
基于伪度量的案例推理改进算法
2020-10-28 01:44余肖生任明霞
计算机技术与发展 2020年10期
余肖生,宋 锦,任明霞,陈 鹏
(三峡大学 计算机与信息学院,湖北 宜昌 443002)
0 引 言
案例推理是指从案例库中检索与新案例相似的案例,然后重用相似案例的方法,若不能匹配则将新案例修正并保存到案例库中。一般采用四步骤,即:案例表示,案例检索,案例重用,案例修正和保存[1]。其中最关键的部分是负责检索提取的案例检索阶段、归纳推理新案例分类的案例重用阶段。
案例推理算法近年来已在医疗、法律、金融、工业等领域都有应用。它是一种比较重要的推理方法,该方法模拟了人类的思维方式,它的一般优点是:案例表示简单,不需要人工设计复杂的规则;求解过程方便,不需要根据规则推理;求解的结果方便用户接受。
在案例推理领域,案例之间相似度的衡量非常关键。其通常采用距离度量和伪度量等。在距离度量方面,有些学者采用欧氏距离、曼哈顿距离、改进的欧氏距离等度量案例之间的相似度,但是这需要案例的各个特征属性之间相互独立。另一些学者则引入差异空间的概念,提出差异关系和案例推理相结合的方法,通过差异指数集成完成案例之间的相似性度量[2-5]。但这样预先设定的度量会导致相似的案例并不能总是反映在预设计的度量空间上。在伪度量方面,有学者研究了案例推理中的度量空间[6],另有学者提出了在相似性度量时使用伪度量空间[7],将其与案例推理领域常用的欧氏距离作比较,并通过实验验证了伪度量应用于相似性时在稳定性和鲁棒性方面优于其他算法。基于伪度量的案例推理算法在处理工业上的故障分类也取得了较好的效果[8-9],但是该算法需要较长的训练时间。该文提出的算法在案例检索阶段采用伪度量作为度量函数,在案例重用阶段采用新的公式判断目标案例的分类,取代以往的聚类做法,与BP神经网络、案例推理、SVM等算法相比,在测试数据上平均提高准确率2%。与文献[9]基于伪度量的案例推理算法对比节省了聚类需要大量预训练数据的时间,并提升了案例推理算法在不平衡数据上的表现。
1 案例推理的相关基础
1.1 案例检索
案例推理算法的关键是尽可能地检索出与目标案例相近的案例,所以度量案例之间的相似度非常关键[10],而衡量两个案例之间的相似度一般采用欧氏距离作为相似度测量方法[11],但是这样可能会将每个属性特征的作用平均化,很容易带来“距离陷阱”的问题,即距离数值最接近的案例却并不是最相似的,所以需要采用一些新的方法来解决这个问题。其他的相似度度量方法还有余弦相似度、皮尔森相关系数等方法[12]。
采用伪度量的方法是直接设定案例之间的距离关系,再由神经网络拟合伪度量空间,作为相似度检索的依据。根据案例数据集构建具体的度量空间,避免了欧氏距离等需要分配各特征属性分配权重和“距离陷阱问题”。
1.2 案例重用
所谓案例重用即将旧案例中解决问题的方法应用于新案例。案例重用阶段同时优化度量设计,如:采用基于二进制灰狼算法确定分类[13];基于遗传算法和粒子群优化算法,并根据设置的权值计算相似度重用分类[14];在以往基于伪度量的案例算法中,采用基于聚类的重用方法聚类并输出分类。文献[9]伪度量的案例推理算法中,在案例重用阶段采用聚类方法。但是聚类需要预先匹配大量数据,需要进一步研究优化。
2 基于伪度量的案例推理算法
在案例推理算法发展过程中,不断有研究尝试改进案例检索和重用阶段。文献[9]的研究认为:案例推理过程中,度量难以设计,权重难以分配,所以尝试使用神经网络来拟合案例之间的度量空间。该算法设计首先从案例库中选取大量案例,构建一个具有案例和度量关系的匹配池,然后使用神经网络模型学习拟合这个匹配池的度量空间,并输出目标案例与案例库案例的度量距离,最后通过聚类方法得出目标案例的最终分类。
该研究主要是从设计上引入了拟合度量空间的思路,取得了一定程度的优化效果,但在案例匹配的基础上仍采用聚类算法,导致了需要重复匹配数据问题,仍有优化的空间。
为进一步提升算法准确率,解决重复匹配数据等问题,该文采用新的方法取代案例重用阶段的聚类方法。设计提出新的案例推理算法(简称LPM-CBR-K),如图1所示。首先从案例库中将数据划分为训练集和测试集,在案例库测试集内按伪度量关系构建匹配池,采用BP神经网络拟合案例之间的度量关系,案例重用阶段依据公式根据上一阶段的预测关系输出目标案例的最终分类。

图1 算法流程
具体步骤如下:
2.1 案例表示
(1)将历史案例库中的数据表达为二元组的形式:
Ck=(Xk;Yk),k=1,2,…,p
(1)
其中,p是案例总数,Xk是第k个案例的描述,Yk是第k个案例的所属分类,其中Xk的描述可表示为:
Xk=(x1k,x2k,…,xik,…,xnk)
(2)
其中,xik为第k个案例第i个属性的值,n为案例库的属性值数量。
(2)数据划分:将数据依据比例划分,比如10%作为测试集,90%作为训练集。在数据预处理阶段,即依据案例构建的匹配池数据输入到神经网络前,该文选择了数据标准化的方法。标准化的方法适合将数据处理为无量纲的形式,在使用距离度量的算法中经常被使用,即
(3)
2.2 案例检索
LPM-CBR-K算法则首先设置一个度量空间[15-16],即伪度量。对于集合X中任意元素x,y,若实值函数{d:(X,X)→R}符合以下三个条件,称它为一个伪度量。
(1)d(x,x)=0;
(2)d(x,y)=d(y,x);
(3)d(x,z)≤d(x,y)+d(y,z)。
它的特点是允许相异的元素之间的度量d(x,y)=0。即在伪度量空间中,虽然两个案例之间的距离为0,并非同一个案例,但是这意味着同属一类,所以在后面的设计中,笔者将同类案例之间的度量距离设置为0,异类案例之间的度量距离设置为1。
定理1:给定集合R和分类案例{[aj],j=1,2,…,n},有
(4)
则函数d为集合R上的一个伪度量。
根据分类,同类案例距离为0,异类案例距离为1,构建一个基于案例库的匹配池。
例如:构建
F(k)={X,Y;d(X,Y)}
(5)
其中,F(k)为两个数据之间的度量距离,X,Y为两个案例,d(X,Y)为X和Y的度量关系,即当X和Y的分类相同时d(X,Y)为0,否则为1。通过此方法对案例库中的数据逐条构建成匹配池。
2.3 案例重用
基于案例库的匹配池建成后,基于案例的伪度量空间同时被建立。通过神经网络等技术去拟合案例的伪度量函数f,训练完成的神经网络就是一个可以输出两个案例之间伪度量距离的函数,对新输入的案例就可以根据函数求得其与任一案例之间的相似度[17]。
在理论上,神经网络等技术可以拟合任意函数,如BP神经网络,通过对x和f(x)学习,完成训练之后,对于任意输入x,神经网络都能输出f(x),或接近f(x)的预测值。同样,在设置完伪度量空间并通过神经网络的训练之后,对新输入的目标数据也能近似地输出其与案例库案例之间的度量距离,即预测新输入案例的分类情况。
由于神经网络的特点,神经网络在预测输出已知案例和目标案例之间的距离时,一般并不会直接输出0或者1,而是由激活函数决定输出的值。如Sigmod函数将输出约束到区间[0,1]。
文献[9]的LPM-CBR算法是对神经网络输出的分类,先定值化为0或1,再进行聚类操作,根据聚类的结果预测分类,而LPM-CBR-K算法在这一步,并不立即根据阈值得出目标案例和案例库中每个案例的具体确定判别,过早的确定值会带来信息损失,而是将求得的关系值加入后续的运算中。
在文本处理等领域,除去正常的判断逻辑之外,利用否定词或否定关系判断也是常用的方法。尤其在情感分析、评论挖掘等领域,鉴别否定词是非常关键的。类似的,在案例推理领域判断新案例X的分类时,既可以通过判断与案例X最相似的案例集合,由这个集合推断出案例X的分类,同样的,也可以计算与案例X最不相似的案例集合,同样由这个集合也能推断出案例X最不可能的分类,如果只存在二元分类,则此时得出案例X的最不可能分类,也就得案例X最可能的分类。
类似的,计算案例最相似的或最不相似的案例都能得出新案例的分类,所以该文提出一个公式,综合最相似和最不相似的案例统一考量。已知x1,x2,…,xi,…,xn的分类为0或1,xi为任意一个案例,Sim(i)为xi和目标案例xp之间的度量距离预测。则对于目标案例xp遍历案例x1至xn,分别计算与每个案例的相似度Sim(i),根据既定公式计算匹配数据的度量关系并记录,k为训练数据中距离0和距离1的比例,则目标案例的最终分类f输出为:
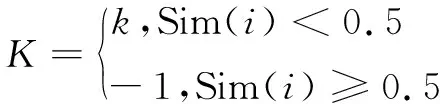
(6)
最终以0作为阈值,目标案例的最终分类P为:

(7)
通过公式获得目标案例的分类。算法综合考虑案例之间的相似度和度量距离的不平衡性,根据函数返回的值输出目标案例的最终预测分类。这样就避免了以往的算法中需要大量的预训练生成数据的过程,该算法只需训练一次训练集即可。同时,传统的算法中需要先将目标案例与案例库中案例的相似度Sim(i)取定值,然后做聚类计算,造成了一定程度的信息损失,而通过该方法可以得到解决。
2.4 案例修正和保存
对用户满意的案例,将其保存到案例库中。若判决结果并未给出合适的解,则将案例作为新的案例源保存到案例库中。
3 实 验
3.1 实验数据
实验数据选择UCI的8类数据集合,如表1所示。其中,Blogger是关于网络日志的分类数据,Breast Cancer Wisconsin (Diagnostic)是关于良性恶性乳腺癌判断的数据集,Acute Inflammations (nephritis)是对泌尿系统的两种疾病进行推定诊断,Fertility是精液质量的数据集,Ionosphere是关于雷达信号的分类,Parkinsons是关于帕金森疾病的检测数据,Planning Relax是关于脑电波的分类数据,EEG Eye State是关于眼部状态的检测数据,Pima Indians Diabetess是关于糖尿病的数据。

表1 实验数据集
3.2 实验方法及评价指标
为了验证提出的案例推理算法改进的有效性,在每一个数据集上都分别采用传统的基于KNN的案例推理算法,BP神经网络,LPM-CBR算法与提出的LPM-CBR-K算法进行对比。算法的验证基于Python语言编写,使用了Sklearn和Keras框架。Sklearn是一个基于Python语言的数据挖掘和机器学习的集成库,包含了大部分的传统机器学习方法,它的功能包括分类、回归、聚类等,因此实验的支持向量机算法和基于近邻的案例推理算法采用Sklearn框架编写。Keras是一个基于Tensorflow和Theano的封装的框架,具有高度模块化,容易上手的特点,文中算法中神经网络部分基于Keras框架编写完成。
在实验中,选择90%的数据作为训练集,剩余10%作为测试集,每轮算法运行10次,以平均值作为最终值。
实验中,在SVM的参数设定中:C设置为1,kernel设置为rbf,gamma设定为auto。在基于KNN的案例推理中:聚类数量设置为5。在BP神经网络中:层数设定为3层,隐藏层节点设置为10个,激活函数选择sigmod,epochs设置为1 200,batch_size设置为128,在LPM-CBR和提出的算法中:90%的数据构建训练库,10%的数据构建待测试库。在训练集中再划分为训练集和测试集,分别构建一个训练池和一个待测试的测试池。在神经网络部分,层数设定为3层,隐藏节点设置为10个,epochs设置为1 200,batch_size设置为128。
3.3 实验结果及分析
3.3.1 算法准确率
对实验的数据集依次测试并记录实验结果,各算法的准确率如表2所示。

表2 算法准确率对比
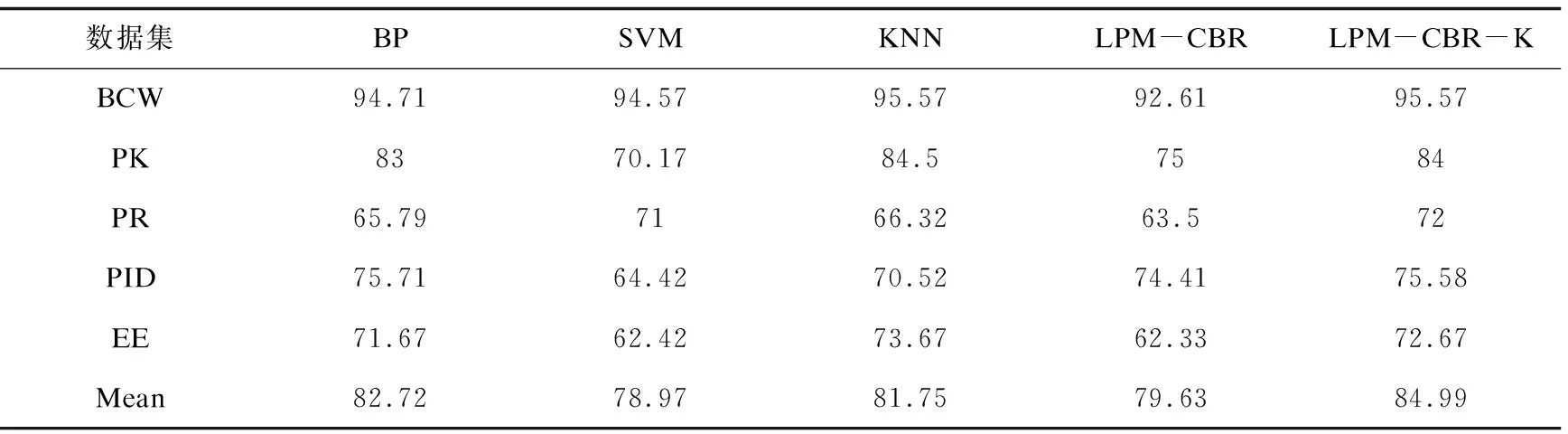
续表2
从表2可以看出:LPM-CBR-K算法在大部分数据上的准确率较好,在IO数据集上比其他算法至少高1.81%,在FE数据集上比其他数据集高1%,在BL数据集上比其他算法高3%,在PR数据集上比其他算法高1%,即使是在PK、EE和PID数据中,该算法也和最高值差距较小。
不难看出,LPM-CBR-K算法在准确率上有一定提升,在所有的数据集上的准确率平均提升至少2%,因为LPM-CBR算法在定值化神经网络的输出和聚类阶段会损失一定的信息。公式(6)、(7)步骤减少了先取值再聚类的操作,没有在运算中间将神经网络的输出数据分类,因此减少了信息的损失,直至最终的输出预测步骤才定值化信息,因此提升了算法的准确率。
3.3.2 算法运行时间
在对比实验中,依次运行参照对比的LPM-CBR算法和提出的LPM-CBR-K算法,除去数据较多的PID和BWC数据(LPM-CBR算法在一般条件下会少量配对,在PID和BWC等数据较多情况下需要设置合适匹配次数),数据的运行时间对比如图2所示。
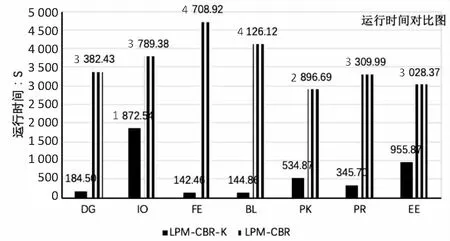
图2 实验数据的运行时间
由图2知,在DG、BL等数据集上,由于数据较少,以往的算法需要抽样提升准确率,而提出的算法极大地节省了时间。在IO、FE等数据较多的数据集上,该算法在不损失信息的情况下,也节省了一定的时间,所以LPM-CBR-K算法显著降低了运行时间。在数据不足的情况下或者数据不均衡的条件下,LPM-CBR算法需要随机选取1 000~20 000条数据生成匹配池。而LPM-CBR-K算法步骤则只需要一次构建,所以省却了大量的抽样的时间,而LPM-CBR算法即使是耗时最小的1 000对数据训练所花的时间也远比提出的算法花费的时间多。改进的案例检索流程上设计为LPM-CBR-K算法运行节省了时间。
3.3.3 不均衡数据
LPM-CBR-K算法在准确率上表现较优,但是在正负样本不平衡的二分类数据中,准确率单一指标参考作用并不大,还需要综合考虑查全率和查准率。一般有较多的衡量指标,实验采用F1指标衡量算法在不均衡数据上的性能,F1是对精度和召回率的调和平均。以数据较多的PID数据为例,将PID的数据数量设置为300,分别用不同比例的正负样本测试。图3展示了在PID数据正负数据样本比例从1∶4到4∶1时的案例推理的判决结果。
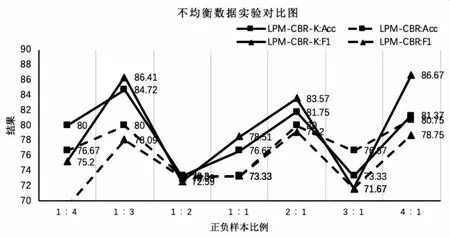
图3 不均衡数据对比
可以看出在不同的正负样本案例测试时,LPM-CBR-K算法的准确率在以往算法之上,正负样本数量差距较大时表现较以往算法更好。正负样本均衡时,LPM-CBR-K的算法F1值略高于传统算法,在正负案例数量差距较大时仍表现较好。综合起来LPM-CBR-K算法的准确率和F1值都要高于文献[9]的算法,提出的算法在数据不均衡的情况下效果更好。
案例推理算法的原理是利用相似的案例判决,因此数据中正负案例的数量会影响判决的结果。为了解决数据不平衡的问题,一种方法是在数据层面进行改进,即通过少量采样过采样或者大量样本欠采样,文献[9]的算法采用了混合采样的方法,自然带来了数据规模的增大,不仅导致神经训练训练的时间增长,也可能导致模型过拟合,泛化能力下降。另一种方法则是直接在算法层面进行改进,比如随机森林或集成学习的方法,通过抽样逐步拟合残差或加权方式解决问题。提出的算法就尝试了在算法层面进行改进,放弃因为聚类部分需随机抽取数据导致的部分信息的损失,通过提出神经网络的数据匹配和处理判决阶段的公式(6)和公式(7)来解决数据不平衡的问题。
4 结束语
案例推理算法作为机器学习领域常见的算法,不断地有针对其案例检索和案例重用阶段的研究和优化。提出的LPM-CBR-K算法,在案例检索阶段选取了伪度量的方法,在设计上选择了利用神经网络去拟合案例之间伪度量空间,取代以往的预先设值度量方法;在案例重用阶段,提出公式(6)和公式(7)取代以往的重用阶段的聚类方法,解决算法在检索步骤匹配大量数据的耗时问题,并有效地避免了信息的损失,减少了随机抽取数据的步骤,并尝试解决数据不平衡时的解决方法。最后通过实验证明了LPM-CBR-K算法在精度上的提高,在时间上的优化,在一定程度上推进了案例推理算法在不平衡样本上的表现。
猜你喜欢
宁夏大学学报(自然科学版)(2022年2期)2022-07-19
上海文化(文化研究)(2022年3期)2022-06-28
宁夏大学学报(自然科学版)(2022年1期)2022-04-30
水上消防(2021年4期)2021-11-05
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
作文与考试·初中版(2019年15期)2019-04-28
江西教育B(2019年2期)2019-04-12
