
近红外光谱技术结合竞争自适应重加权采样变量选择算法快速测定土壤水解性氮含量
2020-11-06 12:18:18彭海根詹莜国陈雅琼封幸兵钱发聪黄天杰
分析测试学报 2020年10期
彭海根,金 楹,詹莜国,陈雅琼,封幸兵,钱发聪, 黄 果,黄天杰,李 杰*
(1.四川威斯派克科技有限公司,四川 成都 610041;2.云南省烟草公司昆明市公司,云南 昆明 650051; 3.中国烟草总公司云南省公司,云南 昆明 650011;4.昆明市烟草公司嵩明分公司, 云南 嵩明 651700)
土壤作为作物生长的基础,其氮素营养是决定作物产量和品质的重要因素[1]。水解性氮是铵态氮、硝态氮、氨基酸、酰胺以及易水解蛋白质的总和,是土壤氮素的重要组成部分,与土壤全氮相比,更能反映土壤近期氮素的供应状况[2],快速准确的测定土壤中水解性氮含量并配合有效的氮肥施肥方案是作物快速生长的关键技术环节。传统土壤水解性氮的检测方法主要有酸水解法、碱解扩散法和碱解蒸馏法[3]等,但这些方法检测周期长、效率低,难以满足土壤施肥方案时效性的要求。相较而言,近红外光谱具有分析速度快、成本低、绿色无损、并能同时测定多种组分等优点[4],被广泛应用于土壤组分含量的检测[5-7]。
随着现代近红外光谱仪器硬件的发展,样品光谱通常包含大量数据点,信息复杂,谱峰宽且共线性严重,同时土壤中包含的大量无机组分在近红外谱区基本无吸收,需通过对其他组分的光谱响应或与其他组分之间的相关性才能被检测[8]。研究发现采用合适的波长变量筛选方法[9]可剔除不相关或非线性变量,从而简化模型并得到预测能力更强、更稳健的校正模型。因此,在建立土壤养分近红外定量分析模型前,有必要对土壤光谱进行波长筛选。贾生尧等[10]采用递归变量选择方法在预测过程中递归更新土壤全氮与有机质的特征变量,并获得了预测效果满意的模型;刘燕德等[11]和于雷等[12]将竞争自适应重加权采样(CARS)变量筛选方法应用于近红外光谱检测土壤组分,建立相应组分的校正模型,取得了预期结果,但上述研究所采用的建模样本较少且未针对特定地区建模。
本研究针对整个昆明地区不同类型的土壤,通过收集大量代表性样品,以土壤中水解性氮为研究对象,结合CARS有效特征波长筛选方法和偏最小二乘(PLS)建模方法,建立了在特定地区范围内准确性和稳健性更好的土壤组分近红外数学模型,可为实现应用近红外光谱方法快速、高效、准确地测定昆明地区土壤水解性氮的含量提供依据,也可为今后有效推进土壤平衡施肥提供重要数据支撑。
1 实验部分
1.1 材料与仪器
样品取自不同地块的表层土壤,分别属于昆明市管辖的安宁、富民、晋宁、禄劝、石林、嵩明、寻甸和宜良8个区县,共计963个。在制样前,首先采用标准方法GB/T17296-2009[13]对土壤进行分类。为减小水分和粒径对土壤光谱的影响,按照标准方法NY/T 1121.1-2006[14]对样品依次进行摊铺、清杂、风干、研磨和过筛,过筛时确保除碎石外的全部样品均通过20目筛网,然后采用四分法将每份制备好的样品分成两部分并编号,其中一部分进行光谱数据采集,另外一部分按标准方法[15]酸水解法测定水解性氮的含量。
采用美国Galaxy公司生产的QuasIR3000傅里叶变换近红外光谱仪采集土壤样品光谱数据,参数设置:采用积分球漫反射方式采集光谱,以仪器内置背景作参比;光谱扫描范围10 000~4 000 cm-1,其中样品原始光谱共包含1 574个数据点数;分辨率8 cm-1;光谱扫描次数为64次。
1.2 校正集与验证集划分
在建立近红外定量模型前,将样品分为校正集和验证集,其中校正集用于拟合数据,建立模型,验证集不参与模型建立,用来评价所建模型的实际效果和预测误差。采用Kennard-Stone(K-S)方法[16]按约1∶9的比例从全部样品中挑选90个样品作为验证集,剩余873个样品作为校正集,具体步骤如下:首先计算所有样本两两间的欧氏距离,选择距离最远的2个样本进入验证集;然后计算剩余样本与所选择样本的最短距离,把其中距离最大的样本从未选中样本集中移入验证集;最后依次迭代运算,直至模型验证集中的样本数量达到指定数目。
1.3 数据预处理
样品原始光谱除样品自身信息外,往往还包含外界因素的干扰,需对光谱数据进行预处理。常用的光谱预处理方法[17]包括多元散射校正(Multiplicative scatter correction,MSC)、标准正态变换(Standard normal variate transformation,SNV)、导数、平滑处理和小波变换(Wavelet transform,WT)等,其中MSC和SNV可消除颗粒分布不均匀及颗粒大小产生的散射影响,在固体颗粒漫反射光谱中应用较广泛;导数处理既可以消除基线偏移,还可以起到一定的放大和分离重叠信息的作用,但由于噪声信号也被放大,因此通常在导数之前需对光谱数据做平滑处理;原始光谱经过导数处理后再进行WT去噪声处理,可使光谱信噪比增大,从而提高分析精度。
1.4 CARS方法
CARS方法[18]模仿达尔文进化理论中的“适者生存”原则,每次通过使用重加权采样(ARS)技术筛选出PLS模型中回归系数绝对值大的波长点,去掉权重小的波长点,利用交叉验证选出模型交叉验证均方差值最低的子集,可有效选择与所测性质相关的最优波长组合。其基本算法如下:假定光谱矩阵为X(m×n),m为样本数,n为变量数,y(m×1)表示目标性质向量,e为校正误差,PLS校正模型可用下式表达:y=Xb+e,那么任一隐变量数下回归系数向量b=[b1,b2,…,bn]。b中第i个元素的绝对值|b|(1≤i≤n)表示第i个波长点对y的贡献,|bi|值越大则表示该变量越重要。为评价每个波长的重要性,定义权重Wi:
通过CARS法去掉的变量,其权重Wi均设为0。
①采用蒙特卡罗采样法采样N次,每次从样品集中随机抽取一定比例(通常为50%~80%)的样品为校正集,分别建立PLS回归模型,得到相应的回归系数。
②利用指数衰减函数(Exponential decreasing function,EDF)强行去掉|bi|值相对较小的波长点。
③通过N次ARS技术筛选出模型中回归系数绝对值大的波长点,用每次产生的新变量子集建立PLS回归模型,计算各模型的交互验证标准偏差(RMSECV),选择RMSECV值最小的子集,即为最优变量子集。
1.5 模型建立与验证
采用PLS[19]建立校正模型,可很好地解决自变量间存在多重相关性和样本数量小于波长数量的问题,同时,对系统解释能力较强的综合变量能够被有效提取,从而排除无解释能力的信息,对变量解释能力增强。本文采用交互验证和验证集验证相结合的方式,并以相关系数(R)、RMSECV和预测标准偏差(RMSEP)等评价参数综合评价模型效果。其中R值越接近1,表明模型回归(或预测)结果越好,Rcv和Rp分别表示模型交互验证和外部验证过程中的模型相关系数。对于同一批次样本,RMSECV和RMSEP值越小说明模型交互验证与验证集验证模型预测效果越好。应用K-S方法挑选样品,CARS方法筛选波长变量,PLS模型建立和预测以及图表绘制均采用Matlab R2019a实现。
2 结果与讨论
2.1 样品统计结果
土壤样品的分类结果见表1,种类涵盖昆明地区的红壤和水稻土2种主要土壤类型,同时又各自包含6种不同类型,具有代表意义。由于采用标准方法对土壤分类对研究人员的要求较高,因此为方便方法的推广,将2种土壤样品混合进行建模。

表1 样品基本信息表Table 1 Basic information of samples
采用K-S方法划分的水解性氮校正集与验证集的参考值统计结果见表2,水解性氮的验证集样品参考值含量变化范围包含在校正集变化范围内,表明校正集样品所建立的校正模型能较好地适用于验证集样品。

表2 样品参考值统计结果Table 2 Statistical results of sample reference value
2.2 不同预处理方法结果
分别采用MSC、SNV、MSC+一阶导数+平滑、SNV+一阶导数+平滑和WT对土壤样品原始光谱数据进行预处理,并采用全波段结合PLS方法建立校正模型(表3)。结果显示,不同预处理方法获得的模型剔除的异常样品数量也不同;其水解性氮PLS模型的结果差异较大,但原始光谱经WT预处理后模型的RMSECV最小,且Rcv最大,表明该模型效果最佳。因此,波长变量选择和建模时均采用小波变换处理原始光谱图,样品原始光谱图和经WT变换后的光谱图见图1。图1显示,样品原始光谱图在经过WT变换后,能够有效地消除样本光谱数据间的基线漂移、随机噪声等现象。

表3 不同预处理方法的模型计算结果Table 3 Calculation results of models with different pretreatment methods

2.3 CARS方法筛选波长变量
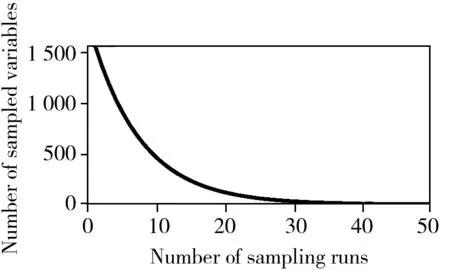
采用CARS方法进行光谱变量筛选,反复迭代采样次数并比较每个采样次数的RMSECV值,直至找到最小RMSECV值所包含的最优变量子集。图2显示了水解性氮进行50次CARS运行的变量选择过程。由图可见,CARS方法在选择光谱变量的过程中,随着采样次数的增加,被选择的波长变量数逐渐下降,下降趋势由快变慢(图2A),同时RMSECV曲线呈先缓慢下降至最低点后又逐渐上升的趋势(图2B)。同时发现有些变量回归系数的绝对值不断变大,而另一些变量回归系数的绝对值却不断变小(图2C),表明过程中先剔除了与水解性氮无关的波长变量,使RMSECV值下降,而后又剔除了与组分相关的波长变量,信息丢失导致RMSECV值增加。图2中垂直星点标记的位置对应整个变量筛选过程中RMSECV值最小,对应的变量数为178个。
2.4 定量模型建立与验证
分别采用小波变换方法对原始光谱进行预处理,再采用CARS方法筛选出波长变量并结合PLS建模方法,建立水解性氮的定量校正模型,最后使用K-S方法挑选出来的验证集验证模型的预测误差,结果见表4。对比表3~4的结果发现,采用CARS方法对土壤样品原始光谱进行波长变量筛选后的模型参数有所改善,即模型的RMSECV分别由31.63降至25.55,Rcv由0.78提升至0.84,表明CARS方法可有效筛选土壤相关波长变量,并剔除其他无关变量,从而改善模型结果,其中模型交互验证过程的RMSECV和Rcv随因子数变化的趋势如图3所示。另外,由于实验所用土壤样本数量大,难免会遇到参考值或光谱异常的样本,本研究在模型拟合过程中剔除了39个异常样本。为进一步验证所建模型的效果,采用建立的模型预测挑选出的外部验证样品,并将模型预测值和参考值进行对比,得到模型的RMSEP为29.83,Rp为0.79,计算得参考值和预测值的平均相对偏差为12.50%。

表4 模型计算结果Table 4 Calculation results of models
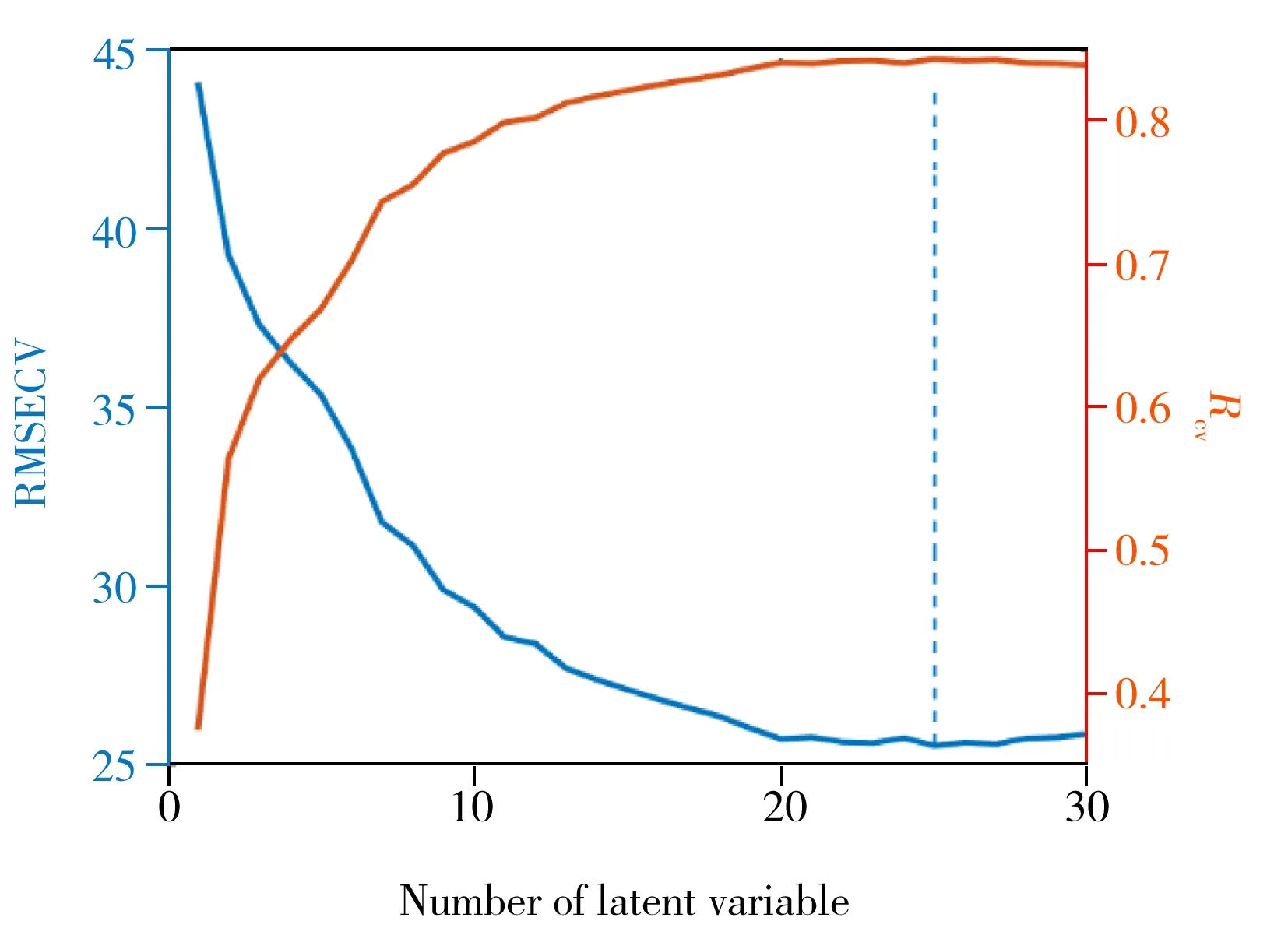
图3 水解性氮建模的RMSECV和Rcv随因子数变化的趋势图Fig.3 A plot of RMSECV and Rcv versus factors for hydrolytic nitrogen
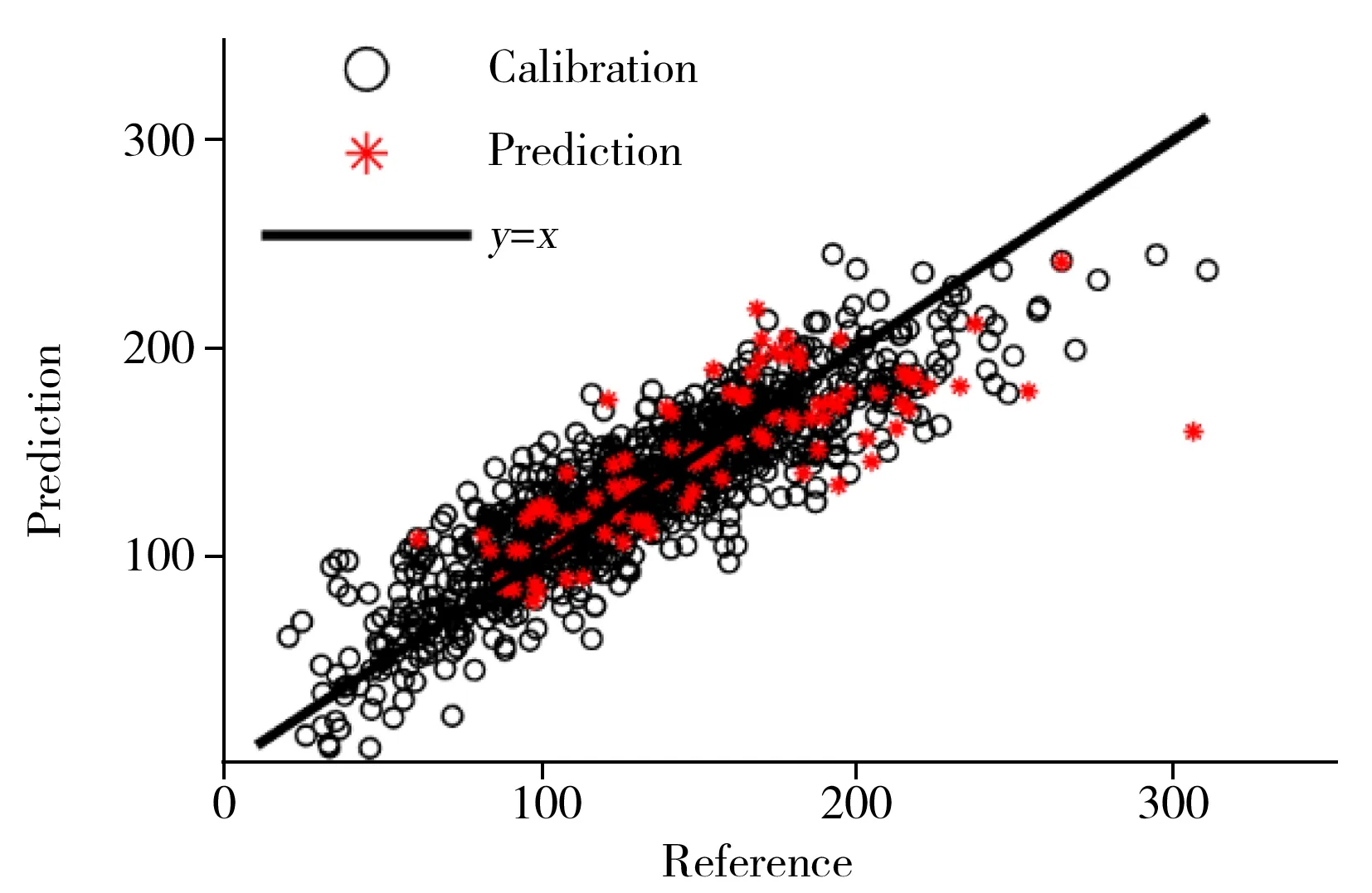
图4 水解性氮校正集和验证集的参考值与预测值散点图Fig.4 Scatter plot of laboratory measured values versus model predicted values for calibration set and prediction set of hydrolytic nitrogen
模型校正集和验证集的参考值与预测值拟合的散点图见图4。图4显示,模型验证集样品均匀分布在土壤水解性氮整个浓度范围内,具有代表性,表明验证集样品的验证结果能够真实反映模型预测结果,且验证集样品的参考值和预测值偏差较小,平均相对偏差仅为12.50%,进一步表明采用CARS方法能有效筛选土壤相关波长变量,从而改善模型结果。
3 结 论
本研究采用CARS方法筛选土壤光谱波长变量,并建立水解性氮的PLS定量分析模型,研究结果显示:①近红外光谱技术结合CARS方法,在大量代表性样品建模下,可有效建立昆明地区不同土壤类型的水解性氮含量的近红外数学模型,模型RMSECV由31.63降至25.55,Rcv由0.78提升至0.84,模型外部验证时的RMSEP和Rp分别是29.83和0.79,预测的平均相对偏差为12.5%;②在采取有效的波长变量筛选和建模方法的基础上,应用近红外光谱技术快速测定土壤含量较低的组分时,同样能取得较好的结果。本方法可推广应用于土壤其他组分的近红外检测。
猜你喜欢
特产研究(2022年6期)2023-01-17 05:06:16
国学(2020年1期)2020-06-29 15:15:30
天然产物研究与开发(2018年7期)2018-08-21 02:04:12
数学物理学报(2017年6期)2018-01-22 02:26:53
实用口腔医学杂志(2017年6期)2017-09-19 02:51:28
摄影之友(影像视觉)(2017年1期)2017-07-18 11:12:16
中学化学(2016年2期)2016-05-31 05:27:22
中国照明(2016年4期)2016-05-17 06:16:15
课程教育研究·下(2016年2期)2016-03-25 13:45:48
物理实验(2015年9期)2015-02-28 17:36:46
