
基于浮值掩蔽的完全卷积神经网络语音增强系统
2020-10-30 01:57代佳鑫帅英俊
科学导报·学术 2020年40期
代佳鑫 帅英俊

摘 要:为了解决卷积神经(CNN)在语音增强中语音清晰度较差的问题,在卷积神经(CNN)语音增强的基础上,提出了基于浮值掩蔽的完全卷积神经网络语音增强系统。该系统首先采从带噪语声特征输入完全卷积神经网络中,以理想浮值掩蔽作为训练标签,估计出带噪语音理想掩蔽值,其次,将理想掩蔽值与带噪语音相乘作为幅度谱。最后将带噪语音相位谱与幅度谱进行反短时傅里叶变换(ISTFT),得到增强语音。实验结果表明,在PESQ标准下,在SNR分别为-12,-6,0,6,-12dB情况下,该系统性能分别提升了11.5%,12.5%,17.2%,11.8%,11.5%提升效果明显。
关键词:语音增强;完全卷积神经网络;浮值掩蔽;单声道
1 引言
随着NLP方向人工智能技术的发展,语音识别技术达到了一个新的阶段,各式各样较成熟的语音助手使得人机交互的变得越来越容易。但实际应用时,由于采集设备和传输过程中的干扰,往往无法得到较清晰的语音信息,对语音识别结果造成较大干扰。本研究构建了基于完全神经网络的理想浮值掩蔽系统。利用去除全连接层的卷积神经网络来估计掩蔽值。其次,将理想掩蔽值与带噪语音相乘作为幅度谱。最后将带噪语音相位谱与幅度谱进行反短时傅里叶变换(ISTFT),得到增强语音。
2 算法介绍
假设,其中、、分别代表带噪语音、干净语音、噪声的时域信号。对上式进行短时傅里叶变换,再将短时傅里叶变换的频谱分为不同的时-频单元,假设、、分别为x(n)、s(n)、n(n)在(t,f)时-频单元的表示。
理想浮值掩模的定义式如下:
其中、分别表示在(t,f)时-频单元中的信号能量和噪声能量,β为可调的系数通常设置为0.5。为信号能量与噪声能量的线性比值。的取值范围为[0,1]。M(t,f)表示目标语音能量在混合的语音和噪声的比重,M(t,f)为CNN的训练目标。
此系统利用浮值掩蔽得到训练目标,以及特征提取,然后通过CNN网络进行集成。网络采用有监督的方式进行学习。网络会对每个带噪语音信号估计出一个浮值掩模,将估计出来的掩模和带噪语音信号的幅度谱相乘得到增强语音的幅度谱,将增强语音的幅度谱和带噪语音的相位谱相乘作为增强语音的频谱。最后将增强语音的频谱做逆短时傅里叶变换得到增强语音的时域信号。该系统首先从训练集中提取特征值,然后计算IRM值,把此值输入到网络中进行训练。而对于测试阶段,从测试集中提取特征值,输入到网络中,得到增强的语音,然后再进行语音信号重建得到最终的输出信号。
3 实验与结果分析
在实验中,训练集和测试集来自TMIT语料库。对于训练集,随机选择1000个话语,对于测试集,我们随机选择了另500个话语。为了使实验条件更加真实,训练和测试集的噪声类型和SNR水平都不匹配。我们采用噪声为:高斯白噪声(WGN),发动机噪音和婴儿啼声,使用五种SNR等级(-12 dB,-6 dB,0 dB,6 dB和12 dB)。在实验中,从波形中提取512个采样点以形成512个采样点,在该研究中,从波形中提取512個采样点以形成用于所提出的SE模型的帧。此外,还从基线系统的帧中获得257维LPS矢量。该实验中的CNN具有四个带有填充的积层(每个都有该层由15个滤波器组成,每个滤波器的滤波器大小为11)和两个完全连接的层(每个都有1024个节点)。FCN具有与CNN相同的结构,除了完全连接的层各自用另一个卷积层替换。DNN只有四个隐藏层(每层由1024个节点组成)。
对于特征变换,音频信号被下采样到8kHz的,并且静音帧从信号中移除。使用512点短时傅里叶变换(为32ms海明窗)计算光谱矢量,窗口移位为64点(8毫秒)通过去除对称的一半,512点STFT幅度矢量减少到257点.此257点用于输入特征,并且被标准化为具有零均值和单位方差。
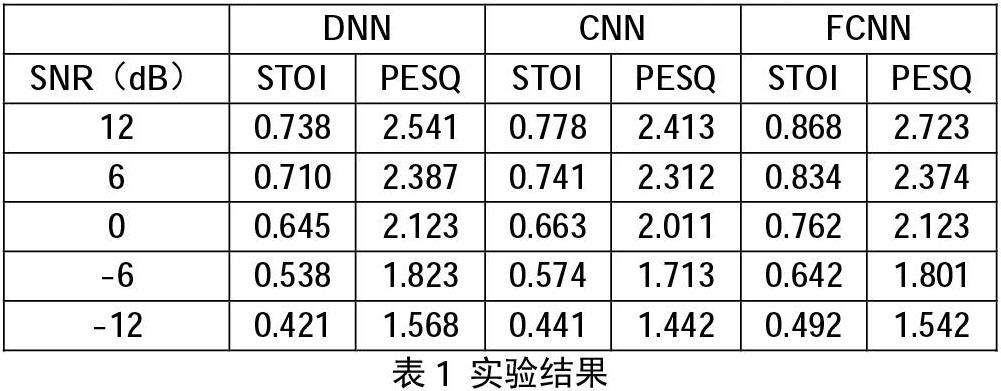
PESQ、STOI分别是用来评价语音质量和语音清晰度的客观指标。PESQ的取值范围是-0.5至4.5,STOI的取值范围是0值1。测试结果如表1 所示。对于CNN,相较于DNN,在SNR分别为12,6,0,-6,-12dB情况下,PESQ指标分别提升了5.42%,4.22%,2.79%,6.69%,4.75%。验证了CNN相较于DNN语音增强效果更好。但是我们注意到在STOI标准下,CNN相较于DNN,提升不明显。而对于FCN,在SNR分别为12,6,0,-6,-12dB情况下在PESQ标准下,分别提升了11.5%,12.5%,17.2%,11.8%,11.5%,在STOI情况下,也分别提升了10.27%,2.68%,5.03%,5.13%,6.93%,证明该系统是有效的。
结束语
本文基于在卷积神经网络的基础上,在卷积神经网络语音增强的基础上,提出了基于浮值掩蔽的完全卷积神经网络语音增强系统。该系统改进了卷积神经网络,使神经网络变得更小,适用于嵌入式设备。同时,该系统考虑到无声段理想浮值掩模不存在的问题,设计了合理损失函数。
参考文献
[1]周志华.机器学习[M].北京:清华大学出版社,2016.
[2]赵晓群,黄小珊,宫云梅.基于无语音概率改进的对数谱幅度估计增强算法[J].信号处理,2008,24(06):912-916.
