
MEC硬件加速技术分析
2020-10-27 09:46陈云斌王全陆威
移动通信 2020年8期
陈云斌 王全 陆威

【摘 要】
为了解决边缘机房的供电、散热以及承重能力有限,无法为MEC提供足够的计算资源的问题,分析了MEC在第三方应用,OVS和虚拟化用户面的性能瓶颈,提供硬件加速的方法。研究表明,通过上述方法,可突破MEC的性能和时延瓶颈,实现高性能、低时延,并兼顾性能、成本和开放性。
【关键词】5G;MEC;硬件加速;UPF;FPGA
[Abstract]
To solve the problems of power supply, cooling, and limited load-bearing capability in the edge DCs, which cannot provide sufficient computing resources for the MEC, the performance bottlenecks of MEC in third-party applications, OVS, and virtualized user planes are analyzed to provide hardware acceleration methods. Research shows that the above methods can break the bottlenecks of the MEC performance and latency, achieve ultra-high performance and ultra-low latency, and balance the performance, cost, and openness.
[Key words]5G; MEC; hardware acceleration; UPF; FPGA
0 引言
5G时代,数字化和智能化对终端的算力需求迅速增加。而终端受功耗、成本和空间的限制,需要将算力向云端移动。云端的算力不能满足实时性要求高的业务的需求,为了降低时延,又使业务向边缘移动。如图1所示,MEC(Multi-Access Edge Computing)技术的应用使边缘云成为数字化和智能化时代的算力洼地,业务和算力汇聚在边缘云。MEC定位在网络边缘,可以有效降低终端成本,减少传输带宽占用,降低业务时延,提高业务数据安全性。
MEC让包括虚拟化用户面和第三方应用在内的算力需求汇聚在边缘,极大地增加了MEC边缘云的计算开销。然而,边缘机房的供电成本高、散热以及承重能力有限,进行DC化改造余地小、成本大,无法提供足够的X86计算资源。因此,提升边缘机房的单位面积算力成为关键。
NFV (Network Functions Virtualization)采用基于X86等通用硬件的虚拟化技术,实现网络功能软硬件解耦,使网络设备功能不再依赖于专用硬件。然而,NFV刚从专用硬件转向通用硬件,却发现以X86服务器为主的通用硬件并不能满足MEC业务的网络性能要求[3]。这主要有两个原因:
一是X86通用处理器CPU为了保证通用性,却丧失了专用性,即并不擅长特定任务的处理。比如,不擅长处理编解码转换、报文转发、加解密等并行处理的任务。
二是CPU性能已经无法按照摩尔定律进行增长,而电信业务特性对计算性能要求超过了按“摩尔定律”增长的速度。
NFV架构基于通用硬件,在数据转发效率与数据并行处理方面存在不足,为提升边缘机房的单位面积算力,在MEC引入硬件加速技术是最佳的选择。
1 MEC加速需求
按照欧洲技术标准委员会ETSI的定义,MEC[2] 指在包含一种或者多种接入技术的接入网络中,靠近用户的网络边缘,提供无线网络能力、云计算能力和IT业务环境的系统[1]。在5G网络中,用户面UPF(User Plane Function)是5G网络和MEC的结合点。通过UPF本地分流,打破传统封闭的电信网络架构,将边缘网络基础设施和硬件加速能力,边缘网络分流能力和无线网络感知能力开放给第三方应用,激活边缘价值。
MEC加速需求主要包括下面三种场景:
(1)MEC应用层加速。MEC的本质是ICT融合。MEC在网络边缘,贴近用戶就近提供算力,需要满足AR/VR、视频直播等业务对视频渲染、转码的加速,以及AI训练、推理的加速需求。这类计算密集型的MEC应用对CPU消耗极大,必须在边缘引入加速硬件。
(2)NFVI(Network Functions Virtualization Infrastructure)层OVS加速。MEC应用对基础设施性的低时延、高速率转发性能指标提出了更高的要求。仅靠软件实现上行10G,下行20G的速率非常困难,采用软加速(DPDK)方案在转发能力上依然不足。电信网络的本质是转发网络,转发处理能力的提升关键在缓存,数据并行处理能力的提升关键在核数。但是,摩尔定律失效,CPU的缓存和核数的提升缓慢。因此,需要引入加速硬件来突破NFVI层的转发性能和时延的瓶颈。
(3)VNF(Virtualized Network Function)层虚拟化用户面加速。虚拟化用户面UPF下沉到MEC,提供本地分流,实现一跳直达,降低传输时延,减少带宽占用。虚拟化用户面实现软硬件解耦,但是相对传统专用硬件而言,性能有所下降。对于工业控制、自动驾驶等超低时延MEC业务,基于X86服务器的纯软件用户面不满足其性能需求,也需要引入加速硬件。
在MEC边缘云,重点将上述三种消耗CPU资源高的业务卸载到加速硬件上,不但可以提升边缘业务体验,还可以节省边缘宝贵的CPU资源,大幅降低边缘机房的功耗。
2 MEC加速硬件的选择
常见的加速硬件包括FPGA、GPU、NP和ASIC等。根据MEC主要的三种场景的加速需求,建议采用FPGA和GPU进行硬件加速。
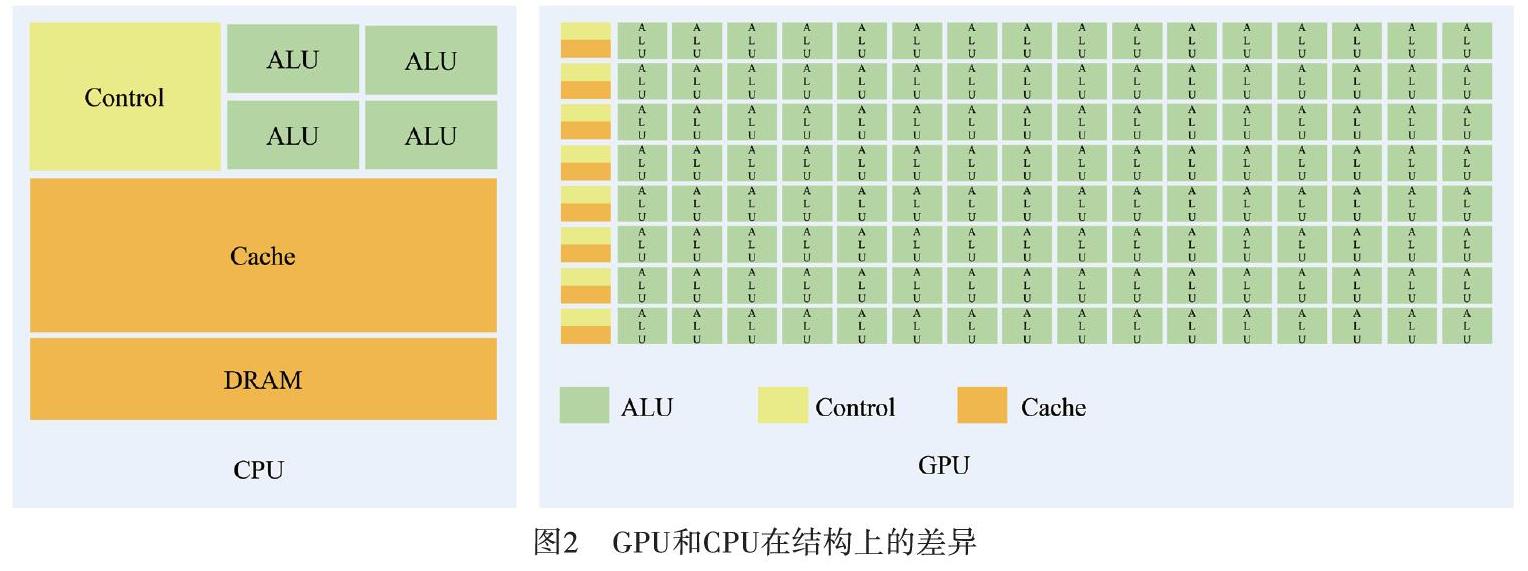
CPU要做得很通用,就要同时很好地支持并行和串行操作,能够处理各种不同的数据类型,同时又要支持复杂通用的逻辑判断,这样会引入大量的分支跳转和中断。这就让CPU的内部结构变得异常复杂,导致计算单元的比重被降低。而GPU面对的则是类型高度统一、相互无依赖的大规模的数据,而且是不会被打断的纯净的计算环境。因此,GPU芯片比CPU芯片简单很多。由于GPU具有高并行结构,所以GPU在处理图形数据和复杂算法方面拥有比CPU更高的效率。
图2展示了GPU和CPU在结构上的差异。CPU大部分面积为控制器和寄存器,而GPU拥有更多的ALU(Arithmetic Logic Unit,逻辑运算单元)用于数据处理。GPU这样的结构适合对密集型数据进行并行处理。GPU适合做大批量的同构数据的处理,视频渲染和AI加速这类MEC应用适合采用GPU加速硬件。
CPU、GPU都属于冯·诺依曼结构,指令译码执行,并共享内存。而FPGA采用无指令、无需共享内存的体系结构。FPGA的每个逻辑单元的功能在重编程时就已经确定,不需要指令。FPGA中的寄存器和内存(BRAM)是属于各自的控制逻辑,无需仲裁和缓存。FPGA的每个逻辑单元与周围逻辑单元的连接在重编程(烧写)时就已经确定,不需要通过共享内存来通信。因此,FPGA具备极低的延迟优势,适用于流式的计算密集型任务和通信密集型任务。因此,MEC的NFVI 层OVS(OpenVSwitch)加速和虚拟化用户面加速适合采用FPGA加速硬件。
3 MEC基于FPGA智能网卡加速方案
3.1 NFVI层OVS加速
传统软件交换技术会消耗大量的CPU资源,在性能和性价比上无法满足MEC业务需求。在MEC采用硬件加速技术,通过硬件逻辑编程,把OVS中需要占用大量CPU资源的数据面功能卸载到基于FPGA的智能网卡上实现;卸载之后释放出来的CPU资源可以用于部署更多的MEC第三方业务。
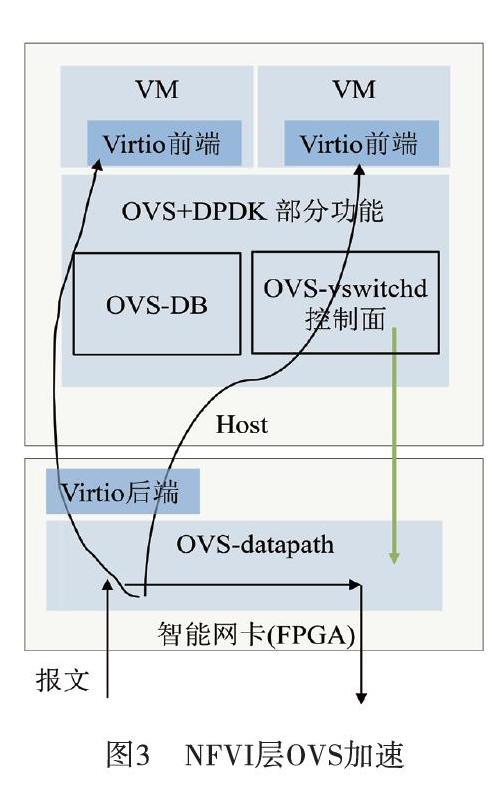
基于FPGA的智能网卡的OVS加速方案如图3所示。
OVS-vswitchd作為控制平面,接收来自SDN控制器的流表配置消息(或者命令行的控制命令),将流表项写入数据库,并更新到OVS-datapath。OVS-datapath由一系列哈希表组成。报文进入OVS-datapath查表,命中后加上出向端口号,直接执行转发。未命中的报文送到OVS-vswitchd,通过IP或MAC学习到出向端口号,并转发出去;同时,将学习到的流表(入向端口、出向端口)下发到OVS-datapath,并更新OVS-datapath 哈希表。下次,相同流表的报文进入后,直接经OVS-datapath转发。
OVS-datapath下沉到基于FPGA的智能网卡实现,原OVS-datapath则由一个简单的根据端口转发模块替代。OVS-datapath数据通道下沉到智能网卡,可以节省超过2核的CPU;OVS-vswitchd控制面仍由CPU完成,与MEC业务共用2核CPU。
基于FPGA的智能网卡测试性能对比如表1所示:
基于FPGA的智能网卡具有如下优势:
(1)高性能。基于FPGA的智能网卡实现DPDK内存拷贝和流表查询。在百万流表的条件下,512字节报文具有40G/100G线速转发能力。
(2)低时延。软件OVS需要数十微秒至上百微秒,而智能网卡仅数微秒,具有更低时延的转发能力。而且,智能网卡具备微秒级的超低延迟流表生效时间。
(3)低成本。实现OVS转发面的CPU完全卸载,仅控制面和MEC业务共用2核CPU;VirtIO后端功能下沉,还可减少2核CPU的消耗。
3.2 VNF层虚拟化用户面加速
为了满足AR/VR、工业控制、无人驾驶等新业务带来的高带宽、低时延的网络需求,基于虚拟化技术的5G网元将控制面和转发面分离,进行分层部署;控制面集中部署,用户面则贴近用户、分散部署,实现管理成本和用户体验的平衡。将用户面UPF下沉到MEC边缘云,可以缩短转发路径,降低传输时延,并在一定程度上提升了数据转发效率[6]。但是,基于X86服务器部署的虚拟化用户面UPF,性能上无法媲美专用硬件,而且需要消耗大量的CPU资源。采用基于FPGA的智能网卡,可以大幅提升MEC虚拟化用户面转发效率。
虚拟化用户面UPF加速主要是将GTP(GPRS隧道协议)业务卸载,包括:
(1)Tunnel Offload:GTP报文的封装和解包。
(2)Service Offload:报文不经过主机处理以look-inside方式直接转发出去,减少主机计算资源消耗。
GTP业务卸载原理如图4:
基于FPGA智能网卡加速虚拟化用户面UPF,在软件VNF(Virtualized Network Function)层进行数据报文的首包学习,生成转发流表,并将流表下发到智能网卡中。同一条流的后续数据报文将由智能网卡接收、解包、处理后直接转发,降低节点内转发处理层次,大幅减轻CPU计算、内存读取、PCIe总线的瓶颈,提升单服务器性能密度[5]。图5是基于FPGA的智能网卡加速的虚拟化用户面UPF的示意图。
虚拟化用户面流量卸载的性能与实际的业务模型有着极大的关系,单条流的包个数越多,卸载转发的效率越高。基于此方案,视频数据的转发效率就非常高, 具有更高的性能功耗比和性价比。通过测试证明,基于FPGA的智能网卡加速的虚拟化用户面,突破了当前虚拟化转发的性能和时延瓶颈,单服务器(双网卡)吞吐量提升至3倍(180 Gb/s),时延降低90%(低于10 ?s),功耗降低55%。
4 问题与展望
在MEC引入加速硬件,进一步提升性能、优化能效和节省成本,这已在业界形成了共识。然而,据不同业务场景和自身优势,通讯厂商引入GPU、FPGA等硬件进行加速,推出了各种加速硬件方案。加速硬件的逻辑与软件层面的加速逻辑强相关,存在功能专一、接口不统一等问题,造成软硬件无法解耦。异构加速硬件要运行在各种云操作系统上,再被上层厂家的VNF调用,如果没有一个统一的标准来管理这些加速硬件,没有统一的接口来让上层网元来调用,将会造成比较严重的问题。
在加速硬件解耦方面(如图6),当前处在加速硬件与服务器可解耦阶段,加速硬件可以资源池化。后续,加速硬件主要有两个解耦方向,包括软硬解耦和软软解耦。
(1)软硬解耦,即标准化硬件加速卡方案。硬件厂商仅提供可编程硬件加速卡,通讯厂商提供全部VNF软件功能(包括加速卡镜像)。需要在VNF软件与硬件加速卡驱动之间制定标准API接口。这种方案实现加速卡与加速功能的解耦,VNF软件与加速功能尚无法解耦[4]。
(2)软软解耦,即用网元功能专用加速卡方案。专用加速卡厂商提供加速硬件及VNF加速能力。通讯厂商通过标准软件接口与专用加速卡对接,通过调用专用加速卡的VNF加速能力来提供完整的VNF功能。这种方案实现VNF软件与硬件加速卡之间解耦,但难点在于繁多的API接口需要标准化[4]。
为了实现NFV异构加速硬件的统一管理,ETSI制定了NFV加速硬件统一管理的软件框架标准。开源社区OpenStack孵化出了Cyborg项目,旨在提供通用的硬件加速管理框架[3]。Cyborg主要面向基礎设施中对加速硬件的驱动集成和VIM对加速硬件的感知。基于Cyborg的加速管理包括:
(1)加速卡驱动管理。Cyborg管理各种加速器的驱动程序,维护加速卡硬件类型/版本与驱动程序的依赖关系。
(2)加速卡资源,能力管理。Cyborg管理本资源池中的所有加速卡的类别、数量、能力和容量等,并通过北向API通报给Mano等(Management and Orchestration)资源编排中心。
(3)加速卡生命周期管理。Cyborg通过与Nova接口,完成虚拟机生命周期中的加速卡生命周期管理。
(4)加速卡业务接口管理。目前主要是直通方式,使用函数接口;常见的SR-IOV模式,也是使用函数接口;如果加速卡支持完全虚拟化,则会采用VirtIO接口,此时,Cyborg组件需要提供VirtIO前端的统一接口以及VirtIO后端与驱动接口适配。
5 结束语
随着相关标准组织和开源社区的推进,加速硬件接口和管理将逐渐标准化,在MEC边缘引入硬件加速技术,可以有效突破MEC的性能和时延瓶颈,实现超高性能、超低时延,并兼顾性能、成本和开放性。
参考文献:
[1] ETSI. ETSI GS MEC 003 V2.1.1: Multi-access edge computing (MEC); framework and reference architecture[S]. 2019.
[2] ETSI. ETSI GS MEC 001 V2.1.1: Multi-access Edge Computing (MEC); Terminology[S]. 2019.
[3] 刘小华. NFV应用中的硬件加速,提升媒体面处理性能[J]. 中兴通讯技术, 2019(5): 33-35.
[4] 王文黎,王友详,唐雄燕,等. 5G核心网UPF硬件加速技术[J]. 移动通信, 2020,44(1): 19-23.
[5] 陆威,方琰威,陈亚权. URLLC 超低时延解决方案和关键技术[J]. 移动通信, 2020,44(2): 8-14.
[6] 朱堃. 面向5G边缘计算[J]. 中兴通讯技术, 2019(9): 19-20.
猜你喜欢
工业经济论坛(2020年6期)2020-04-13
电子制作(2019年10期)2019-06-17
电子制作(2019年23期)2019-02-23
汽车观察(2018年12期)2018-12-26
测控技术(2018年6期)2018-11-25
汽车观察(2018年10期)2018-11-06
电子制作(2018年14期)2018-08-21
电子测试(2017年11期)2017-12-15
系统工程与电子技术(2016年7期)2016-08-21
电测与仪表(2016年17期)2016-04-11
