
发电侧燃料管理系统及燃煤优化预测研究
2020-11-04 06:02:08赵玉柱卢伟辉张中林
浙江电力 2020年10期
赵玉柱,卢伟辉,王 寅,张中林
(1.中国南方电网有限责任公司调度控制中心,广州 510623;2.南京华盾电力信息安全测评有限公司,南京 210013;3.南京工程学院 能源与动力工程学院,南京 211167)
0 引言
2018 年火电企业发电量占总发电量的71%以上,依然是国内电网主要发电来源,火电企业的安全稳定运行对于电网的安全至关重要,而燃料问题是火电企业面临的根本问题。由于受到能源政策、供需形势、资源分布、供应价格、交通运输、市场博弈等多种复杂因素的影响,燃料供应存在一定的随机性和不确定性,造成电网和调度机构难以充分了解和掌握火电企业的燃料运行状态,电网调度和火电企业产能之间匹配不够,无法做到科学调度,一旦发生大面积燃料供应问题,将严重威胁到电网的安全运行。
为了应对燃料问题,火电企业和火电发电集团陆续建立了燃料的信息化管理系统[1-6],通过信息化技术实现了对燃料的有效管理,对燃料从采购到入炉进行全面管控。但是目前所建立的大量燃料管理系统只是对传统燃料管理的信息化,而且范围局限在一个厂区或者某个区域之内,主要问题是不能对火电企业的燃料供应进行智能化预测和管控,无法对燃料计划和采购提出指导意见。对于电网而言,在实现厂网分离后,火电企业的燃料计划、采购和库存等信息处于盲区,这给电网的调度带来困难,同时也威胁到电网的安全稳定运行。
为了解决电网与火电企业燃料管理脱节的问题,迫切需要建立统一区域燃料信息管理系统,同时利用大数据和云平台建立发电燃料预测系统,利用该系统实现区域燃料统一管理和燃料需求预测,确保燃料安全,保证电网的安全稳定运行。
本文利用互联网+技术构建南方电网(以下简称“南网”)燃料管理系统,在此基础上构建南网范围内的大数据平台,不仅实现了南网范围内的燃料有效管理,还可以通过预测模型准确预测燃料需求,确保南网范围内火电企业燃料安全。
1 燃料管理系统构建
1.1 燃料管理系统结构
所构建的燃料管理系统主要基础数据分散在各个燃煤和燃气电厂,在信息安全要求较高的条件下,要求该燃料管理系统既要实现火电企业燃料数据的实时采集和传输,又要确保数据和信息的安全。
图1 为燃料管理系统的网络拓扑和硬件布置结构,主要硬件包括两台数据服务器、数据采集终端、数据采集网络和防火墙。
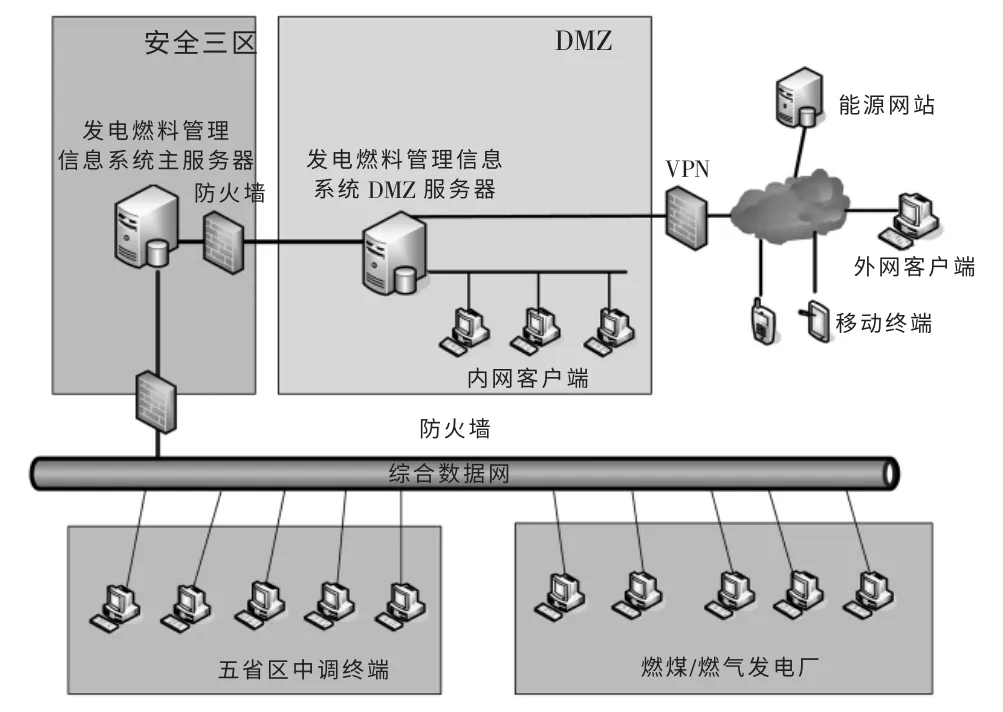
图1 燃料管理系统网络和硬件结构
数据采集终端布置在各个火电企业,通过接口上传火电企业燃料管理系统中的相关数据,布置在中调的终端负责区域的燃料数据收集和上传。由于各个数据采集终端地理位置具有分散性,需建设统一的综合数据网络用于基础数据传输。
服务器的建设采用分区和分层方式,在安全三区布置有主服务器,在DMZ(隔离区)布置DMZ服务器,各个服务区之间采用防火墙隔离,确保数据安全。数据采集终端所采集的数据通过综合数据网络上传至主服务器,DMZ 服务器是主服务器安全备份,内部客户端可以与DMZ 服务器进行数据交互,移动终端等外围智能终端通过互联网和防火墙与DMZ 服务器交换数据。
1.2 数据接口
系统提供各类数据接口,实现与其他系统的数据互联,数据接口主要特性如下:
(1)采用通用的标准数据接口方式。
(2)采用OSB(Oracle 数据服务总线)实现与DMIS(调度指挥管理信息系统)等业务系统的数据交互。
(3)充分考虑现行数据源发生改变的可能,具备灵活、可扩展性强的数据接口实现方案。
(4)实现发电燃料基础信息、燃煤电厂盈亏测算等应用的OSB 服务封装。
1.3 燃料数据直采
燃料数据的直采对于系统数据实时性非常重要,南方电网发电燃料管理信息系统实现了发电厂燃料数据的自动采集功能。通过接口程序,将发电厂燃料数据从发电厂本地燃料数据库中自动采集上传到部署在南网总调的发电燃料管理信息系统数据库中。
采用Oracle 公司的OSB 方式进行数据传输,OSB 提供WebService 和MQ 两种技术标准的数据传输方式,系统在实现燃料数据直采时结合数据交互的具体要求可任意选择其中的一种:对于实时性要求高但数据量不大的交互场景可以采用WebService 方式;对于实时性要求较低或数据量较大的交互场景可以采用MQ 方式。通过接口程序,采用WebService 或MQ 方式将发电厂本地数据库中的发电燃料数据通过综合数据网自动采集上传到南方电网发电燃料管理信息系统数据库中,实现数据的自动采集和上传。这两种方式提高了燃料数据直采的灵活性和适应性,能够适应不同场景数据采集的要求,确保了燃料基础数据准确和实时采集。
2 发电燃料综合管理平台
2.1 燃料综合管理平台
利用所采集到的火电企业燃料基础数据,建立燃料综合管理平台。除了日常燃料数据分析与管理功能,在该管理平台内开发了燃煤电厂盈亏测算模块,主要功能如下:
(1)基于K-means 聚类算法,建立火电企业燃料大数据模型。
(2)以标杆发电厂(示例发电厂)数据为基础,完成测算;随着模型中变量的更改,可展示不同的计算结果。
(3)具备单一变量灵敏度测算功能。
(4)建立全网所有燃煤电厂各项成本及上网电价、煤价等数据库。
(5)盈亏模块测算的主要参数有发电厂利润、盈亏平衡点、单位发电边际利润、对应设计利用小时数盈亏平衡点标煤价。
2.2 燃料管理大数据研究
K-means 算法流程如图2 所示。
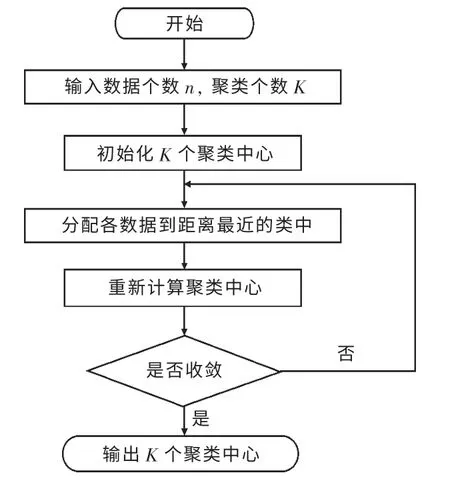
图2 K-means 算法流程
K-means 算法是一种基于划分的聚类算法,是数据挖掘中的一种经典算法,其中n 表示输入样本数,K 表示有多少个类,即簇的大小,在给定的数据集中使得规定的误差达到最小的K 个分类,其中所有类中的均值则由means 来表示。K-means 算法高效且简单,对大数据有较高的运行效率,比较适用于大规模数据聚类[6-8]。
K-means 算法的基本思想是:
首先需要根据一定准则或随机指定K 的大小,即将数据集分成K 个簇;然后随机初始化K个点作为K-means 算法样本;计算各数据元素到已经初始化的聚类中心的距离,根据计算得到的结果(也就是与簇心的距离)进行对比,根据一定规则将该数据元素分配至最邻近的簇中。采用物理上计算重心的方法调整每个聚类中心(将聚类中心移动至中心位置),反复迭代执行,比较两次聚类中心移动的位置,如果移动位置小于某个值或者未移动,表明算法收敛,当所有聚类中心都收敛表示算法已经结束。

传统的K-means 算法自身存在主观给定K值、随机给定初始点的局限性,导致聚类结果不稳定。文献[10]提出了一种改进的K-means 算法,通过加入密度系数的最大权值法分析电网用户的用电行为,选取距离最远的密度样本时采用评价函数权值计算法,考虑簇间距离和簇内距离,并通过UCI 数据集验证算法的准确率和稳定性[10]。本文利用该改进的K-means 算法分析南网电源侧燃料特性。
定义新的评价函数ω 为:

式中:s(i)为簇间距离;Nε(xi)为样本密度函数;a(i)为簇内样本的平均距离;xi为样本数据。
Nε(xi)定义为:
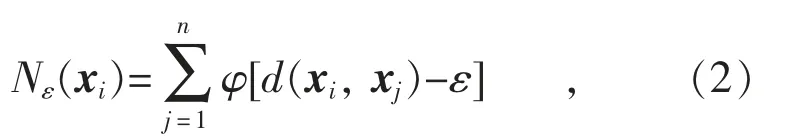
式中:d(xi,xj)为任意两个数据对象之间的欧氏距离;ε 为残差;。
a(i)定义为:

式(1)中:Nε(xi)越大,表示样本点i 周围元素点越多,元素越集中;a(i)越小,1/a(i)越大,表示簇中元素越密集;s(i)越大,表示两簇之间距离越远,其相异度就越大。因此,通过最大权值法可以求出最佳聚类中心,而密度参数的引入使得初始中心的选取更具客观性。
利用改进的K-means 算法对2018 年南网所有燃煤电厂的入炉燃料品质进行分析,将发电厂采购的煤质按照入炉情况进行分类,主要指标包括发热量、硫分、灰分等指标分为A,B,C,D,E 5 个等级,具体指标如表1 所示。通过K-means算法大数据分析,得到初始聚类中心和最终聚类中心如表2 所示,南网2018 年发电厂采购煤炭的品质分布如图3 所示。
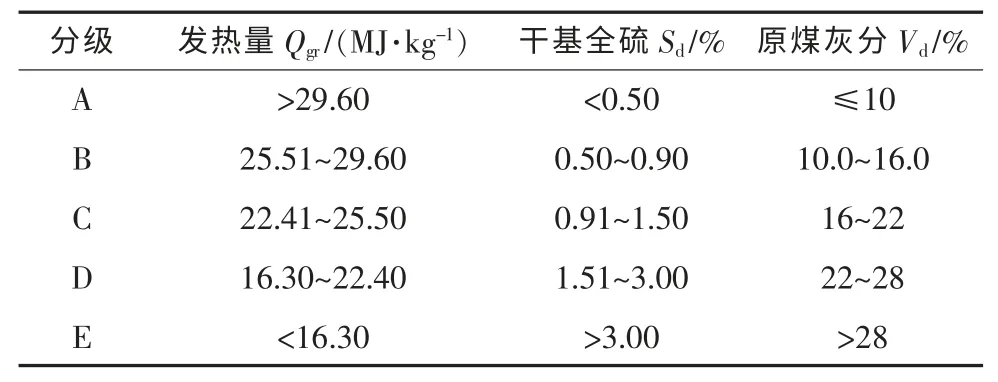
表1 燃煤等级指标

表2 K-means 聚类中心
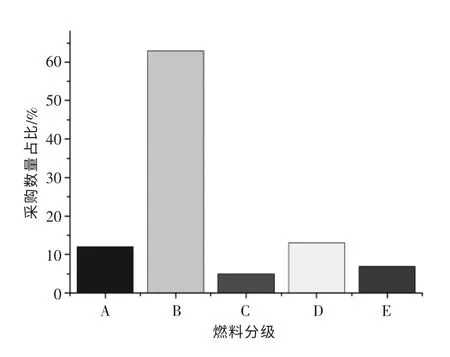
图3 2018 年南网火电企业电煤煤质分布
由图3 可以看出2018 年南网发电厂所采购的煤炭比较优质,B 等级的煤炭采购量占60%以上,其发热量在24.13 MJ/kg 左右,含硫率普遍在1%以下,灰分含量低于15%。但同时也存在着采购劣质煤的情况,其硫分和灰分含量均较高。
3 发电燃料供应预测
在已有的大数据基础上,采用合适的模型建立南网燃料预测方法,对于确保南网的燃料安全非常重要。目前的主要预测方法包括定性预测、时间序列平滑预测、自适应预测、自适应预测和回归预测等方法[11]。本文采用ARMA(自回归滑动平均)模型用于燃料预测,ARMA 模型[12-14]是目前最常用的拟合平稳时间序列的模型,由自回归模型和滑动平均模型“混合”构成。ARMA 模型在市场中常用于长期追踪资料的研究,如随季节变动特征的销售量、价格、市场规模预测等[15]。
ARMA 模型族是平稳序列的一种重要模型族,但对于有季节性等非平稳序列,该模型就不再适用。ARIMA(差分整合移动平均自回归)模型通过差分将时序平稳化,然后用ARMA 模型讨论差分后的时序,一般非季节性的ARIMA(p,d,q)模型形式为:
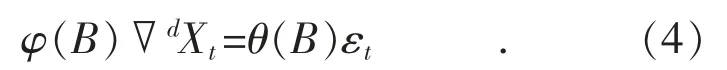
乘积季节模型是随机季节模型与ARMA 模型的结合式,其阶数为(p,d,q)×(P,D,Q)S,形式为:

式(4),(5)中:εt为残差;Xt为原始数据序列;B为优化参数;S 为一个季节循环中的观测个数;φ(B)▽dXt表示同一周期内不同周期点的相关关系;表示不同周期的同一周期点上的相关关系。
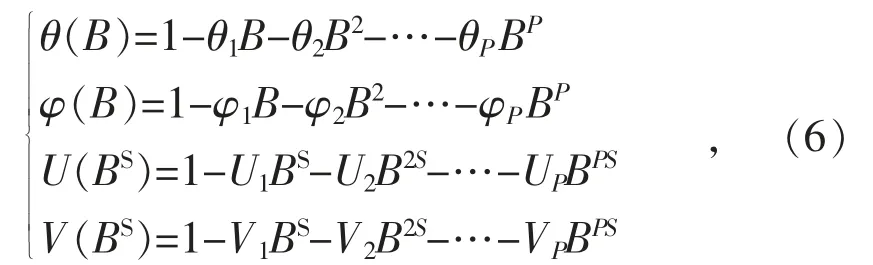
式中:θi,φi,Ui,Vi均为系数。
建立南网燃料预测模型主要有以下步骤:
(1)平稳化处理。将原始数据的不平稳时间序列转换为平稳时间序列。
(2)模型识别与定阶。根据自相关图和偏自相关图,建立预测模型,确定模型参数。
(3)模型参数估计。由自相关图确定参数q和Q,由偏自相关图确定p 和P,结合AIC(赤池信息准则)和BIC(贝叶斯信息准则),最终确定p,q,P,Q;根据数据的平稳性确定参数d;根据数据的周期性确定参数D。
(4)模型适应性检验。进行残差独立性检验或异方差检验,修改预测模型,直至残差序列为白噪声序列,提取所有有用信息。残差检验公式为:
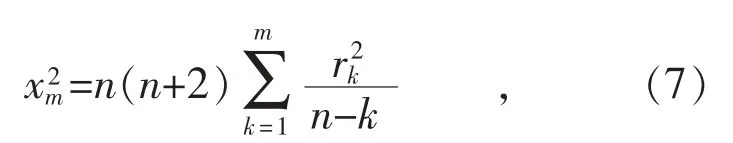
将图4 中的实际值进行数据平稳化处理,绘制南方电网发电燃料原始数据的时间序列图、自相关图和偏相关图,通过一阶差分和季节差分后消除了其中的二次趋势,得到模型参数d=D=1。
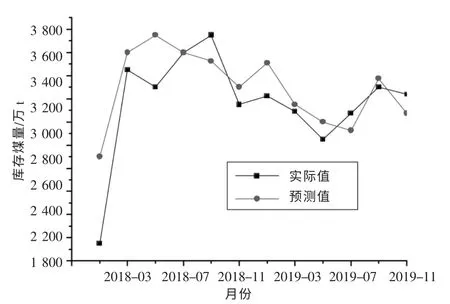
图4 2018—2019 年南网全网燃料量预测值和真实值对比
由自相关图和偏相关图,经试算比较后当ARIMA(0,1,1)(0,1,0)12时BIC 值最小,即此时p=0,P=0,q=1,Q=0。对模型进行适应性检验,残差为白噪声,所有信息都被提取,模型适应性检查通过。
南网全网发电燃料预测最终模型为:

利用所建立的预测模型对南网燃料量进行预测分析,如图4 所示。该模型在考虑历史数据和影响因素的前提下,更好地反映了发电燃料供应的季节性。与实际值对比结果表明,预测值能准确反映南网火电企业燃料量变化,该预测方法具有一定的准确性和精度。
4 结语
厂网分离提高了能源企业的竞争力,但是电网侧与电源侧的脱离也造成电网对电源侧的信息(尤其是各个能源企业燃料储备和燃料品质情况)掌握不足,造成在电力调度过程中存在一定的盲目性,威胁到电力系统的安全稳定运行。因此,迫切需要利用互联网+技术,构建全网统一的燃料信息管理和预测优化平台,利用大数据对全网燃料特性和品质进行实时分析,并对燃料库存进行预测。
本文主要内容总结如下:
(1)以OSB 方式构建了全网统一的燃料信息管理平台,实现了电源电网侧燃料数据的实时共享。
(2)以信息化技术为基础,利用K-means 算法和大数据对燃料品质等特性进行分析,进一步掌握全网的燃料主要特征。
(3)利用ARMA 模型,建立全网燃料预测模型,通过与实际值比较,验证了模型的正确性。
本文通过建立全网燃料信息化平台,实时了解全网燃料运行状态,通过大数据分析燃料品质,利用预测模型预测燃料库存,提高了燃料安全性,确保了电网安全稳定运行。
猜你喜欢
农村电气化(2022年7期)2023-01-07 01:03:45
英语文摘(2021年8期)2021-11-02 07:17:58
小学科学(学生版)(2021年5期)2021-07-22 02:40:06
中国电业与能源(2021年3期)2021-04-16 07:01:38
军事文摘(2020年14期)2020-12-17 06:27:16
河北电力技术(2020年1期)2020-04-15 09:39:12
广西电业(2020年11期)2020-03-23 07:14:24
通信电源技术(2018年5期)2018-08-23 01:17:06
能源(2015年8期)2015-05-26 09:15:36
自动化博览(2014年4期)2014-02-28 22:31:18
