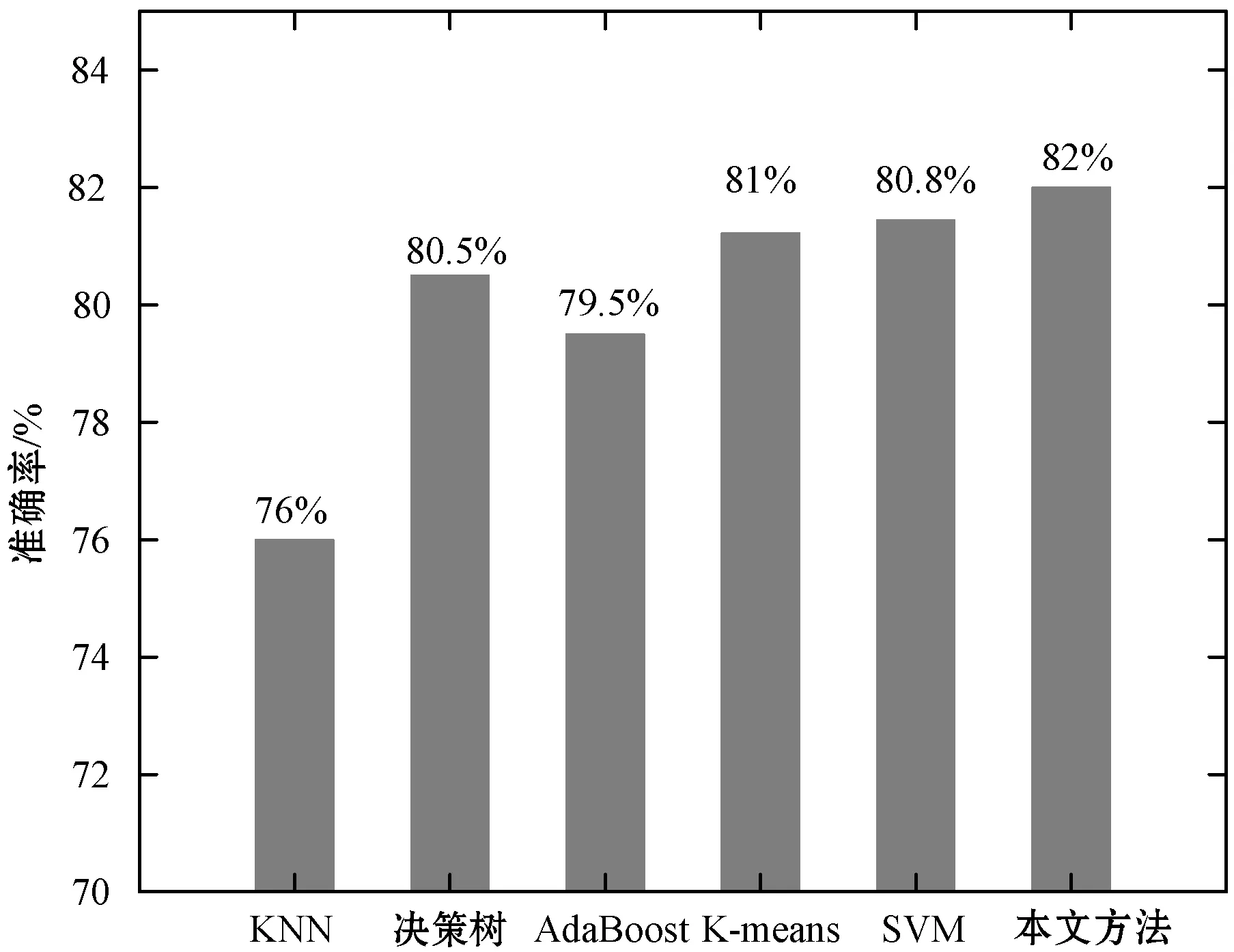
不妨设F={F1,F2,…,Fn}是整个特征集;S={Fτ(1),Fτ(2),…,Fτ(m)}(S⊆F)是整个集合中特征的选定子集,其中m 此外,由于额外噪声特征的存在,通常会增加训练分类器的难度,故识别噪声特征也是一个关键的预处理步骤,因为在这种噪声数据上构建的分类器的性能将高度依赖于训练数据的质量。换言之,噪声背景下需要确定最优的特征决策边界值,这直接导致特征提取难度更大,当前针对含噪声的特征提取问题而言,可以分为如图3所示的三种类型:过滤方法、包装方法和嵌入方法,其中FS表示所有特征的集合空间。 (a) 过滤方法 (b) 包装方法 (c) 嵌入方法图3 不同特征选择方法 1) 过滤方法:如图3(a)所示,特征选择与分类过程相互独立,通过检查数据的内在属性来确定特征重要性。一般计算所有特征的相关性得分,去除低评分对应的特征后即为所选择的特征。 2) 包装方法:如图3(b)所示,该方法采用机器学习确定特征子集的空间范围,且分类器的构造过程与特征选择过程紧密结合,但机器学习过程与后续的分类器构造与特征选择过程独立。 3) 嵌入方法:如图3(c)所示,该方法在机器学习过程中执行特征选择步骤,其优势在于提升算法执行效率,且机器学习和特征选择部分不能分开。 1.2.2递归特征添加方法(RFA) 考虑到嵌入式特征选择方法存在的明显优势,本文提出基于递归特征添加方法的特征选择算法。其基本原理为,通过根据计算出的剩余特征的排序系数(Ranking Coefficient,RC),一次性地向该集合添加一个特征,来初始化要用于所选特征的一组空特征。 将针对支持向量(其基本上代表训练示例的小子集)计算决策函数D(x)的权重wi。支持向量是最接近决策边界的训练示例,并提供类之间的最大间隔。对RFA中的特征进行排序取决于权重大小作为排序系数,通过在成本函数的最大变化时添加一个特征来执行。 需要最小化的SVM的成本函数为: J=(1/2)αTHα-α1 (4) 式中:α1是n维向量;H是可以计算的矩阵: H=yhykK(xh,xk) (5) 式中:xh和xk是训练样例;K是用于测量训练样例xh和xk之间的相似性的核函数,且有h,k=1,2,…,N,N为需要选择的特征数量;y是类标签的向量。此算法中使用RBF核函数,可以计算为: (6) 式中:γ是常数,通常选择为总特征数量的倒数;为了计算由于添加一个特征i而导致的成本函数的变化,需要重新计算H矩阵,不妨记为H(+i),其中符号(+i)对应于添加特征i。这一过程中需要同步更新计算K(xh(+i),xk(+i))。最终的排序系数RC计算为: RC=(1/2)αTHα-(1/2)αTH(+i)α (7) 算法第一次迭代时,由于还没有选择特征,此时的排名系数RC仅有第一项。随后迭代地执行该算法以执行递归特征加法(RFA),从而对应于取最大值的RC(i)的特征被不断添加到排序特征列表,算法的结果将是从最重要到最不重要的特征的排序列表。 以图4所示的4特征排序问题对所提算法进行详细阐述,嵌入式前向特征选择有四个特征,选择顺序为实线(2,4,3,1),其中:1表示存在特征;0表示缺失。 图4 4特征排序图 图4中,每个特征位都表示为二进制值(0或1)。选择此特征后,其位置将为1,否则为0。RFA方法以空特征集(0 0 0 0)开始。示例中,特征2被选择为其他特征中最相关的特征,因此首先选择它。算法继续进行,直到它根据排名系数对所有特征进行排名。实线表示方法遵循的路径,而虚线表示当前案例中的所有可能情况。该示例的最终排名分别为(2,4,3,1)。 为衡量特征添加前后对网络入侵检测效果的影响,采用检测精度和F度量值作为指标。其中检测精度计算公式为: (8) 式中:TP、TN、FP和FN分别为True Positive、True Negative、False Positive和False Negative值。可知分类器检测精度是正确分类的示例与示例总数的百分比。另一方面,F度量值是检测精度和召回率的调和平均值,公式为: (9) 此外,引入额外三个指标以评估所提入侵检测方法的有效性: (1) 检测率(Detection Rate,DR)。任何入侵检测系统的检测率根据以下公式得到,表示正确检测到的攻击占攻击总数的百分比: (10) (2) 误报率(False Alarm Rate,FAR)。FAR表示根据以下公式将正确实例的百分比错误地分类为对正常实例总数的攻击: (11) (3) 综合性能。除了前面提到的指标之外,提出了一个综合指标,以便将三个指标(准确度、检测率和FAR)合并在一起来比较: (12) 该度量的结果将是-1和1之间的实数值,即Combined∈[-1,1],其中:-1对应于最差的整体系统性能;1对应于最佳的整体系统性能;而0对应于50%的整体系统性能。在目前的形式中,该公式给予所有三个指标(准确度、检测率和误报率)相等的权重。但在其他场景下,可通过赋予不同权重值以实现对不同性能的侧重关注程度。 为了阐明所提出的组合度量的重要性,假设有一个数据集,其中200个实例分为100个普通实例和100个攻击实例。现在讨论具有相同精度50%的三种不同场景。 对于上述三种不同的混淆矩阵,可以计算出性能指标,如表1所示。 表1 具有相同准确性的三种不同方案的性能指标 所有上述场景具有相同的准确度值。但是,这三种情况具有不同的检测率和误报率。这使得很难确定哪个系统在产生三种情景的三个系统中表现最佳。但是,如果计算提出的组合度量,可以得出结论,生成第三个场景的系统是其他系统中最好的系统。 同样,可能存在具有相同检测率、不同精度和误报率的不同系统,如下面三种情况所示,它们都具有相同的检测率50%。表2为脚本4-脚本6所对应的性能指标。 表2 具有相同检测率的三种不同方案的性能指标 从表2可得,具有最大组合度量的最佳系统是生成第二个场景的系统。同样地,可能存在不同的系统,这些系统产生具有不同精度和检测率的相等误报率,如下面三种情况所示,它们都具有相同的误报率50%。表3为对应的性能指标。通过考虑组合性能可以得出结论,与第一个场景相对应的系统是最好的系统,因为它的组合度量是0.3,这是其他系统中最高的。 表3 具有相同误报率的三种不同场景的性能指标 综上,当单独拍摄时,在测量入侵检测系统的性能时,准确度、检测率和误报率都不足以表达。但是提出的组合指标可以整合上述三个指标给出的信息,以便更加彻底地衡量入侵检测效果,正如从上述情景中注意到的那样。通过使用所提出的组合度量,可以选择具有最佳的最大准确度、最大检测率和最小误报率的系统。如前所述,可以根据应用修改提出的组合公式以测量其性能。这可以通过根据它们对该应用的重要性给予三个分量(准确度、检测率和误报率)不同的权重来执行。 为进一步评估不同入侵检测方法的检测性能,采用基准数据集ISCX进行评估,其由不同类型的特征组成:数字,分类,日期时间和字符串。通常,网络流量信息由上述类型混合表示,但是蕴含的特征通常由长字符串值表示,这使得在机器学习中难以处理,为此采用二元组编码技术进行问题化简。 不失一般性,考虑将网络入侵特征转换为双字节表示的示例。三个网络特征具有不同的长字符串:“B7z2”,“Vud3j”和“z2nB7”。依据图2所示的字典生成过程,得到由9个单词组成的字典(即二元组):B7|7z|z2|Vu|ud|d3|3j|2n|nB。如表4所示,三个网络特征的二元组表示转化为具有“0”和“1”的二进制编码。 表4 示例中三个网络入侵特征的二元组表示 为了准备用于特征选择的结果数据集,使用快速过滤器选择算法对特征进行预排序步骤。由于当前的特征数量很大,并且在这种情况下特征选择可能非常耗费时间,因此从原始特征中获取350个特征的子集。产生的350个特征分别用于生成大小为25、50、100和500的数据集。为了模拟“零日攻击”,使用不同数量的示例来监视每种数据集大小的特征选择行为,从特征提取到使用特征选择算法对特征进行排名的所有步骤如图5所示。 图5 利用二元组技术提取ISCX数据集的特征向量 为了观察包含网络入侵特征添加对提高检测精度的影响,在所有ISCX数据集上测量网络入侵特征添加前后的分类精度和F-度量值,如表5所示。 表5 在ISCX数据集上应用RFA前后的性能指标 % 表5的第2列和第3列表示不添加网络入侵特征时的检测性能;第4列和第5列表示在利用二元组编码技术添加网络入侵特征之后,从分类器获得的最大性能。可以看出,与没有二元组特征的相同数据集上分类器的性能相比,本文算法的检测精度提升8%以上。 表6为采用RFA方法后相关评估指标随数据集规模的变化情形。 表6 在ISCX数据集上应用RFA后的所有性能指标 % 可以看出,大多数单一指标随着数据集大小的增加而提高,而FAR指标则不严格遵守随数据集规模扩大而下降的趋势。然而,对于组合评估指标而言,由初始25个样本所对应的指标62.5%逐步提升至500个样本所对应的指标(86.5%),与大部分单一性指标的变化趋势相同。这表明采用组合性能指标能够较好地反映入侵检测的性能,且随着数据集样本规模的扩大,其评估结果越好。 需要指出的是,文献[12]提出的检测方法未使用RFA添加网络入侵特征,故在此作为本文算法的对比算法,表7为相应的评估性能。为直观分析本文方法的优异性,相比文献[12]方法,在不同样本数情况下,本文方法的评估指标提升情况如图6所示。 表7 在ISCX数据集上的所有性能指标(文献[12]) % 图6 与文献[12]相比本文方法评估指标提升百分比 根据图6,相比于传统的未考虑特征选择的方法(文献[12]),在不同数据集样本规模下,本文方法的检测准确率、F-度量值、检出率和综合性能指标均有所提升,而误报率低于未考虑特征选择的方法。例如,当数据样本数量为25时,与文献[12]方法相比,本文方法的准确率、F-度量值、检出率和综合性能指标分别提升了16.5%、7.2%、9.8%、7.4%,而误报率则下降了12.6%;而其余数据样本规模下,本文方法的准确率、F-度量值、检出率和综合性能指标则至少提升了3.6%、7.7%、6.4%和5.5%。因此,算例结果表明,本文方法在提升检测精度的同时,由于综合考虑了网络入侵的特征,进一步降低了将正常情形分类为入侵事件以及将入侵事件误判为正常情形的风险,因而所提方法的检测性能更优。 为验证所提深度置信网络结合递归特征添加的网络入侵检测方法的有效性,采用KNN算法[14]、决策树算法[15]、Adaboost算法[16]、K-means算法[17]、SVM算法[18]等主流入侵检测算法进行对比。对比指标为检测精度,如式(8)所示。相应的检测结果如图7所示。 图7 几种算法对网络入侵准确率检测结果 可以看出,相较于传统入侵检测算法,本文算法的准确度最高,且准确度最多提升7.89%。这是因为本文算法首先采用深度置信网络对网络入侵特征进行提取,并基于二元组编码与RFA算法相结合的方法对主要特征量进行选择,因此对未知网络入侵攻击的检测准确率更高,网络安全防御能力更强。 为实现对网络“零日攻击”的有效判别,在综合考虑检测准确率、检出率和误报率的基础上,提出一种深度学习结合递归特征添加的网络入侵检测方法。同一数据集下的算例实验表明,相较于传统不考虑网络入侵特征的方法,本文算法的检测精度得到有效提升。此外,与传统入侵检测方法相比,本文算法同样展现出更高的检测能力,从而保证对未知网络攻击手段的检出能力,保障互联网安全。 未来的研究方向是使用集成分类器方法进行入侵检测,以提高检测性能,并利用Android僵尸网络数据集,来研究这些技术在检测Android系统恶意软件中的行为。

2 实 验
2.1 评估指标
2.2 评估指标不同对入侵检测方法性能的影响












2.3 特征提取和数据集准备


2.4 在ISCX数据集上应用RFA的结果



2.5 方法对比结果分析
3 结 语
猜你喜欢
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
考试周刊(2017年7期)2017-02-06
现代电子技术(2016年23期)2017-01-12
安徽理工大学学报·自然科学版(2016年1期)2016-12-14
电脑知识与技术(2016年25期)2016-11-16
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
阅读(中年级)(2009年11期)2009-04-14
