
基于吉林一号卫星河道水质综合监测方法
2020-11-06 05:50朱熹刘黎明叶张林
中国水运 2020年9期
关键词:神经网络
朱熹 刘黎明 叶张林
摘 要:面对上海市的水环境监测需求,针对国产“吉林一号”卫星的多光谱遥感数据,及水文水资源管理署提供的河道断面采样点数据,提出了一种水质参数反演方法。以上海市浦东新区为研究区,总磷、氨氮、高锰酸盐、溶解氧为待反演水质参数,神经网络BP算法为反演模型,基于国家标准得到水质类别。实验结果显示,浦东新区内总磷为主要污染指数,遥感反演算法精度良好,能够应用于城市河道水质监测,为政府决策提供依据。
关键词:吉林一号;神经网络;水质反演
中图分类号:U61 文献标识码:A 文章编号:1006—7973(2020)09-0043-03
1 引言
清洁安全的水环境与人民的健康生活息息相关,也是社会可持续发展的基础。城市区域人口密度大,经济发展迅速,水环境的维护是重点也是难点,城市河流的监管任务充满了挑战。上海为了整治水体污染,按照分级管理属地负责原则,建立了市、区、街镇三级河长体系,力争在2020年完全消灭劣V类河道。因此为了保障人民群众的健康生活,维护城市的生态环境,水污染的及时发现就显得尤为重要,也对监管部门的发现及响应能力提出了更高的要求。遥感手段相较于传统的化学采样分析法,具有以下优势[1]:①响应速度快,遥感卫星可以实时传输影像数据,不需等待样本检测,即可为相关部门快速定位污染河道提供依据;②覆盖范围广,对于上海市各区镇可以完整覆盖;③实际成本低,相较于采样送检,遥感手段极大降低了污染定位的各类成本。
随着国家对于卫星遥感能力的重视,更多高时空分辨率的卫星升空,为建立完整的遥感监测网提供了可能性。而遥感水质反演技术依附于遥感硬件力量的成长,也获得了长足的进步,可反演的各类参数也扩充至叶绿素a、悬浮物、氨氮、总磷等。目前的水质反演方式主要分为分析方法、经验方法及半经验方法[5-7],其中,分析方法基于光谱的反射、散射及水体的吸收等方面考虑,建立在光学传输的物理基础上,具有严谨的推演逻辑,但是所需数据较多,模型构建困难,且也有一定的区域局限性。经验方法则是对采样数据与光谱数据统计关系建立模型[8],方法相对简便,但是局限性明显样本与卫星影像同步困难,且没有物理依据。Dekker[2]基于Landsat卫星的TM数据,对悬浮物和叶绿素a进行了线性和指数回归。半经验方法将已知的光谱特征与统计模型结合,分析相关性较优的谱段或谱段组合,多应用于高光谱遥感影像。Buckton[3,4]使用Meris数据和BP神经网络构建模型,反演了叶绿素a、黄色物质、悬浮物等水质参数,验证精度高于一般经验模型。
本文以长光卫星技术有限公司自主研发的“吉林一号”多光谱遥感影像及浦东新区水文水资源管理署提供的水质样本点数据为基础,对四项指标总磷、氨氮、高锰酸盐、溶解氧建立神经网络BP算法模型,在此基础上得到遥感水质参数的反演模型,并对其精度进行验证。
2 实验数据及预处理
2.1实验数据
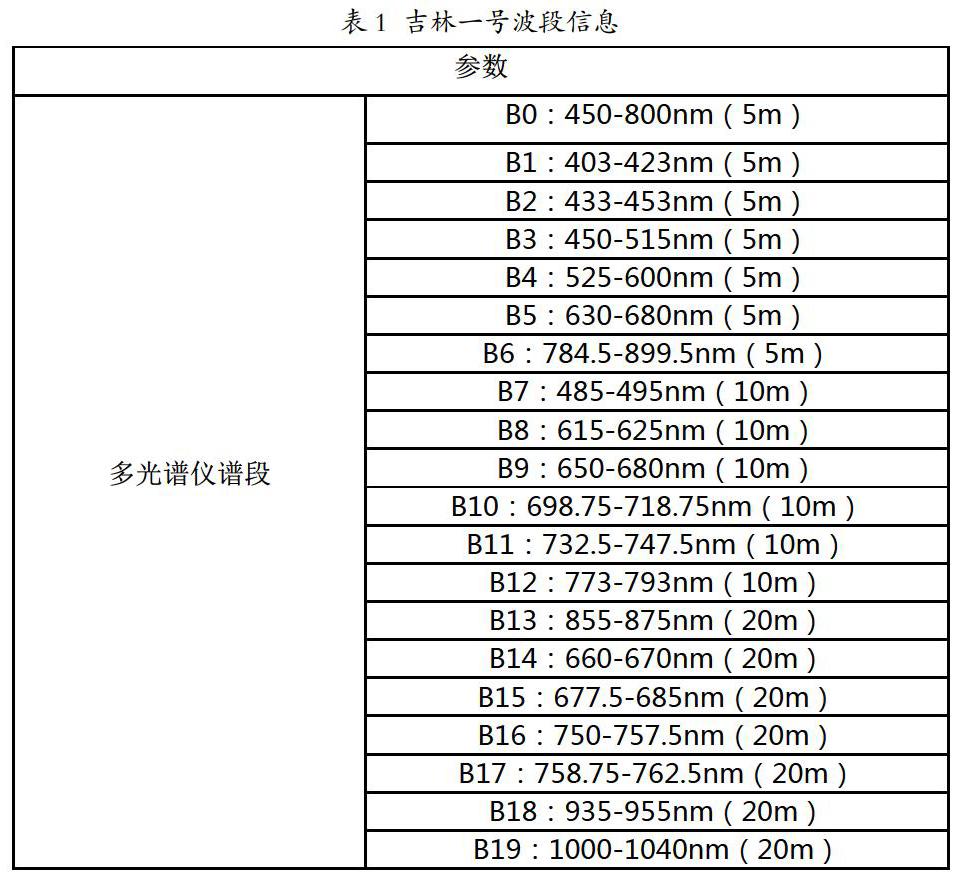
本文遥感卫星采用“吉林一号”,该卫星一箭四星包括一颗光学A星、两个灵巧视频星及一颗灵巧验证星。本次实验使用光学A星的浦东区四景多光谱数据,其包括B0-B19共20个谱段,其中,B0-B6空间分辨率为5m,B7-B12分辨率为10m,B13-B19分辨率为20m,重返周期为3.3天,幅宽有11.6公里,考虑到分辨河道的空间分辨率要求,选用B0-B6进行遥感水质反演,见下表。
水质参数采样数据获取的是卫星成像同一天的上海市河流断面实地采样分析数据,按照《地表水环境质量标准(GB3838-2002)》由水文水资源管理署提供737个断面采样点溶解氧(DO)、高锰酸盐指数(CODMn)、氨氮(NH3-N)、总磷(TP)共四项指标进行评价。
2.2数据预处理
在进行水质反演之前,需要对卫星遥感数据进行镶嵌拼接、辐射定标、大气校正以及几何校正,利用定标参数将遥感卫星获取的传感器记录的数字量化DN值转化为地表反射率。除此之外,利用NDWI对水体进行提取,一般阈值设为0,大于0的像元视为水体,整体提取效果良好,但是在细小河道由于混合像元现象严重,漏检明显,由于本实验主要针对市区镇管河道,所以NDWI可以较好达到目的。
针对水质样本点的预处理工作包含两个部分,一是剔除狭窄河道样本点,该区域混合像元现象严重,严重误导反演结果,二是通过标准阈值法剔除样本数据中的异常点。经过上述两步筛选,共计保留641个样本点数据参与之后的模型构建。
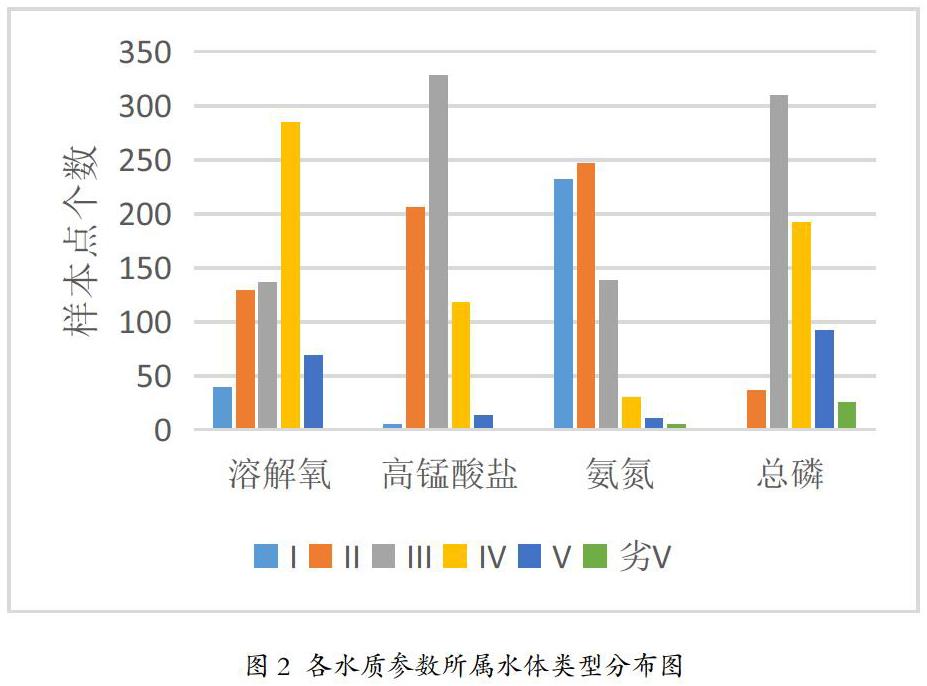
上图为筛选之后样本点各水质参数指标分布,总体上四水质指标展示整体水质良好,但仍然存在少量劣V类水样,及大量V类水样。由图可知,高锰酸盐指数表现最良好,主要集中为II-IV类水,总磷表现最差,V及劣V类水样占比最高,且不存在I类水样,超标通常源于生活污水和化工废水,主要是由人类活动造成。
3 基于神经网络BP算法遥感水质反演方法
3.1神经网络模型构建
神经网络模型作为一种半经验模型,近年来被广泛应用于卫星遥感反演。神经网络是一種模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部节点之间相互连接关系,从而达到处理信息的目的。其中,误差反向传播(BP)算法(图3)是神经网络中的基础,学习过程由信号的正向传播与误差的反向传播两个过程组成。正向传播时,输入样本从输入层传入,经各隐层逐层处理后,传向输出层。若输出层的实际输出与期望的输出不符,则转入误差的反向传播阶段。误差反传是将输出误差以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差信号即作为修正各单元权值的依据。这种信号正向传播与误差反向传播的各层权值调整过程,是周而复始地进行的。权值不断调整的过程,也就是网络的学习训练过程。此过程一直进行到网络输出的误差减少到可接受的程度,或进行到预先设定的学习次数为止。
猜你喜欢
客联(2022年3期)2022-05-31
中国教育信息化·高教职教(2022年4期)2022-05-13
计算技术与自动化(2022年1期)2022-04-15
计算技术与自动化(2022年1期)2022-04-15
计算技术与自动化(2022年1期)2022-04-15
计算技术与自动化(2021年2期)2021-11-10
西部交通科技(2021年9期)2021-01-11
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
智富时代(2018年7期)2018-09-03
智富时代(2018年7期)2018-09-03
