
基于大数据挖掘技术的工业锅炉性能优化升级研究
2020-11-06 00:55:26刘彩利
工业加热 2020年10期
刘彩利
(西安外事学院,陕西 西安 710077)
置身于互联网大背景下,各领域都被贴上数字化的标签,于电力行业而言亦是如此,正逐步朝着信息化的方向发展,现阶段以监控信息系统的应用最为广泛,受惠于现代信息技术,可确保各类数据的完整性,实现对数据的有效存储[1-2]。
1 相关工作背景
1.1 粗糙集理论
Pawlak经研究后提出粗糙集理论,其基本应用对象为信息数据系统,依托于粗糙集理论可实现高效化的数据分类,并确保信息分类能力的稳定性,使其在较长一段时间内不发生改变[3]。相较于前人的研究理论而言,Pawlak所提出的理论能够简化问题解决思路,实际分析工作中无需得到除数据库外的其他知识的支持,且具备与其余理论互补的条件。在长期发展之下,粗糙集理论已经得到广泛应用,在临床医学等领域均见其身影。粗糙集理论的鲜明特点在于属性约简,选取原始特征,在此基础上经筛选后获得最佳子集,并进一步选择突出特征,将大量无用数据删除,达到有效缩小数据维度的效果,有助于提升数据的研究效益[4-6]。本文也充分运用了粗糙集理论,引入了决策表属性约简算法,从而达到属性约简的效果,具体流程如图1所示。
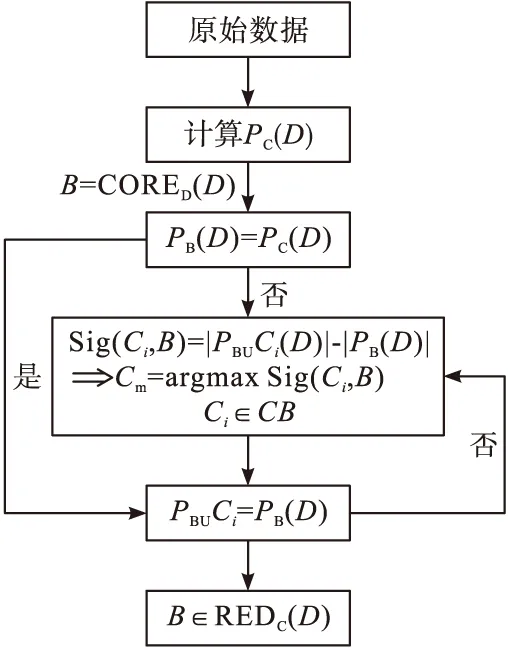
图1 属性约简的基本框架
1.2 Hadoop平台
依托于MapReduce主框架,可实现对数据的分析,此处采取的框架形式具有较强适用性,可实现对多类大数据问题的处理。其内置有Map和Reduce函数,具体指的是映射与归约函数,在其支持下可实现对数据的高效处理。立足于实际情况,针对数据源展开分散处理,基于

图2 MapReduce工作流程
2 RCK-means新算法流程
通过上述提及的MapReduce,经顺序组合后可得到特定程序,即RCK-means算法。类似于上述操作机制,需执行属性约简操作,实现对数据原件的处理,随后再一次执行Canopy 与K-means子框架。关于各流程,具体内容如图3所示。

图3 RCK-means算法流程
(1)在粗糙集理论的支持下,可形成初始决策表,并判定具体的条件与决策属性,通过对各自属性依赖度的分析,实现进一步的属性约简处理,经此环节后可筛除大量无关数据,余下的有用数据便可构成特性集合。
(2)通过 Canopy 算法中的Map函数,可实现对新数据几何的转换,使其成为与
(3)通过Reduce 函数,可实现对上述Map结果的进一步处理,即并集操作,此时可以得到Q集合,随后再运行Canopy流程,针对既有的程序展开多次处理,最终使得集合为空,便可求得聚类簇K,获得此结果后可将其作为输入值,以便做后续的处理。
(4)在上述基础上,通过K-means算法中Map函数,可求得聚类簇,将所得结果通过
(5)基于Combine 函数,能够实现对上述输出值的处理,将其分类后再数据归集,在求得各数据维度值的基础上,做进一步的总和计算。
(6)通过K-means 算法中的Reduce函数,针对(5)中求得的结果加以分析,考虑各数据的维度值,为之实行总和计算,并明确数据的具体数量,随后可创建新的聚类中心,以此为基础重新迭代,最终收敛。
3 在锅炉效率优化中的研究
3.1 运用大数据技术的意义
较为典型的优化方式有两种:第一,从燃烧器与受热面入手,为之采取升级整改措施,从而达到提升运行效率的效果,或是适配先进设备,在其支持下实现对参数的监测。尽管此方法的应用效果良好,但对于人力与财力的需求较大,因此经济效益较低。第二,基于DCS的数据挖掘技术,从而实现对锅炉性能的分析并确定合适的参数,此方式模型优化工作量相对较大,且在实际处理中易出现样本获取难度大的情况,不具备较高的实用性。DCS系统储有丰富的数据,将其作为实行大数据技术的基本支持,创建严密的计算流程,针对热力系统中涉及到的大量数据展开分析,从中确定与锅炉效率有关的几项参数,分析具体参数值与理论的误差,经此方式所得的参数值则具备作为最佳参数值的条件。对此,本文引入了K-means聚类算法,在此基础上辅以Hadoop框架,通过集(簇)聚类中心点实现对庞大数据群的分析,从中检验最合适的参数,确保所得参数具有可行性,成为提升锅炉运行效率的关键指导。
3.2 大数据挖掘对象
本文选取的是600 MW 燃煤机组锅炉,该装置适配的燃烧器采取的是摆动四角切圆形形式,数据总量129 600条,依据实际情况,重点从2018-10-01—2018-12-31时段内获取相关数据。
3.3 确定大数据挖掘目标
(1)排烟氧量。又可称为过量空气系数,伴随燃烧作业的持续发生,该值将随之减小,在此过程中锅炉未完全燃烧损失将呈现出明显提升的趋势,不利于锅炉燃烧效率;若过量空气系数偏大,有助于缓解不完全燃烧现象,但随之出现明显的排烟损失,也会对锅炉运行效率造成影响。从这一角度来看,需确定合适的取值范围,此举对于提升锅炉效率而言尤为关键。
(2)磨煤机给煤量。在特定负荷区间内,若磨煤机组合方式发生变化,或是煤量分配比随之改变,都会使得火焰中心高度处于波动的状态。若火焰中心高度偏高,则会对炉膛出口处造成影响,使得该处温度急速提升,并伴随大量的流换热量,降低了锅炉效率。
(3)一、二次风参数。锅炉炉膛温度的变化主要与一次风有关,若炉膛温度处于较高水平,将会提升燃烧速度,从而达到充分燃烧的效果;若炉膛的温度处于异常偏高的情况,将伴随明显的燃烧逆反应现象,也会出现燃烧不完全的问题。不仅于此,一次风还会影响到煤粉气流温度,会提早煤粉着火时间,在充分燃烧的作用下,将明显减少飞灰含碳量。同时,二次风也是重要的影响因素,该参数也将决定燃烧效果。总体上,一、二次风的良好配合是创建高效空气动力场的关键因素,在其支持下可提升煤粉与空气的混合效果,确保煤粉得到充分的燃烧。当锅炉处于稳定运行状态时,需以燃料量为基准合理调节一次风参数,由于两大因素呈线性关系,因此一次风不具备作为选用参数的条件。
(4)燃烧器摆角。根据燃烧器的基本形状,若为四角切圆形式,在该设备摆动之下,除了会引发火焰中心偏移现象外,还会对切圆直径造成影响,从这一角度来看,燃烧器摆角的控制尤为关键,是影响锅炉效率的重要因素。
3.4 大数据预处理
引入粗糙集理论后,只具备分析离散型数据的能力,但无法满足辨别数据关系的要求。而通过DCS归集后,可获得连续且具有非离散特性的信息,因此需要在分析之前实行DCS归集,通过此方式达到对信息分散处理的效果。现阶段,分散数据的方式较多,若基于传统的方式展开,易出现数据分割点判别难度大的问题,在缺乏合理的数据分散处理后,后续数据处理工作将受到严重影响,有价值的数据易被视为无用数据而排除。基于此,本文建议采用模糊粗糙集分散法,即兼顾了模糊集与粗糙集两种典型的方式,在其支持下实现对数据的分散处理,以达到数据属性约简处理的效果。采取此方式后,能够改变传统方式下粗糙集的局限之处,且提升数据判别的准确性。
3.5 大数据挖掘算法应用及结果
基于对数据的约简处理后,可通过RCK-means 算法进一步处理,实现对数据深度挖掘的效果。在Hadoop平台中,将支持度下限设置为2%。在此基础上,执行标准数据的处理流程,实现对约简集合的进一步处理,从中挖掘具有应用价值的参数,明确聚类中心点与锅炉效率间的最合适参数。基于实际分析得知,相较于排烟氧量最佳优化值而言,预先设置的实际值与之存在较为明显的偏差。若处于低负荷运行状态,相比于最佳优化值而言,设定值将比其更小,这一现象与锅炉难燃烧有关,伴随排烟氧量的增加,可有效控制不燃烧热,此时锅炉的运行效率随之提升。若负荷值处于较大水平,当超过500 WM时,将会显著提升锅炉燃烧效率,此时排烟含氧量最佳优化值也会出现明显的下降趋势,可以得知的是设定值大于最佳优化值。因此,若要达到效率最大化的目标,可通过设定值进行操作,针对各运行状况下的数据展开深度优化,基于此方式求得最佳参数值,提升锅炉性能。
4 结 语
依托于大数据技术,在其支持下展开数据挖掘,明确影响锅炉效率的主要因素,从中求得最佳参数值,以达到锅炉效率最大化的效果。通过RCKmeans新算法,有助于剔除无效数据,在此基础上求得最佳集合,确保了聚类准确率。从实际应用情况来看,为满足不同环境下的运行要求,可设定最佳区间,随后对各工作环境下的数据做针对性优化,最终求得最具适用性的参数值。
猜你喜欢
科教导刊·电子版(2021年6期)2021-05-06 05:05:10
大众投资指南(2021年35期)2021-02-16 01:06:26
成都信息工程大学学报(2019年2期)2019-08-28 10:00:46
自动化学报(2018年2期)2018-04-12 05:46:01
成都信息工程大学学报(2017年1期)2017-07-21 14:14:11
电力与能源(2017年6期)2017-05-14 06:19:37
厦门理工学院学报(2016年3期)2016-11-10 09:39:14
广东石油化工学院学报(2016年3期)2016-05-17 05:17:10
信息通信技术(2015年6期)2015-12-26 01:16:46
四川师范大学学报(自然科学版)(2015年1期)2015-02-28 14:07:21
