
基扩展模型下基于深度学习的双选信道估计方法
2020-11-03 11:36:56曹梦硕陈宝文
计算机测量与控制 2020年10期
曹梦硕,韩 军,陈宝文
(中国电子科技集团公司 第五十四研究所,石家庄 050081)
0 引言
高速移动环境中,无线信号同时受到多径效应和多普勒效应影响,信道响应具有时间选择性衰落和频率选择性衰落(双选衰落)特性[1]。OFDM技术通过插入循环前缀(CP,cyclic prefix)和串/并变换等手段可以减少或消除由于多径效应产生的符号间干扰(ISI,inter-symbol interference)[2]。然而,OFDM技术对信道多普勒效应非常敏感,少许的信道动态便引起显著的子载波间干扰(ICI,inter-carrier interference)[3],有效抵抗ICI干扰的手段之一便是OFDM信道估计。
在双选衰落信道中,直接估计信道冲激响应(CIR,channel impulse response)待估参数过多[4],而基扩展模型(BEM,basis expansion model)[5-6]通过将信道特性转换为基函数(通常是正交的)与基系数乘积的线性组合,有效地减小了所要估计的参数的个数[7]。高速移动时,无线信道具有时域稀疏性[8],其CIR通常可以由少数主导的路径近似。故采用压缩感知(CS,compressive sensing)技术可以准确地恢复基系数,同时有效降低所需的导频数量[9]。在文献[9]中,提出了基于分布式压缩感知(DCS,distributed compressive sensing)的信道估计方法。与CS理论只能重构单个稀疏信号不同,DCS理论可以利用相同的测量矩阵重构一组联合稀疏信号。
通过BEM结合CS可以有效估计出导频位置的CIR,通常假设导频位置的CIR与数据位置的CIR之间的变化是线性的,根据线性插值由导频位置CIR得到数据位置CIR。然而高速移动环境下,线性变化这一假设不成立[10]。即使使用其他的插值方法,也无法很好地描述其变化。
深度学习(DL,deep learning)可以学习到样本数据中的变化规律,对于信道估计来说,则是可以根据标准的双选信道数据学习到导频位置CIR与数据位置CIR之间的变化规律,从而优化信道估计的结果。近年来,深度学习开始应用到无线通信领域,例如毫米波信道估计[11],但是对于双选信道下的信道估计,DL还未得到广泛研究。
因此,针对双选信道的信道估计,本文提出了一种BEM结合DL的方法。采用BEM结合CS的方法估计出导频处的CIR,再根据导频位置处的CIR使用线性插值得到数据位置处的CIR,再输入到经过训练的深度神经网络(deep neural network,DNN)中进行补偿,提高估计精度。
1 OFDM系统模型
1.1 导频结构
本文所提方法也是导频辅助下的估计方法,首先介绍导频结构。在文献[12]中,提出了基于DCS框架的同时正交匹配追踪(SOMP,simultaneous orthogonal matching pursuit)算法—DCS-SOMP,同时提供了一种导频密度较低的导频图样。类似的,本文所采用的导频图样为如图1所示的包含虚拟子载波的均匀矩形导频结构。频域上每个符号包含88个有效导频,为了防止导频位置的接收值受到来自数据子载波的ICI干扰,每个有效导频左右各有一个虚拟子载波;在时域上,每3个符号包含一个含有导频的符号。综上,本系统的导频密度为2.4%。

图1 导频结构
1.2 OFDM系统
OFDM系统的收/发模型如图2所示。调制后的高速数据流经过串并转换,变成一组并行的低速数据流[2]。然后插入导频,并通过离散傅里叶逆变换转换成时域信号。假设OFDM系统的数据子载波个数为N,x(n)是X(k)做离散傅里叶逆变换后的时域数据,其表达式为:
x(n)=IDFT{X(k)}=
(1)

图2 OFDM系统模型
为了防止产生符号间干扰(ISI),在每个OFDM符号前插入Lcp长度的循环前缀(CP),得到N+Lcp长度数据帧。经过并串变换后,信号经历双选信道。在接收端,先对信号进行串并转换和去除循环前缀,得到时域信号y(n):

(2)
式中,L为多径数目,h(n;l)为第n时刻第l条径的冲激响应,w(n)为第n时刻的噪声,x(n-l)为第n-l时刻的传输抽样。
当信号经历双选信道时,时域信道矩阵h表示如下:
h=


可以看出待估参数为NL个,当N较大时,待估参数很多。
2 算法模型
2.1 深度神经网络
神经网络(NN,neural networks)是由大量连接的简单计算单元(神经元)形成的网络系统,典型的神经网络通常由输入层,隐藏层和输出层三层组成,如图 3所示,而DNN可以包含多个隐藏层,每层包含一定数量的神经元。

图3 神经网络结构示意图
其中:x1和x2表示输入,z1,z2,z3为中间隐藏层的输出,最后的输出为y。
如图4所示,在神经网络模型中,每个节点计算单元称为神经元。神经元的功能是传输来自神经网络的信号。

图4 神经元计算方法
以图中的结构为例,每个神经元计算公式为:
y=σ(ω1·x1+ω2·x2)+b
(3)
其中:ω1和ω2为网络的权重参数,b为偏置参数,权重参数和偏置参数统称为神经网络的模型参数。σ是激活函数,用来拟合输出分布的非线性。
神经网络有两个主要过程:正向传播与反向传播。正向传播过程是指输入数据正向通过各个隐藏层,然后输出预测结果。反向传播过程是指,根据计算预测结果与目标值的偏差值,采用链式求导与学习算法(例如梯度下降法)对各层网络的权重进行更新。
训练深度学习网络的方式主要有4种:监督、无监督、半监督和强化学习[13]。

图6 训练次数增加时的训练误差
1)在有监督学习中,输入数据称为训练数据,用于进行模型学习,训练数据具有自己的标签。
2)无监督学习则不需要预先学习出模型,并且输入数据没有标签。
3)强化学习中,数据主要为来自外部环境的反馈,且模型必须对这些反馈数据做出反应。
4)半监督学习的样本数据由少量带标签和大量不带标签两种组成,先通过带标签的数据学习,再通过对未带标签数据更新完善模型。
深度学习目标是分层次地学习特征[14],对于应用深度学习进行双选信道估计来说,则是可以使DNN学习到双选信道中导频位置处的CIR与数据位置处的CIR之间的变化特征,从而信道估计的结果更加精确。本文可以将大量标准的信道数据用于训练,且这些数据都是带标签的,故采用监督学习的方式对DNN进行训练。
2.2 鲸鱼优化算法
除了神经网络中的模型参数,深度学习中还有很多超参数,学习率是深度学习中最重要的超参数之一,学习率过小,模型的收敛速度会很慢,学习率过大,则会无法收敛。本文使用鲸鱼优化算法(WOA,whale optimization algorithm)搜索最佳学习率。
WOA是一种受自然启发的元启发式优化算法,这类算法依赖于相当简单的概念,并且具有易于实现、不需要梯度信息等优点,在工程应用中变得越来越流行[15]。Goldbogen等人研究了座头鲸特有的“螺旋气泡网”捕食策略,他们发现了“向上螺旋”和“双循环”这两个与气泡相关的行为[16]。前一种行为如图 5所示,通过研究这种行为,Mirjalili发明了一种新的群智能优化算法,即WOA算法。WOA算法模仿了座头鲸的狩猎行为,即“螺旋气泡网”捕食策略,通过包围猎物、搜寻猎物以及螺旋更新位置三种机制进行捕猎的相关行为数学模型化,该算法的结构简单,所需调节的参数少。

图5 座头鲸捕食策略
在WOA算法中,位置的更新主要有三种策略:包围猎物、搜寻猎物、螺旋式更新。假设鲸鱼种群的数量为N,在D维的搜索空间中,第i只鲸鱼在D维空间中的位置可表示为(Xi1,Xi2,…,XiD),其中i=1,2,…,N;j=1,2,…,D。
包围猎物:座头鲸可以识别猎物的位置并将其包围,假设当前的目标猎物位置是最优解或接近最优。在定义了最优位置之后,其他位置将尝试朝着最优位置更新其位置。此行为由以下方程式表示:
(4)

A=2ar1-a
(5)
C=2r2
(6)
其中:r1和r2是[0,1]之间的随机数,a为控制参数,随迭代的次数从2线性减小到0,即:
(7)
式中,tmax为最大的迭代次数。
搜寻猎物:可以使用基于A向量变化的相同方法来搜索猎物。实际上,座头鲸根据彼此的位置随机搜索。因此,我们使用[-1,1]之间的随机值A强制搜寻鲸鱼远离参考鲸鱼。其数学模型如式(8)所示:
(8)
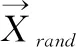
螺旋式更新:在鲸鱼的位置与其猎物之间建立螺旋方程,以模拟座头鲸的螺旋运动,如下所示:
(9)
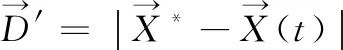
(10)
通过WOA搜索得到本文算法中的最佳学习率为0.1,此学习率时,DNN模型收敛速度最快且不会陷入局部最优解。不同学习率时训练误差随训练次数变化的曲线如图6所示。
当学习率为0.1时,下收敛速度很快且误差很小,训练次数为50次时,误差便降为0.006,而训练次数达到500次时,误差只有8.99×10-19。而当学习率过小(0.01)时,收敛过程十分缓慢,而当学习率过大(0.5)时会导致无法收敛,训练误差很大。
3 信道估计模型
3.1 BEM模型下的OFDM系统
在双选信道中,直接估计CIR所需估计的参数过多,这限制了传统的信道估计技术,找到一种合理的方法来降低要估计的信道参数的维度非常重要。基扩展模型通过寻找优化的基底,将信道冲激响应转换到由基函数扩展的低维空间,并用对基系数的估计代替对CIR的直接估计,从而有效地减少了所需估计的参数的数量;同时,通过选择合理的基函数,确保压缩过程对信道信息的破坏几乎忽略不计[17]。
复指数基扩展模型(CE-BEM,complex exponential BEM)由于其基向量的生成过程简单而不依赖额外的信道统计信息,且基向量之间又具备两两正交的特性[17],综合复杂度与性能的考虑,本文选择CE-BEM信道模型作为基本的信道模型,其基函数的表达式为:
b(n,q)=ej2π[q-(Q/2)]n/N
(11)
其中:n=0,1,…,N-1;q=0,1,…,Q-1。
BEM信道建模是将信道的冲激响应h(n;l)表示为已知的基函数(通常是正交的)bq(n)和基系数gq(l)加权和的形式:
(12)
式中,n=0,1,…,N-1;l=0,1,…,L-1,Q为阶数,且Q≥2┌fdmaxNTs┐,“┌ ┐”代表向上取整,fdmax表示最大多普勒频移,Ts表示抽样间隔。
故时域信道矩阵h用BEM建模的方式重构为:
(13)
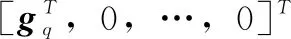
Gq=
通过BEM模型来描述OFDM系统,得到接收端频域信号表示如下:
Y=FhFHX+W
(14)
可以推导出:
(15)

令Dq=Fdiag(bq)FH,则:
(16)
由上述可知,只需要估计出L(Q+1)个BEM的系数矢量g,就可以重构出时域信道矩阵h。通常Q取值很小(1≤Q≤5),故BEM模型极大地简化了信道估计。
由于BEM模型中的系数矢量g是联合稀疏的[18],通过DCS-SOMP算法,可以利用接收信号将其恢复出来,从而进一步通过BEM模型将导频位置处的CIR恢复出来。
3.2 DNN结构
得到导频位置处的CIR之后,利用线性插值得到数据位置处的CIR,再将其输入到DNN中进行补偿。使用DNN补偿时,首先要使用标准的双选信道数据对DNN进行离线训练,使其学习到信道的变化特征;再将由线性插值得到的数据位置处的CIR输入经过训练的DNN中,得到更准确的数据位置处的CIR,如图7所示。

图7 信道估计结构
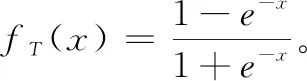
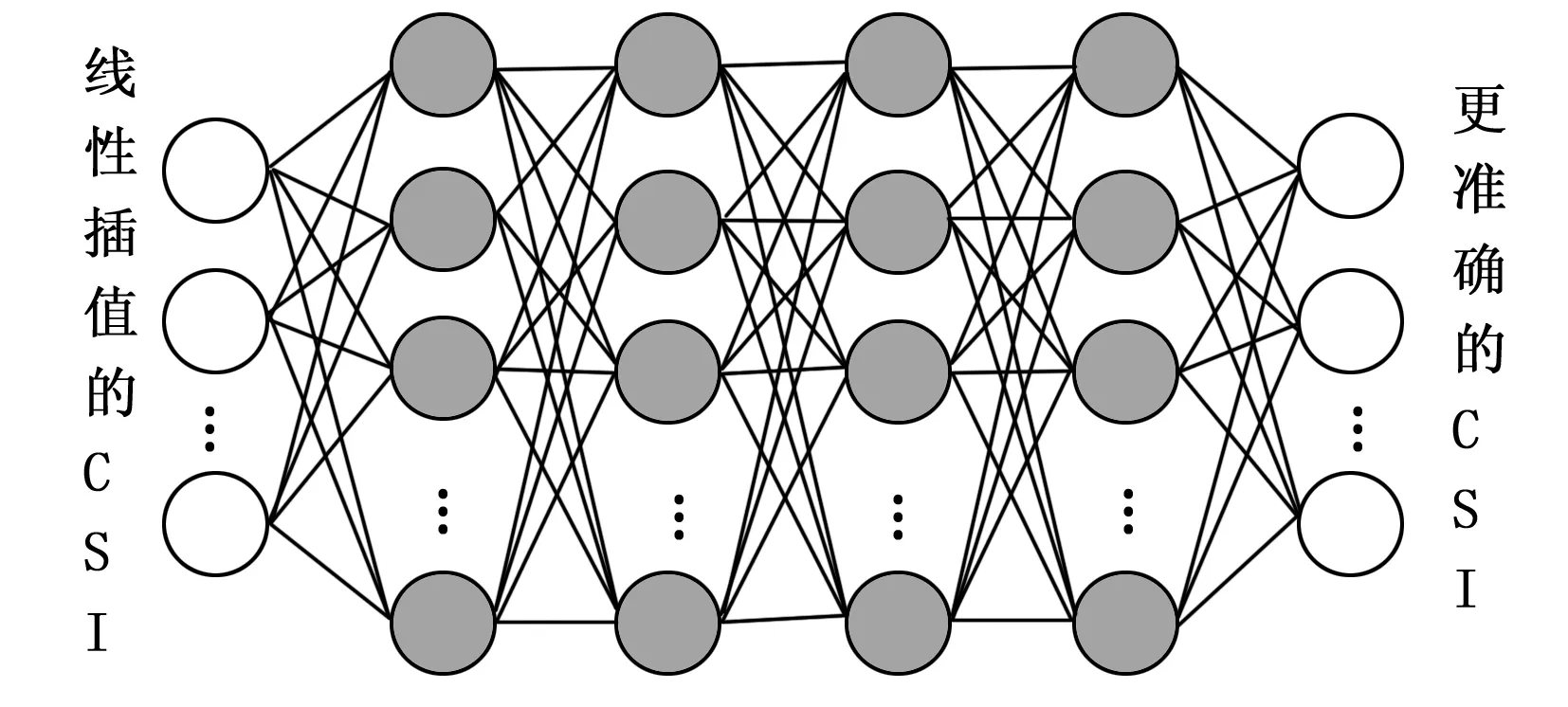
图8 DNN结构
图8中,输入层数据是由线性插值得到的数据位置处的CIR,h=[h1,…,hN]T∈N×1。因为原始信道数据是一个复信号,所以在将其输入学习网络前需要预处理,提取复信号的实部和虚部,然后将实部和虚部串联起来结合成一个维度,得到的实际的输入数据h∈2N×1。
输入层后面有4个隐藏层。每个隐藏层由一定数量的神经元组成,每个神经元的输出是上层神经元加权总和的非线性变换,表达式为:
(17)
式中,l1,i、w1,j、b分别为第1个隐藏层中第i个神经元的输出、权值和偏置。第k个隐藏层中神经元的输出为:
lk=fT(Wklk-1+bk)
(18)
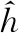
(19)
式中,L为DNN的网络层数。
以前的研究中,提出过很多标准信道模型,利用这些模型,通过调节参数,可以生成标准的双选信道信息作为训练数据。本文利用Rayleigh信道生成训练数据,离线训练时,将其引入到DNN中,并使用梯度下降算法更新学习网络中的权重和偏置集。为了衡量算法的性能,使用归一化均方误差(NMSE,normalized mean square error)作为学习网络的损失函数:
(20)
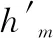
4 仿真
在本节中,通过与经典的最小二乘(LS,least squares)信道估计方法、未补偿的BEM结合线性插值的信道估计方法对比,评估本文提到的BEM结合DL的信道估计方法在高速(500 km/h)、不同信噪比(SNR,signal noise ratio)环境下的性能。本文提出的DNN模型分为6层,其中4层为隐藏层,每层神经元数为4,输入输出层神经元数为2。对于离线训练过程,训练集、校验集和测试集的样本数量分别为120,20,40,通过WOA算法搜索得到的最佳的学习率为0.1。使用Matlab中的Simulink工具箱搭建1.2节中提到的OFDM系统收发机模型,仿真的主要参数如表1所示。
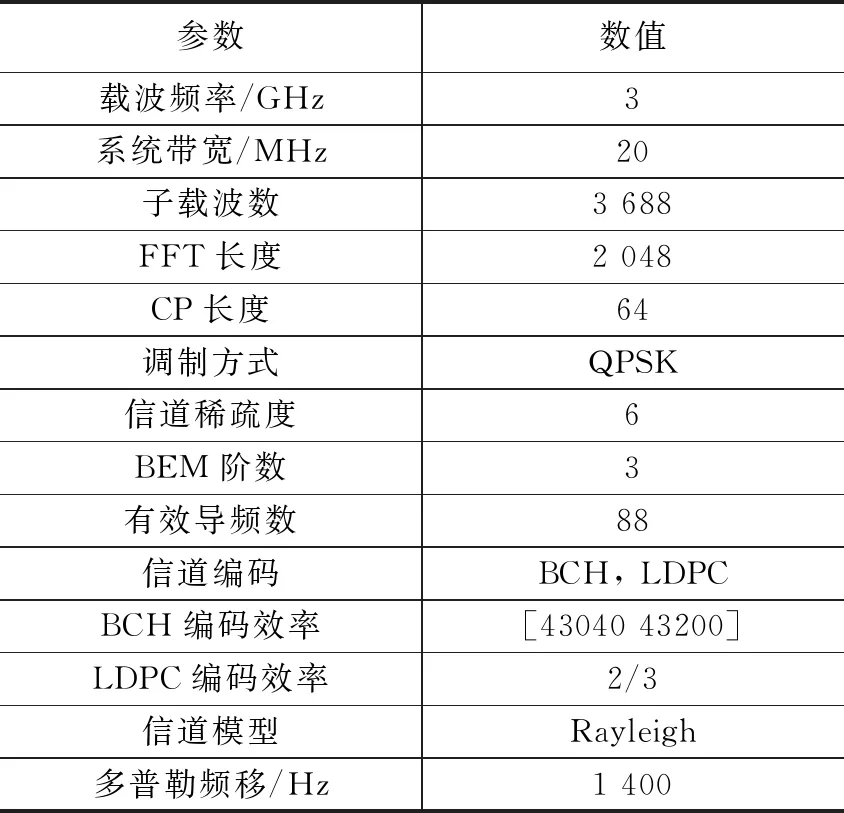
表1 仿真参数
图9为LS信道估计方法、未补偿的BEM结合线性插值的信道估计方法以及本文提到的BEM结合DL的信道估计方法在高速(500 km/h)、不同信噪比环境下的归一化均方误差(NMSE,normalized mean squared error)性能,NMSE表示信道估计方法的精确程度,信道估计结果越接近实际的信道响应,则NMSE的数值越接近0。
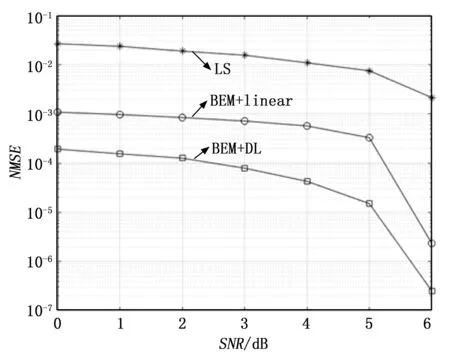
图9 不同信道估计方法的NMSE
总体来看,LS信道估计的NMSE性能最差,其次是未补偿的BEM结合线性插值方法,本文所提到的信道估计方法性能最优。随着SNR的增大,三种方法的NMSE性能均在提升,LS信道估计变化较为平缓,NMSE性能一直较差,这主要是因为LS估计缺乏先验的信道统计信息,而且忽略了信道噪声的影响;而BEM结合线性插值的方法估计精度不足的主要原因在于,双选信道为非平稳信道,其信道的变化规律不满足线性假设,故采用线性插值误差较大;本文所提到的BEM结合DL的信道估计方法NMSE性能提升非常明显,这主要是因为所提到的DNN能够通过训练学习到双选信道的变化特征,对BEM结合线性插值方法进行补偿后可以得到更准确的信道估计结果。
误码率(BER,bit error ratio)性能是一个宏观指标,用于衡量信道估计方法对系统整体性能的影响。图10为上述三种方法在高速(500 km/h)、不同信噪比环境下的误码率性能。
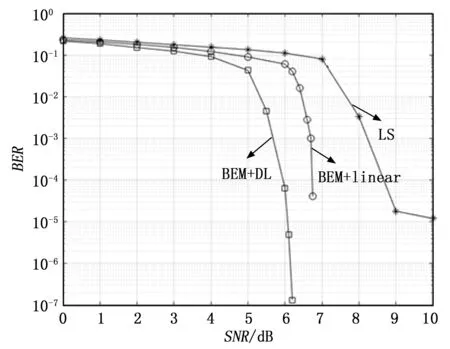
图10 不同信道估计方法的BER
对于BER来说,依旧是LS估计性能最差,本文所提到的估计方法最优。在SNR较小时,三种方法的BER变化均比较平稳,随着SNR的增大,三种方法的BER性能均在提升,本文所提方法在SNR超过5 dB之后BER性能提升明显,而未补偿的BEM结合线性插值的方法需要SNR超过6 dB,而LS方法直到信噪比超过7 dB时BER性能才得到较大的提升,但是提升依旧不如另外两种方法明显。这主要是由于传统的LS方法未考虑信道非平稳的因素以及忽略的信道噪声的影响。综合来看,本文所提方法相对于传统的LS方法峰值SNR增益为4.8 dB左右,相对于未补偿时的BEM结合线性插值的方法峰值增益为1.2 dB左右。
由以上分析可知,对于双选信道,在不同的信噪比环境下,所提到的BEM结合DL的信道估计方法NMSE和BER性能均优于传统的LS方法与未补偿的BEM结合线性插值的方法。
5 结束语
本文基于OFDM系统,采用矩形导频,针对传统的信道估计方法在双选信道环境下性能不足的问题,提出了一种BEM结合深度学习的信道估计方法。对于高速移动环境下信道的双选特性,使用BEM对信道进行建模,减少了待估参数,有效降低了信道估计的复杂度;对于高度移动的环境下信道的非平稳特性,建立了深度神经网络,并通过离线训练使其学习到双选信道的变化特征,提高了信道估计的准确度。从仿真结果可以看出,本文所提的方法具有更优秀的NMSE性能与BER性能。
猜你喜欢
自然杂志(2021年6期)2021-12-23 08:24:46
现代装饰(2018年5期)2018-05-26 09:09:01
电信科学(2016年9期)2016-06-15 20:27:26
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27 06:31:42
华东理工大学学报(自然科学版)(2015年4期)2015-12-01 04:00:44
电源技术(2015年5期)2015-08-22 11:18:38
弹箭与制导学报(2015年1期)2015-03-11 15:32:06
电子设计工程(2015年8期)2015-02-27 12:05:34
电子设计工程(2015年8期)2015-02-27 12:05:33
现代防御技术(2014年6期)2014-02-28 18:26:23
