
基于CNN的Android恶意代码检测方法
2020-11-11 08:28赖英旭殷刘智子罗叶红
北京工业大学学报 2020年11期
赖英旭, 陈 业, 殷刘智子, 罗叶红, 刘 静,3
(1.北京工业大学信息学部, 北京 100124; 2.信息保障技术重点实验室, 北京 100072;3.西安电子科技大学陕西省网络与系统安全重点实验室, 西安 710071)
智能手机已经成为最为广泛使用的终端通信工具,但是在Android手机系统中,应用程序运行时需申请调用系统的关键应用程序编程接口(application programming interface,API)[1],用户在安装应用程序时一般默认选择同意申请,否则在安装完成后应用程序将不能提供相应的服务. 很多恶意应用开发者就利用Android系统这一特点,在开发应用时调用部分关键的API来实现自己的恶意行为,例如获取设备信息、访问网络、获取手机通信信息等[2]. 用户安装的应用大多来源于第三方市场,如应用宝、豌豆荚等第三方平台以及各个智能移动设备制造商提供的应用市场. 第三方市场往往疏于对开发者应用的审核,应用市场对恶意应用的管理也不及时[3],同时,市场对Android平台的恶意应用检测能力较弱,以上原因造成了恶意软件通过各种途径被下载并安装在用户的手机中[1,4]. 用户在下载恶意应用后往往不能及时意识到安全问题,并且很多应用潜伏在系统后台窃取用户信息,因此,很多用户无法及时发现这些恶意应用并阻止其恶意行为[4].
虽然Android应用采用了签名机制、权限机制、沙盒机制等安全手段[5],但仍然有较高比例的恶意应用无法被准确地检测和识别. 目前,Android应用的恶意行为大致分为恶意扣费、隐私窃取、远程控制、恶意传播、资费消耗、系统破坏、诱骗欺诈、流氓行为等[6],其中实施恶意行为的方式常为恶意代码植入,其原理就是利用Android应用的逆向技术[7],获得正常应用的源代码,然后将恶意代码插入到正常应用的代码中,这类恶意软件通常很容易欺骗用户通过正常的下载安装,进而实施恶意行为.
Android平台恶意代码的检测方法主要分为静态分析方法和动态分析方法2种[8]. 静态分析方法通过检测文件是否拥有已知恶意软件的特征代码来判断是否为恶意应用,优点是速度快、准确率高、误报率低,但无法检测未知的恶意代码. 动态分析方法是依靠监视程序的行为与已知的恶意行为模式进行匹配,以此判断被检测应用是否具备恶意特征,但是动态监测占用的系统资源较多且有被攻击的风险. 因此,这2种方法都不能同时满足高效的检测效率和未知恶意代码的检测[9].
现有的静态检测方法有代码语义分析、代码特征分析等,代码的语义分析需要结合Android反编译的技术来获取源代码及指令信息,而代码特征分析则需要提取特征,一般为系统权限、逻辑流程以及API调用、二进制代码等. 2014年,王站[7]提出了一种Android恶意代码静态检测方案,这种方案基于静态检测的Android平台恶意代码检测框架Android Sec,以dex文件为研究对象,以危险性API 的调用为特征,利用数据挖掘中词频- 逆向文件频率(term frequency-inverse document frequency,TF-IDF)算法,将恶意样本抽象为文本,通过相似度计算并辅以后台监听、黑名单匹配等手段,对 Android平台恶意代码进行检测. 该静态检测方法需要对应用文件进行代码逆向工程,获取源代码并进行语义分析、API调用信息获取等操作,对计算资源的消耗很大. 本文希望通过更为简便的方案实现静态特征提取,相比之下本文方案无须安装或是利用沙盒进行模拟运行,通过反编译、解压缩等多种途径即可获得应用程序的权限信息,再利用系统权限的调用能够间接反映出应用程序行为特征的特性[10],将系统权限申请与恶意应用的行为对应上,达到分类的目标和效果.
经过研究,目前大部分提取静态权限特征分类的恶意应用检测,都是将贝叶斯算法作为分类的方法,其特点是简单快速,但是需要满足分布独立的假设,对于一个应用的静态权限特征来说,一个应用行为常常需要申请多个权限,组合使用,使用贝叶斯的方法就默认消除了不同权限之间相互的联系与影响,为此本文选用卷积神经网络(convolutional neural network,CNN)作为分类器,利用其能够学习特征之间联系的优势特性来应对多种应用权限组合产生的行为,解决贝叶斯算法分布独立假设的缺点.
综合上述分析,本文提出一种基于CNN的Android静态权限恶意代码检测方法,既保证了对恶意代码的检测准确率,又弥补了静态检测在应用程序变种检测方面的不足.
1 恶意应用检测方法
近年来,在深度学习的研究领域出现了很多高效的神经网络算法,经过对大量样本特征数据的学习,能够训练出检测速度快、效率高的分类器[11]. 经过对Android平台安全机制的分析,结合深度学习中的CNN算法,本文提出了一种基于静态申请权限特征的恶意代码检测方案. 该方案通过静态解析应用程序提取申请权限特征,利用独热编码的方式将权限的调用申请转化为权限特征集合,以权限特征集合为输入数据,利用CNN算法,最终通过大量权限特征数据的训练获得用于检测恶意代码的分类器,对Android应用程序实现高效的检测.
1.1 恶意代码检测系统设计
本文中恶意代码检测系统的整体设计分为Android应用程序包(android application package,APK)逆向工程、权限特征转化、深度学习训练集成、训练分类器几个部分,包含了从读取APK到获得恶意代码检测结果的整体流程设计,如图1所示.
1.2 Android应用程序APK安装包分析
APK是当前Android平台中使用最广泛的应用程序安装文件包格式,用于分发和安装移动应用及中间件. 因此,本文提出的对Android平台的恶意代码检测方案是基于APK的. 实验中的应用样本囊括各种功能分类且均来自于第三方应用平台,部分恶意样本来自VirusShare网站,用于训练CNN的学习样本均由以上的应用样本通过特征提取操作获得,广泛覆盖各种类型的权限申请,具有代表性. 在获取正常应用程序样本的过程中,发现第三方平台中约有5%的应用程序安装包被检测出含有恶意代码,进一步证实第三方Android应用市场安全风险较大.
APK的分析包括以下几个步骤:1) 获取APK;2) 反编译APK;3) 解析AndroidManifest.xml文件;4) 提取应用程序静态申请的系统权限,转化为权限特征.
1.3 逆向分析权限特征提取方法
Android官方给出了138种权限,申请的系统API权限信息在Android应用程序中表现为一个静态常量. 从AndroidManifest.xml文件的
本文提取权限特征的方法是通过静态分析提取应用程序权限特征. 结合Android应用常用权限以及本文提取应用申请权限的结果,共选取144种系统权限作为权限特征处理的基础,经过调整之后合成一个1×144的参考权限特征列表,以此列表作为基本序列,通过读取AndroidManifest.xml文件获得的APK权限特征列表作为比较对象,采用独热编码的方式对2个列表进行比对,最终生成有12×12=144个元素的二位数组,如图2所示.
1.4 卷积神经网络设计
1.4.1 输入层设计
图像输入层的权限特征数据采取灰度图的方式进行存储,CNN的优势在于对图片的识别和分类,特别是通过卷积操作能够揭示图片中局部像素点之间的联系. 从过程上来说,是把一张图片作为一份整体的数据进行处理,而不是单独的像素点的数值分析[13-14]. 从APK反编译结果中解析AndroidManifest.xml文件所获得的权限特征数据为多元素的权限列表,经过独热编码方法的处理转化成为二进制数值,组成单一的数据列表,这些特征数据从数值上分析没有明显的关系. 为了揭示其中权限特征之间的联系,本文将1×144的特征数据列表转化为12×12的特征数据图片,然后以图片的形式输入到CNN的结构中进行学习和分类.
1.4.2 卷积层设计
卷积层中每个节点的输入实际上是上一层的神经网络中的一部分内容,由预先设定的卷积核来实现. 卷积核是一个过滤器,是一个正方形的像素点组合[15],其作用是对应到输入的图片上,分区域进行块状扫描,然后根据预先设定的步长等参数开始扫描输入图片. 扫描的计算规则是被覆盖的图像像素矩阵和卷积核的权重对应位置相乘然后求和,每扫描一次就能得到一个输出数值.
卷积层所执行的功能就是对输入图像像素的局部进行特征的抽象提取,可以通过多个不同的卷积核对同一张图片进行卷积操作. 卷积核的个数就是卷积层处理之后输出矩阵的深度,也等同于一张输入图片经过卷积处理后输出卷积个数层的图片. CNN的参数个数与图片大小无关,只跟过滤器的尺寸、深度以及卷积核的个数有关. 假设28×8灰度图片卷积核的大小为3×3,输出矩阵的深度为500,那么总体的参数个数为3×3×500+500=5 000个参数,当输入图片更大时,参数会急剧增多,参数过多不仅会导致网络模型计算速度变慢,同时也容易导致过拟合问题,CNN在一定程度上可改善这种情况,因此,本文采用CNN进行训练.
1.4.3 激活函数选择
激活函数,也叫激励函数. 因为在神经网络中每一层输出的都是上一层输入的线性函数,所以,任何可能的网络结构,输出都是输入的线性组合,失去了CNN隐藏层的效果,因此,决定引入非线性函数作为激励函数,这样深层神经网络就不是输入的线性组合,而是可以逼近任意函数的曲线[13,16]. 一般情况考虑使用sigmoid函数或者tanh函数,因为这2个函数的输出都在0~1或-1~1,输出有界,很容易就能够充当下一层的输入,完成隐藏层的功能. 通过本文的设计实验和研究,同时考虑到Relu函数是目前CNN结构设计中最为常用的激励函数,其能够在x>0时保持梯度不衰减,从而缓解梯度消失的问题,并且其函数特性对于图像识别方向有明显的优势,在图片分辨率较高的情况下,能够减少大量的计算,提高神经网络的学习分类速度,因此,本文采用Relu作为激励函数.
1.4.4 池化层设计
对于池化层来说,池化的方式有2种:一种是最大值池化,另一种是平均值池化. 由于通过APK提取出的静态样本特征在图片上会表现出不同的纹理细节,像素点之间的数值差距很大. 最大池化是选图像区域的最大值作为该区域池化后的值,有利于对图片细节进行提取和保留,因此,本文实验采用的是最大值池化tf.max_pool().
1.4.5 全连接层设计
在CNN结构中,经多个卷积层和池化层后,连接着1个或1个以上的全连接层. 与移动定位协议(mobile location protocol,MLP)类似,全连接层中的每个神经元与其前一层的所有神经元进行全连接. 全连接层整合卷积层和池化层中具有类别区分性的局部信息. 为了提升 CNN网络性能,全连接层每个神经元的激励函数一般采用Relu函数. 最后一层全连接层的输出值被传递给softmax函数进行分类,该层也称为softmax层.
2 算法设计与实现
2.1 APK分析
APK作为Android应用程序文件是Android平台最终运行的程序包,类似于ZIP文件格式. 目前,能够完成APK反编译的工具有dex2jar、jd-gui、APKDB、enjarify、Apktool等,本文选择APKDB作为反编译APK的工具,通过反编译可以获取应用程序的源代码、资源文件等内容,包括assets目录、lib目录、META-INF目录、res目录、AndroidManifest.xml文件、classes.dex文件、resources.arsc文件等,如表1所示.
2.2 AndroidManifest.xml文件
AndroidManifest.xml文件属于Android应用程序的配置文件,是一个用来描述Android应用“整体信息”的设定类文件. Android系统可以根据其各方面的描述完整地了解APK的各项信息以及和系统进行交互所需要的各类资源,每个APK都必须包含一个位于根目录的AndroidManifest.xml文件,并且文件名字是固定的,不能修改.

表1 反编译APK获得的文件Table 1 Files obtained by decompiling APK
2.3 获取APK申请权限模块
Android应用程序申请的权限都在可扩展标记语言(extensible markup language,XML)文件中,因此,本模块主要是获取清单文件并从中提取权限信息. Android应用程序所有申请的权限都在
本文实验中选择使用python中提供的xml.etree.ElementTree模块作为解析XML文件. XML文件按照树型结构组织,ElementTree有2种类来表示这种组织结构:ElementTree表示整个XML树,Element表示树上的单个节点. 操作整个XML文档时使用ElementTree类,比如读写XML文件. 操作XML元素及其子元素时使用Element类. Element是一个灵活的容器对象,在内存中存储层次化的数据结构.
本模块中,创建uses-permissions list用于存储读取到的权限列表,按照反编译过程中对APK的处理顺序从目录中读取XML文件包含的权限信息并存入uses-permissions list列表中. 获取APK申请权限模块设计的流程图如图3所示.
2.4 静态权限特征的提取模块
本模块在实现过程中建立了2个存储权限的列表——allPermissionArray[]所有权限列表和dangerPermissionArray[]行为映射权限列表,分别储存了Android平台应用能够申请的所有权限和根据应用行为映射对应的重要权限列表. 将所有权限列表和应用程序提取权限列表进行比对,将应用程序没有申请的权限置0,申请的一般权限置100,申请的高危权限置255,分为3种情况存储,并用于最终生成应用程序权限特征向量. 设置不同权限安全等级能够更加准确地描述应用申请系统权限的特征,从而获得更好的识别准确率.
Android应用程序通过声明权限才能在系统运行中实现运行,在运行过程中会产生API调用,可以理解为应用行为,因此,静态权限特征虽不能完全包含应用运行过程中的具体行为,但是通过行为和权限的映射关系,可以代替应用的大部分行为特征. 恶意应用的开发者一般会在静态标注的权限列表中标记远超实际需求的权限申请以掩盖其为了实现恶意行为的目的. 包含恶意代码的应用会申请较多高风险权限,进而实现恶意行为. 经过阅读大量文献,本文选取了25个高危权限来确定行为与权限特征映射,如表2所示.
2.5 CNN搭建
1) 输入层. 本文中CNN实际的输入数据是从AndroidManifest.xml文件中提取出的申请权限,特征列表是一张12×12的灰度图,每个像素点为一个权限特征经过权重计算后的数值,这个数值限定在0~255,由图片生成的二位数组作为输入层数据导入神经网络进行计算,如图4所示.
在本文的实验中,通过借鉴MNIST_data数据集的数据存储格式,将从APK中提取出的静态权限特征信息分别标记为0和1类,0代表恶意样本数据,1代表正常样本数据.
2) 卷积层. 本文选择的是Tensorflow中的二维卷积函数:tf.nn.conv2d函数,定义x是图片的所有参数,W是此卷积层的权重,然后定义步长strides=[1,1,1,1]值,strides[0]和strides[3]的2个1是默认值,中间2个1代表填充时在x方向运动一步,地逐步覆盖图片中的每一个像素点,而填充采用的方式是补零填充,表示给边界填充“0”让卷积的输入和输出保持同样的尺寸. 定义第1层卷积核的大小为5×5,通道数为1,使用32个不同的卷积进行计算;第2层卷积核为3×3,通道数为1,使用64个不同的卷积核进行计算.

表2 APK行为与权限特征映射表Table 2 Mapping of behavior and permission featurein the APK application
经过2次卷积池化处理,原本12×12的图片就转化成了3×3×64的向量. 图片的卷积处理过程如图5所示.
3 实验测试与结果分析
3.1 功能模块化测试
APK反编译模块unpackging.py反编译APK,批量获得AndroidManifest.xml文件,并分别被存储到不同编号的目录下.
获取APK权限申请模块list to csv.py,成功提取AndroidManifest.xml文件中声名的申请权限,转化为一维权限特征数组,并将1×144的数组存入one.csv文件,将578份恶意样本和5 369份正常样本分别存入目录0和目录1.
权限特征图片生成模块csv to pic.py根据采集到的权限特征数组集合成功生成5 947份12×12灰度图学习样本.
3.2 实验结果
3.2.1 实验数据以及来源
学习样本总体数量为5 947个,包括578个恶意样本和5 369个正常样本,每次学习30张图片,共计迭代计算次数为600,并获得准确率、召回率、误报率,经过多次迭代后获得稳定的结果,如表3所示.

表3 实验数据及来源Table 3 Experimental data and sources
3.2.2 CNN学习测试结果
经过多次实验测试,选取600作为最终的学习迭代次数,最终神经网络分类的准确率能够达到98.81%并稳定在这一数值,总体实验结果如表4所示.
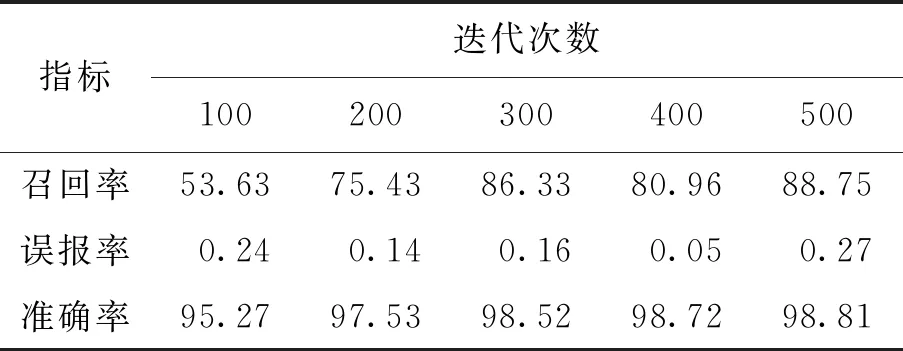
表4 实验最终结果汇总Table 4 Summary of the final results of the experiment %
根据以上实验结果进行分析,在迭代次数为500次及以上的情况下,准确率逐渐趋于稳定时能够达到98.81%,如图6所示. 图中曲线有较为明显的波动,分析其原因为部分实验样本没有经过分类筛选,因此,在学习的过程中使准确率发生波动. 实验结果生成的接受者操作特性曲线(receiver operating characteristic curve,ROC)如图7所示,曲线贴近纵坐标轴,比较靠近(0,1)坐标点,表示本模型基本满足对恶意应用的分类要求. 根据局部放大图,实验ROC波动较大,对比图7中的预期ROC,本文实验所使用的CNN模型还存在一定的过拟合问题,需要进一步扩增数据集来获得更好的分类模型.
通过进一步分析,本文对5 947个应用程序静态申请权限特征的实验样本进行学习,所提出的CNN分类方式已经能够达到98.81%的准确率,对于Android平台应用程序恶意代码的检测已经能够达到较高的检测准确率,并且照顾到了对硬件资源的节约和检测效率的平衡,预测增加样本数量之后,检测的准确率还能够进一步提高.
3.3 测试结果分析
在本次实验过程中,不断尝试对搭建的CNN进行了部分参数和构建函数的修改和调整,包括卷积核的大小、池化方法、不同的激励函数等,以寻求最高的检测准确率,并尽可能提高检测效率.
实验中考虑了对行为映射权限和普通权限的申请进行区分,设置了对照实验组. 在其他参数不变的情况下,一组保留对行为映射权限和普通权限的区分,另一组仅按照是否申请了该项系统权限进行处理,最终的实验结果如表5所示.

表5 有无权限区分的实验最终结果Table 5 Final results of the experimental with or without permission distinction %
经过对上述实验的对比分析,无权限区分的实验准确率高于有权限区分的实验准确率,但是,提高准确率的同时召回率有所降低,误报率有所升高,对于模型的检测分类效果是有影响的. 在实际情况中,将正常应用误判为恶意应用会影响该应用的下载量和使用量,但是如果将恶意应用误判为正常应用,则会对用户造成更严重的损失,因此,在识别准确率接近的情况下,牺牲一部分准确率来换取更低的误报率是可行的,也就是说,对行为映射权限和普通系统权限进行区分能够让分类器具有更好的识别分类效果.
对比现有基于贝叶斯分类检测方法,本文所提出的恶意应用检测方案具有更高的准确率(如表6所示),同时误报率较低,能够较好地分辨恶意应用. 贝叶斯分类算法的优势在于简单快速,特别是对小样本数量的分类有较好的效果,但是CNN的优势在于能够揭示不同权限特征之间的联系,并且将这种关系作为学习依据进行判断,对于本文实验中的数据集来说有更好的分类检测效果.

表6 其他分类方法实验结果对比Table 6 Comparison of experimental results of other classification methods %
但是从静态特征提取的角度分析,本文为提高特征提取速度以及深度神经网络训练速度,将方案提取的特征均存入12×12的图片之中,作为权限特征存储的信息媒介来说,存储量偏小,并且仅涉及144个静态申请的权限,对于一个应用程序是否包含恶意代码来说不足以精确地反映其特征,但本文实验主要考虑特征提取的简易程度,其优点在于提取方法简单、可靠,不需要复杂的提取流程,能够大幅缩短单个Android平台应用软件的检测时间,从而提高检测效率. 因为利用了CNN对权限特征进行学习,在一定程度上关注到了应用程序申请的权限之间的关系,而不是对单一的权限进行特征分析学习,通过这种对图形化的特征数据进行学习并分类的方法还具有一定的普适性,利用揭示申请权限之间的关系来进行恶意代码的检测,可以破解部分程序对恶意代码的伪装,例如大量申请无用权限来隐藏恶意代码真实需要的危险权限.
同时,本文中整体的实验设计也存在一定问题,比如对5 947个静态申请权限特征数据没有进行甄别和处理,还存在极个别样本特征提取表示不准确的情况,比如没有申请任何权限应用程序有可能就是APK文件反编译结果有误或是特殊种类的应用程序,对于样本集的处理还需要再进一步精确,减少过拟合情况对实验结果的影响.
4 结论
1) 经过实验,本恶意代码检测方案的准确率已经达到98.81%,并对包含未知类型的Android恶意代码有较好的检测能力.
2) 本文提出的方案利用CNN对权限特征进行学习,在一定程度上关注到了应用程序申请的权限之间的关系,通过这种对图形化的特征数据进行学习并分类,能够提高一定的方法普适性;利用揭示申请权限之间的关系来进行恶意代码的检测,也可以破解部分程序对恶意代码的隐藏.
3) 本文将深度学习的方法引入了Android平台的恶意代码检测,通过对应用静态申请特征的学习来检测是否含有恶意代码,达到了比较理想的分类准确率,在面对未知类型的恶意代码时有一个较好的检测效果,但是还存在一些不足:①实验方案需要再结合更全面的权限特征和应用代码特征. ②需要进一步扩大实验样本的数量,丰富样本的种类,并按照不同恶意行为实现对恶意应用的分类;需要进一步优化深度学习神经网络结构,降低过拟合情况对分类器性能的影响,提高准确率.
猜你喜欢
云南画报(2021年8期)2021-11-13
北京航空航天大学学报(2021年6期)2021-07-20
成都体育学院学报(2021年1期)2021-07-16
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
电脑报(2019年12期)2019-09-10
阅读(低年级)(2019年4期)2019-05-20
中国计算机报(2018年30期)2018-11-12
