
基于注意力的双流CNN的行为识别
2020-11-02 11:52马翠红毛志强
计算机工程与设计 2020年10期
马翠红,王 毅,毛志强
(华北理工大学 电气工程学院,河北 唐山 063210)
0 引 言
近年来,研究人员将深度学习应用于视频监控的目标检测、行为识别等领域[1]。Simonyan等[2]利用包含空间流网络和时间流网络双流卷积网络分别提取堆叠光流图和RGB视频中的长时运动和表观特征,该模型仅考虑了视频中的短期动态特征,视频中的长期特征没有得到充分利用。
Woo等[3]提出基于RNN可以实现对视频中多对象行为进行识别。Hochreiter等[4]提出了长短时记忆网络(LSTM),用LSTM替代传统的RNN,解决了RNN梯度消失的问题。Gammulle等[5]设计双流融合LSTM网络用于行为识别,且其应用在模式识别等任务中也取得了很好的效果。
针对上述存在的问题并总结各种网络优势的基础上,提出基于注意力的双流CNN与DU-DLSTM的识别模型来解决复杂场景下监控视频的行为识别问题。
1 整体模型
本文提出的模型采用时空双流网络和视觉注意力提取特征向量,输入DU-DLSTM模块深度解析后经Softmax函数完成识别任务,模型如图1所示。
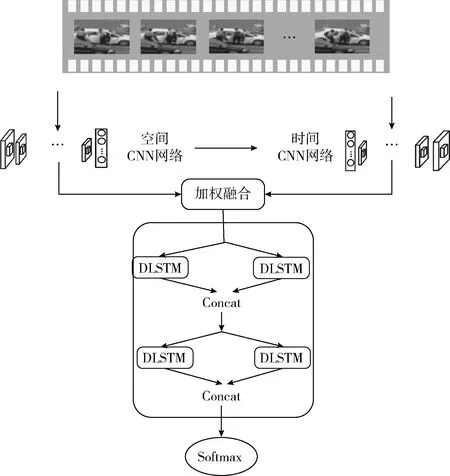
图1 系统总体框架
2 基于注意力的双流CNN
2.1 LSTM
LSTM是时间递归神经网络(recurrent neural network,RNN)的另一种形式,LSTM的优点是解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,与普通的RNN相比,LSTM能够在较长的序列中发挥更好的作用。
LSTM的整体功能实现的结构如图2所示,其中LSTM的最重要的部位就是她的记忆单元ct,它实现的功能是对信息进行筛选,留下最佳信息,如式(5)所示,LSTM的最大的特点就是通过它自身特殊的门[6]结构对行为信息与记忆单元之间交互的能力进行操控。LSTM的主要的门结构是通过一个Sigmoid函数具体体现的,其中σ(x)=(1+e-x)-1表示它的Sigmoid函数,Sigmoid函数优点在于其最终输出值都分布在[0,1]之间,代表最终信息的保留程度。具体如式(1)~式(6)所示
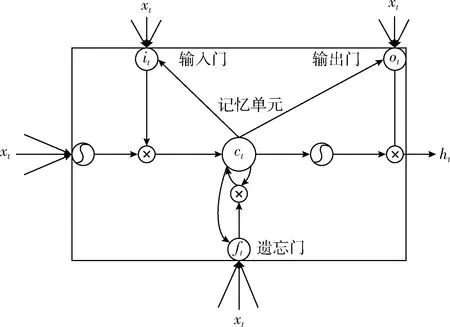
图2 LSTM内部结构
it=σ(Wxixt+Whiht-1+bi)
(1)
ft=σ(Wxfxt+Whfht-1+bf)
(2)
ot=σ(Wxoxt+Whoht-1+bo)
(3)
gt=tanh(Wxcxt+Whcht-1+bc)
(4)
ct=ft⊗ct-1+it⊗gt
(5)
ht=ot⊗tanh(ct)
(6)
式中:xt代表当前记忆单元的输入,ht-1表示上一时刻细胞的输出。it,ft,ot,分别为输入门、遗忘门、输出门,gt是由双曲正切函数创建的一个新的候选值向量。具体如式(6)所示,其中LSTM的输出ht是由ot来具体控制是否需要激活其中的记忆单元ct。本文采用的多层LSTM网络建模隐状态,其中每一LSTM层的全部输出内容成为下一层的全部输入内容,一层层叠加使其形成多层LSTM。
2.2 软注意力机制的空间模型
本文主要提出的空间注意力模型,该模型可以主动学习视频内空间上的重要的特征的概率分布。采用这里提出的注意力机制充分提取视频和其具体的光流序列的整体特征[7]。其中假设xt作为具体的空间网络特征输出,也为时间网络的输入,xt是采样部分的切片。本文选择确定性软注意力机制[8]
(7)
其中,xt表示视频特征立方体,Xt,i为Xt在t时刻的第i个切片,K2表示切片大小,lt,i表示光流特征提取的空间softmax参数[8]
(8)
(9)
其中,c0为初始状态,h0为隐含状态,finit ,c和finit,h分别为多层感知器,视频段的帧数。
2.3 软注意力机制的时间模型
本文提出时间注意模型,解析所有视频帧与识别动作的相关性,解析光流序列得到隐状态参数ht,时间注意模型解析视频帧得到隐状态参数bt,时间维注意力权重值为
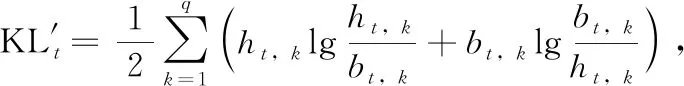
(10)
其中,t表示时间帧,n表示视频长度;h表示隐状态层参数,q为其最大值;bt,k和ht,k分别表示视频帧和光流帧的隐状态参数向量。本文采用sigmoid函数将时间维注意权重系数限制在[0, 1]区间
(11)
时间流网络提取特征的概率分布P(yt=c),利用softmax分类器获得对应类别概率分布
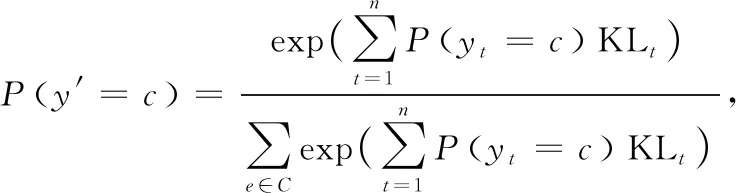
(12)
其中,t代表时间帧,c表示动作类别,P(y′=c)为相关性最大的动作特征。
3 双单向结构DU-DLSTM设计
在行为识别领域LSTM由于可以更好提取长时运动信息备受欢迎,但由于其过多的依赖于所有输入信息,识别精度受到限制。Chevalier等[9]提出的双向LSTM使得准确度有了升高。如图3所示。
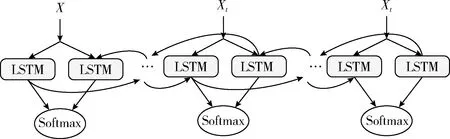
图3 双向结构Bi-LSTM
双向LSTM网络经常遇到各种优化瓶颈,导致识别精度很难进一步提高。通过总结遇到的问题,我们提出 DU-DLSTM模块,如图4所示,两个单向传递的DLSTM组合后形成DU-DLSTM单元。当前各种拓展的LSTM网络结构越来越深,时序信息通过深层次的网络传输后,仍能进行更好地融合,深层双单向LSTM更好地获取动作的全局信息,完成识别任务。
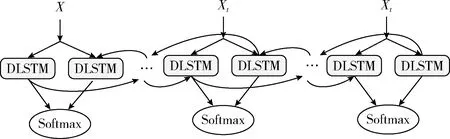
图4 双单向结构DU-DLSTM
DU-DLSTM单元表示为
hDU=c(d(W1hDL1+b1),d(W2hDL2+b2))
(13)
其中,hDL1和hDL2代表相同传输方向的两个DLSTM单元的输入,W和b为权重和偏置项,hDU为输出。
4 实验及结果分析
4.1 数据集
本文使用的视频数据集是KTH,选择了一些动作,如图5所示。该数据集包含固定视角摄像机拍摄的600个动态视频。视频的帧率为25 frame/s,视频每帧图片的分辨率都为160像素×120像素。有25位不同的实验对象,4种不同的实验场景:户外、室内、户外(场景变化)、户外(服饰装扮变化),6种不同的人体行为:散步(Walking)、慢跑(Jogging)、奔跑(Running)、拳击(Boxing)、挥手(Hand waving)、拍手(Hand clapping)。

图5 KTH样本数据集
首先对数据集进行划分,随机取80%作为训练集,剩下20%为测试集。提取视频的RGB帧和光流帧后进行预处理,然后将视频随机剪辑为25 frames的短视频后训练,来增强数据。
4.2 实验环境搭建
本实验主要选择的是Python语言,将其搭建在深度学习框架Tensorflow下实现具体的实验,实验环境:Ubuntu16.04 64位;NVIDIA GeForce GTX 1080Ti(11 G)显卡;32 G内存。
在训练过程中,为加强鲁棒性,首先在imagenet数据集下进行了10万次训练,得到预训练模型,对参数进行优化。图6为具体训练过程中,光流图和视频帧数据随着训练次数的增加,识别准确率的具体变化。
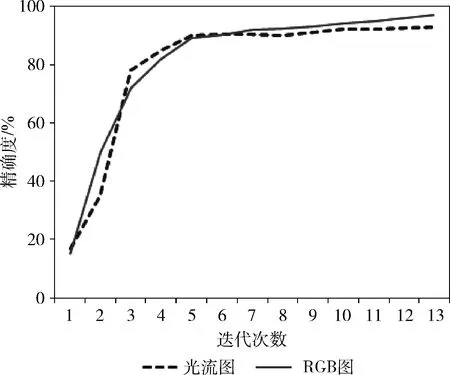
图6 KTH数据集训练准确率
4.3 实验结果分析
本文将模型对KTH测试集中6种不同的行为识别结果做了可视化处理,用来观测模型的效果,对角线元素代表识别的准确率。
通过表1可以看出,分析KTH数据集,慢跑和奔跑行为是最容易混淆的,而拍手、挥手、拳击、散步的识别率准确率极高。通过人眼观察原始的视频也可以看出,慢跑和奔跑的区分度很小,数据本身的相似性极高。

表1 各种行为的混淆矩阵
在先前的实验中, 已经得到空间注意网络与时间注意网络的最佳效果, 受到之前学的结果分布学习相关内容的启发, 本文对具体提出的空间注意网络与提出的时间注意网络得到的实验结果加以不同的分布比来加权, 进行实验。实验结果见表2,分布比=空间层∶时间层。
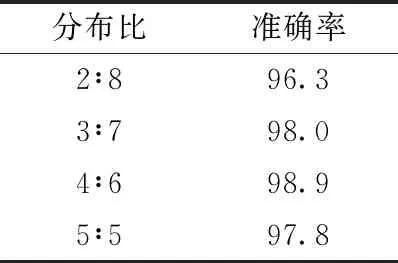
表2 双流网络模型在不同权重比下的准确率/%
从表2可以看出,这里提出的空间注意网络与提出的时间注意网络的实验结果具体的分布比为4∶6时,本文的模型的识别精度相比最高, 在数据集中取得98.9%识别准确率。
最后,将本文的网络模型与目前识别精度较高算法[8,10,11]测试然后对比,其最终的实验结果见表3。
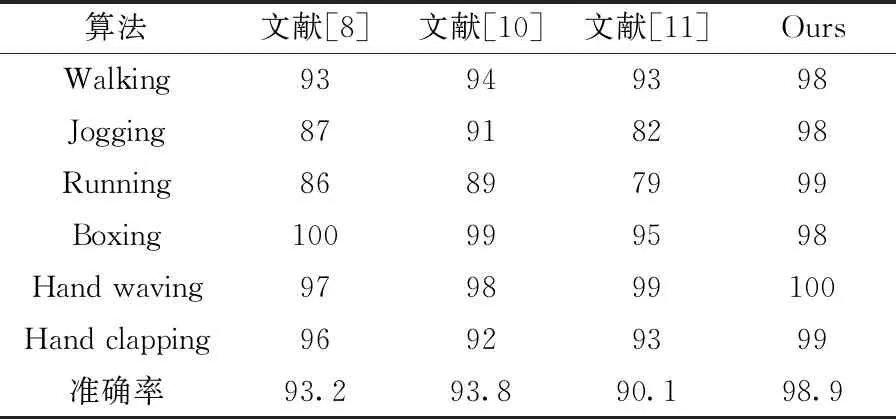
表3 不同算法在KTH上的比较结果/%
从表3中可以看出,本文提出的注意力的双流CNN与DU-DLSTM模型使行为识别的准确率有很大的提高。
5 结束语
为充分融合视频的时间和空间信息,更加充分利用视频的长时运动信息,本文提出的基于注意力的双流CNN与DU-DLSTM的行为识别模型,通过与光流特征结合捕获场景运动信息,构建基于注意力的空间和时间网络,利用注意力机制学习相关性较大的特征对象,构建DU-DLSTM模块拓宽网络深度,有利于学习表征能力更强的特征,最后采用Softmax最大似然函数对视频进行分类,提高了鲁棒性。在KTH数据集上对模型进行了测试,并与其它算法进行比较,表明本文的模型有效提高了识别精度,本文提供一个很好的方案。
猜你喜欢
现代经济信息(2022年22期)2022-11-13
导航定位学报(2022年5期)2022-10-13
中小学校长(2022年7期)2022-08-19
小雪花·成长指南(2022年1期)2022-04-09
冶金设备(2020年2期)2020-12-28
中小学校长(2019年10期)2019-11-07
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
中北大学学报(自然科学版)(2014年3期)2014-11-22
中国铁道科学(2014年6期)2014-06-21
