
车牌识别系统中的字符分割和识别算法研究
2020-11-09 02:06武云飞
安阳师范学院学报 2020年5期
武云飞
(安徽工贸职业技术学院,安徽 淮南 232007)
随着人口的增长以及国民经济水平的不断提高,近年来汽车使用量一直在增加,汽车在交通运输中起着很大的作用,随之而来的车辆检测和违规行为抓拍成为影响车辆管理的关键。车牌识别是一种仅通过车牌识别车辆的图像处理技术,无须识别外部的卡片、标签或发射器,只需识别车牌即可。因而,实时车牌识别在交通规则的自动监控和公共道路的执法维护中起着重要的作用[1]。
车辆牌照的提取与识别是汽车识别领域的研究热点之一,王保全[2]提出了利用光学字符识别技术实现自动车牌识别的方法。惠人杰[3]给出了车辆自动识别的知识边界跟踪和模板匹配。李艳玲[4]将双向联想记忆(BAM)神经网络用于车牌识别,但是经验证它仅仅适用于少量的模式。马婉婕[5]提出了基于模糊逻辑和神经网络的汽车车牌识别算法,采用模糊逻辑进行分割,离散元神经网络(DTCNN)进行特征提取。考虑到单一类别车辆的形状和尺寸的多样性,使用简单的参数很难对车辆进行分类,当需要多个类别且在诸如遮挡、阴影、相机噪音、光线变化和天气状况等复杂环境条件时,识别过程变得更加困难。
1 车牌识别系统
在本研究中,基于车牌区域的提取、车牌字符的分割和字符的识别对车牌进行识别。本系统主要分为对象提取、目标跟踪、遮挡判定、遮挡区域隔离、给出车牌字符的分割、基于统计模板匹配算法的字符识别等几个模块。该系统的输入是由摄像机捕捉到的车辆图像,从4~5米外采集的图像,通过车牌提取器进行处理,并将其输出到分割部分,分割部分将字符单独分割。最后是识别部分,识别结果为车牌号码的字符。
1.1 目标定位
图像预处理模块。该模块目的是丰富边缘特征,由于检测方法是基于边界特征的,因此图像经过预处理可以提高检测模块的成功率。图像预处理模块使用的算法有灰度化、规格化和直方图均衡化。在获得灰度图像后,使用Sobel过滤器提取边缘图像,然后对图像进行二值化阈值处理。此后,使用局部自适应阈值算法进行二值化。
作为该算法的第一步,从相机捕获的图像首先转换成只有1和0组成的二进制图像(只有黑白)。通过对输入图像中亮度小于阈值的所有像素进行阈值化,使其像素值为0(黑色),其余像素为1(白色)。捕获的图像(原始图像)和二值化图像分别如图1(a)和1(b)所示。
图像二值化处理。为了找到平板区域,首先使用了涂抹算法,沿着垂直和水平方向(扫描线)对图像进行处理。如果白色像素的数量小于所需阈值或大于任何其他所需阈值,则将白色像素转换为黑色[6]。在这个系统中,水平和垂直涂抹的阈值都被选择为10和100。如果“白色”像素数< 10,像素则成为“黑”。
f白像素的数量{没有变化
>100像素变为黑
(1)
在得到板的位置后,只涉及板的区域被切割,得到图2。

图2 板图片
1.2 区域定位
对图像进行形态学操作,以确定印版的位置。为了找到准确的区域并消除其他区域,对图像进行了模糊和滤波处理。经过这一阶段处理后的图像如图3(a)所示,只涉及车牌板的图像如图3(b)所示。

图3 平板区域及图像
对于板区域的提取,基于边缘统计与数学形态学相结合的技术具有很好的效果。在这些算法中,通过计算图像不同部分的梯度幅值和方差,可以看出基于车牌区域的亮度变化比其他区域更显著和更频繁。然后,将边缘幅值高、边缘方差大的区域识别为可能的牌照区域。该方法不依赖于车牌边界的边缘,可以应用于车牌边界不清晰的图像,实现简单快速。一个缺点是基于边缘的方法很难单独应用于复杂的图像,因为它们对不想要的边缘过于敏感,而这些边缘也可能显示出很高的边缘幅度或方差(例如,车辆前视图的散热器区域)。尽管如此,结合去除处理后图像中不需要的边缘的形态学步骤,与其他方法相比,车牌提取率相对较高,速度也较快。
2 图像分割
2.1 分割步骤
图像分割阶段确定的候选车牌在车牌识别阶段进行检验。识别阶段主要包括字符分割分离和字符识别两个阶段。字符分割是通过投影、形态学、松弛标记、连通成分和斑点着色等技术来实现的。由于投影方法假设车牌的方向已知,而形态学方法要求知道字符的大小,因此这两种方法都不适合本文的应用。松弛标记本质上是迭代的,而且常常很费时间。
2.2 车牌分割
在本研究中,将车牌分割成多个组成部分,分别获得车牌字符。首先对图像进行滤波,增强图像,去除噪声和多余的斑点。然后对图像进行膨胀操作,使字符之间距离较近时进行分离。在此操作之后,应用水平和垂直涂抹来寻找字符区域。结果如图4所示。

图4 车牌字符位置

图5 单个字符
分割剪板字是通过在水平方向上查找字符的起始点和结束点来完成的。从底片上剪下的单个字符如图5所示。
3 字符识别
3.1 字符匹配
在字符识别之前,需对所有字符进行归一化处理,将字符细化为一个块,所有四个边都不包含额外的空白(像素),如图6所示。

图6 大小相同的字符
模板匹配需要采用拟合方法。为了使字符与数据库匹配,输入图像的大小必须与数据库字符相同,从车牌中提取的字符和数据库中的字符大小相等。下一步是模板匹配,就是将字符图像与数据库中的字符图像进行比较,得出最佳相似度。
3.2 模板匹配
为了度量相似度并找到最佳匹配,本文使用了霍洛维茨图像识别技术。该方法测量了若干幅相同尺寸的已知图像与未知图像之间的相关系数,同时计算图像中相关系数最高的部分之间的相关系数,从而得到最佳匹配结果。自相关函数(ACF)只涉及一个信号,并提供有关信号结构或其时域行为的信息。互相关函数(CCF)是对两个信号之间相似性或共有特性的度量。由于系统中存在未知输入图像和已知数据库图像两种信号,因此采用了互相关的方法。
令1≤j≤J和1≤k≤K的F1(j,k)和F2(j,k)分别表示要搜索的图像和模板的两个离散图像。图像对之间的归一化互相关定义为[7]:
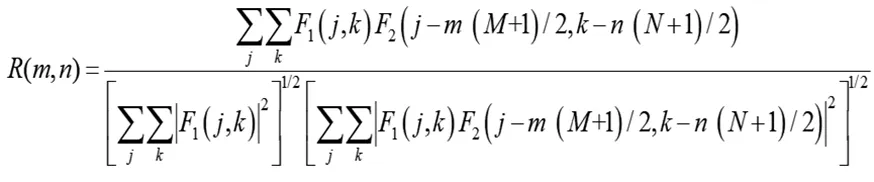
(2)
式中,m= 1,3,…,M和n= 1,3,…,N,其中M和N是奇数。
本系统建立专用数据库存储车牌字符,共33个字母数字字符(23个字母和10个数字),大小为36×18。形成的数据库如图7所示。

图7 数据库角色
由于一些汉字的相似性,在识别过程中可能会出现一些错误。易混淆的汉字主要有B和8,E和F, D和O, S和5,Z和2。为了提高汉字的识别率,系统对混淆汉字进行了标准测试,确定了汉字的特征。将字符特征应用在字符识别算法中,有效提高了识别率,使误差最小[8]。
4 算法实验
4.1 测试实验
测试在Matlab中设计完成,系统输入的图像为彩色图像,大小为1200×1600。实验图像是在不同光照条件下拍摄的。试验结果如表1所示。
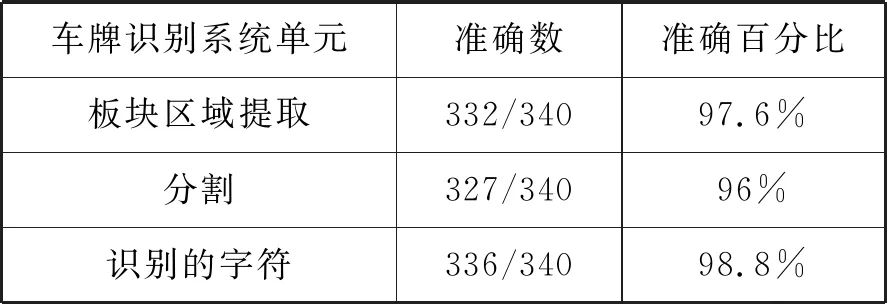
表1 测试结果
结果表明,提取车牌区域的正确率为97.6%,字符分割正确率为96%,识别单元正确率为98.8%。
4.2 实际实验
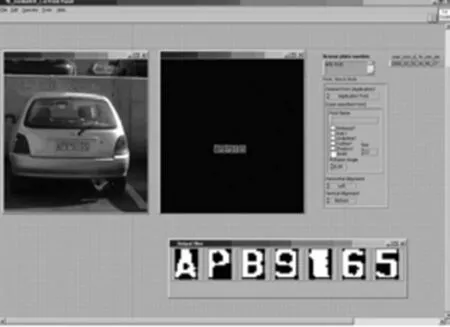
图8 车牌识别人机交互界面
在车牌定位实验中,使用了1088张不同场景和不同条件下的图像。其中,23幅图像未能定位到图像中存在的车牌,车牌定位成功率为97.9%。
5 总结
在车辆模型识别任务中,车牌位置在分割车辆前视图的特定参考区域时起着重要的作用。 本文介绍了一种用于汽车牌照识别的应用软件。首先提取车牌位置,然后通过分割对车牌字符进行单独的分割,最后利用模板匹配方法对车牌字符进行识别,并为每个车型创建数字签名。根据输入的车牌信息,从数据库中提取相应的模板图像,并将其与实时检测得到的图像进行对比。在实验中,分量彩色图像序列的帧分辨率为320×240。该系统是为识别车牌而设计的,并在大量图像上进行了测试。结果表明该算法对车牌区域的提取率为97.6%,对字符的分割率为96%,对识别单元的准确率为98.8%,在实际实验中整体系统的识别率为97.9%。在未来的研究中,该系统可以针对跨国汽车牌照进行重新设计。
猜你喜欢
动漫界·幼教365(中班)(2021年4期)2021-05-23
汉字汉语研究(2020年2期)2020-08-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
电子制作(2019年12期)2019-07-16
小猕猴智力画刊(2017年5期)2017-05-25
现代电子技术(2016年22期)2016-12-26
软件导刊(2016年11期)2016-12-22
科学与财富(2016年28期)2016-10-14
