
面向街景自动驾驶的DSC-MB-PSPNet语义分割技术研究
2020-10-27 03:19胡云卿潘文波侯志超金伟正
控制与信息技术 2020年4期
胡云卿,潘文波,侯志超,金伟正,于 欢
(1.中车株洲电力机车研究所有限公司,湖南 株洲 412001; 2.武汉大学 电子信息学院,湖北 武汉 430079)
0 引言
图像语义分割是自动驾驶中一个基本的街景理解任务,高分辨率图像中的每个像素都被划分为一组语义标签。与其他场景不同,自动驾驶场景中的对象呈现出非常大的尺度变化,这对高层次的特征表示提出了很大的挑战。
随着大数据时代的兴起以及深度学习技术的飞速发展,图像语义分割的主流技术已经变为以深度学习[1]为基础,但目前的各种算法在自动驾驶实际应用中仍存在泛化能力、精确程度及运行时间等方面的问题,无法满足自动驾驶的要求。
本文提出一种面向城市自动驾驶、轻量级、可实时运行的语义分割模型,其可用于自动驾驶高精度、实时的图像语义分割,能提供详细的车辆周围可行使区域、障碍物目标及车道等信息,为单纯视觉感知的自动驾驶提供技术支持与保障。
1 图像语义分割技术研究现状
自从AlexNet[2]在ImageNet[3]比赛中以绝对优势领先普通算法夺冠之后,以卷积神经网络为基础的深度学习技术成为图像语义分割的主流方法。
文献[4]首次使用全卷积神经网络(FCN)进行图像语义分割,该网络架构成为之后多种改进型图像分割网络的基础架构。首先,FCN 使得整个网络全部由卷积层组成,通过双线性插值的方法对特征图进行上采样(Upsampling),将其恢复到输入分辨率大小,再逐像素通过分类器实现语义分割。此外,为了获得更精确的分割效果,FCN将浅层特征与深层特征进行深层次融合,使得网络最后分类的特征层包含更多的语义与形状位置信息。FCN 是第一个将深度学习与卷积神经网络应用到图像语义分割领域的端到端算法。
文献[5]提出采用编码-解码结构的U-Net 网络,其中编码网络对图像进行特征提取,得到图片的高层语义特征图;而解码网络则采用转置卷积来逐步恢复图像信息,最终可以输出与输入同分辨率的语义分割效果图。U-Net 还采用了跳跃连接的方式,即将编码网络中间层的特征图与解码网络中同等大小的特征图进行融合,以保证解码网络拥有更多的信息来恢复图像。U-Net 被提出后,在多种场景的图像分割中取得了良好的应用成果;针对U-Net 的改进算法也层出不穷,如U-Net++[6]等。U-Net 在医疗图像分割中表现良好,但对于高分辨率自动驾驶场景的图像分割,效果却不尽如人意;同时,U-Net 难以做到实时运行。
谷歌公司提出了图像语义分割网络Deeplab[7-9]系列。在Deeplab v1 中,将深度卷积神经网络与概率图模型(CRF)相结合,由于CRF 可以被简单地理解为在决定一个位置像素值时会考虑周围位置的像素值,因此通过全连接的CRF 可获得图像的全局信息,从而提升了分割的精度。Deeplab v2 采用空洞卷积,扩大了卷积核的感受野。之后的Deeplab v3 与Deeplab v3+抛弃了概率图模型而采用ASPP 模块,实现了完全的深度学习的端到端训练与测试。Deeplab v3+针对ASPP 模块进行了许多算法的创新,如采用PSPNet[10]。PSPNet 将经过特征提取网络提取的特征图利用不同大小的池化核进行池化,将不同池化结果特征图与原特征图进行融合,使得最后的特征图中具有大量不同尺度的全局信息。这种通过融合多尺度全局池化特征的方法可以有效提升图像语义分割的精度。Deeplab v3+是目前公开的图像语义分割算法中精确度最高的算法,但其最大的缺点是消耗时间长、难以实时运行,所以尽管精度最高,但难以投入到自动驾驶应用中。
文献[11]中提出的ICNet 网络虽然很好地解决了高分辨率图像实时语义分割问题,但没有解决城市自动驾驶中各种类样本严重不均衡的问题,因此无法满足自动驾驶的要求。
针对以上各算法的不足,本文提出一种深度可分离卷积、多分支、金字塔池化尺度融合结构(DSCMB-PSPNet),其在保证模型具有良好表征能力的同时可以做到实时运行。文中提出抑制性交叉熵损失函数(inhibitory cross entropy loss,ICE Loss)以降低样本不平衡的影响,消除城市自动驾驶中各种类样本严重不均衡的问题;同时加入了多级损失函数计算方式,提升了训练的效率,使得模型更容易收敛。
2 DSC-MB-PSPNet 模型方案
自动驾驶所需要的图像语义分割与传统学术界的语义分割研究有很大不同。首先,自动驾驶中场景更加复杂。由于交通环境的特殊性,所以任何数据集都不可能包括所有的交通场景,这就需要自动驾驶中的图像语义分割算法具有良好的泛化性,不仅能在常见场景中表现良好,而且在陌生场景中特别是环境比较恶劣的情况下也能保持较高的精度,从而保障自动驾驶的安全性需求。其次,自动驾驶中对于类别的侧重点不同。目前基于CNN 的图像语义分割算法都是在公开数据集上评测性能,每个数据集都有其相应的类别;然而在自动驾驶中只关注少数的类别,如路面、车道线、车辆行人等,因此自动驾驶中将树木、天空这类目标看作背景,致使背景中包含的像素明显增多,这会导致严重的数据种类不均衡问题;同样,在已划分出的类别之间也存在严重的不均衡问题,如一般情况下的交通场景图片中行人的像素数量显然大幅少于路面行人的像素数量,这些不均衡问题将会导致模型本身训练难度的增加,进而影响精度。再者,模型的速度难以被保证。自动驾驶由于安全性的需要,所以所有算法的实时性永远是第一要求,而目前许多图像语义分割算法在实验室内装有大型计算显卡的PC 机上尚且难以实时运行,更何况在自动驾驶的嵌入式平台之上。因此,图像语义分割算法模型的高效性与轻量性是目前图像语义分割算法在自动驾驶中应用所面临的最大困难。
目前绝大多数图像语义分割算法采用树形结构网络,即在网络初始时只有一个分支,在几层提取之后再采用特征图融合的方式提取中间过程中的特征层,将其与最后的特征层相融合,其好处是前面的特征提取网络可以使用性能优异的分类网络,且预训练模型可以被初始化,能保证模型快速收敛。但这些模型存在两个突出问题,会导致网络运行时间的增加:一是分类网络为了具有良好的提取特征能力,其卷积层的通道数一般较多;二是图像语义分割为了达到高精度,需要大分辨率的输入,而这会造成经过基础分类网络计算量的显著增加。
2.1 DSC-MB-PSPNet 模型构建
本文所提出的DSC-MB-PSPNet 模型如图1 所示,其采用多分支网络结构来进行不同层次提取,在降低计算量、保证分类使用特征图的同时,还具有丰富的语义信息与位置信息。网络可被分为3 路分支,即下、中、上分支;3 路分支的输入为同一张图像,只是各自的分辨率不同而已。
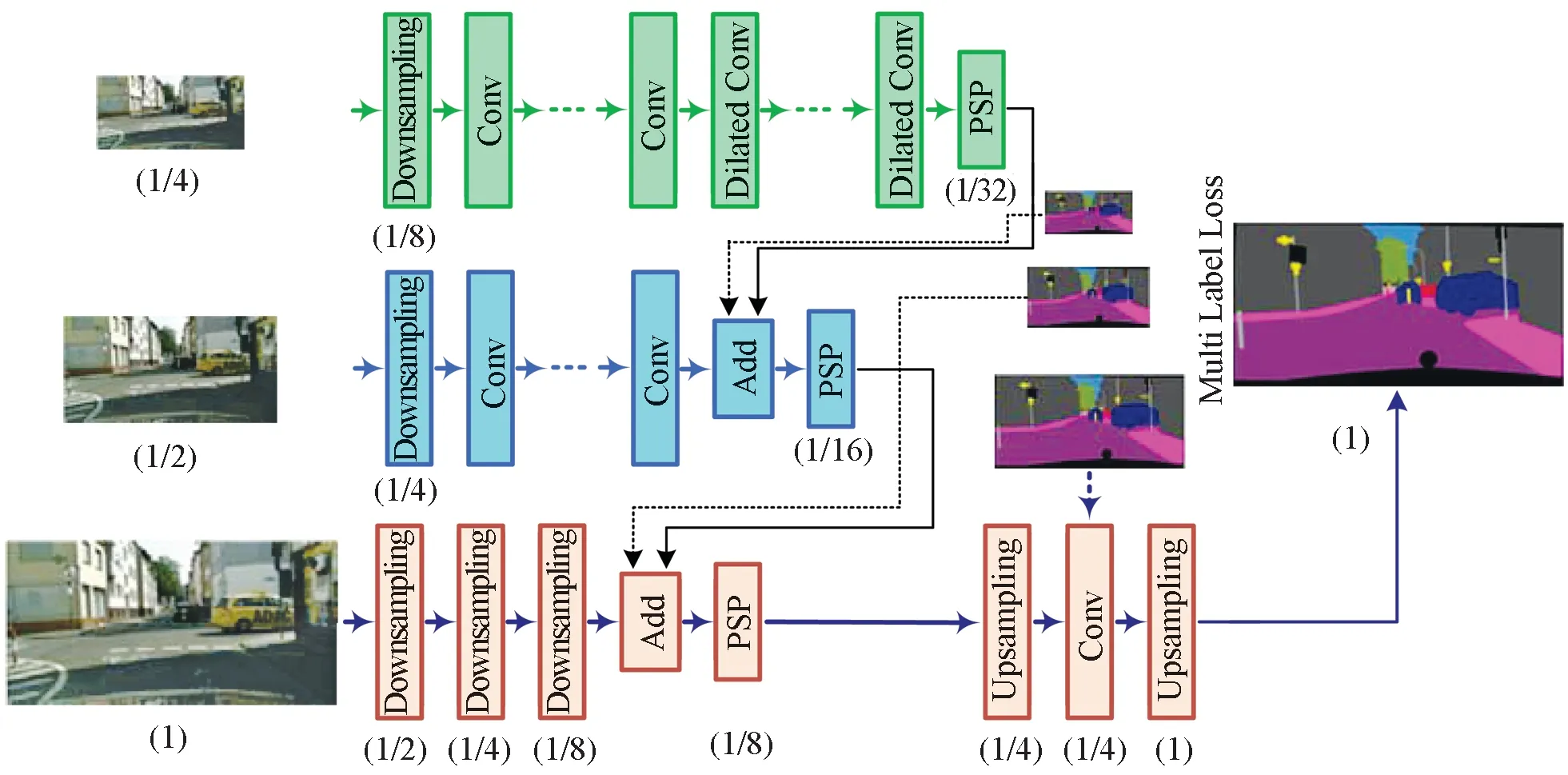
图1 DSC-MB-PSPNet 网络结构Fig. 1 Structure of DSC-MB-PSPNet
下分支输入原始分辨率图像,图像经过3 个下采样层(Downsampling)后,特征图变为1/8 原始图像分辨率的大小。可以发现,最下路的分支作用是用很少的卷积层得到图像的低维特征。下路分支输入图像的分辨率高,且只经过了少数几个卷积层的计算,因此计算量并不会显著增加。中分支输入1/2 原始分辨率的图像,图像经过多个卷积层模块后,特征图变为1/16 原始分辨率的图像。中分支的作用主要是得到图像中间层的特征,为最终的特征图提供更多可供选择使用的特征信息。上分支输入1/4 原始分辨率的图像,经过多个卷积层模块与空洞卷积处理后,特征图变为1/32原始分辨率的图像。上分支主要用于提取图像的高维语义特征。虽然上路分支经历了大量的卷积提特征操作,但由于输入分辨率较低,总的计算量也没有明显增多。
3 路分支之间最终的特征图需要进行逐级融合[12],即上层分支的特征图先与中间层的特征图相融合,之后再与下层的特征图进行融合。融合中采用全新设计的Add模块。为了使模型轻量化,网络中采用可分离卷积来代替普通的卷积;在上层分支中,为了提取高维特征时具有良好的感受野,在该分支网络的后半部分采用了空洞卷积。
2.1.1 Downsampling 模块及PSPNet 模块
Downsampling 结构(图2)将输入分为两路,一路分支经过步长为2 的卷积层进行下采样,另一路经过池化(pool)来下采样,两种输出结果经拼接后再经过1×1 卷积实现融合。这样设计的好处是可以让网络自身去学习并判断两种方式中哪种效果更好,最终网络本身在更新过程中使两者之间达到一个平衡。为使模型更加轻量级且运行速度更快,图2 中的卷积(Conv)以及网络中其他3×3 Conv 均使用深度可分离卷积,其具体结构如图3 所示,其中Depthwise Conv[13]为深度可分离卷积中的通道内卷积,BN[14]与AF 分别代表批规范化层与激活函数层。
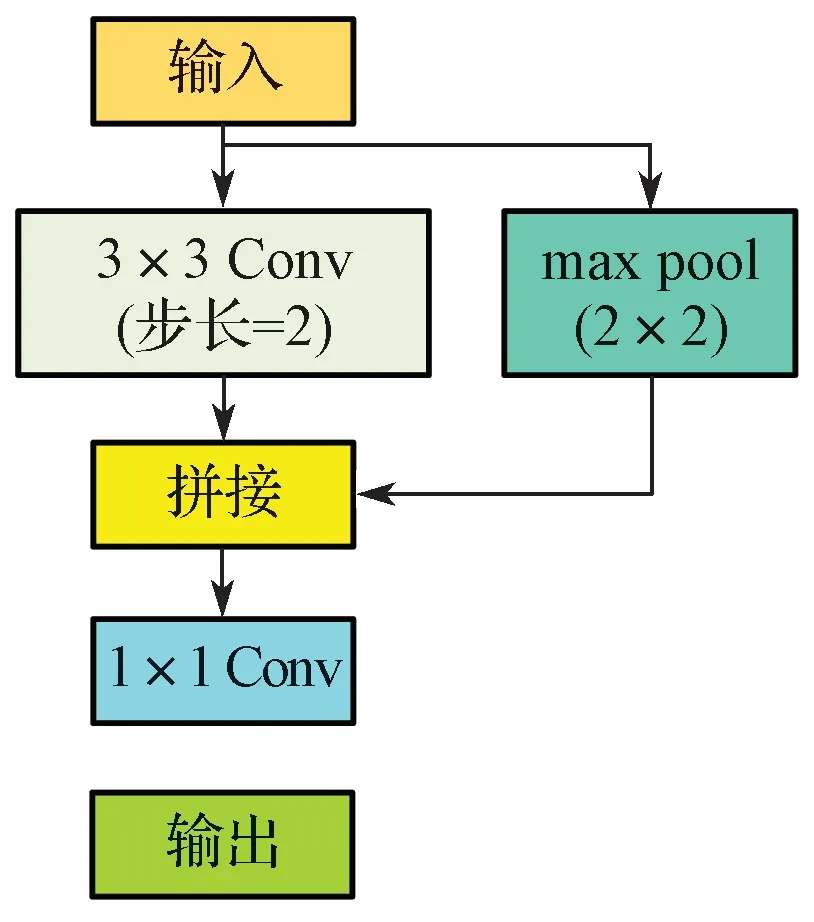
图2 Downsampling 模块Fig. 2 Downsampling module
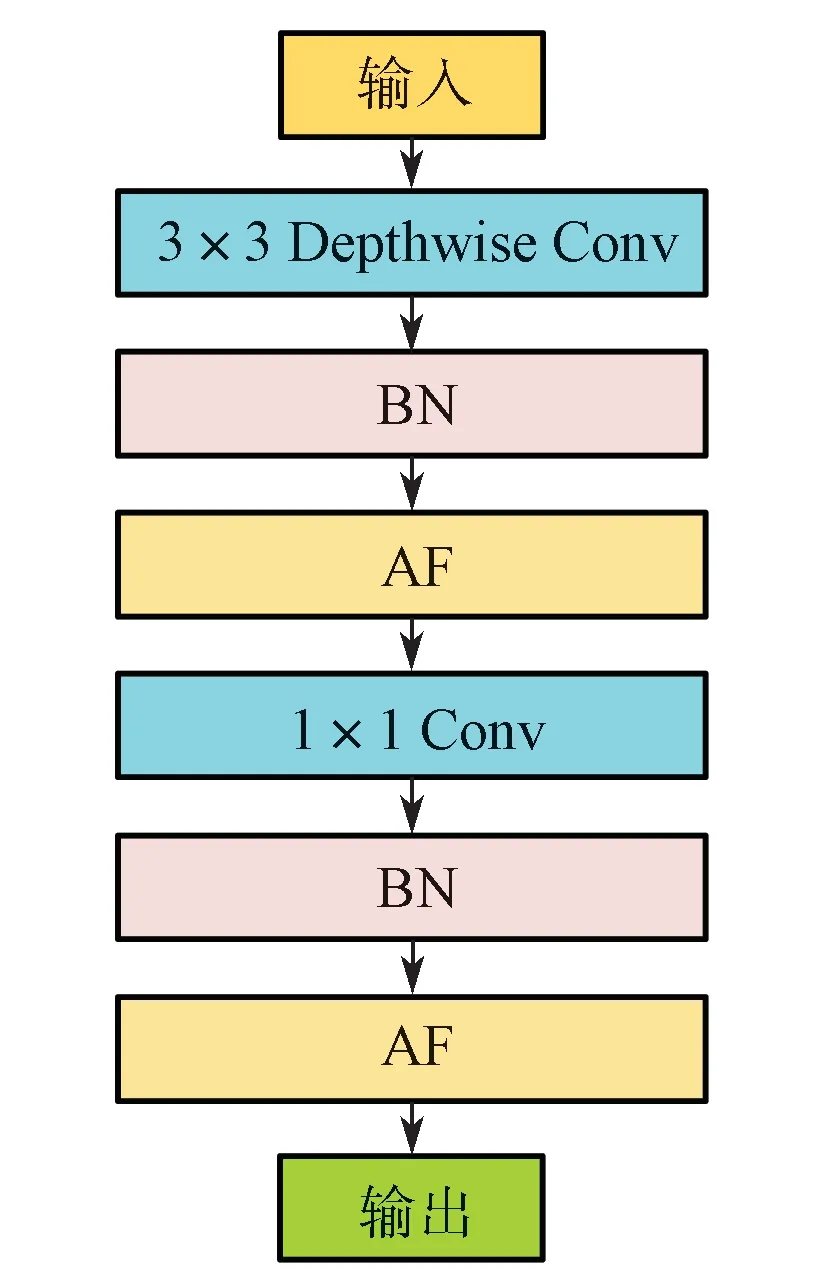
图3 Conv 的具体结构Fig. 3 Specific structure of Conv
在经典的图像语义分割算法PSPNet 中,采用金字塔池化尺度融合的结构来解决全局信息缺失的问题,很好地处理了图像语义分割中场景之间的上下文关系和全局信息。本文采用这种结构并在3 路分支上分别采用金字塔池化尺度融合以得到每一路分支的最后特征图。金字塔池化尺度融合结构如图4 所示,在得到某一特征图后,首先对特征图进行不同尺度的池化操作(图中分别采用了1×1, 2×2, 3×3, 6×6 的池化核大小来进行池化),接着通过1×1 卷积层将通道数降为原来的1/4;之后将所有池化之后的特征图上采样到输入前的尺寸并与输入的特征图进行连接,就可以得到通道数为原来2倍的特征图;最后利用1×1 Conv 进行多尺度信息的融合与降维。金字塔池化尺度融合的结构在多种尺度上进行了池化,提升了最后特征图的各尺度特征信息,使得网络更容易捕捉到图像中的全局信息。
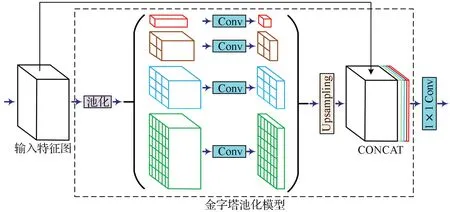
图4 金字塔池化尺度融合结构Fig. 4 Structure of PSPNet
金字塔池化尺度融合方式实现了图像不同尺度的感受野,主要有两层作用:一是将图像局部区域的上下文信息与全局的上下文信息相结合,使得特征信息更加丰富;二是将整体的轮廓信息与图像细节纹理信息相结合,提升了分割物体边缘的效果。金字塔池化尺度融合的结构在一定程度上提升了图像语义分割的多尺度精度。
2.1.2 Add 模块及残差结构
在网络输出端仅需要一个维度的特征图来进行分类输入,在3 个分支之间设定相应的Add 模块(图5)以对不同维度的特征图进行融合。Add 模块的输入包括一个高维特征图Fh与一个低维特征图Fl。另外,Add 模块中也包括了损失函数的部分(图5 中的Label 输入)。
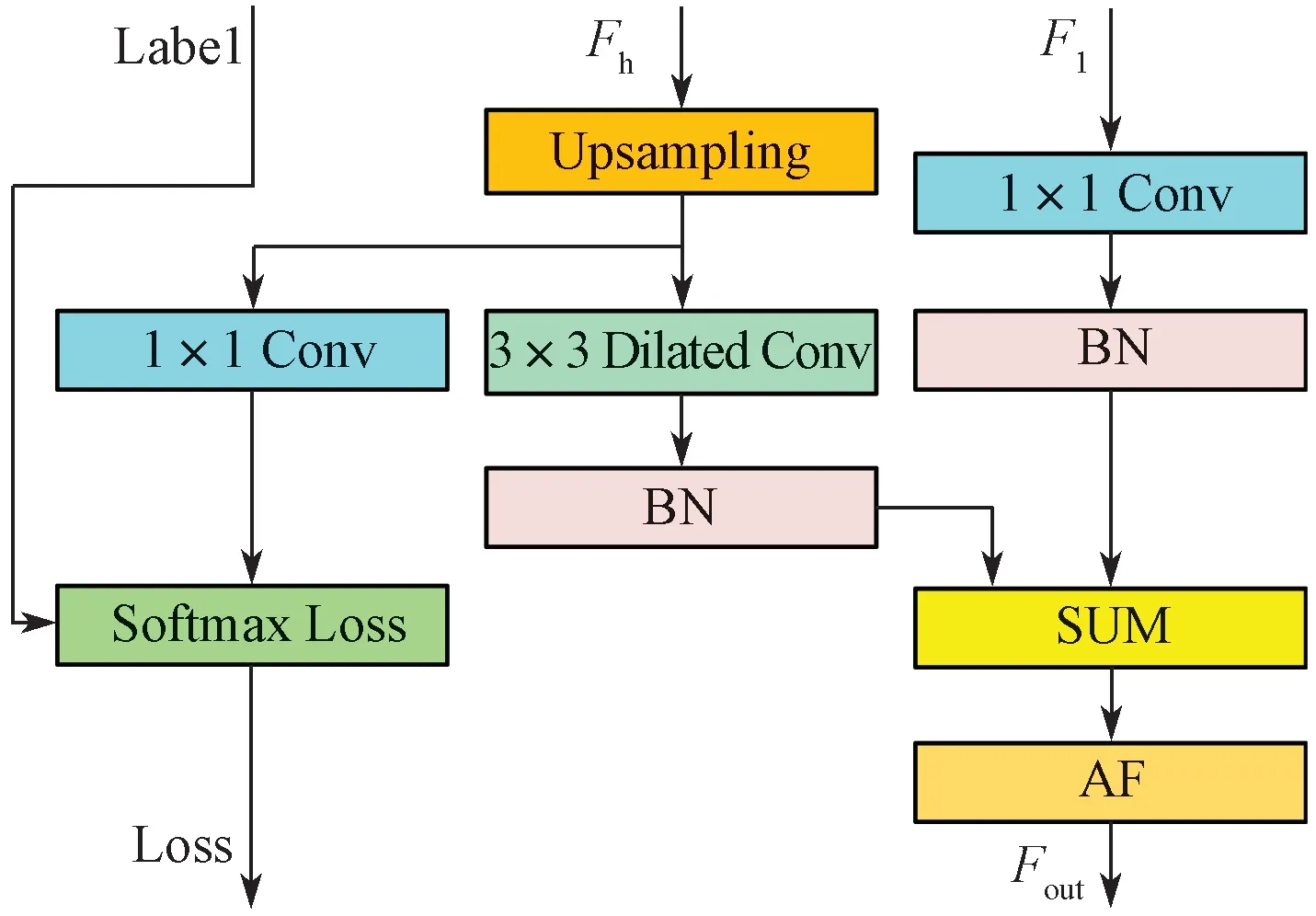
图5 Add 模块结构Fig. 5 Structure of add module
对于高维特征图Fh,首先需要将其上采样到与低维特征图同等大小,之后再利用空洞卷积进一步扩大感受野的范围;对于低维特征图Fl,经过1×1 Conv 处理降维之后,与处理后的高维特征图进行SUM 操作,输出结果Fout即为融合后的特征图。如图1 所示3 分支结构中上支路和中支路之间的Add 模块,上支路输出特征图作为Fh的输入,中间支路输出特征图作为Fl的输入,经过该Add 模块融合之后的特征图再与下支路输出特征图一起输入到另一个Add 模块中,最终的输出结果即为所有分支特征融合之后的特征图。
Add 模块的主要作用是融合不同维度、不同分辨率的特征图,其中最主要的操作为SUM,其本质上是对两个矩阵之间相同位置的元素进行相加,得到新的矩阵。一般来说,特征图之间的融合操作还有Concat 和MUL等,但经过实验发现SUM 的效果最好,因此本文选用SUM 操作作为Add 模块中的融合手段。
2.1.3 残差结构及激活函数
在多分支结构中的上支路中,为了使网络更深且提取的特征更加精细,使用了残差结构。图6 示出两种不同的残差结构,二者左边结构相同,均参考了Mobilenet v2 的设计,第一和第三个卷积为1×1 Conv,中间为3×3 Conv。第一个卷积被称为降维卷积,其目的是减少输出特征图的通道数量,以有效减少后续3×3 Conv 的计算量,但降维卷积对特征提取能力的影响有限;第二个卷积为可分离卷积;第三个卷积为升维卷积,其目的是增加输出特征图的通道数量,以保证特征的丰富性。特别需要指出的是,第三个卷积之后没有激活函数,因为对于高维特征,激活函数会破坏特征信息,因此在卷积之后高维特征被直接线性输出到下一层。图6(a)中,右分支中存在一个卷积层,其将卷积之后的输出与左分支相融合,得到输出;而图6(b)中,直接将左分支的输出与输入进行融合,这样既保证了深层网络的信息流通,又保证了计算量的稳定。
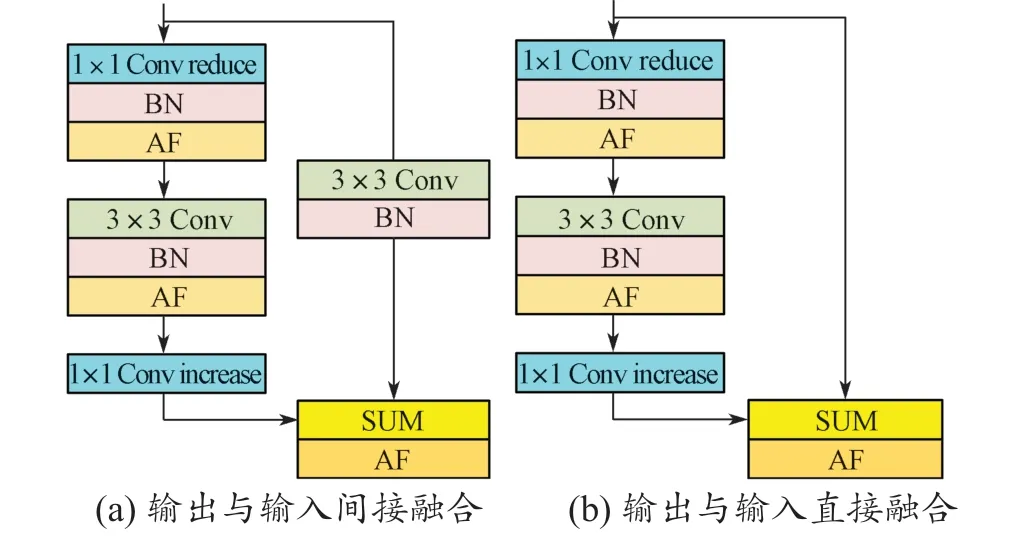
图6 残差结构Fig. 6 Residual structure
在卷积神经网络中的激活函数[15]一般采用修正线性单元ReLU 函数。当输入大于0 时,ReLU 函数进行线性输出;输入小于0 时,直接输出0,如图7(a)所示。ReLU 函数由于只有线性关系,所以比其他激活函数速度更快;同时梯度保持稳定,不会存在梯度消失的问题。但该函数输入为负时,梯度为0,会导致神经元坏死,一旦某一位置输入为负,有可能导致后续该位置永远不会更新,使得网络失效。为了解决这一问题,可采用Leaky ReLU 函数,其在ReLU 函数的基础上,当输入为负时不再置0,而是乘以某一系数α 进行线性输出,如图7(b)所示。本文选用Leaky ReLU 函数作为激活函数,以使得网络具有更强的表征能力且更易被训练和收敛。
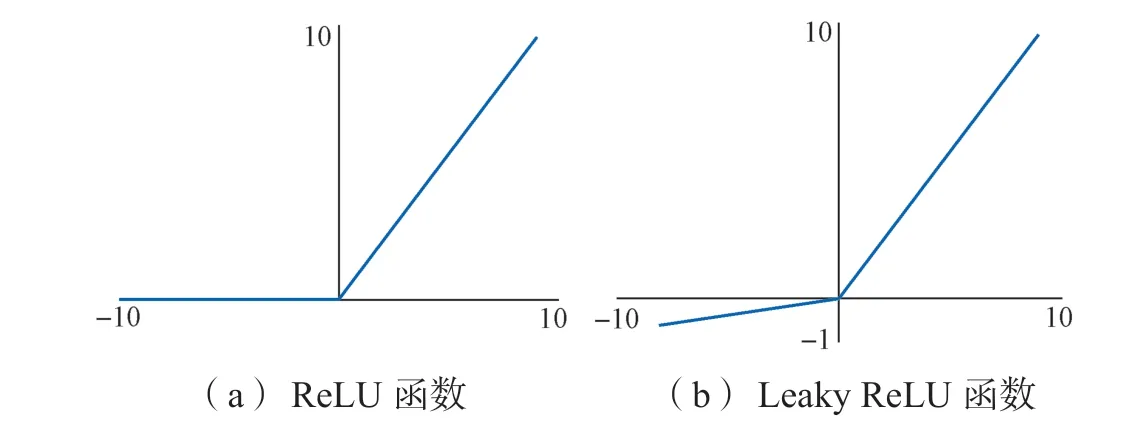
图7 激活函数图像Fig. 7 Activating function
2.1.4 上采样方法
图像语义分割若要得到与输入图像同等分辨率的分割结果,必然需要上采样操作。目前在语义分割中常用两种上采样方法。第一种是利用线性插值或双线性插值方法来填充图像分辨率放大时产生的空余像素,如图8所示。在图像放大过程中,Q11, Q12, Q21, Q22为原始的4个已知像素点,若要求得到中间未知点P 的像素值,首先需对X, Y 方向进行插值,分别得到R1与R2处的像素值,如式(1)和式(2)所示;其次,可以通过R1与R2处的像素值插值得到P 点的像素值,如式(3)所示。
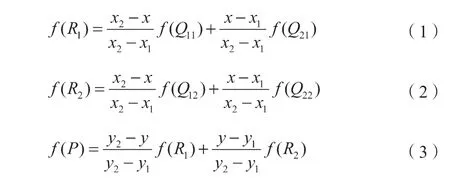
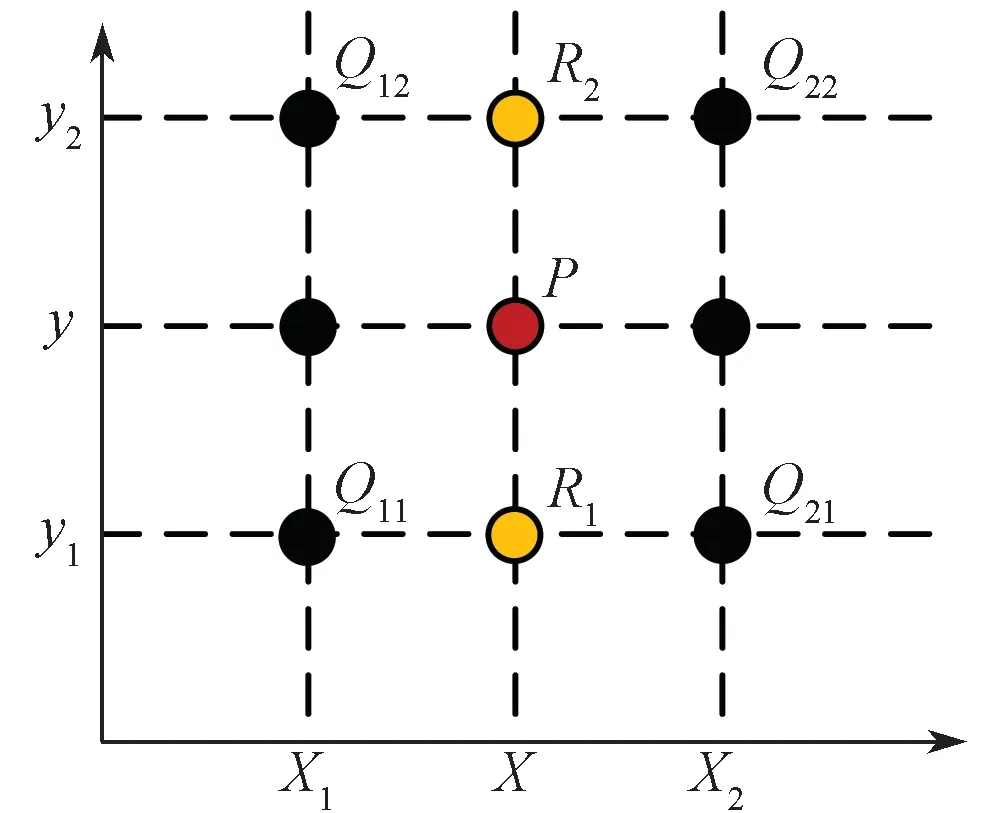
图8 双线性插值 Fig. 8 Bi-linear interpolation
第二种是利用转置卷积的方法。转置卷积即卷积的反过程,其首先将普通卷积操作中的卷积核做一个转置,然后将普通卷积的输出作为转置卷积的输入,而转置卷积的输出就是普通卷积的输入。转置卷积同样利用网络自学习方法去学习最优的转置卷积参数,使得图像上采样效果最好。
双线性插值的方法计算简单、耗时少且效果较好;而转置卷积通过网络自学习方式得到参数,因此计算量较大,同时也会增加模型的复杂度,因此本文在对速度和精度进行均衡考虑后,选用双线性插值作为上采样方法。
2.2 多级监督损失函数以及抑制性交叉熵损失函数
在图5 的Add 模块中加入监督损失计算(即将标签图缩放到与每一路特征图同等维度,利用1×1 Conv分类之后再与标签图像进行交叉熵损失函数的计算),对每一个维度的特征形成一个有效的监督,这样整个网络结构中会产生3 个损失值(L1, L2和L3),因此总损失计算函数公式为

多级辅助监督损失不仅对最终输出结果进行损失误差的计算,同时对中间层的特征图也进行损失误差的计算。这样设计的好处是,在本文模型的反向传播更新中对3 路分支进行同步的参数更新,相比于一般的损失函数计算方式,其可以显著提升网络的收敛速度并在一定程度上提升了模型的精度。
在训练样本种类不均衡时,原始的交叉熵损失函数会由于简单像素以及大量存在的种类像素其分类损失误差的大量累积而导致网络倾向于易学习的样本,最终导致网络对简单种类且数量多的样本学习越来越好,对于种类复杂且数量少的样本学习越来越差,造成训练的恶性循环,不符合模型训练的初衷。为了解决这一问题,可对不平衡的种类进行权重控制,分级损失计算如式(5)所示。

式中:Si——Softmax 函数值;ui——可调参数;i—训练次数。
通过改变μi值来控制不同种类像素损失误差在总误差中的比重。但这种做法只控制了类别不均衡样本之间的占比平衡,从根本上还是无法区分出困难样本;在训练中后期,梯度还是向着更易学习的样本种类方向进行更新,因此不能促进神经网络对困难样本的学习。
Softmax 函数的输出概率值越大,说明其为某一类别的可能性就越大,网络此时对该像素判断的可信度比较高,也就是此时的输入为简单样本;反过来说,当Softmax 函数输出概率较小,说明网络难以区分出输入的准确类别,即此时的输入为困难样本。所以,区分简单与困难样本可以依据Softmax 函数的输出概率来确定。参考Focal Loss 函数,本文采用融合多级损失的形式并取其平均,提出抑制性交叉熵损失函数来解决自动驾驶中样本的不平衡性问题。该函数被定义为
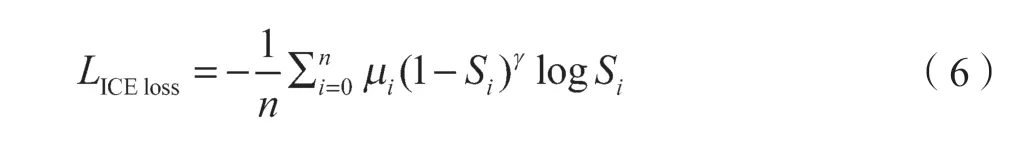
式中:γ——可调参数。
当一个样本越容易被区分时,Si值就越大,那么(1-Si)γ值就越小,两者的乘积相当于对该样本的损失进行了抑制,则在总的损失误差之中的比重也就越小;相对而言,对困难样本的损失误差值进行了一定程度的放大,其在总损失误差中的比重就会加大,模型也就会更倾向于学习困难样本。
3 算法模型的实验
卷积神经网络的实现与训练测试等都在深度学习框架Tensorflow 下进行。算法使用的系统为Ubuntu 16.04版本、CUDA 版本8.0 和CUDNN 版本6.0;算法实现的硬件环境见表1。

表1 算法使用硬件平台Tab. 1 Hardware environment for the algorithm
3.1 实验数据集
本文主要在两种数据集上进行了相关算法模型的实验与测试,包括Cityscapes[16]数据集及自搭建的城市交通场景数据集。Cityscapes 评测数据集是目前自动驾驶感知领域内公认的最具代表性的图像语义分割数据集之一,该数据集重点关注对真实城区道路场景的理解,其共包含50 个不同城市、不同背景、不同季节的街景,提供了5 000 张经过精细人工标注的图像以及20 000 张粗略标注的图像,共包含30 类标注物体。我们主要使用了其中3 500 张精细标注的图像以及其中常见的20 类标注类别、训练数据图像3 300 张,测试数据图像200 张。图9 所示分别为Cityscapes 中的真实图像、标签图像以及颜色标注实例。
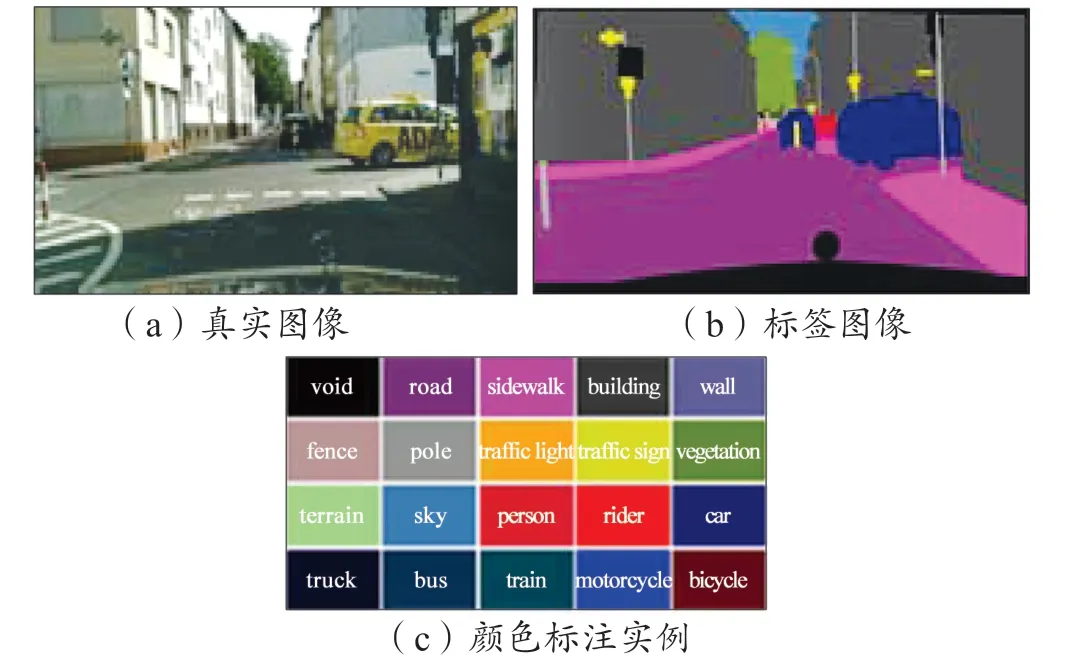
图9 Cityscapes 数据集Fig. 9 Cityscapes dataset
为了测试在国内真实城市道路交通场景中的效果,我们通过自动驾驶平台的车载摄像头采集了武汉市道路场景的图片并利用图像语义分割标注工具Lableme 进行了标注,制作完成了图像语义分割数据集,包括训练集4 000 张、测试集400 张,共分为道路、车道线、车辆、行人及背景5 种类别。图10 所示为自制数据集中的样本数据实例。
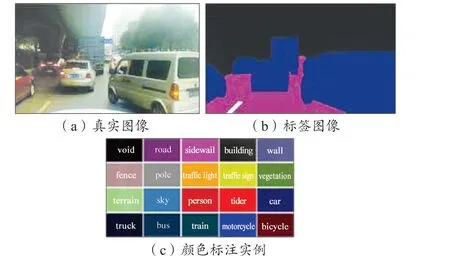
图10 自制城市交通场景数据集Fig. 10 Self-produced scene dataset for urban traffic
3.2 数据预处理
首先,对数据集中的图像进行裁剪处理。Cityscapes数据集中的图片分辨率为2 048×1 024,经过中心线剪裁,可以将一张图片分为2 张1 024×1 024 图片,这样不仅降低了训练的难度,同时也扩充了数据集;自制作的数据集采集图片分辨率为1 280×720,将上方裁去16 个像素,使得图片变为1 280×704 分辨率。
其次,对数据进行减均值操作。在深度学习中,由于反向传播中遵循求导的链式法则,若图像中的像素值都为正值,那么权重在更新迭代过程中会同时增大或同时减小,致使权重更新效率低,因此在输入中减去整体数据集的均值之后,输入就会有正有负,在一定程度上消除这种不利影响。Cityscapes 数据集中,RGB 三通道的均值分别为123.68, 116.78 和103.94;自制数据集的均值分别为122.54, 117.32 和104.78。
最后,对输入数据进行归一化处理。训练所用彩色图像的像素值均分布在[0, 255],进行归一化就是将像素值都压缩到0 到1 之间,使得各个特征尺度都控制在相同范围内,以保证梯度更新时更加平稳,加速网络的收敛,尽快找到网络的最优解。同时,对标签图像进行编码,将不同类别所代表的颜色编码成唯一的标签向量。如对Cityscapes 数据集的20 个类别,编码标签向量的长度为20,其中每一位都代表一种类别。经过编码的标签图像更易于训练计算,在网络输出之后同样需要进行反向的解码输出。
另外,虽然卷积神经网络具有强大的特征表征能力,但由于存在巨大的网络参数,模型需要大量的数据作为支撑,因为数据样本过少会导致网络模型学习不到位、泛化性能差、容易陷入过拟合等问题。为了尽可能在有限的数据集上扩充训练样本,对数据在训练中进行了随机的数据增强处理,具体包括:(1)水平翻转。训练过程中,每一次迭代时图像都有50%的概率进行水平翻转。(2)旋转。训练过程中,每一次迭代时图像都有20%的概率旋转一定角度,范围在-30°~ 30°之间。(3)垂直翻转。训练过程中,每一次迭代时图像都有20%的概率进行上下翻转。
3.3 模型训练参数设置及分级训练
网络搭建完毕后,在Tensorflow 平台上分别在Cityscapes 数据集与自制数据集上进行训练。由于网络不存在预训练模型,所以对于网络中的卷积层采取Xavier 方法进行初始化:
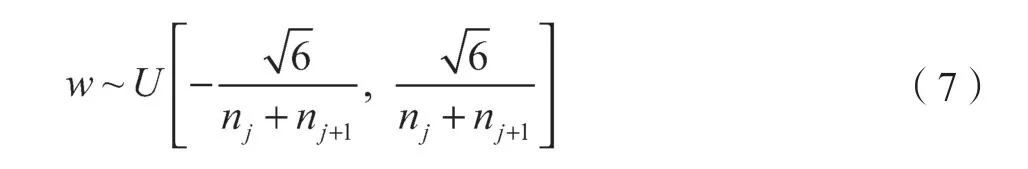
式中:nj——第j 次训练。
对于偏置,则直接初始化为0。梯度更新采用Adam 优化器。模型的其他训练参数设置还包括:训练的初始学习率为0.000 2;Batchsize 为5;网络结构中自上而下3 个损失误差的比重因子分别为α1=0.25, α2=0.4, α3=1.0。在Cityscapes 上训练的Epoch 为150 次,在自制作数据集上训练的Epoch 为80 次。
由于网络结构较为复杂,若直接进行全部网络的训练,难度比较大且不易于收敛,所以采用了分级训练的方法。具体过程是,在图2 的网络中,首先只激活下路分支的网络,即只对下路分支的参数进行更新;在损失误差基本保持不变时,固定下路分支的参数,将中路分支接入网络继续训练;同样,在损失误差基本保持不变时,固定下路与中路分支的参数;之后,将上路分支再接入网络,实现整个网络的训练,得到整个模型最终的参数。结果表明,相比于直接进行全网络训练,分级训练可以缩短模型收敛的时间,并且最后的模型误差也降得更低,因此其是一种非常适应于本文算法的训练方法。
3.4 对比实验及结果
为了测试本文算法的效果以及抑制性交叉熵损失函数对网络的提升,在Cityscapes 数据集及自制作数据集上做了多种对比实验。
首先,网络中分别使用普通交叉熵损失函数与本文提出的抑制性交叉熵损失函数进行了两组对比实验,损失误差如图11 所示。图中,CE Loss 表示普通交叉熵损失,ICE Loss 表示抑制性交叉熵损失,1 个Epoch表示一个完整的学习过程。损失误差均从3 路分支同时开始训练算起,可以看出,使用抑制性交叉熵损失函数比使用普通交叉熵损失函数更早收敛,抑制性交叉熵损失误差在40 次Epoch 之后就保持平稳,而普通交叉熵损失在100 次Epoch 之后才开始保持平稳,证明抑制性交叉熵损失函数可以加快模型的训练速度,保证模型的快速收敛;同时由于抑制性交叉熵损失中每一个像素损失误差均会与小于1 的因子相乘,所以抑制性交叉熵损失误差始终小于普通交叉熵损失误差。
图11 不同损失函数训练误差对比Fig. 11 Comparison of training errors of different loss functions
最终每种类别的精度如表2 所示。可以发现,在road 和car 这类数量较多且简单的类别中,两组实验的平均交并比(mIoU)值相差不大;但对于traffic sign, pole 等数量较少且困难的类别,使用抑制性交叉熵损失函数的实验mIoU 值均高于普通交叉熵损失函数的,其中wall 类别高3.2%,fence 类别高3.3%,truck 类别高4.5%,motorcycle 类别高3.4%。最终两组实验的整体mIoU 值比使用抑制性交叉熵损失函数的实验高出了1.4%。这组对比实验结果说明,本文加入的抑制性交叉熵损失函数可以提升数据集中数量较少的类别分割精度,一定程度上解决了数据集样本种类不均衡的问题。
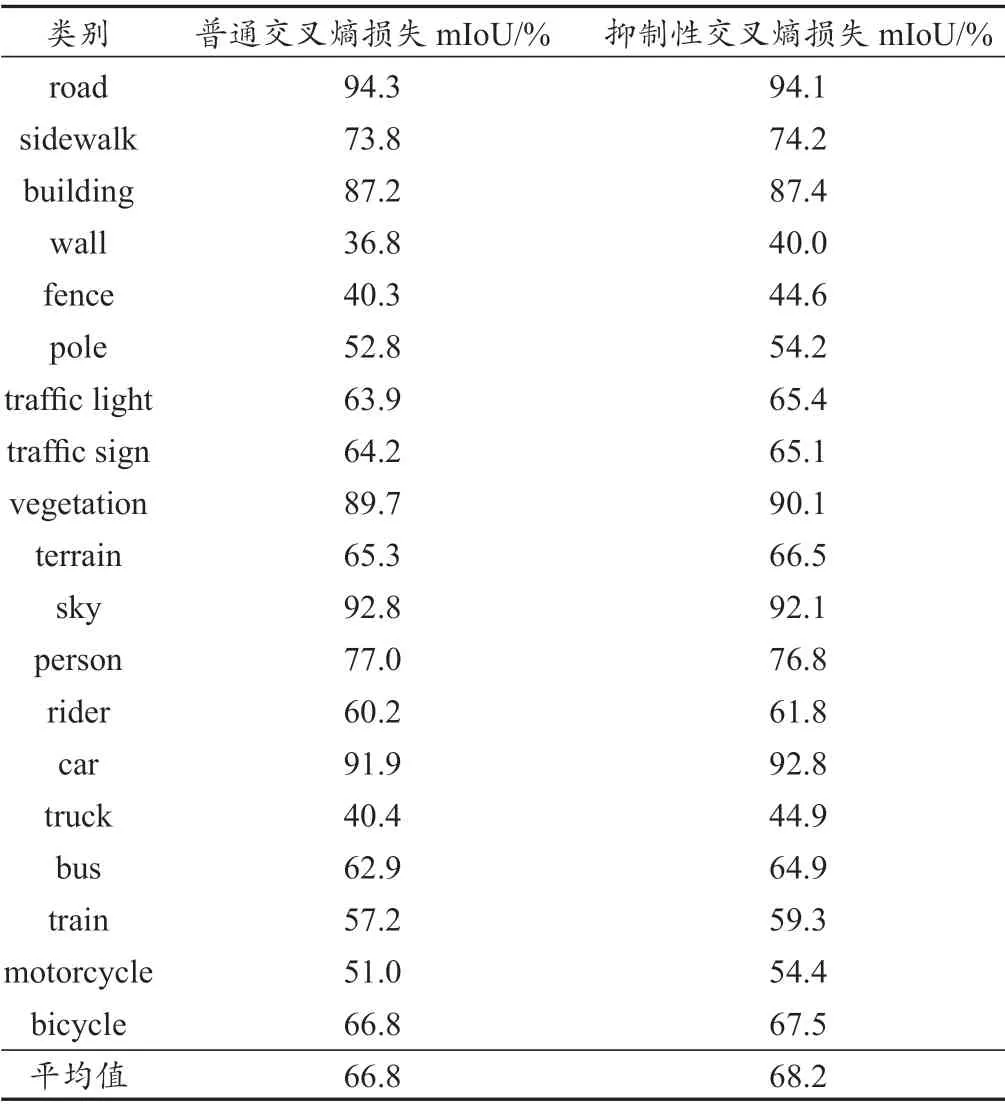
表2 Cityscapes 上不同损失函数各类别平均交并比Tab. 2 mIoU of different loss functions on Cityscapes
其次,本文对比了在Cityscapes 数据集上与各主流语义分割算法的结果,主要比较了最终的mIoU 值及运行时间(表3),其中Cityscapes 图像分辨率为2 048×1 024。表3 中的DR 参数代表输入图像的缩放倍数,如DR=2,则输入分辨率为1 024×512。其他算法[17-19]的数据来源于Cityscapes 官网,其中运行时间与mIoU 均为NVIDIA TITAN XP 测得,而本文算法在NVIDIA 1080Ti 上测得,结果之间具有一定差异性,但影响有限。本文只收录了Cityscaps 官网中明确给出运行时间的一些方法。
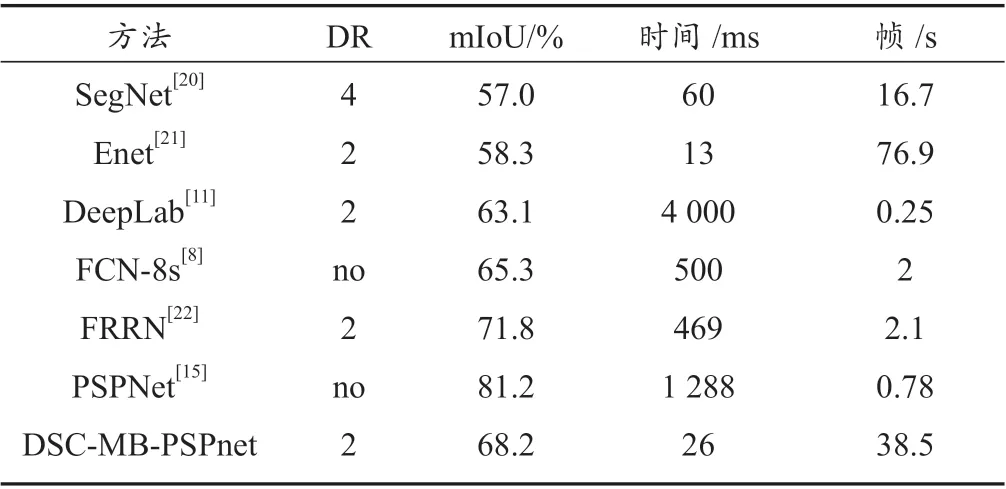
表3 本文算法与其他语义分割算法的对比Tab. 3 Comparison between our algorithm and other semantic segmentation algorithms
由表3 可以看出,其中mIoU 最高的为PSPNet,达到了81.2%,但运行时间很慢,需要1 s 多才能得到结果;而速度最快的为Enet,只需要13 ms 就可以处理完一张图像,但其mIoU 仅有58.3%,无法满足精度要求。因此,通过对比各种算法的效果可以发现,本文的算法在下采样2 倍之后,取得了68.2% 的mIoU 值,同时处理一张图像仅需要26 ms,在所有算法中做到了精度与速度的平衡,可以满足自动驾驶语义分割任务的需要。
最后,为了验证本文添加的金字塔尺度融合结构对于模型精度的影响,本文做了相应的对比实验,如表4所示,表4 表示了在每路分支后添加金字塔尺度融合结构的mIoU 变化。由表4 可以发现,在全网络中不添加任何金字塔尺度融合模块,mIoU 仅有60.2%;而在添加金字塔尺度融合模块之后,模型的测试精度有了大幅度的提升,并且当只有上路分支和中路分支添加后,模型的精度达到最高。下路分支添加金字塔尺度融合模块后mIoU 值下降的原因可能是下路分支仅经过了3 个下采样结构,提取的特征中主要以纹理特征为主,多尺度融合容易破坏其中的特征信息,进而影响了最终的模型质量。
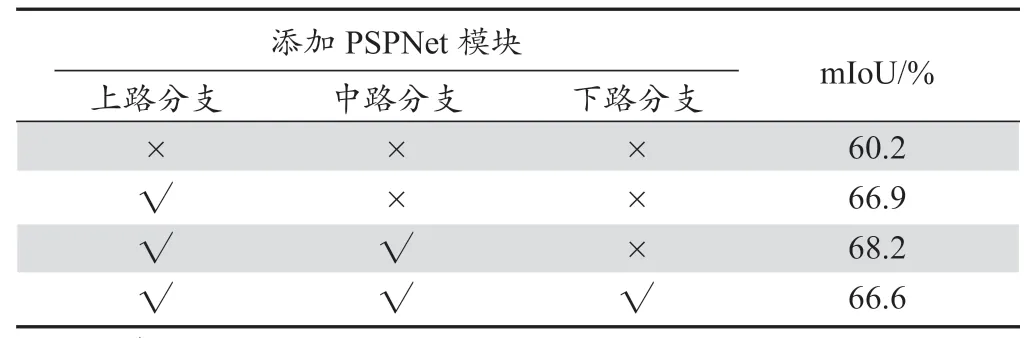
表4 金字塔尺度融合结构对模型精度的影响Tab. 4 Impact of pyramid scale fusion structure on model accuracy
图12 展示了部分训练完成后的测试图像,其中左侧为输入的真实城市交通场景图像,中间为对应的真实标签图像,右侧为算法输出图像。

图12 部分数据算法结果Fig. 12 Partial data algorithm results
3.5 嵌入式平台中模型的加速
以上实验测试均在装有NVIDIA 1080Ti 显卡的PC机上完成,运行功率达到400 W,显然在自动驾驶平台中无法持续提供如此高的功率以供计算,且放置大型PC 机也不符合车规级标准要求。因此,自动驾驶平台中只能放置体积较小、功率很低的嵌入式平台设备,且嵌入式平台中用于计算的硬件资源有限,无法提供如NVIDIA 1080Ti 显卡那样强大的计算能力,所以模型在移植到嵌入式平台时运行速度会大幅降低[23-24],难以实时化。为了解决这一问题,采用NVIDIA 的开源加速库TensorRT 4.0 版本对本文的训练模型进行加速,并对加速前后效果及运行时间进行了对比。实验平台为NVIDIA Jetson TX2 嵌入式平台,在测试时使用Cityscapes 数据集,采用1 024×512 分辨率,即将原测试集图像分辨率整体缩小一半(原因是TX2的显存有限,不能容纳更大的分辨率图像),并采用了FP16 的存储方式,对比结果如表5 所示。

表5 采用TensorRT 加速前后模型在TX2 上的精度与运行时间Tab. 5 Accuracy and running time of the model on TX2 before and after TensorRT acceleration
对比实验结果可以发现,使用TensorRT 之后,模型的精度会略微下降,这是因为模型中参数由32 位浮点数转化为16 位浮点数,造成了一定的计算误差,但损失的精度仍在可以接受的范围内;相比于原始的模型,加速后的模型运行时间有了显著的减少,整个模型的速度有了近1 倍的提升。
4 结语
本文提出一种DSC-MB-PSPNet 模型,其采用3 分支结构的网络,通过不同分辨率的输入在计算量比较小的情况下同时得到了低维与高维特征,同时网络中采用PSPNet, Add 和深度可分离卷积等模块。在Cityscapes数据集上的测试结果表明,该算法能够在精度与运行时间之间达到有效的平衡。针对自动驾驶场景中数据样本种类之间严重不均衡的问题,本文提出抑制性交叉熵损失函数,对于容易区分的样本,降低其在总损失误差中的比重;对于难以区分的样本,提高其在总损失误差中的比重,使得网络在反向梯度更新时能够朝着难以分割的样本目标的方向前进。在自制作的城市交通场景数据集中进行了训练测试,为了使模型能够在自动驾驶嵌入式平台上运行,利用TensorRT 对模型进行加速,实车测试结果表明,模型可以在自动驾驶平台上做到实时运行,并且分割结果在大多数场景中具有较好效果。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机系统应用(2021年10期)2022-01-06
数学小灵通·3-4年级(2021年5期)2021-07-16
学生天地(2019年28期)2019-08-25
今日农业(2019年15期)2019-01-03
长江学术(2016年4期)2016-03-11
共产党员(辽宁)(2015年2期)2015-12-06
读者·校园版(2015年19期)2015-05-14
人间(2015年21期)2015-03-11
