
建筑HVAC的可视化及基于非监督学习的异常探测
2020-10-29 02:06赵雪圻
中国房地产·学术版 2020年9期
关键词:人工智能
摘要:建筑可视化是应用该技术的重要领域。讨论功耗异常检测方法,试图找到一种合适的数据可视化方法来构建HVAC功耗和异常检测。与其他建筑物异常可视化方法相比,K-Means+Polty异常检测可视化方法主要具有以下优点:(1)可以将室外数据与传感器检测到的功率损耗数据结合起来,包括天气的影响可以被认为包括在内,并获得更准确的结果;(2)所有可视化数据都提供了一个交互式UI,便于建筑物管理员在异常时刻更快速、方便地查找相关信息;(3)与带标签的数据采集相比,无标签数据的采集难度和采集成本大大降低。
关键词:建筑可视化;异常检测;无监督学习;人工智能
中图分类号:F293 文献标识码:A
文章编号:1001-9138-(2020)09-0064-69 收稿日期:2020-09-07
1 绪论
美国有73%的用电量和39%的二氧化碳是建筑物排放的,如何减少用电量也是环境保护中非常重要的部分。如何减少建筑物的用电量呢?一种方法是减少异常用电量。在许多情况下,异常的发生将使功耗达到峰值,但是这样的功耗并未带来任何收益。除此之外,通过检测电力系统异常并减少电力损耗来解决电力系统问题不会影响普通用户的使用。因此,如何检测建筑用电异常以及如何帮助建筑经理找出异常情况将成为解决此问题的关键。本文将专注于用无监督学习的方法解决HVAC(供暖、通风和空调)部分的电力异常检测。尽管建筑物中有许多不同的系统,但是HVAC系统占据了商业建筑总能耗的30%。更详细地讲,HVAC消耗5.35万亿Btu,照明设备需要1.48万亿Btu,包括PC在内的办公设备需要1.71万亿Btu等。有许多研究集中在如何节省照明功率上,但实际上照明仅需1.48万亿Btu。换句话说,HVAC的能耗几乎是照明的4倍。因此,尝试减少HVAC的用电量非常有意义,因为它是商用建筑用电量的最大部分。异常检测和可视化是帮助建筑物管理员节省HVAC或其他部分耗电方法的有效方法。
异常检测(Anomaly detection)也被称为离群值检测(outlier detection)。它是对不常出现的个例、事件或观测值的识别,这些数据与大多数据明显不同,从而引起人们的关注。功耗异常检测区域中使用了一些方法:基于预测的异常检测(prediction-based anomaly Detection)、基于聚类的异常检测(clustering-based anomaly detection)、Z分数(z-score)、自回归模型(Autoregressive Model)、自动回归移动平均模型(Auto regressive-moving-average model)、高斯内核分布模型(gaussiankernel distribution model)等。随着机器学习技术越来越发达,一些机器学习方法大大改善了异常检测的实施难度和检测正确率。根据数据是否带有标签(在异常检测领域,标签表示该数据是否已知为异常,未标记表示该数据不知道其是否为异常),有三种不同类型的异常检测技术:一是监督学习技术。监督技术基于整个数据(异常数据和正常数据)生成模型。将需要预测的数据根据生成的模型计算出不同类别的概率,并分配给整个模型中具有最高概率的类别中。二是半监督学习。半监督技术仅针对正常数据生成模型。它介于监督技术和无监督技术之间。如果需要预测的数据很好地适合半监督模型,则将其分类为正常;否则,将其分类为异常。三是无监督技术。无监督技术不需要带有任何标签的数据。该方法基于以下假设:异常值或异常的发生概率或频率比正常数据小得多。无监督技术将相似的数据划分为一个类,并将整个数据集分为多个类,异常类与其他类相比,数据明显更少。
由于本文研究的是没有标签的数据,因此,无监督技术将是最佳选择。
异常或离群值可分为三类:一是点异常:与其他数据相比,存在一个单个数据异常。二是上下文异常:数据实例在上下文中是异常的,例如在冬季,所有HVAC都使用暖气,但是其中一个数据对空调的使用率很高。三是集合异常:当尝试浏览整个数据集时,一些相关数据实例是异常的。这些异常数据并不是单个数据,而是一个集合。可视化可帮助建筑经理更直接地获取所需信息。与大量数字数据相比,人类更愿意看到可视化的数据,并且对可视化的数据有更加清晰直观的理解。
2 相关工作
2.1 电力消耗异常检测
基于预测的异常检测是电力消耗异常检测的一个优秀方法。此方法有一个前提假设:人们所观察到的模式应该是通用的,并将在未来保留。模型基于现有数据,并且可预测的方法无法根据未来发生的改变做出应有的调整。因此,如果将来的数据不遵循现有模型发现的模式,则该模型将无法准确地预测将来的数据。
基于聚类的异常检测适用于时间序列数据,并且仅有少数数据是异常数据,大多数时间的数据都是稳定且正常的。Z分数会根据一个可靠的标准偏差发生的频率来识别异常。每一个单一数据会根据Z分数的算法得到一个单独的Z分数。分数越高表明数据异常的可能性越高。
自回归模型是基于时间序列数据分析中的一种著名方法。这种方法的关键是试图找到数据和过去数据之间的关系,这意味着它们不是独立的。例如,AR(2)意味着使用Xt-1和Xt-2预测数据Xt,以t时刻为基准,t-1意味着t之前的第一个时间节点,t-2意味着t之前的第二个时间节点。
2.2 可视化
可视化可以帮助用户更简便地查看整个数据集并对整个数据集产生更直观的认识。在建筑物电源异常检测区域中,可视化被广泛使用,以帮助建筑物管理员更轻松地獲取有关建筑物的信息。通过建筑物可视化,建筑物管理员可以通过图形方式了解数字数据,从而不仅可以了解到单一的数据,还可以轻松找到数据变化的趋势和异常数据。由于包括暖通空调和室外温度在内的数据都是基于时间序列的,因此适用的方法应该着重于深入研究构建异常可视化区域的时间序列可视化方法。
时间序列方式有几种不同的建筑物可视化方法:
一是折线图(line chart):折线图是建筑物电源异常检测区域中最常见的可视化方法。在大多数情况下,x轴显示数据时间,y轴显示电力消耗。
二是递归模式(Recursive Pattern):用来展示数据属于某个确定类别的概率,或者使用不同颜色表示将数据预测到不同的类别。通常,数据的颜色越亮,代表其出现的概率越高(在少数情况下使用相反的颜色)。热力图是递归模式的一种,本文所使用的可视化方法之一正是热力图。
三是螺旋可视化(Spiral visualization):螺旋可视化通常用于可视化周期性数据集。在螺旋可视化中,每一轮螺旋用于显示特定时间段的数据,例如每轮一天或每星期一周。螺旋可视化可以更直观地显示数据的周期性特征。
四是矩形式树状图(Treemapping):矩形式树状图与树状图不同,在树状图中,彼此之间存在根节点和分支连接,但是在矩形式树状图中,整个图形是由数个小长方形组成的一个矩形。每个小矩形代表一个类(class),小矩形的面积越大,意味着相应类出现的可能性越大。而且每个矩形还具有自己独特的颜色,以显示彼此之间的关系。
3 方法
上文所介绍的电力异常检测方法并不适合建筑HVAC功耗异常检测。对于异常检测,无监督技术K-Means是更为适合的方法之一。对于基于时间序列的异常可视化部分,将折线图和热力图相结合可能会得到更好的结果。
3.1 电力消耗异常检测
机器学习在数据科学领域非常有帮助。本文的案例研究数据都是无标签数据,因此应该选择一种无监督算法来解决此问题。第4章案例研究的主要目标是找到异常数据。要应用无监督学习算法,有一个必要的假设:异常数据的数量远远小于正常数据。如果不满足这一假设在对案例数据进行聚类时会出现问题,无法分辨哪一个聚类是需要找到的异常类。
那么,章节2.1所提到的方法为什么不适合用于建筑电力异常检测呢?自回归模型的缺陷是:温度将对HVAC产生很大影响,如果室外温度由于气候变化突然升高或降低,HVAC系统将适应室外情况并改变工作状态。比如室外温度突然下降,则供暖的电力消耗将大大增加,自回归模型将基于最近几天的数据得出异常的结论。实际上,HVAC系统照常工作,只是由于室外温度的变化而使功耗发生很大变化,而自回归模型没有这种能力来找到温度与HVAC功耗之间的联系。Z分数也有这样的问题,因为它基于整个数据的均值和标准差,而夏季和冬季分别使用不同的系统,一种是空调,一种是暖气,两者电力消耗量并不相同。如果使用整个数据平均值,将很难检测到异常。另一方面,如果为使用空调和暖气建立两个不同的Z分数模型,来尝试解决不准确的平均值问题,那么当温度突然下降,它将给出相当高的Z值。
因此,对于HVAC功耗异常检测,重要的是找到一种可以将室外温度和功耗连接在一起以获得更好精度的方法。这也是为什么要将室外温度作为变量的原因,而不仅仅是依据供暖和空调的电力消耗来建立所要使用的模型。
机器进行无监督学习方法的优势是可以利用多维度的数据并且不需任何数据的标签。而恰恰就是这样的特性,可以解决室外温度和电力消耗的直接联系关系,从而更加准确对电力消耗异常做出判断。一旦算法生成模型,新数据就可以在模型上验证,系统就可以自动将新数据直接分类到正常组或异常组。K-均值(K-Means)的关键公式如下:
算法的核心就是尝试最小化式(1)来为每个组找到最合适的中心点。xi代表已知数据的多维数据,包括室外温度、暖氣电力消耗、空调电力消耗。μj是聚类(cluster)的中心点,j的数量由人为定义,意味着将数据集分为j个族。因此,K-Means聚类的方法就是尝试找到每一个最佳的μj,使其组内所有数据到中心点μj的距离之和最短。
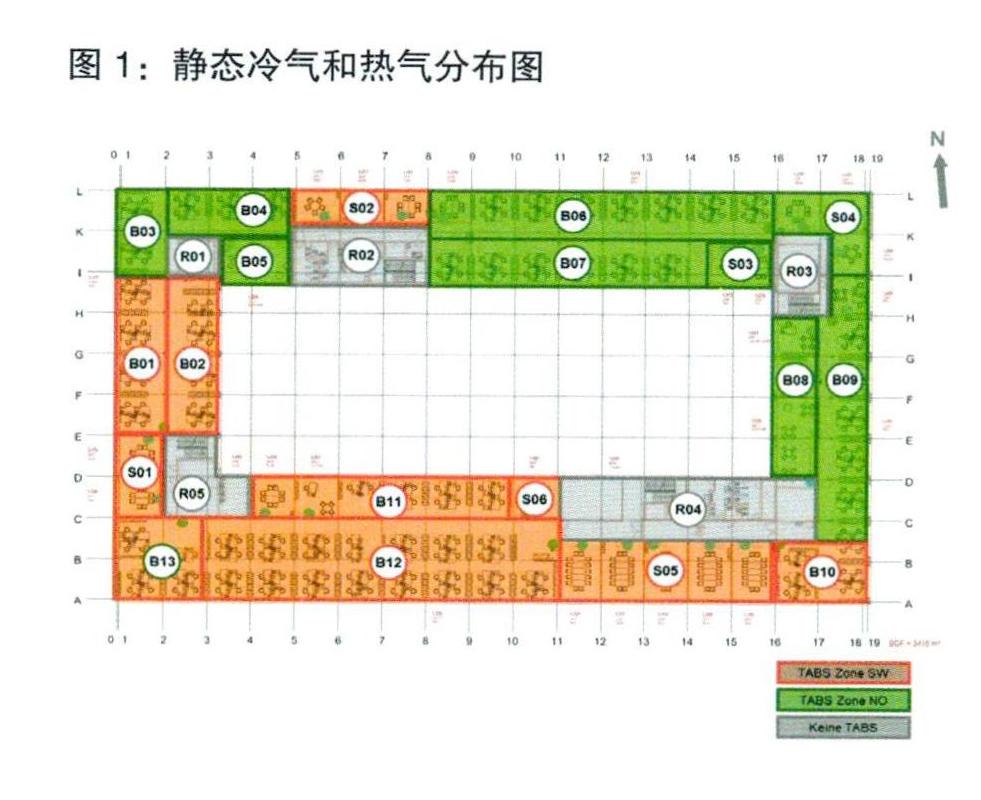
除了传统的HVAC数据外,外部温度也被视为xi的附加维数,并将其添加到x;以执行与HVAC的K-Means聚类。这意味着每个xi具有5个维度,分别代表南/西冷气电力消耗、北/东冷气电力消耗、南/西热气电力消耗、北/东热气电力消耗和外部温度。建筑各房间静态冷气热气分布如图1所示,橘色为南/西部分,绿色为北/东部分,灰色为没有HVAC房间。
3.2 可视化
本文方法的可视化部分使用了折线图和热力图,并结合了两者的优点。折线图用于显示初始数据,例如按时间序列显示电力消耗或按时间序列显示室外温度。热力图将显示数据所属的最佳类别。热力图中的每个像素代表一个时间戳,像素的颜色显示了该时间点数据所属的类编号。
在案例研究中,热力图并非对所有xi都进行了可视化,而是在对所有xi进行K-Means聚类之后,每6小时(0:00、6:00、12:00、18:00)取一次值,然后将取出来的这些值进行可视化,在案例研究中聚类族的数量J等于4a
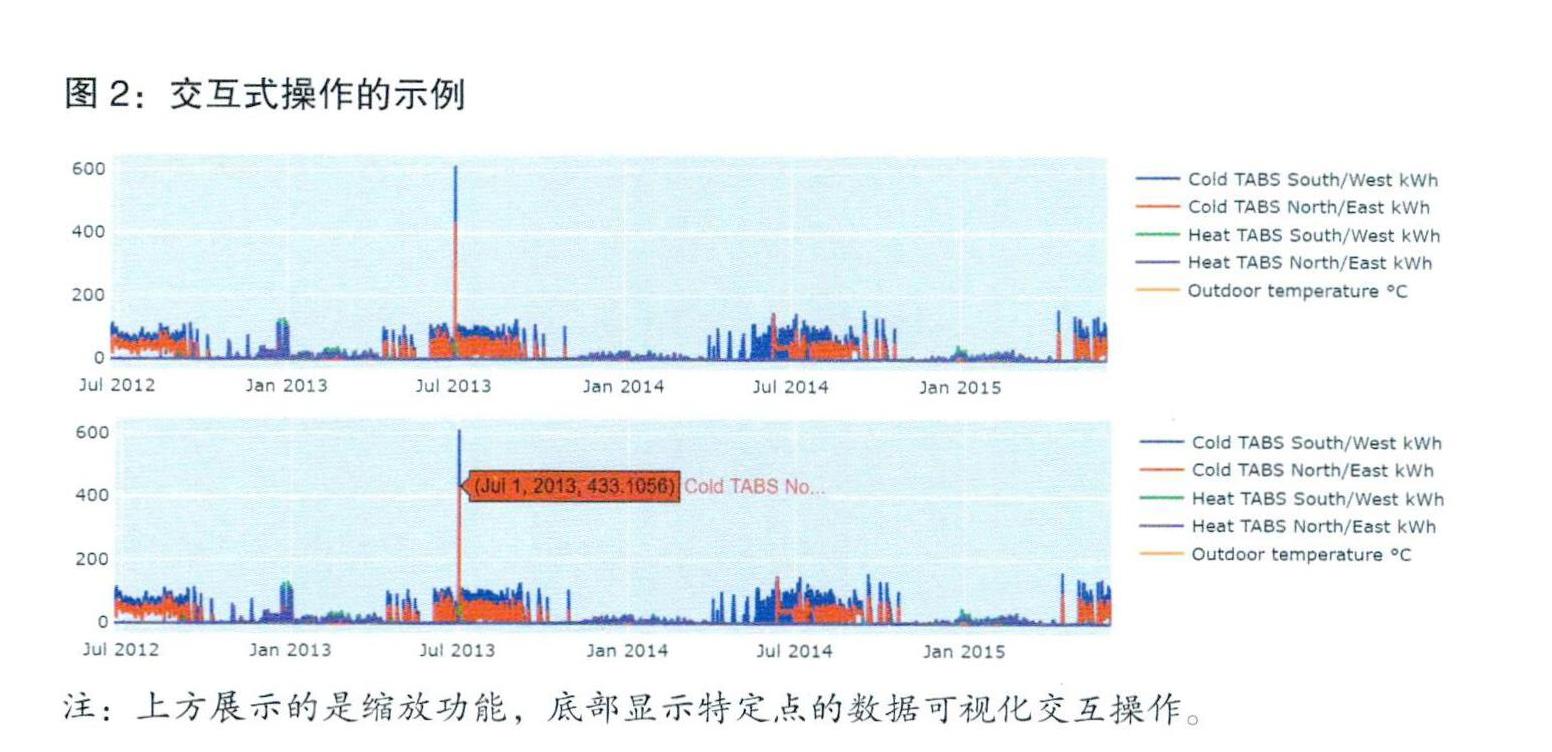
此外,本文的方法还为建筑物管理员提供了交互式操作。包括对可视化的数据进行放大缩小,以及当触摸或移动鼠标到所需位置时,具体数据值的展示。图2显示了有关交互操作的示例。它从图3中3年的数据放大到了一周的数据,并检查了2013年7月1日22:00北部和东部的冷气电力功耗。
4 案例研究
4.1 实验环境
Python 3.7.7
Numpy 1.18.1
Pandas 1.0.3
Plotly 4.5.2
Sklearn 0.22.1
4.2 数据信息
案例研究数据来自Synergy BTC AG,位于伯尔尼Laupenstrasse 20,3008。它是一个大约有9560平方米、三层楼高的建筑物,位于Industrigebiet的Ostschweiz。整个建筑有13个办公区域(主要是OpenSpace)、6个会议室和5个外围区域。每个小时,传感器会记录电力消耗的数据。
图1显示了案例研究数据中的HVAC系统。整个建筑分为两部分:西/南和东/北。有一些特殊情况,例如S02分为南/西,而S02则更靠近北。北方和南方的照明时间不同,因此在不同的室内温度下,所需的HVAC功耗将有所不同。HVAC数据将对整个K-Means的聚类产生一定的影响。
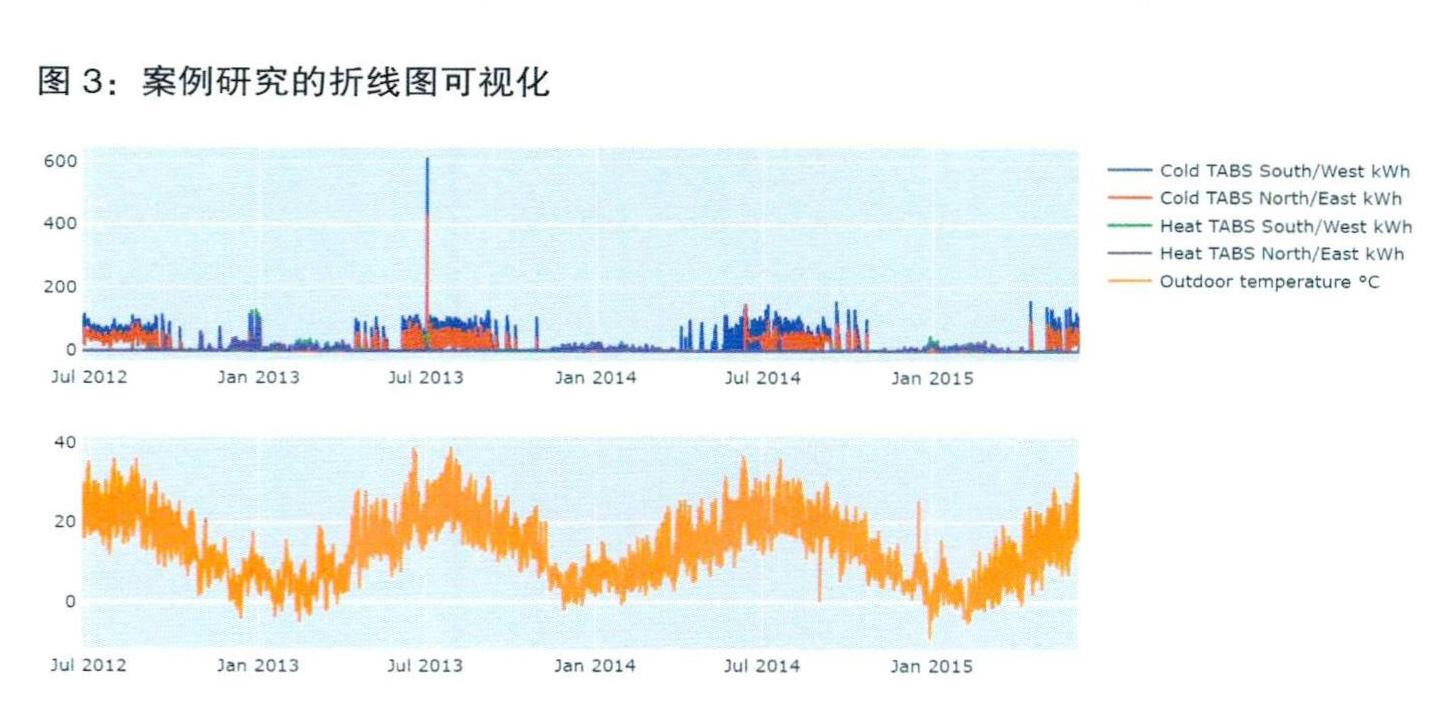
图3有两个子图。上面的子图是可视化功耗,下面的子图显示了同一时间的室外温度。但是,由于使用两个子图片分别进行可视化,也带来了一个问题:横坐标并不完全一致。在案例研究中,个别室外温度数据丢失,而两个子图看上去完全正常。
4.3 结果
在本文的案例研究中,j的数值被设置为4。之所以将j设置为4,是因为建筑的HVAC系统主要存在4种情况:(1)室外炎热,需要空调;(2)室外环境很好,无需空调或暖气;(3)室外寒冷需要暖气;(4)异常数据。
原始的数据并不能满足机器学习的格式,因此必须进行规范化。通过归一化将几组不同的数据进行归一,使不同的属性之间拥有相同的权重,例如室外温度是两位数,而电力消耗可能是三位数,这就会导致电力消耗的权重远远大于室外温度,但是归一化之后,两组属性的最大值被设为1,大大减小了样本数据属性之间带来的权重变化。对于K-Means中的其他一些参数,最大迭代数为10000,重心种子的值设为10。
图4显示了方法获得的最终结果,并将结果可视化。4种不同的类别所显示的4种不同的颜色,而用黄色表示异常则更容易找到。异常检测可视化同样支持交互操作。每个数据具有x、y、z的三个属性,x表示日期,y表示一天中的时间,z表示数据所属的类。有趣的是,与K-Means发现的异常点相对应的数据对于人类视觉而言并不那么重要。除此之外,2013年7月1日10点的异常数据在热力图中并没有被展示,因为热力图选取的时间并不包含10点,见图5。
5 总结
本文不仅关注异常检测,同时还提供了一种优秀的可视化方法,并在异常检测和可视化之间找到平衡。组合折线图和热力图不仅可以帮助建筑物管理员轻松获得有关整个数据的概览,还可以快速找到异常数据信息。
本文的主要结论如下:(1)使用无监督方法K-Means来适应功耗异常检测,从而显着缩短检测时间。(2)结合折线图和热力图,以帮助建筑物管理员轻松获得有关整个数据的总体概览,同时快速找到异常数据信息。(3)提供了一种交互式的方法来取得可视化折线图和热图中的数据。交互方式可以使建筑管理员更加方便地获取数据的详细信息。(4)找到了一种将空调、暖气和室外温度结合在一起的方法。大多数传统方法无法将室外温度与HVAC系统结合起来。但是,室外温度是HVAC功耗和异常检测的直接影响因素。
参考文献:
1.Y.Agarwal,S.Hodges,R.Chandra,J.Scott,P.Bahl,and R.Gupta.Somniloquy:Augmenting NetworkInterfaces to Reduce PC Energy Usage.In Proceedings ofUSENIX Symposium on Networked Systems Design andImplementation(NSDI09)USENIX Association Berkeley,CA,USA,2009
2.Mills,Evan.“Building commissioning:a goldenopportunity for reducing energy costs and greenhouse gasemissions in the United States.”Energy Efficiency 4.2 (2011):145-173
3.Goetzler,William,et al.Energy savings potential andRD&D opportunities for commercial building HVAC systems.No.DOE/EE-1703.Navigant Consulting,Burlington,MA(United States),2017
4.Janetzko,Halld or,et al.“ Anomaly detection for visualanalytics of power consumption data.”Computers&Graphics38(2014):27-37
5.Seem,John E."Using intelligent data analysis to detectabnormal energy consumption in buildings.”Energy andbuildings 39.1(2007):52-58
6.Cui,Wenqiang,and Hao Wang.“A new anomalydetection system for school electricity consumption data.”Information 8.4(2017):151
7.Chandola,V.:Banerjee,A.:Kumar,V.Anomalydetection:A survey.ACM Comput.Surv.(CSUR)2009,41,15
8.Chatfield,C.The Analysis of Time Series:AnIntroduction; CRC Press:Boca Raton,FL,USA,2003
9.Oelke,Daniela,et al.“Visual boosting in pixel一basedvisualizations.”Computer Graphics Forum.Vo1.30.No.3.Oxford,UK:Blackwell Publishing Ltd,2011
10.Weber,Marc,Marc Alexa,and Wolfgang M ii Her.“Visualizing time-series on spirals." Infovis.Vol.I.2001
11.Shneiderman,Ben.“Tree visualization with tree-maps:2-d space-filling approach.”ACM Transactions ongraphics(TOG)11.1(1992):92-99
12.jain,Anil K.“Data clustering:50 years beyondK-means.”Pattern recognition letters 31.8(2010):651-666
作者簡介:赵雪圻,瑞士伯尔尼大学硕士研究生,研究方向:计算机科学与技术-人工智能-深度学习。
猜你喜欢
儿童故事画报(2022年3期)2022-04-27
作文周刊(高考版)(2020年12期)2020-05-28
科学Fans(2019年6期)2019-07-26
商界(2019年12期)2019-01-03
故事作文·高年级(2018年11期)2018-11-19
IT经理世界(2018年20期)2018-10-24
中国经贸聚焦·英文版(2017年9期)2017-09-26
小康(2017年16期)2017-06-07
IT经理世界(2017年6期)2017-03-29
南风窗(2016年19期)2016-09-21
