
大数据技术在LKJ 设备分析系统中的应用研究
2020-10-27 03:19:34杨献,言圣
控制与信息技术 2020年4期
杨 献,言 圣
(湖南中车时代通信信号有限公司,湖南 长沙 410100)
0 引言
列车运行控制装置(LKJ)为铁路行车安全保障设备。虽然其记录了丰富的列车运行数据,同时设备的监测、生产、返修、故障记录数据都有相应的系统进行管理,但目前仍存在以下问题:现场LKJ 设备文件分析不全面且分析效率低,致使故障查找定位难;设备维护管理采用定期修和故障修两种模式,设备故障易导致事故,且设备故障修影响列车运行效率;既有设备质量分析、生产管理、LKJ 设备运行监测管理(LMD)等系统的数据独立,未关联融合,综合数据的价值有待发掘。
大数据技术随着第四次产业革命而发展,在产、供、销、创新等环节发挥了重要作用[1],推动企业向精益生产和服务型制造业的快速转型升级;工业大数据和人工智能技术的出现正是着眼于产品全生命周期内服务能力的提升,以全面提升产品和服务品质,实现降本增效,提高企业的核心竞争力。如何利用大数据技术实现LKJ设备的智能分析,提升产品可靠性,提高维修效率,降低维护成本,是当前亟待解决的问题。为此,本文通过研究分析大数据关键技术,提出一种基于大数据技术的LKJ 设备分析系统方案及其功能实现方法,并进行了实验验证。
1 大数据关键技术
大数据技术是信息化社会的代表技术之一,其应用范围广泛[2]。根据大数据的信息处理流程,基于大数据技术的LKJ 设备分析系统信息处理流程可分为数据采集、处理、存储、挖掘分析和结果展示5 部分(图1),其中数据采集、处理和挖掘分析是关键技术。下面主要介绍数据处理和挖掘分析技术。
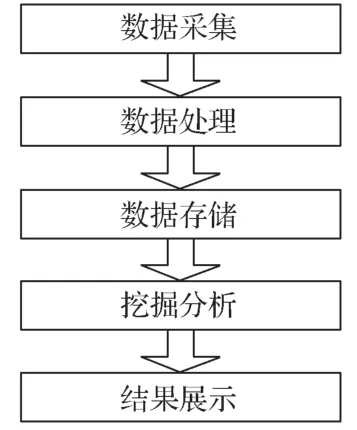
图1 信息处理流程Fig. 1 Information processing process
1.1 数据处理技术
传统的数据处理方法是以处理器为中心;而在大数据环境下,需要采取以数据为中心的模式,以减少数据移动带来的开销。大数据处理模式包括流处理和批处理,其中批处理模式采用先数据存储后处理方式,流处理模式采用直接处理方式。根据大数据的数据特征和计算需求,数据处理方法还包括内存计算、图计算和迭代计算等。
大数据的基本处理流程与传统数据处理流程差别不大。由于大数据要处理大量非结构化的数据,所以在各处理环节都采用Map Reduce 方式进行并行处理。Map Reduce 适合进行数据分析、日志分析、商业智能分析、客户营销、大规模索引等业务。Spark Streaming 是构建在Spark 上的处理Stream 数据的框架,其基本原理是将Stream 数据分成小的时间片段(几秒钟),以支持高吞吐量和容错的实时数据流处理。
1.2 数据挖掘分析技术
数据挖掘分析是大数据的核心。由于大数据具有海量、复杂多样及变化快等特性[3],需要采用适应大数据特点的分析方法。常用分析方法有数据挖掘方法、概率统计法、相关系数法和机器学习方法。
(1)数据挖掘方法
数据挖掘方法[4]主要包括分类分析、关联分析、聚类分析和异常检测等4 种。分类分析包括模式识别、决策树、贝叶斯分类及人工神经网络等;关联分析包括Apriori 算法、FP 增长算法及频繁子图挖掘等方法;聚类分析包括基于原型的聚类、基于密度的聚类以及基于图的聚类等方法;异常检测包括离群点检测等。
(2)概率统计法
概率统计法又称数理统计方法,是研究自然界中随机现象统计规律的数学方法。概率统计法主要研究对象为随机事件、变量和过程,采用概率理论研究大量随机现象的规律性,通过一组样本判定能否以相当大的概率来保证某一判断的正确性,并可以控制出现错误的概率。概率统计中常用的异常检测方法是利用高斯密度函数,计算数据出现的概率,如果概率小于某个阈值的数据,就认为该数据是异常的。
(3)相关系数法
相关系数是最早由统计学家卡尔·皮尔逊设计的统计指标,是研究变量之间线性相关程度的量,一般用字母r 表示。由于研究对象的不同,相关系数有多种定义方式,较为常用的是皮尔逊相关系数。皮尔逊相关系数是用以反映变量之间相关关系密切程度的统计指标,其按积差方法计算,同样以两变量与各自平均值的离差为基础,通过两个离差相乘来反映两变量之间相关程度,一段着重研究线性的单相关系数。皮尔逊相关系数的定义为
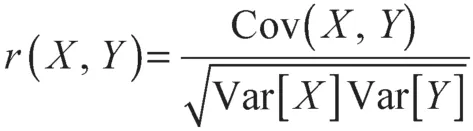
式中:Cov(X, Y) ——X 与Y 的协方差;Var[X] ——X 的方差;Var[Y]——Y 的方差。
(4)机器学习法
机器学习的本质是使用实例数据或经验训练模型进行分析处理,其包括归纳学习、分析学习、类比学习、遗传算法、联结学习及增强学习等。机器学习是面向任务、基于经验提炼模型以实现最优解设计的计算机程序,其利用经验学习规律,一般应用在缺少理论模型指导但存在经验观测的领域中。
2 系统方案
根据上述大数据关键技术分析,本文提出一套基于大数据的LKJ 设备分析系统方案。该LKJ 设备分析系统通过与其他信息系统接口,获取LKJ 设备的运行记录、故障记录、现场反馈记录及检修记录等数据,并对这些数据进行清洗融合、抽取转换加载(extraction-transformation loading, ETL)和事件拦截分析;采用聚类分析、贝叶斯网络[5]、复杂关系网络、有向概率图等模型算法,通过数值理论分析、数据挖掘等环节,生成大数据模型与算法,建立故障规则和质量项点分析规则,通过趋势、突变、关联及因素分析,生成LKJ 设备的状态图或异常趋势图,形成故障或异常出现的规律,以便及早发现LKJ 产品潜在故障点或故障隐患,并及时提醒设备检修。系统采用分层架构,主要包括数据源、数据清洗层、数据存储层、数据分析层以及应用层(图2)。
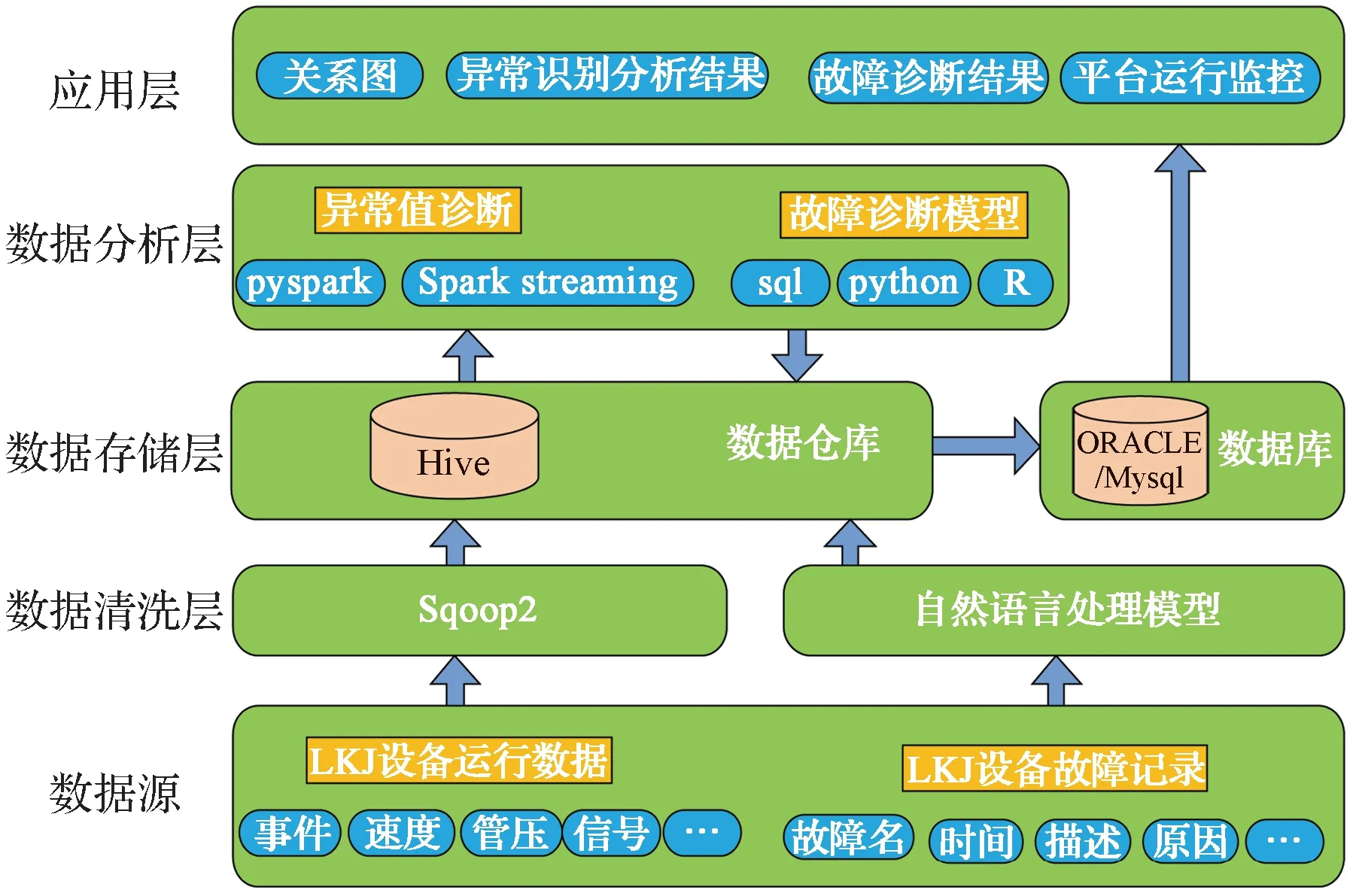
图2 基于大数据的LKJ 设备分析系统总体框架 Fig. 2 Overall framework of the LKJ equipment analysis system based on big data
(1)数据源
主要包括LKJ 设备运行记录、设备状态、故障记录、返修及设备管理等数据。
(2)数据清洗层
主要包含Sqoop2 和自语语言处理模型两种工具。结构化的LKJ 运行数据采用Sqoop2 工具进行数据采集、清洗和转换;非结构化的LKJ 设备故障记录日志采用自然语言处理模型,用以识别出符合LKJ 设备的故障和故障表征词库。
(3)数据存储层
用于存储源数据、模型分析中间过程数据及分析结果。建立相应的数据库和存储目录,以文件和数据库形式存储在大数据分析平台:采用文件形式存储LKJ设备运行记录文件和故障数据,采用Hive 数据仓库和Mysql 数据库存储分析结果。
(4)数据分析层
采用数理统计、机器学习领域[6]的异常识别方法和异常离群点检测法来识别LKJ 设备数据的异常情况;采用对比、同比、类比及分布等方法实现对设备状态或故障不同维度的统计分析;采用滑动窗口找出速度、管压、缸压及转速(电流)突变情况,并利用相关系数法进行相关性分析;采用聚类方法实现质量项点和异常事件趋势分析;采用故障诊断有向概率图模型实现设备故障关联分析;采用复杂网络模型实现故障因素分析,挖掘分析突变和趋势阈值。
(5)应用层
采用折线图、饼图、散点图及树形关系等形式展示挖掘分析结果,对故障报警和预警进行及时提示。
3 功能实现
基于大数据的LKJ 设备分析系统主要功能包括数据处理、异常拦截、趋势分析、故障关联分析、故障因素分析、故障预警及统计分析等。
3.1 数据处理
与LMD 系统接口,获取LKJ 设备运行记录数据和实时状态数据;与其他系统接口,获取故障记录、反馈、检修、设备管理等数据;采用批处理模式对数据进行转换处理并存储在LKJ 设备数据处理服务器;定期通过ETL 工具Sqoop2 将LKJ 设备的转换数据导入到大数据分析平台[7];对某机车的在线运行数据进行异常诊断,将诊断结果保存到Hive 数据仓库,同时,通过Sqoop2将诊断结果保存到Mysql 数据库;基于某机车异常诊断结果和故障关联库,利用故障诊断模型,实现故障诊断,并更新故障诊断库,供可视化系统展示。图3 示出LKJ系统数据流图。
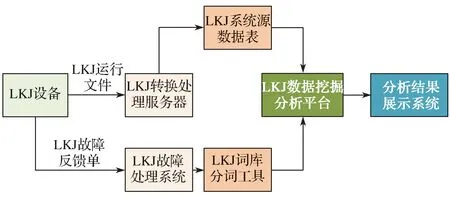
图3 数据流图Fig. 3 Data flow diagram
3.2 异常拦截
异常点识别方法主要有Delphi 专家咨询法、概率统计法、Isolation Forest 算法、FP-Growth 算法和Apriori算法。LKJ 设备记录数据具有体量大、类型繁多及数据特征复杂等特点[8]。通过比较各种异常点识别方法的优劣性,并结合LKJ 设备记录数据特征和识别方法的数据要求,来选择合适的异常点识别方法。
故障诊断的异常值拦截分为两大步骤:一是利用LKJ 设备历史数据建立异常值识别规则;二是根据已有规则对新的LKJ 设备数据实现异常值的实时诊断。根据LKJ 设备记录数据的具体特征,采用不同的异常值识别方法,从LKJ 设备历史数据中筛选可能的异常值,确定异常值并建立相应的规则库。通过异常模式库、通用模式库、频繁模式库及波动范围库,匹配入库事件,以判断是否存在异常;若存在异常,则直接输出异常,并将异常拦截分析结果存储在Hive 数据库中,用于数据挖掘分析。图4 示出异常拦截流程。
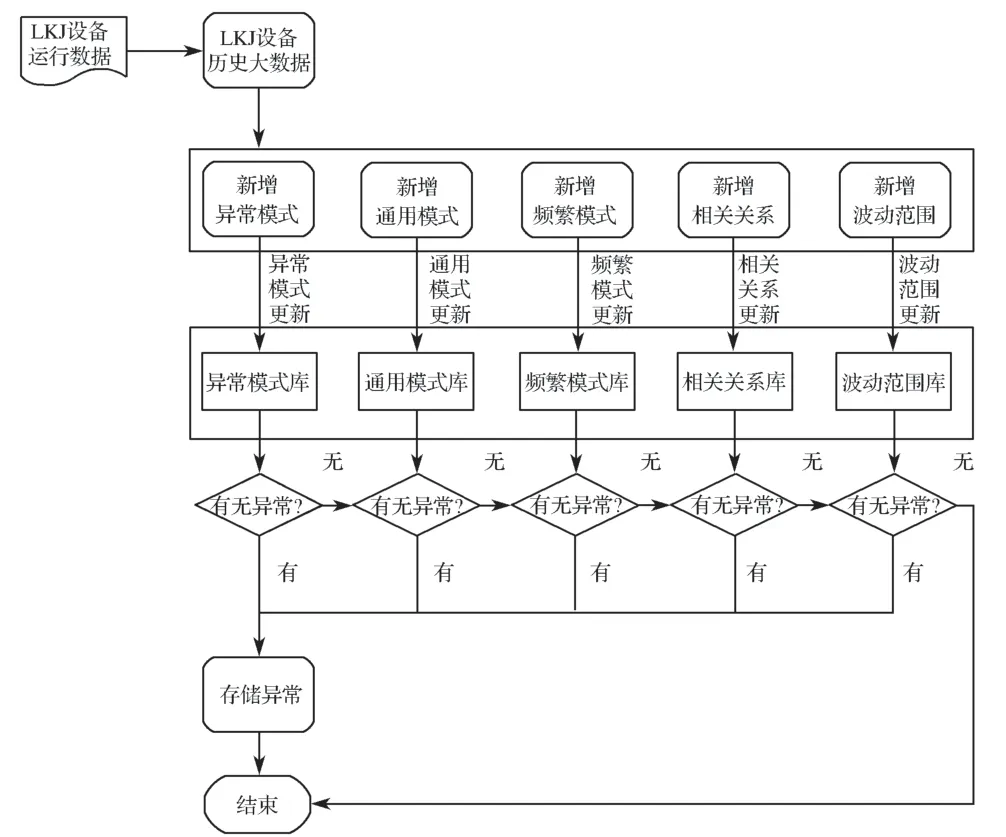
图4 异常拦截流程图Fig. 4 Abnormal intercept diagram
3.3 设备趋势分析
采用离散序列的偏态分析,总结异常规律,形成故障数据的趋势分析[9],实现设备状态的预警提示。LKJ系统故障/异常趋势分析时,按时间维度分析故障/异常发生的趋势,生成某种故障/异常状态趋势图并总结出相关规律,为LKJ 设备的检修形成指导依据。在分析过程中,增加车型(机车型号、机车号)、地域、区间和时间等要素,以分析在特定条件下的趋势规律;同时,针对不同分析维度添加预警线,也能帮助定位到极度异常事件。图5 示出异常状态趋势分析结果展示界面。
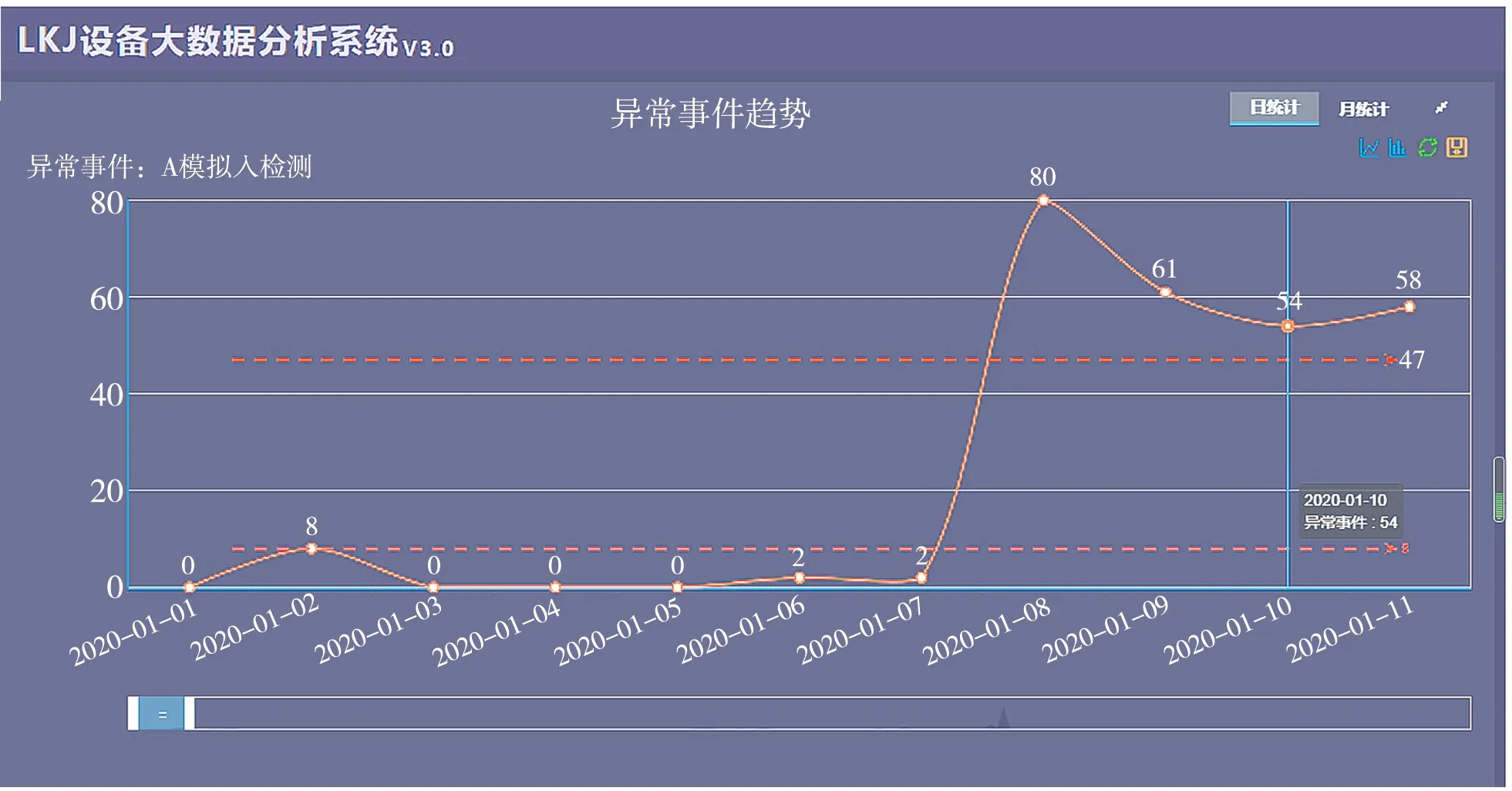
图5 异常状态趋势分析 Fig. 5 Abnormal state trend analysis
3.4 故障关联分析
LKJ 设备的运行数据文件、故障反馈单等信息中含有故障检修和故障关联的相关信息。对于故障文本数据,可以通过对其进行数据预处理,筛选出有关故障表征、故障原因的数据,结合专家知识建立自然分词库和人工提词库,并通过机器语言算法和人工筛选分类建立故障表征和故障设备的关联关系;基于故障特征建立故障关联分析,其中提取故障特征是关键的分析环节,其分析结果的好坏直接影响到故障之间关系的映射。针对故障文本特征的提取算法有Viterbi 算法、N-Gram 算法、TF-IDF 算法、基于信息熵的新词发现等,通过上述算法实现最初的中文分词,从不同的角度对分词结果进行筛选和优化,分类建立故障表征和故障设备的关联关系;通过参数学习和结构学习,分类建立故障与异常之间关联关系。
采用故障/异常之间关联图,展现故障和异常事件、异常事件和异常事件、故障和故障之间的关联关系,以及关联的精密度,为故障的预测和深度故障的挖掘[10]提供数据支撑。图6 示出LKJ 设备故障关联分析图。
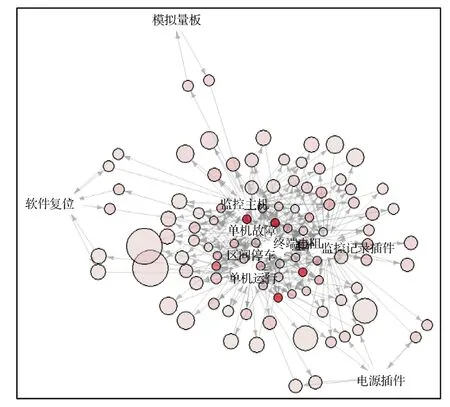
图6 故障关联分析图Fig. 6 Fault association analysis chart
3.5 故障因素分析
故障因素分析采用复杂网络模型实现。复杂网络模型主要研究事物的关联性,基于异常变量的关系,探索故障关联性;借鉴复杂网络模型,构建故障关联的复杂网络模型,实现从大量运行记录数据中挖掘分析与故障相关的关键要素。对接入大数据分析平台的LKJ 设备文件实时进行挖掘模型分析,找出该文件出现故障或异常的关键要素,以便于故障定位,提高分析效率。故障因素分析主要包括单机运行、显示器黑屏、轮对空转、信号异常(绿灯转白灯、灭灯、双黄灯转红黄灯、红黄灯转红灯、绿灯转红黄灯)等项点,其主要实现的功能如下:
(1)显示挖掘分析的模型关键要素及当前运行记录数据中该故障或异常出现的关键要素,进行故障定位分析(图7);
(2)显示该故障或异常的全程运行记录数据;
(3)显示挖掘分析结论;
(4)显示故障前置事件并进行排序;
(5)提供指导意见的编辑功能;
(6)显示关键前置事件并进行排序;
(7)实现按时间、车型、车号查询出现故障的因素分析。

图7 故障因素分析界面 Fig. 7 Fault factor analysis interface
3.6 统计分析
基于设备故障的经验规则方面的研究,全面综合地分析利用各类LKJ 设备数据和与设备相关的数据,对大量历史运行记录数据文件进行检索分析并对同一LKJ设备状态或故障进行累计,按路局、电务段、时间、线路、故障类型等维度对设备故障或异常进行分析统计,对LKJ 设备使用里程、时间、按键次数、开关情况进行累计分析,实现设备维修预警和使用寿命管理,并及时提醒检修和设备更换,以减少设备故障。
4 实验验证
该系统已在实验室进行部署并应用;通过在实验室搭建大数据分析平台,将大数据挖掘分析算法部署到大数据平台,将近3 年LKJ 运行记录数据和故障反馈数据导入大数据分析平台,进行挖掘分析,并对分析结果进行展示。图8 示出综合分析结果数据的展示界面。
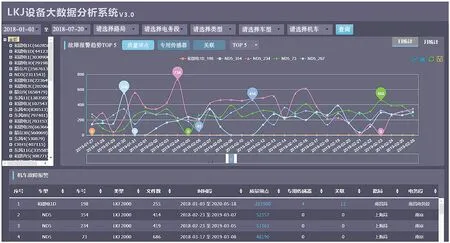
图8 分析结果数据展示界面 Fig. 8 Data display of analysis results interface
通过该系统的实验室应用,找出LKJ 设备运行过程中出现的速度、管压、缸压、转速、电流的突变情况,发现转速记录异常、速度跳变等问题,并及时进行处理;建立设备故障趋势统计指标,以可视化方式展示各LKJ设备状态的历史趋势和设备故障的分布情况,用于针对性地指导维护策略的制定;形成现场各LKJ 设备的使用时长、使用里程、按键、开关等寿命管理数据,为设备检修和维护提供指导;得到LKJ 设备的单机运行、显示器黑屏等典型故障的关键因素及支持度,为分析设备故障原因提供数据支撑。
5 结语
本文给出基于大数据技术的LKJ 设备分析系统设计方案及其功能实现。通过部署与试用,所设计的系统可以从大量历史运行记录数据中找出设备运行记录的异常情况,形成设备累积里程和使用时间,生成典型设备故障相关因素汇总、设备状态历史趋势曲线、设备故障异常趋势曲线以及故障指标统计,以辅助维护人员及时发现问题并及时处理,从而降低设备故障率,并为设备维护提供数据支撑和决策指导。
随着LKJ 设备相关数据的不断完善及异常故障数据的不断历史累积,后续将通过深入研究设备故障特征、故障因素及故障规律,挖掘分析模型,不断更新智能化分析技术,以进一步提升设备的故障定位和故障预测的准确率。
猜你喜欢
中国特种设备安全(2022年6期)2022-09-20 02:52:28
汽车维修与保养(2019年7期)2020-01-06 03:30:42
当代陕西(2019年15期)2019-09-02 01:52:00
电子制作(2018年11期)2018-08-04 03:26:08
学苑创造·A版(2018年11期)2018-02-01 06:29:20
读者(2017年5期)2017-02-15 18:04:18
汽车维护与修理(2016年10期)2016-07-10 08:17:41
工业设计(2016年12期)2016-04-16 02:52:00
汽车维修与保养(2015年6期)2015-04-17 03:31:50
汽车维护与修理(2015年2期)2015-02-28 12:15:39
