
基于深度学习的移动端表情识别系统设计
2020-10-29 07:52孔英会郄天丛张帅桐
科学技术与工程 2020年25期
孔英会, 郄天丛, 张帅桐
(华北电力大学电子与通信工程系, 保定 071003)
表情识别在很多场景有应用需求。基于传统的机器学习表情识别方法中,最重要的是表情特征的提取,选取的特征必须能够尽可能地表征人脸面部表情,以便能够识别出各种人脸表情。Zhang等[1]使用34个基准点的几何位置作为面部特征来表征面部图像;Acevedo等[2]提出了一种在人脸上寻找关键点,然后把关键点连成一个三角区域来提取特征的方法;文献[3]运用可变形组件模型(deformable part model, DPM),在CK+、Jaffe数据集上取得了较好的效果。这些特征虽然易于提取和计算,但是传统表情特征的提取方法存在诸多局限,比如不同类别的表情之间具有很大的相似度,而同一类别的表情之间又有很大的差异性等,识别效果受到局限。
近些年,卷积神经网络在图像分类和识别等领域取得了重大进展,2014年Google团队提出的Inception网络,在ImageNet数据集上的Top-5准确率达到了94.1%,而后续提出的极限版本Xception网络,在Top-5正确率更是达到了94.5%。卷积神经网络在表情识别领域也取得一定成果,文献[4]采用了VGG-Face网络进行表情识别实验,在CK+数据集上达到了91.3%的准确率;文献[5]提出了网中网残差网络模型(NIN _ResNet)对表情图像做分类识别研究,在fer2013和CK+数据集上取得了较好的效果;文献[6]受Xception网络启发引入了深度可分离卷积模块,设计了一个14层的卷积神经网络,在fer2013数据集上达到71%的准确率。虽然上述方法中的表情识别准确率较高,但是网络模型的参数非常多,参数量均达到了上亿,这样得到的识别模型也就非常大,给移动端的部署带来了巨大的挑战。针对移动端深度学习模型的研究也取得了一些研究成果,文献[7]将MobileNet-V1神经网络部署在Android手机上,实现了垃圾分类;文献[8]将改进后的 MobileNet网络与SSD(sigle shot multiBox detector)目标识别框架相结合起来构成一种新的识别算法,并移植到了IOS(iphone operation system)移动端设备上,能够对城管案件进行目标识别,且网络在一定程度上降低了参数数量,减小了模型大小;文献[9]提出了mini_Xception网络架构进行表情分类并取得了较高的识别率,最后一层加入了全局平均池化,减少了参数的数量,模型所需空间更小,该模型对于移动端应用提供了更好的支持。
随着信息时代的到来,智能家居已经走入了生活,并已经有了相当的发展规模,近些年出现的有智能监护系统、人脸身份验证系统、家居自动化系统等。而智能家居系统中,情绪识别的研究也取得了一定的成果,文献[10]提出了一个虚拟人类情感模型,并将其运用于智能家居系统,通过识别家人表情来掌握家人满意度和舒适度;文献[11]将表情识别算法移植到嵌入式设备中,设计了一款老年护理机器人。但是,有关智能家居的表情识别研究依旧停留在个人电脑端,而移动终端家居表情识别的研究几乎是空白,在智能手机普及的今天,研究移动终端家居表情识别,具有重要意义。
针对情感化的智能家居应用需求,提出了一种基于深度学习模型的移动端表情识别方法,并进行了系统设计。通过Vitamio 框架获取远程视频,采用轻量级模型mini_Xception进行表情识别以适应移动端需求,将训练好的模型移植到Android手机之中,进行了实验测试,结果表明设计的系统可实现实时远程表情识别,及时了解家人状况,为智能家居应用提供技术支持。
1 mini_Xception网络结构
mini_Xception网络架构是Xception网络的改进版,主要是对Xception网络进行了压缩,使之变得更为轻量级。Xception网络是Google公司在2016年提出的一种网络结构,也是继Inception后提出的对Inception V3的另一种改进,主要是采用深度可分离卷积来替换原来InceptionV3中的卷积操作。而mini_Xception网络正是引入了深度可分离卷积的思想,这样不仅提升了分类的正确率,也增强了网络对诸如人脸表情这类细微特征的学习能力。
1.1 InceptionV3网络结构
Inception结构由Szegedy等[12]在2014年引入,被称为GoogLeNet(Inception V1),之后被优化成多种模型诸如InceptionV2、InceptionV3以及最新的Inception-ResNet。自从首次推出,Inception无论是对于ImageNet的数据集,还是Google内部的数据集,都是表现最好的模型之一。有着多分支、不同卷积核大小的Inception模块是Inception系列网络的基本构成单元。图1所示为InceptionV3模块。
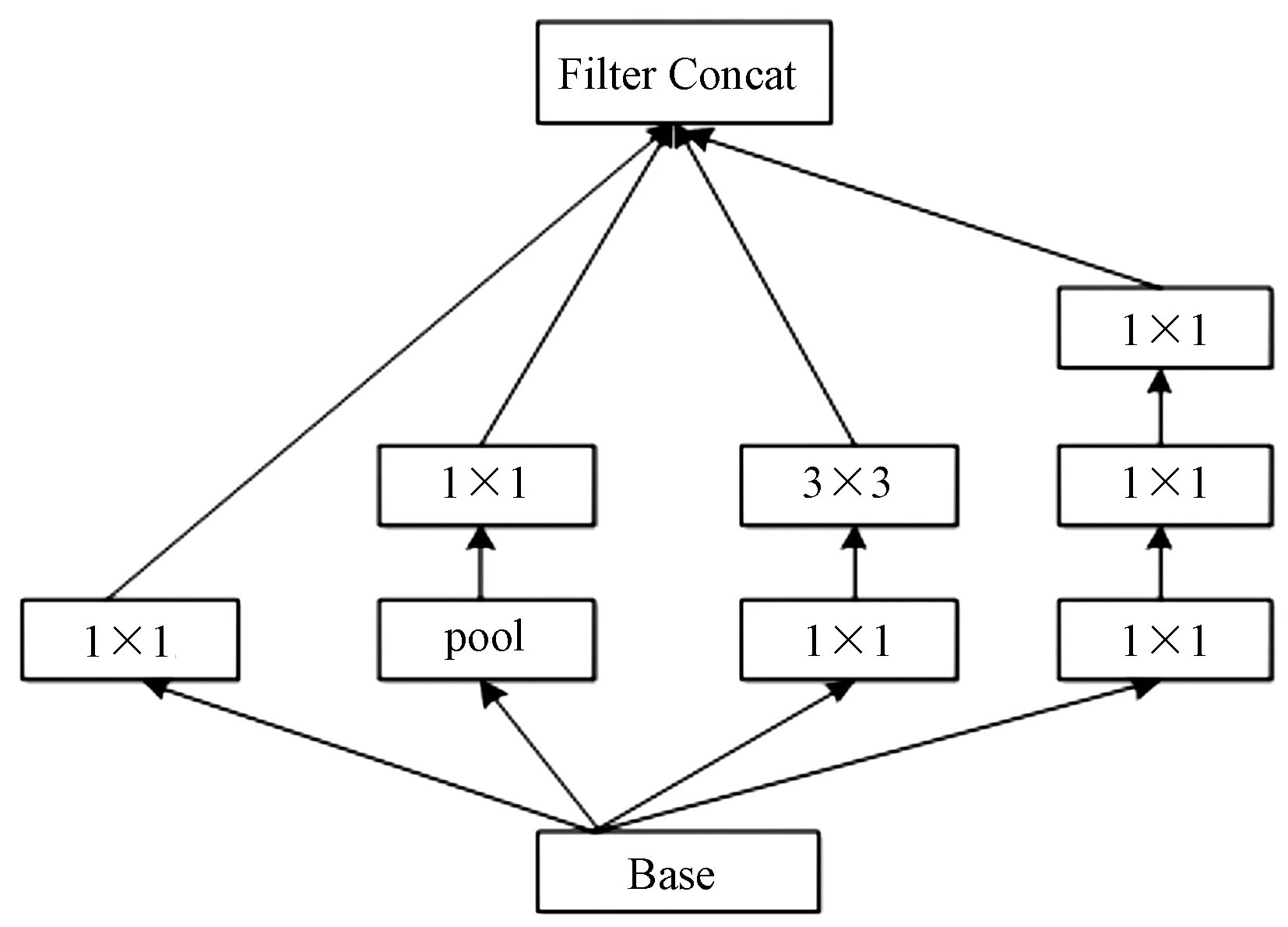
图1 InceptionV3模块Fig.1 The model of InceptionV3
InceptionV3引入Factorization into small convolutions的思想,将一个较大的二维卷积拆成2个较小的一维卷积,比如将7×7卷积拆成1×7卷积和7×1卷积,一方面节约了大量参数,加速网络运算能力并且减轻过拟合现象;同时增加一层非线性变换,扩展模型的表达能力。
1.2 深度可分离卷积
标准卷积是卷积神经网络最基本的运算方式,是卷积神经网络的基础,如图2所示。假设输出特征图大小为DF×DF×N,输入特征图大小为DF×DF×M,其中DF是输出特征图的空间宽和高,输出是N个通道,输入是M个通道,卷积核尺寸为DK×DK,故标准卷积计算量大小为DF×DF×DK×DK×M×N,参数量大小为DK×DK×M×N。

图2 标准卷积Fig.2 Standard convolution
深度可分离卷积由两层组成,如图3所示。它将标准卷积分解为一个深度卷积和一个1×1的逐点卷积,深度卷积与逐点卷积如图3所示。先通过DK×DK×M的卷积核对之前输入的M个特征通道卷积,但是这里DK×DK×M的每个DK×DK都只对输入的M通道中对应的那个进行相应的卷积。最后输出是M个通道的输出,然后接上一个点卷积将输出映射为N个通道,这里卷积核大小变成了1×1。

图3 深度可分离卷积Fig.3 Depthwise separable convolutions
从图3中可以看出,深度卷积的计算量大小为DF×DF×DK×DK×M,参数量为DK×DK×M;逐点卷积的计算量为DF×DF×M×N,参数量大小为M×N。而深度可分离卷积计算量为深度卷积与逐点卷积之和,即DF×DF×DK×DK×M+DF×DF×M×N,其参数量大小也是深度卷积与逐点卷积之和,即DK×DK×M+M×N。进一步可以得到深度可分离卷积计算量与标准卷积的计算量之比:

(1)
同时,还可以得到深度可分离卷积和标准卷积参数量之比:
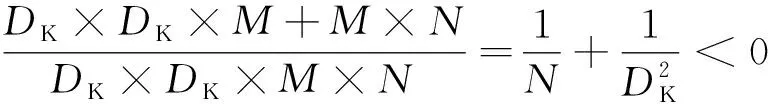
(2)
由此可以看出,深度可分离卷积操作计算量、参数量都发生了下降,将其运用到卷积神经网络结构中,可以大大降低网络的计算量和参数量,节省CPU的运算空间。
1.3 Xception模块
使用深度可分离卷积替代Inception模块能够改善Inception网络性能,即用深度可分离卷积堆叠来构建模型,由此得到一个完全基于深度可分离卷积的神经网络结构,称其为Xception,意指“极致”Inception[13],结构如图4所示。其主要是对每个输入通道先独立进行空间卷积,然后再使用1×1大小的滤波器进行逐点卷积,最后将通道输出映射到新的通道空间,将深度可分离卷积操作引入Xception网络结构中,使得参数由原来InceptionV3的23万降为了22万;在ImageNet数据集测试上,Xception也比Inceptionv3的准确率稍高;同时,Xception引入了ResNet的残差模块显著加快了Xception的收敛,并获得了更高的正确率。
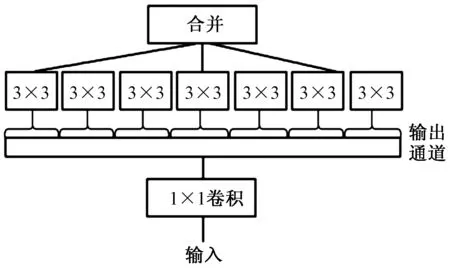
图4 Xception模块Fig.4 The model of Xception
1.4 mini_Xception架构
虽然Xception的参数相比于InceptionV3有了下降,但是对于移动端应用来说,参数量还是比较大,若在移动端上直接采用Xception网络模型,手机CPU运算起来会比较慢,识别速度也会变慢,所以需要对Xception模型进行简化。mini_Xception[13]是一个全卷积神经网络,模型架构如图5所示,它包含4个深度可分离卷积模块,在每个卷积层之后采用了批量归一化层,批量归一化层可以加速网络训练和收敛,此外采用ReLU作为激活函数;每个卷积层之后连接最大池化层,最后一层卷积层之后没有采用全连接层,而是采用了全局平均池化层,这样可以防止网络出现过拟合并降低了参数;之后再接softmax层来进行表情分类。

图5 mini_Xception网络结构图Fig.5 mini_Xception network structure
该模型架构不仅引入了深度可分离模块实现了降低参数,还对Xception网络进行压缩,由原先的36个卷积层变成了7个卷积层,使得模型参数进一步降低到60 000个,参数量比Xception网络降低了391倍。此外,该模型架构在FER-2013表情数据集上进行了测试,在表情识别任务中获得了66%的准确率,模型的权重可以存储在855 KB的文件中。在I5-4210M CPU上表情识别耗时仅仅在0.22 ms左右,可以看出此模型在空间需求和运行速度方面比较适合移动端设备应用场景。
2 基于mini_Xception的移动端表情识别系统设计
设计的远程表情识别系统由数据采集、传输、识别终端三部分组成,系统结构如图6所示,其中识别终端是系统的核心部分,通过手机APP实现远程视频获取、人脸检测和表情识别功能,表情识别基于深度学习方法,识别模型是mini_Xception,人脸检测采用OpenCV自带的局部二值模式(local binary pattern,LBP)人脸检测器;数据采集采用海康威视公司旗下的萤石云智能摄像机,型号为CS-C2C-1A1WFR,分辨率为1 920×1 080,C2C这款型号的网络摄像机具有体积小、轻便、高清、易安装和易使用的优点;数据传输通过路由器和互联网云端来完成,传输协议为RTMP协议。

图6 系统结构图Fig.6 System structure
工作过程如图7所示。主要包括模型准备和移动端远程识别两部分:首先,将表情数据集输入 mini_Xception 网络进行训练,得到.hdf5表情识别模型文件,由于Android手机不支持.hdf5模型,所以还需要将.hdf5模型文件转换为Android手机支持的.pb模型文件,通过编写python程序即可完成模型的转换,这样生成了最终的模型文件,文件名为model.pb,此模型文件可往Android手机上进行移植;然后从萤石云官网上获取自己的萤石云摄像头的RTMP播放链接,并将vitamio库导入到Android手机中实现远程取流播放,从而实现调用远程摄像头的表情识别;最终将项目编译成APK,导入Android手机生成 APP,通过APP实现移动端表情识别。

图7 工作流程图Fig.7 Work flow diagrams
在表情数据集上,传统的表情有七种,分别是高兴、平静、生气、吃惊、恐惧、厌恶和悲伤,针对家居环境完成三类表情的识别,分别为悲伤、平静、高兴。通过对公共数据集图片的选取,以及通过 Google、Baidu、实地拍摄等方式制作了表情数据集,其中高兴图片8 989张,悲伤图片6 077张,平静图片6 198张,共包含21 264张人脸图片。其中训练集17 010张、验证集 2 155 张、测试集2 099张,数据库中的图片均为灰度图片,并将所有的人脸图像经过眼睛定位、校准、剪切,最后归一化到64×64像素。
2.1 基于Vitamio框架的远程监控视频获取
Vitamio是一种运行于Android与IOS平台上的全能多媒体开发框架,支持RTMP传输协议,采用H.264视频压缩标准,能够流畅播放720P甚至 1 080P 高清MKV、FLV、MP4、MOV、TS、RMVB等常见格式的视频,还可以在Android与IOS上跨平台支持MMS、RTSP、RTMP、HLS(m3u8)等常见的多种视频流媒体协议,包括点播与直播。Vitmaio在Android应用层上通过API接口提供了视频播放的相关类,其中videoview类负责视频的解码与播放,mediacontroller类负责视频的控制页面,包括开始、暂停、进度条等。通过VideoView类实现远程视频获取,主要工作包括设置网络URL地址、获取RTMP视频流并播放、设置控件监听,以进一步完成表情识别。关键代码如下:
private void initData() {
String path="rtmp://rtmp01open.ys7.com/openlive/09cd5738650a4da1b9b2932648857c63.hd"; //萤石RTMP播放链接
mVideoView.setVideoPath(path);
mVideoView.setMediaController(new MediaController(this));
mVideoView.setOnPreparedListener(this);
mVideoView.setOnErrorListener(this);
mVideoView.setOnCompletionListener(this);
}
实现效果如图8所示。

图8 监控视频播放Fig.8 Monitoring video playing
2.2 预处理与人脸检测
预处理是人脸检测之前对图像进行灰度化处理的过程,人脸检测是通过一定的算法判断一幅图像中是不是有人脸的出现,一旦发现,需要将人脸区域给标记出来。
2.2.1 预处理
由于移动端平台中央处理器(CPU)运算能力较弱,为了保证人脸图像中人脸大小、位置及人脸图像质量的一致性,需要在人脸检测之前对摄像头获取的图像进行预处理,这样能够降低移动设备的计算量。预处理过程主要是进行图像灰度化操作[14],主要作用把三通道的彩色图像,转化为单通道的灰度图像,将彩色图像转换为灰度图可以更加简单具体地表现出图像中的信息,主要代码如下:
MatOfRect matOfRect=new MatOfRect();
Mat mGray=new Mat();
Mat mColor=new Mat();
Utils.bitmapToMat(mBitmap, mColor);
Imgproc.cvtColor(mColor,mGray,Imgproc.COLOR_RGBA2GRAY);
2.2.2 LBP人脸检测
LBP(local binary pattern)是一种用来描述图像局部纹理特征的算子,它具有计算简单、对线性光照变化不敏感及较强的鲁棒性等特性,适用于实时人脸检测。人脸检测是表情识别最为关键一步,检测的结果对接下来的表情识别过程具有重要意义。

图9 LBP编码示意图Fig.9 LBP encoding schematic
OpenCV库中提供了基于LBP特征的级联检测器,通过detectMultiScale方法即可完成检测。下载好OpenCV4Android SDK之后,可以在它的sdk/etc目录下找到lbpcascades文件夹,里面存有lbpcascade_frontalface.xml文件,导入LBP检测器代码如下所示:
String modelName=MyUtils.copyFile(this, "lbpcascade_frota-lface.xml", "model");
cascadeClassifier=new CascadeClassifier(modelName);
初始化加载之后,就可以调用detectMultiScale方法设置好的相关参数以实现人脸检测,代码如下所示:
//人脸检测
cascadeClassifier.detectMultiScale(mGray,matOfRect, 1.1, 5, 0
,new org.opencv.core.Size(100, 100)
,new org.opencv.core.Size(1000, 1000));
看着老妈容光焕发地从学校回来,一进家门就用自以为很温柔、很有爱的眼神盯着我,尽量克制高昂情绪地说:“这学期表现不错,继续保持啊!”我就知道,她又在家长会上被“众星”捧成“月亮”了。
定义一个faces集合用于临时存储检测到的人脸图像,将人脸图像保存为Mat格式,然后将人脸图像存储为bitmap类即可完成人脸图像临时存储。基于LBP特征的人脸检测器实现的人脸检测效果如图10所示。

图10 人脸检测效果图Fig.10 The effect of face detection
2.3 模型移植与移动端表情识别
训练好的模型文件为hdf5格式,还需要将.hdf5模型文件转换为Android手机支持的.pb文件,转换完成后的模型名称为model.pb。将生成的model.pb模型文件以及label.txt标签文件放到工程的asset文件夹下,即可完成模型的移植工作,导入模型和标签文件的代码如下所示:
private static final String MODEL_FILE="file:///android_asset/model.pb";
private static final String LABEL_FILE="file:///android_asset/labels.txt";
将上面人脸检测保存的bitmap类送入classifier表情分类器中进行表情识别,把识别结果以及存到results数组中,将results结果呈现在APP的结果区域resultsView中,结果区域显示内容为每个人脸的表情的类别和置信度,主要代码如下所示:
final List
for (final Classifier.Recognition recog: results)
{
item_str+=recog.getTitle()+":"+String.format("%.3f",recog.getConfidence())+" | ";
}
resultsView.setResults(results);
3 系统实现及结果分析
按照图6构建实验系统,实现终端表情识别,并对实验结果进行分析。代码主要基于 Tensorflow 1.13、Keras 2.0深度学习框架,主要使用的编程语言为python 3.5与java;APK编译环境为 Android Studio 3.0.0,移动端测试平台为华为P10,手机CPU型号为麒麟960,运行内存为4G,搭载的Android系统为Android 9.0;PC端GPU采用的是双块NVIDIA GeForce 1080 Ti,CPU为Intel i7-i7-6700k,操作系统为Ubuntu 16. 04、Windows 10。
3.1 模型建立
在训练之前,还需要对mini_Xception神经网络进行调参,在尺寸的设定上,GPU对2的幂次可以发挥更佳的性能,因此设置成16、32、64、128等数值时往往要比设置为整10、整100的倍数时表现更优,而迭代次数(epoch)的设定也会对准确率有一定的影响,由于数据集所涵盖的图片数量比较大,故将尺寸其设置为32,迭代次数设为1 000。主要参数设置如表1所示,训练的曲线图如图11所示。

表1 网络模型部分参数设置

图11 准确率以及损失曲线图Fig.11 Accuracy and loss curve
由于设置的性能改进值为50,也就是说在50次迭代内准确率都没有改善,训练就自动停止,最终迭代120次。训练集的准确率达到了0.84,验证集准确率在0.79,模型文件名称为mini_XCEPTION.107-0.79.hdf5。
3.2 不同人脸检测器效果对比
由于OpenCV-3.3.0库中包含基于Haar-like和LBP两种特征的人脸检测器,检测器文件分别为haarcascade_frontalface_alt2.xml(快速的Haar)及lbpcascade_frontalface.xml(快速的LBP),对这两种特征的人脸检测器的检测速率进行对比,选取1 275帧含有人脸的视频进行测试,表2是两种人脸检测算法运行于Android 9.0平台的性能测试结果。

表2 人脸检测器对比
通过表2可以看出,基于LBP特征的检测器的检测速率要快,比Haar-like特征快了将近一倍,可以看出,选取的LBP人脸检测器在实时性表现较好。
3.3 不同模型表情识别结果对比
将表情分类模型与移动端常用的两种图像分类模型MobileNet、InceptionV3进行对比。对于MobileNet模型,有两个指标,分别为宽度乘数α、分辨率乘数ρ,设置这两个参数可以调整模型大小,本文设置其宽度乘数α=0.25,分辨率乘数ρ=128和225,宽度乘数α越小,MobileNet模型就越小。
对比结果如表3所示。可以看出,本文模型仅有0.25 MB,比InceptionV3和MobileNet训练的模型都要小;同时,本文模型的验证集准确率达到了0.79,比MobileNet和InceptionV3两种模型的准确率要高。
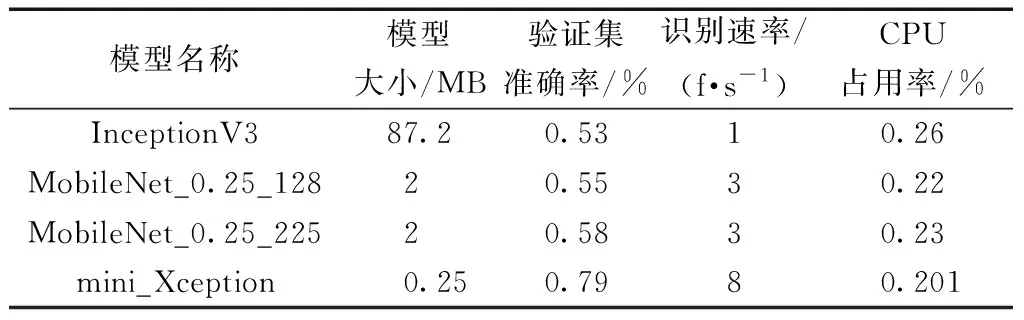
表3 模型性能对比
将三个模型分别移植到Android手机上进行识别速率以及CPU占用率对比测试,从表3中可以看出,mini_Xception网络的识别速率达到了8 f·s-1,比InceptionV3模型和MobileNet模型实时性要好一些。mini_Xception模型CPU占用率也比InceptionV3和MobileNet低,在Android手机上运行不会影响手机的流畅性。
3.4 不同距离与光照条件识别测试
首先打开萤石云官方的APP对摄像机进行WiFi配置,搭建测试环境的网络带宽为20 MB/s,待配置成功后,萤石云摄像机会提示WiFi连接成功;接下来将本工程打包成APK安装到手机上即可运行。
为了综合测试设计的移动端远程表情识别系统,分别对视频采集中光照和距离条件变化进行了实验。测试采用的视频流为1 280×720格式的高清视频,测试结果如表4、图12、图13所示,其中,图12与图13左右两列为不同光照与距离获取的图像帧,从表4中可以看出高兴的准确率为85%,悲伤的准确率为63%,平静的准确率为96%,三种表情的平均正确率为81%。
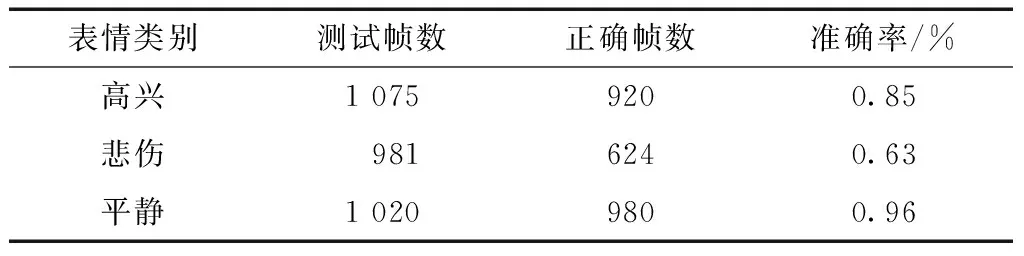
表4 表情识别准确率

图12 不同光照下效果Fig.12 Recognition effects under different lighting conditions
从图12的结果可以看出,系统表情识别的功能不会受光照的影响,因为萤石云摄像机自带夜视功能,可以看出对光照的鲁棒性较强。从图13可以看出,若视频流格式为1 280×720高清格式,在离摄像机2 m以内的距离下表情识别不会受到影响,人脸距离摄像头若超过2 m,则会受到影响;若视频流为640×480标清格式,人脸距离摄像头0.3 m之内才不会受到影响,超过0.3 m识别结果会受到影响。所以本系统在家庭环境下部署时,选择高清视频格式,且尽量将摄像机选择部署在客厅的影视墙,或者卧室床头正对的墙壁上,在这些地方是家人出现较多的地方,能更大程度地捕获到人脸图像,进而识别家人的表情。

图13 不同距离效果Fig.13 Recognition effects under different distance
4 结论
针对通过手机实现远程表情识别问题,设计并实现了一种基于深度学习的移动端远程表情识别系统。系统先导入Vitmaio框架实现远程视频流播放,再将LBP检测算法导入到Android手机之中实现人脸检测,最后将mini_Xception训练好的模型移植到Android手机之中实现表情识别,并在Android平台中进行了实验和测试数据对比,得出以下结论。
(1)系统表情识别的准确率达到81%,识别速率达到了8 f·s-1,基本满足家居环境的要求。
(2)系统利用 Android手机以及网络摄像机实现,成本低且便携性高,将其运用在家庭环境中来识别家人的表情,具有很大的实用价值。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
动漫星空(2018年9期)2018-10-26
