
基于Python的甲骨文摹本半自动生成系统的设计与实现
2020-11-03 10:42张星移
安阳工学院学报 2020年6期
李 娜,刘 冰,高 峰,张星移
(1.安阳师范学院计算机与信息工程学院,河南安阳455000;2.安阳工学院,河南安阳455000;3.甲骨文信息处理教育部重点实验室,河南安阳455000;4.河南省甲骨文信息处理重点实验室,河南安阳455000)
1 研究背景及意义
甲骨埋藏于地下3000多年,时间久远,绝大多数甲骨都已经被腐蚀,再加上后来在出土过程中由于各种原因造成表面磨损、断裂,大大降低了原始甲骨的研究价值。又因为多数出土的甲骨会受到风化腐蚀,所以在后期研究过程中甲骨学者尽可能不使用原始甲骨,通常以甲骨片作为原型经过“墨拓”得到甲骨拓片。由于拓片中会保留大量的骨缝、裂痕等干扰信息,甲骨学者会对原始甲骨或者拓片进行手工摹写,得到清晰、没有干扰信息的甲骨摹本作为材料进行研究。甲骨发掘存世的有十五万四千片[1],对于每一片进行手工摹写来说,数量是非常庞大的,而且由于人为因素的存在,手工摹写会大大降低摹本与原始甲骨片之间的精准程度。这样的情况很大程度制约了甲骨文研究的进程。在实践过程中,具有字形清晰的拓片摹本才是适宜于进行甲骨文研究的材料。本系统利用计算机图像处理技术自动生成甲骨摹本,很大程度上加快了摹本生成速度,而且大大提高摹本的轮廓和字形的精准程度,生成便于处理、保存的摹本电子图像数据。摹本电子图像数据相对于手工描写数据更加科学、规范,生成的标准统一,有利于实现甲骨文摹本信息共享,更加便于甲骨文的文献资源的研究和利用。
2 研究现状
目前针对甲骨文拓片已有相当多的研究,在甲骨文字形特征提取方面,如郭磊提出的行文工整的甲骨拓片文字特征提取算法研究[2];在甲骨文拓片图像降噪方面,如王旖旎提出的基于极值检测算法在甲骨拓片图像双边滤波方法的应用[3];在甲骨文拓片图像目标定位方面,如史小松等人提出的甲骨拓片图像的目标自动定位算法[4]。以上这些研究的主要目的是为了研究甲骨拓片上的文字而对拓片进行的各种图像处理。
本文提出的基于Python的甲骨文摹本半自动生成系统是利用图像处理技术来完成传统手工绘制甲骨文摹本的工作,高效、精准、规范的生成甲骨文摹本数字化数据,便于后续的甲骨文研究工作的开展及面向应用方面的推广。
3 系统组成及模块说明
基于Python的甲骨文摹本半自动生成系统大致可以分为以下5个功能模块:获取甲骨文拓片图像;提取拓片图像的外缘边框;文字定位;调整大小放置文字;保存生成的摹本。该系统通过上述这5部分来实现由拓片得到与之相对应的摹本。系统的功能模块整体设计图如图1所示。下面分别针对每一功能模块实现时的关键技术进行详细分析。
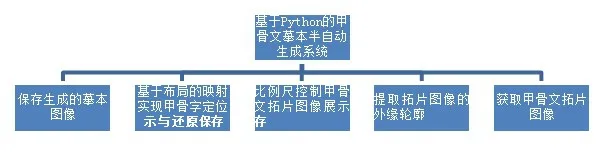
图1 系统功能模块设计图
3.1 获取甲骨文拓片图像模块
通过Python PyQt5模块的相关可视化方法,引导用户将原始拓片图像文件导入,完成系统的图片输入功能,同时建立一个用于处理甲骨拓片图像的缓存区,用于随时调入调出实时的甲骨拓片图像的处理记录。这样保存每一步图像处理的中间结果,便于用户灵活调整、对比甲骨拓片图像处理前后的变化,从而选择保存最佳处理完成的结果图像数据。
3.2 提取拓片图像的外缘轮廓模块
该模块是本系统的核心功能模块之一,其功能是处理目标拓片从而得到其外缘轮廓。此模块采用了多个图像处理算法,技术上借助了Python-Opencv模块的相应方法实现。
3.2.1 采用均值滤波对原始拓片图像进行预处理
首先,采用均值滤波算法对原始拓片图像进行预处理。对于每个中心像素而言,其取相邻像素的平均值作为新的像素值[5],从而达到去除图像中存在的颗粒噪点的效果,实现图像的初步模糊平滑处理,减少噪点或者失真点。如图2所示,(a)图是原始拓片图像,(b)图为采用均值滤波预处理后的图像,通过多次实验测试表明,采用5×5的内核大小可以使甲骨文拓片图像得到最佳的处理效果。
3.2.2 采用泛洪填充算法分割图像主体与背景
由于甲骨文拓片图像自身具有内部颜色和外部背景差异明显的共性特点,经过模糊处理后,图像内外不同像素的差异就能很好地消除。所以,采用泛洪填充算法把主体与背景进行分离,从而达到消除背景的目的。数值上我们把重绘区设置为白色(255,255,255),也就是白色背景,与拓片主体区域分割开来。泛洪填充算法的参数中Scalar的负差和正差分别采用(2,2,2)和(3,3,3),其效果如图2中的(c)图所示。


图2 预处理图像
3.2.3 泛洪填充算法在特殊甲骨拓片图像上的不可靠性
本系统采用泛洪填充算法有一个需要特殊处理的情况,就是对于有一类甲骨拓片图像,如图3中的(a)图所示,存在有比较明显的人工刻画痕迹或是骨头本身带有的生物裂纹,这种裂痕明显,具有贯穿性,与背景色相近且连通,泛洪填充算法应用于具有这些特征的图像后,会错误识别主体,部分主体被填充为背景色,如图3中的(b)图所示。在后期进行灰度图转化和开闭运算的时候,由于错误识别主体,导致图像中的主体边缘绘制错误,如图3中的(c)图所示。


图3 泛洪填充算法处理图
泛洪填充算法虽然在填充拓片主体内部有着不错的表现,但对于带有贯穿性裂痕的甲骨拓片图像并不适用,这一步可通过软件接口让用户选择,跳过泛洪填充算法,直接进行后续的处理,得到正确的边缘轮廓。
3.2.4 灰度图与开闭运算算法
利用泛洪填充算法分割背景后就得到一个比较孤立的甲骨文拓片图像,这时拓片主体内部还保留有甲骨文刻痕和很多细节痕迹信息。然后,采用转化灰度图的方法来得到一个颜色差异不大的拓片实体图像,让原始图像中的不同颜色的像素都转化为白到黑的像素,也就是灰色,但因为拓片中心本来就是以黑色为主的,所以从视觉上观察,生成的灰度图与前图并没有很明显的变化。
得到灰度图后我们采用开闭运算来对图像进行中心的细节合并。开闭运算的特点就是弥合小裂缝,而拓片主体的位置和形状不变,所以这样可以把甲骨文字体和其他刻痕完全去掉,把实体内部的细节抹去。这样处理过的甲骨文拓片,除了基本的轮廓外,中心部分的图像信息已经被很好消除了,如图3中的(d)图所示。
3.2.5 采用二值化将图像最大简化
采用二值化处理是进一步简化图像的一个操作,去除拓片图像中与边缘轮廓无关的信息,减少数据量,有利于拓片边缘轮廓的提取等后续处理。
二值化处理中的阈值threshold并没有统一的标准,因为不同的拓片图像处理后会出现不同的中间效果。本系统通过多组数据实验测试发现,采用泛洪填充算法时,threshold的阈值设置为200左右,可以得到最佳的边缘轮廓效果;不采用泛洪填充算法时,threshold的阈值设置为100~150,可以得到最佳的边缘轮廓效果,对比效果如图4所示。系统在实体软件窗口也给用户提供了相关的阈值调整接口。

图4 不采用泛洪填充算法时,不同二值化阈值对于边缘提取的效果比对
3.2.6 采用findCounters函数检索、drawCounters函数绘制拓片轮廓
轮廓检索时用到OpenCV中的cv2.findCounters()函数来实现,该函数有效的参数表为(image,mode,method),其中,image为我们处理的图像文件,这里使用的是二值化处理后的图像。mode为轮廓提取模式,采用的是CV_RETR_TREE方式,构建一个嵌套式的轮廓存储,方便后续直接获取轮廓到白板中的操作。method为轮廓逼近方法,采用的是CV_CHAIN_APPROX_SIMPLE逼近法,这种逼近方法主要采取的是压缩横向和纵向以及对角线以达到仅保留线段端点的特点,比如一般的非方形矩形就只会压缩四个点。最终,本函数会返回两个值,第一个值contours是以点列组成轮廓线,也就是最终需要使用到的轮廓值,而第二个值hierarchy是从拓片图像中提取出的轮廓的拓扑信息,采用二维数组的方式存储,包含各个轮廓的子父关系以及上下轮廓的关系。
最终的甲骨文摹本边缘图像是一个黑边框白底的图像。为了还原摹本的外貌,需要重新把拓扑轮廓以黑色存储于白底图像中,作为最终采用摹写域的标准图像,也是后期操作中需要把甲骨字形存放的区域。
3.3 比例尺动态控制甲骨文拓片图像展示与还原保存
实际中,需要处理的图像中的甲骨文拓片大小形态各异,在系统的界面布局中展现出来时,为了方便用户的观察、操作,就需要动态调整显示图像的大小,使每一张图像都以适中的尺寸大小展示出来,最后,保存的图像的大小还要和原图一致,确保清晰度不降低,并且选中的甲骨文字大小也要和原拓片中的甲骨字大小一致。对于以上需求,不能简单采用图像的满填充方式,否则,会出现图像的压缩和变形,降低图像质量,极大程度影响用户的使用体验。
本系统采用了比例尺对图像进行动态大小控制。利用一个规范的比例尺把图片按照我们需求的长宽展示出来,所有操作都按照如此的长宽标准来操作,操作全部完成后只需要再经过这个比例尺的反向处理即可还原。比例尺的设计就要充分利用图片的长宽比规范以及实时结合现阶段大多计算机屏幕大小要求。本系统展示不支持根据分辨率来动态设置,默认按照现在的主流屏幕大小1920×1080的长宽度来设定,甲骨文拓片图像的长宽度以读入的每一张图像的实际值来设定,定义宽为w,长为h。确定了分辨率后,我们要保证图片稳定在一个显示范围内。为了保证这个稳定的范围有普遍性,进行如下规定:
在图像过小或者过大的时候要通过比例尺进行动态调整。
比例尺默认值需要为1,当大小合适的时候,比例尺操作不会影响大小。
在比例尺的控制下,必须有个标准范围。
采用长宽中较大的值用来判定是否达到需要使用比例尺的上限,即横向图以宽度定比例,竖图以高度定比例。
通过上面的四个要求,确定图像的最大长宽范围都是800,但是不可能所有图像都是标准的正方形。下面是最大值的映射关系公式:

这样的关系仅仅是最大的映射关系,不需要给所有图像加上这样的映射,规定只有在长宽不在某个范围内时再使用上式的映射关系,超过这个范围定义为图太大,小于这个范围是图太小。所以可以得到比例尺如下的数学定义:
在某个二维定义域R2={(w,h)|w,h∈R}中,存在这样一个定义域δ,满足∀(w,h)有δ={(w,h)|w∈(700,800)或h∈(600,650)},那么当前如果存在一个点β(w,h),有如下情况:

利用比例尺公式(2)推导后,便可以很快得到Ratio值,显示给用户的拓片图像的长宽只需要加上一个Ratio比例尺系数即可在软件中动态显示。文字区域确定后,如果要存储到原图中去的话,也只需要除以Ratio系数值就可以还原为原始图像中文字的区域大小。
3.4 基于布局的映射实现甲骨字定位
本系统中,甲骨字定位是通过拓片域与摹本域的物理映射来实现的,把拓片上框选的文字位置通过映射准确定位到摹本区。其实现的基础是在静态GUI界面中加入了3.3中使用到的比例尺和“伪鼠标范围框选”功能来让静态的数据可以在各种参数的实时监控下边实现的“动态”。
“伪鼠标范围框选”是利用了GUI中固定的外边框的静态元素与鼠标实时监控参数的动态特性搭配完成的,实现了一种让原本不动的静态外边框元素移动起来,营造一种“选择框体”的效果。实际上是一种基于布局的硬空间规律的物理硬映射,因为拓片与摹本的宽度和高完全相同,所以这种映射是可行的。
如图5所示,B表示拓片域宽,拓片域和摹写域间距用A表示,域中的小矩形空间表示选择的区域,则自然可以计算的两个域中的圈选小矩形区域距离为A+B。因为在比例尺的调整下,A与B都是确定的,所以可以通过加减计算完成映射。
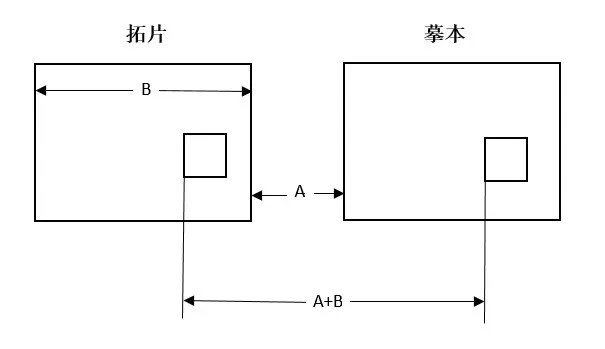
图5 拓片域与摹本域的物理映射关系图
3.5 保存生成的摹本图像
如图6示例所示,通过软件本身的图形接口,提供给用户自定义的摹本保存操作,方便用户对于完成摹本图像的存储管理。

图6 生成摹本图像
4 结语
本系统主要解决甲骨文摹本自动生成问题,实验表明本系统可以实现由拓片生成与之相对应的摹本,其中的甲骨字定位和调用甲骨文输入法部分还需人工选择完成。基于Python的甲骨文摹本半自动生成系统较手工画制摹本的方法更加规范,结果更加科学、准确。由于时间和知识水平的限制,目前仅对相关内容进行了初步的研究,本系统还存在着不足,在以后的工作中还有待进一步的优化和完善,包括以下内容:
目前该系统是半自动生成拓片摹本,可以尝试实现自动化摹本生成系统,使得在摹本生成的过程中进一步减少人员参与和参与时间,增强系统的普适性,提高其工作效率。
当拓片中文字方向不与界面水平方向垂直且拓片上文字较为密集时,当前系统中确定文字位置的选框可能会与轮廓或相邻选框相重合,可以尝试控制矩形选框使其可以旋转一定的角度,进一步提高摹本的准确性。
猜你喜欢
江苏教育·书法教育(2022年4期)2022-05-05
黄河·黄土·黄种人(华夏文明)(2021年7期)2021-12-23
黄河·黄土·黄种人(华夏文明)(2021年5期)2021-09-28
教育周报·教育论坛(2021年21期)2021-04-14
黄河·黄土·黄种人(华夏文明)(2020年6期)2020-07-14
紫禁城(2020年4期)2020-05-20
英美文学研究论丛(2019年1期)2019-11-25
艺术大观(2019年30期)2019-10-12
汉字汉语研究(2019年4期)2019-03-04
汉字汉语研究(2019年4期)2019-03-04
