
面向不完备数据的民航旅客流失预测模型
2020-11-03 00:59:46王怀超
计算机工程与设计 2020年10期
李 国,袁 闻+,王怀超
(1.中国民航大学 计算机科学与技术学院,天津 300300;2.中国民航大学 中国民航信息技术科研基地,天津 300300)
0 引 言
中国民航旅客信息服务主要由中国民航信息股份有限公司的新一代旅客服务信息系统提供,其由21个相对独立的子系统组成,在航班信息查询、航班预定、出票、航班离港、费用结算、旅客画像等核心业务中承担主要工作。由于各系统之间标准数据结构定义不同,存取方式不同,系统之间通信方式差异等多方面原因,从而造成数据缺失、数据冗余、数据不一致等数据质量问题,从而影响到后续旅客流失预测分析及其它方面的应用,对航空公司收益造成巨大的损失[1-3]。
本文所研究的问题为基于民航旅客服务信息数据不完备且类别不平衡的情况下,对旅客进行流失预测。传统的方法将此问题分开串行处理,先将数据集缺失数据使用基于统计的方法或基于机器学习的方法进行填补,再将填补后完整的数据集进行旅客流失预测模型构建,因没有关注任务之间的相关性,导致当数据集属性维度较多,且缺失率较高时,填补后的数值与真实值差异较大,从而影响预测任务精确性。
针对上述问题,本文考虑到两个任务之间的相关性,提出以多任务学习为框架,将旅客流失预测作为主任务,缺失数据填补作为辅助任务,利用两个任务之间的相关性,将两个任务在深度学习模型下同时并行建模,在提高数据处理与分析效率的同时,极大提升了预测精度。实验结果表明,本文提出的方法在数据不完备的条件下对缺失数据的填补质量较高,同时能精准地对旅客进行流失预测,从而能为航空公司提供有效的决策,挽回相应的损失。
1 相关工作
1.1 SMOTE算法
目前针对类别不平衡问题处理的方法主要包括:样本采样技术、代价敏感学习技术、决策输出补偿技术、集成学习技术、主动学习技术、一分类技术[4]。其中,样本采样技术是在工程上最为常用的技术。即通过增加少数类样本或减少多数类样本的方式以获得相对平衡的训练集。增加少数类样本的方法称为过采样(oversampling),减少多数样本的方法称为欠采样(undersampling)。考虑到使用欠采样方式,会使训练集中旅客记录数据量减少,导致后续模型可能学习不到旅客的重要特征,从而影响旅客流失预测精度。因此,本文决定采用过采样技术处理类别不平衡问题。其中,SMOTE算法[5]是由Chawla等提出的经典随机过采样方法,可有效解决少数类样本不足的问题。其主要思想在于,以每个少数类样本为中心,采用最近邻KNN算法,选出K近邻少数类样本。在距离较近的K近邻少数样本之间通过式(1)随机生成一个新样本
(1)
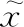
1.2 多任务学习
多任务学习(multitask learning)是一类同时学习多个相关任务的机器学习算法,基本思想是在学习期间利用其它相关任务中包含的信息,更好地或更快地学习任务[6]。其优点是能同时并行学习多个任务,并且通过每个任务互相学习其它任务的所附加的额外信息,能最快最好提升自身任务的学习性能。此外,由于使用共享表示,多个任务同时进行预测时,减少了数据来源的数量以及整体模型参数的规模,使预测更加高效。
1.3 降噪自编码器神经网络
自编码器是一种无监督学习神经网络,由编码器和解码器两部分构成。编码器通过隐藏层将输入样本数据进行降维或升维,从而起到数据编码的作用。解码器将编码器输出的样本再次通过隐藏层恢复到原来输入编码器时的维度,从而起到数据解码的作用[7]。利用逐层训练优化算法初始网络权重并使用反向传播算法对网络参数进行微调。通过多次组合自编码器网络,把当前层的输出作为下一层的输入,可形成堆叠自编码器深度神经网络。
编码过程为
(2)
解码过程为
Y=g(H):=Sz(a′H+b′)
(3)
损失函数为
(4)
(网络参数为:W={a,a′,b,b′})
2 提出的算法
2.1 基于部分距离的SMOTE算法
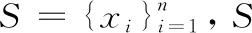
(5)
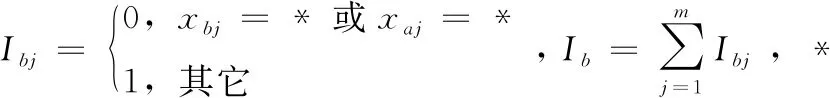
结合式(5),采用SMOTE算法对少数类别样本进行过采样步骤如下:
(1)将少数类中每一个样本,根据式(5)计算其到少数类集合所有样本点的距离,得到K近邻样本;
(2)根据样本不平衡比例设置合适的采样频率N,从K近邻样本中,随机选择若干样本;
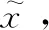
(6)
其中,rand(0,1)表示生成0到1之间的随机数。
2.2 基于降噪自编码器的多任务网络模型:MLT-DAE
针对数据属性缺失处理,数据缺失值填补的最终目的是能对旅客流失做出精确的预测。结合多任务学习与降噪自编码器的优势,本文设计出一种基于降噪自编码器的多任务学习网络模型MLT-DAE。由模型架构和训练过程分别进行论述。
2.2.1 模型架构
模型网络架构如图1所示。
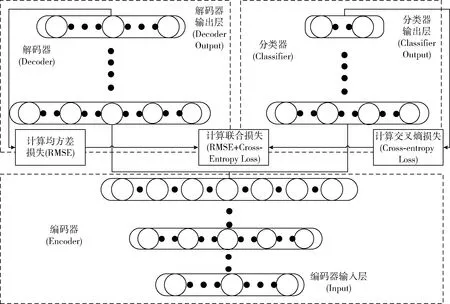
图1 模型MLT-DAE网络架构
图1中提出的架构由3部分组成:编码器、解码器、分类器。各部分中间均包含多个隐藏层,其中编码器与解码器构成堆叠降噪自编码器。参考有关DAE网络[10-12]架构,区别于传统自动编码器架构,受Kernal SVM[13]启发,本文采用的架构在编码阶段与输入层相比,连续隐藏层中的单元数更多,试图将输入数据映射到更高维子空间,将数据扩充有助于增加数据可分性以及增强数据恢复能力。从初始Xn维输入开始,然后在每个连续的隐藏层,添加a个节点,将维度增加a维。在模型输入阶段,将输入数据进行归一化处理,使得数据数值在0和1之间,以加快模型在中小样本量时收敛,同时引入噪声,在输入层随机将输入Xn中的一半分量设置为0,使得网络能提取到更加抽象的特征,增强网络鲁棒性。对于降噪自编码器部分,因为由多个隐藏层构成,因此采用逐层贪婪方式先对编码器和解码器网络进行预训练,最后配合分类器对整个模型参数进行微调。采用交叉熵损失函数针对分类器进行训练,采用均方差损失函数针对编码器解码器进行训练。由于在初始化时需要完整的数据,因此在不完整样本输入前,对于缺失的连续变量使用相应的列平均值进行初始填补,对于缺失的分类变量的使用属性中出现最多的值作为初始填补。
2.2.2 模型训练过程
输入:数据集X1,X2,X3,…,Xi,任务权重系数λ
输出:encoderFφ,decoderGθ,classifierHβ
(1)初始化网络参数φ,θ,β;
比特币不是基于账户的密码货币,而是基于交易的密码货币。在基于账户的货币中,我们可以通过账户直接查询余额;但在比特币系统中,我们需要通过未花费交易输出(UTXO)来统计该地址余额。
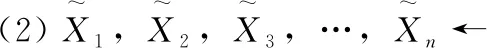
(3)逐层无监督预训练编码器encoderF、解码器decoderG;
(4)结合分类器classifierH,通过任务权重系数入对整体网络进行联合训练,并有监督微调降噪自编码器网络;
(5)Repeat
(6)计算对应任务的损失函数
E=λEm+(1-λ)Es

(8)Until网络参数φ,θ,β收敛。
模型由一个输入端,两个输出端构成。解码器的输出是为了对输入数据的缺失值进行恢复,从而采用均方差损失函数进行模型训练。分类器的输出是为了对最终目标流失预测任务,从而采用交叉熵损失函数进行模型训练。由于两个任务的重要程度不一致,因此在模型中引入任务权重系数λ[14],用于调节模型训练两个任务的权重,以平衡两个任务的重要程度,对模型整体性能有着非常重要的影响,是重要的模型调优参数。λ的最优值一般处于0到1之间,并且它的取值取决于所解决问题的性质以及当前数据质量。
2.3 数据整体处理流程
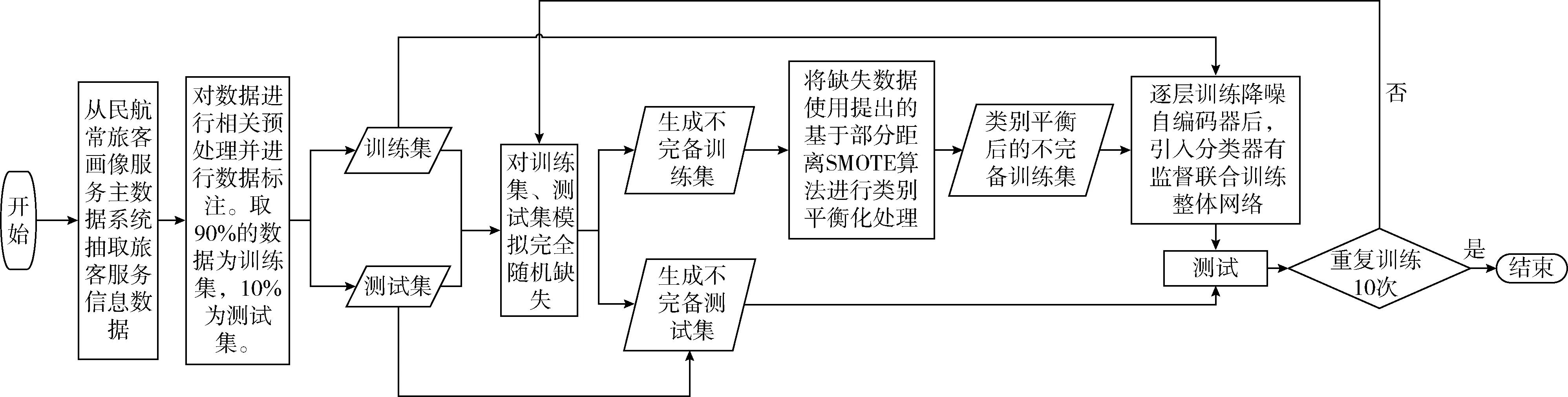
图2 整体数据流
步骤1 从民航常旅客画像服务主数据系统抽取旅客服务信息数据。其中,抽取的数据的属性主要为旅客基本信息、旅客值机信息、旅客积分信息等。
步骤2 按照行业经验,对抽取的数据进行相关预处理,并进行数据标注后,等比例对数据进行分割。将90%的数据形成训练集,10%的数据形成测试集。
步骤3 同时对训练集与数据集模拟完全随机缺失,形成不完备训练集、不完备测试集。
步骤4 将不完备训练集使用提出的基于部分距离的SMOTE算法进行随机过采样生成类别平衡后的不完备训练集。
步骤5 将类别平衡后的不完备训练集与完备训练集放入设计好的多任务学习降噪自编码器模型,进行模型训练。
步骤6 将不完备测试集与完备测试集放入已训练好的网络模型进行相关性能指标验证。
步骤7 判断是否重复已训练模型10次,如果已训练10次,则计算模型平均性能指标,否则回到步骤3继续。
3 相关实验设计与分析
本实验采用从中航信旅客信息服务部门旅客信息服务主数据系统中抽取的某航空公司部分常旅客会员信息服务主数据。将数据进行如上文所述流程处理后,分别进行相关对比实验以验证所提出方法的有效性。
3.1 数据集说明
由于涉及旅客和航空公司的相关隐私信息,所有属性均经过脱敏处理。数据集一共37 237条样本记录,属性维度为44维。数据集中,其与核心业务相关的主要属性包括3个方面:①旅客基本信息:包含旅客ID、旅客性别、旅客年龄、旅客工作所在城市、旅客价值等级、首次乘机时间、旅客入会时间等。②旅客值机信息:包含旅客当前累积飞行次数、第1年乘机次数、第2年乘机次数观测窗口结束时间、旅客飞行总公里数、票价总收入、平均折扣率、平均乘机时间间隔、末次飞行日期等。③旅客会员积分信息:总基本积分、积分兑换次数、总精英积分、促销积分等。
3.2 数据预处理
参考民航旅客价值评估体系分析的独有特点,对传统的客户价值RFM指标进行相应改进,引入旅客保持关系长度L、一定时间内旅客所享受的平均折扣系数C,形成L、R、F、M、C这5个价值系统指标,作为重要的生成特征[15]。其中,L可由旅客观测窗口结束时间与旅客入会时间相减计算出;R代表旅客最近一次距今消费时间可由观测窗口结束时间与末次飞行日期相减计算出;F代表消费频率可以由属性当前类型飞行次数得出;C可以由属性平均折扣率得出。同时,根据业务分析人员经验判定第2年乘机次数与第1年乘机次数比例低于50%为已流失旅客,处于50%到90%之间为准流失旅客,依然高于90%以上为未流失旅客。其余属性在删除例如对模型训练无意义的旅客ID属性同时,对数据集中的离散特征的标签类别属性如旅客性别、旅客工作所在城市等进行数值化处理。最终,形成特征数40维,已流失旅客数为4802,准流失旅客数为8301,未流失旅客数为25 134,可以看出绝大多数的会员为未流失状态,已流失的会员相对来说比较少,非常符合类别不平衡的情形。为了训练模型的缺失值填补能力,针对现有的3种缺失机制:完全随机缺失、随机缺失、非随机缺失[16],考虑到完全随机缺失(MCAR)具有普适性,因此对预处理后的训练集、测试集以缺失率0.1至0.6分别模拟完全随机缺失,最终形成符合数据系统环境下的不完备训练集、测试集。在正式输入网络模型训练前,将数据进行归一化处理,以加快网络模型的参数收敛。
3.3 相关参数
本实验环境为Windows 10 64 bit,CPU 2.8 Hz 内存16 G,使用Python语言及Tensorflow2.0框架完成相关数据处理以及模型训练。其中基于部分距离的SMOTE算法,近邻个数k为5,采样倍率N为5和3分别对已流失旅客和未流失旅客进行随机过采样,从而使数据集类别达到平衡。基于降噪自编码器的多任务学习网络模型,经过多次实验采用四层网络架构,隐藏层激活函数设置为Tanh函数,解码器输出层激活函数设置为Sigmod函数,采用均方差损失函数,分类器输出层激活函数设置为Softmax函数,采用交叉熵损失函数,编码器每层增加的节点数a为7。整体模型采用Adam优化函数计算更新网络权重。训练轮数Epoch设置为200,每次训练批处理数Batchsize为256,任务权重系数λ为0.1~0.9。
3.4 评估指标设置
在传统分类算法中,一般以整体正确率为评价指标。由于本文所面向的数据集类别不平衡,因此准确识别出绝大部分未流失旅客,可能整体正确率会高达95%以上,但这对于航空公司来说没有实际价值意义,重点在于能精确识别出未流失旅客和准流失旅客。因此,实验采用综合衡量模型精准率(Precision)和召回率(Re-call)的F1-Score值作为分类预测旅客流失任务的评价指标,其值越大越好,即
(7)
同时,对于缺失值填补任务,采用均方差损失(RSME)作为评价指标,其值越小越好。
3.5 实验结果与分析
3.5.1 分类预测效果对比
在分类效果对比实验中,将本文提出的基于降噪自编码器的多任务学习方法分别与通过传统主流数据填补算法均值填补算法、MIC算法[17]、KNN、SoftImpute算法[18]先进行缺失值填补,再采用SVM算法进行分类预测对比。同时,将基于部分距离的SMOTE算法与以上算法结合,验证其有效性。实验结果以F1-Score值作为度量分类任务性能指标,全部实验均重复10次以获得最终平均结果。实验结果如图3所示。
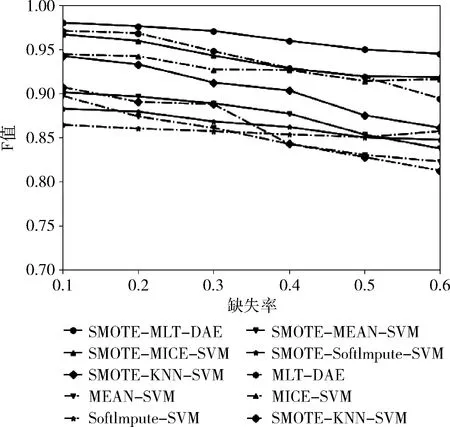
图3 分类预测效果对比实验
由图3可知,实线均为各算法在数据经过提出的改进SMOTE算法在类别平衡化处理后使用后续相应算法训练出的结果。相比未经类别平衡化处理,各算法在使用提出的改进SMOTE算法后在分类性能上均有相应的提升,体现出基于部分距离的SMOTE算法在解决缺失模式下数据类别不平衡的问题的有效性。同时,相比先对缺失值进行填补,后对填补后的数据集进行分类预测的传统处理方法,本文提出的MLT-DAE网络模型在缺失率不断增大下有着非常好的优越性及稳定性,F值一直处于0.95以上的水平,而均值填补、KNN填补、SoftImpute填补当数据集缺失率较大时,模型的分类精度均出现较大的损失。主要原因在于,在数据缺失率较高情况下经过基于部分距离的SMOTE随机过采样会生成的带有噪声的数据样本,从而影响后续进行分类任务的性能。由此可以分析出:①经过采用基于部分距离的SMOTE算法,能有效解决缺失模式下的类别不平衡问题。②类别平衡后的数据经过降噪自编码器处理可以较大减小数据经过基于部分距离的SMOTE算法采样后形成的噪声,从而有助于提升分类任务的性能。
3.5.2 填补效果对比
对于缺失值填补任务,将MLT-DAE模型对不同缺失率下的数据集进行填补,以对缺失率为0.3的测试集LRFMC属性填补效果为例,经多次测试本文提出的模型部分填补效果见表1~表3。同时将本文提出的方法与均值填补法、MICE、KNN填补法、SoftImpute填补法进行对比。采用均方根误差RMSE作为评价指标,为减小随机误差,分别对5种方法重复进行10次实验,得到综合实验结果如图4所示。
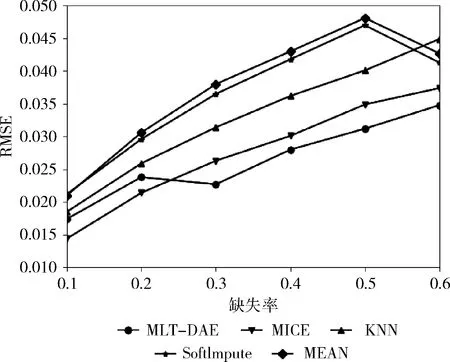
图4 缺失填补效果对比
由表1~表3所示,模型在对民航价值业务体系业务指标LRFMC的填补有着非常不错的效果,经模型填补后的数值与数据原始值较为接近,有助于后续对旅客进行更进一步的数据画像分析。同时,由图4所示,相比传统方法本文提出的方法在缺失填补方面也一直保持较好的效果,随着数据缺失率不断增大,均方根误差与其它传统方法相比较低,且差距明显。尤其是在数据集缺失率较高的情况下,配合多任务学习能对数据进行有效填补。进一步从侧面体现出,在不完备数据集进行旅客流失预测任务时,缺失值对分类结果有着直接的影响。算法对缺失值的填补性能的提升有助于分类任务性能的提升。
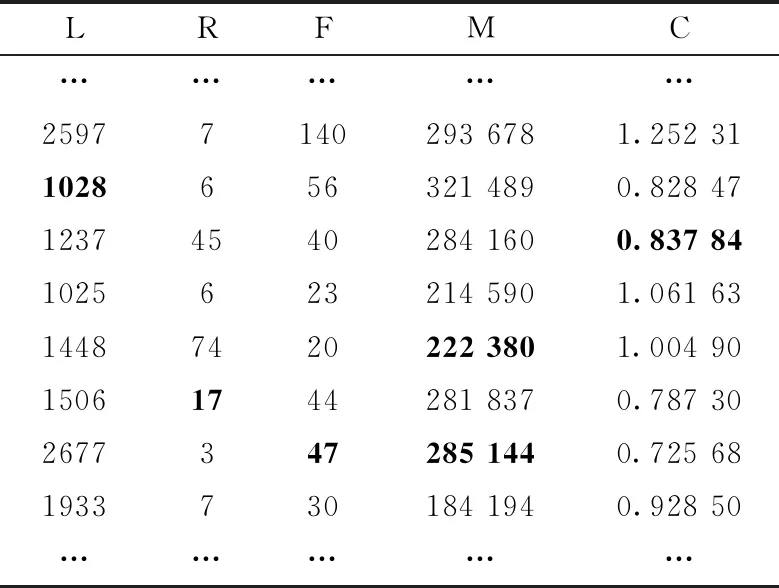
表1 测试集LRFMC属性原始记录
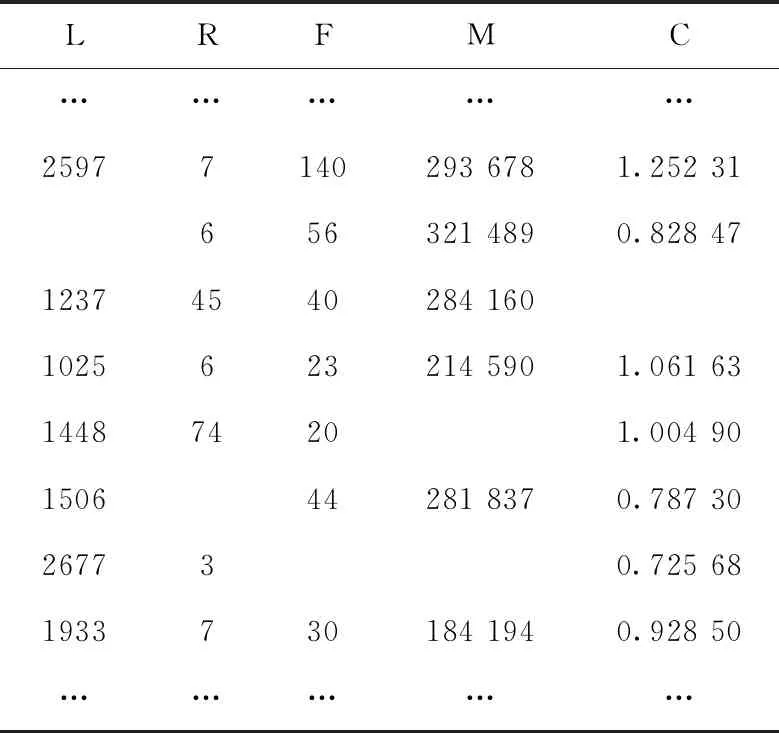
表2 测试集LRFMC属性缺失记录
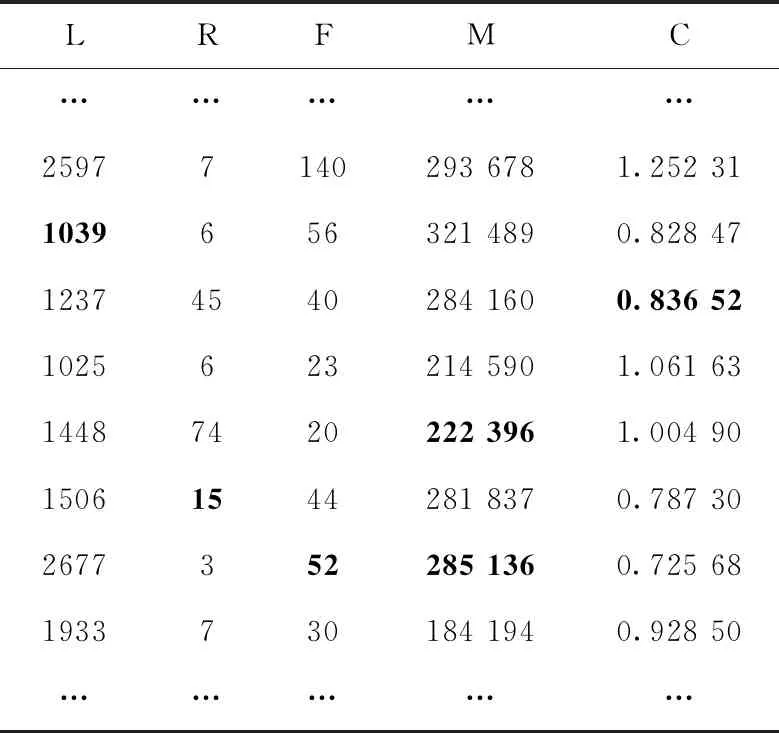
表3 经过模型填补后LRFMC属性记录
3.5.3 多任务学习有效性验证实验对比
由于本文提出的MLT-DAE网络模型既能进行旅客流失预测任务又能进行缺失值填补,为了验证多任务学习网络架构的有效性,将经MLT-DAE网络模型去掉分类器直接采用由编码器和解码器构成的DAE网络模型填补后的输出,配合SVM算法、逻辑回归(LG)算法进行旅客流失预测,与MLT-DAE分类器端的结果输出进行对比。分别以缺失率0.2、0.4、0.6重复进行10次实验,取平均值作为最终结果,综合结果见表4。

表4 多任务学习验证对比
从实验结果可以归纳出,针对旅客流失预测问题,传统的SVM算法要略好于LG算法,原因在于SVM在高维空间中找出分割面将数据按照类别得以分割,类别不平衡对其影响较小,而LG算法要度量总体损失函数,对平衡类别较为敏感。本文结合业务环境提出的预测方法,考虑到自编码器对数据进行自动特征提取的优势,将数据在编码阶段进行维度扩展得到更高维更抽象的特征表达,配合解码器网络和分类器网络,使得中间层学习到的特征表达既包含原有数据样本缺失的信息,又能对数据进行有效的分割,从而使缺失值得填补以分类预测为导向,有助于提升预测精度。
3.5.4 参数任务权重系数λ
MLT-DAE模型,对两个任务同时进行处理,由于两个任务有各自的权重,因此模型的输入参数任务权重系数λ对模型收敛及整体性能有着非常重要的影响。以缺失率为20%、40%、60%的数据集为实验数据进行说明,以F值为评价指标,对任务权重系数λ设置,以0.1为步长,从0.1到0.9分别对数据集进行对比实验,以发现最优值规律。实验综合平均结果见表5。
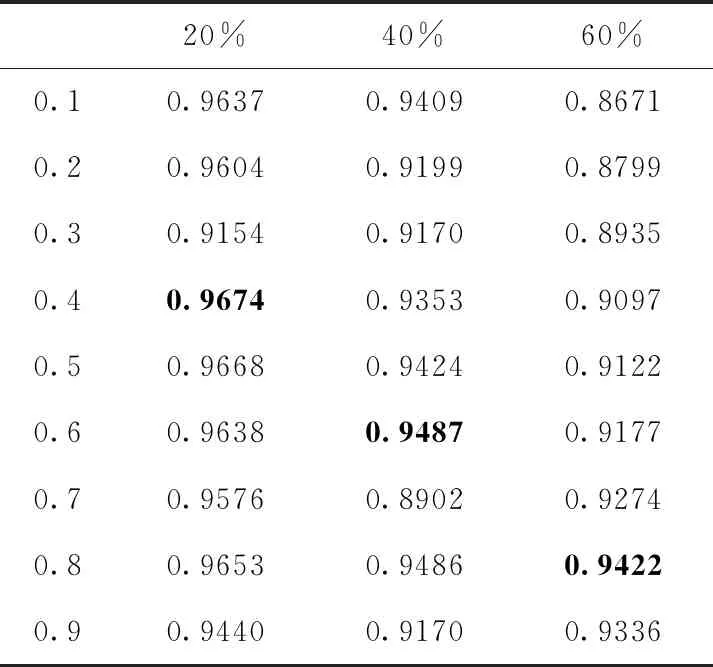
表5 参数任务权重系数λ选择
当数据集缺失率低于10%时,参与模型训练的数据质量比较高,网络模型联合训练应该偏向旅客流失预测分类任务,λ值可从0.1~0.2中设置。随着数据集的缺失率逐渐升高,参与网络模型训练的数据质量逐渐变低,使得模型训练由原来的以流失分类预测为主任务转为以缺失值填补为主任务,导致λ值也相应升高。因此,实际在生产环境上部署训练模型时,要根据当前环境下的数据质量以及模型的主要任务搜寻合适的权重系数以使模型性能达到最优。
4 结束语
针对民航旅客信息服务系统中数据缺失影响对旅客做流失预测的情形,本文对已有SMOTE算法进行改进,使其能在不完备数据集下对已流失旅客和准流失旅客进行过采样以平衡数据集。同时,设计出一种基于降噪自编码器的多任务深度神经网络模型,将旅客流失预测任务作为主任务,数据缺失值填补作为辅助任务,同时并行解决民航旅客服务信息主数据缺失值填补以及民航旅客流失预测问题。实验结果表明,相比传统处理方法,模型考虑到现实生产环境,在分类任务和缺失值填补任务中有着较好的性能,可提升分类精度和数据质量,同时更为重要来说使其能在数据不完备的情况下对旅客流失进行精确预测,因此具有较大的工程实用价值。
猜你喜欢
小哥白尼(趣味科学)(2021年3期)2021-07-16 07:47:32
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
故事大王(2018年3期)2018-05-03 09:55:52
数学学习与研究(2017年3期)2017-03-09 18:12:42
电子设计工程(2017年20期)2017-02-10 03:39:29
空中之家(2016年1期)2016-05-17 04:47:43
中国老区建设(2016年1期)2016-02-28 09:32:00
电子器件(2015年5期)2015-12-29 08:42:24
