
探讨基于神经网络的商品评论情感分类
2020-10-26 02:23孙庆阳刘磊
科学与信息化 2020年29期
孙庆阳 刘磊
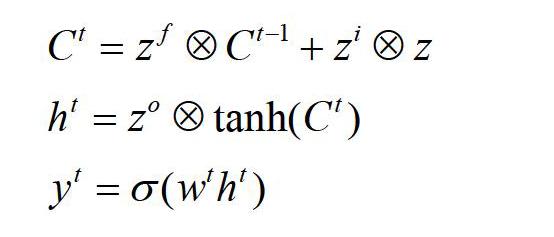

摘 要 随着计算机技术的飞速发展,自然语言处理在日常生活得到了广泛应用,同时由于神经网络地开发和应用,自然语言处理技术在电商平台上大放异彩。实验内容为基于在某电商平台上获取的某一书籍商品的评论数据,从而对该数据进行情感分类工作。实验首先利用双向LSTM算法对文本数据信息进行深层提取,再利用Attention机制将双向LSTM算法的输出信息进行整合,最终通过全链接层进行分类,从而构建了一种准确度更高的分类模型。实验结果表明,基于Attention机制处理之后的分类算法取得了96.27%的准确度。
关键词 自然语言处理;文本分类;LSTM;Attention机制
Sentiment Classification Of Commodity Reviews Based On Neural Network
Sun Qingyang, Liu Lei
Anhui University of Technology, Anhui Maanshang 243000
Abstract With the rapid development of computer technology,natural language processing has been widely used in daily life. At the same time,due to the fast development and application of neutral network,natural language processing technology has been playing an important role in e-commerce platform. This paper is exactly based on an e-commerce platform to obtain a book review data,so as to work on the sentimental classification of it. In this paper,firstly,it used the two-way LSTM algorithm to extract the text information in depth. Then,the output information of the algorithm was integrated by making use of Attention mechanism. Finally,classifing it through the full link layer,this paper constructed a classification model with higher accuracy. Experimental results showed that the classification which is based on Attention mechanism achieved high accuracy up to 96.27%.
Keywords Natural language processing; Text classification; LSTM; Attention mechanism
引言
当下随着人工智能技术发展得火热,自然语言处理逐渐成为人工智能技术和计算机技术最重要的研究方向之一。从计算机问世至今,人类一直希望计算机可以使用人类的语言和人类进行交互,在自然语言处理技术发展成熟之前,人们一直难以让计算机理解人类语言词语中所包含的深层意思,而现如今,随着机器学习技术和自然语言处理技术地发展,人们可以使用计算机对语言或者文字信息进行定量化地研究,从而可以使人與计算机之间共同使用语言描绘。
随着互联网技术地高速发展,人们的生活与互联网紧密联系在一起,同时随着淘宝、天猫、京东商城等一众互联网购物平台得新兴,越来越多的人习惯于在这些电商平台上购买商品。而众多买家对商品的评价也成为人们对该商品的评判标准之一,购买过该商品的买家会对该商品的质量、使用感受和性价比等要素进行评价。所以对商品评论文本进行情感分析研究具有理论和实际应用价值。
1相关研究
文本情感分析[1]是指对包含了感情色彩的文本进行分析和处理,从而提取文本所包含的深层的信息因素,而文本情感分析也具有较为广泛的应用前景,现如今,文本情感分析广泛地应用于用户评论分析、市场变化预测和互联网舆论分析。
而自然语言处理算法大致包含以下三类:情感字典方法、传统的机器学习算法、深度学习算法。
情感字典方法就是人为的构建情感字典对文本进行情感计算从而对文本进行分类的方法。刘玉娇[2]等人利用基础情感字典和基础词对不同领域的文本评论进行分析,从而获得不同领域带有情感倾向的特征词,然后利用这些特征词计算句子的情感倾向,该模型在不同领域都有着较好的表现。
传统的机器学习方法首先对文本进行特征提取,再将文本特征转换为文本向量,再利用机器学习算法进行分类。常用于文本特征分析的机器学习算法有:朴素贝叶斯、支持向量机、逻辑回归、随机森林、最大熵等。陈平平[3]等人使用jieba分词下的TF-IDF技术对电影评论文本进行特征提取,再利用多项式贝叶斯算法建立情感分析模型,从而达到了86.2%的准确率。王峥[4]等人利用决策树、N-gram算法的特征提取方法结合支持向量机分类器,从而提出了一种情感分析模型,解决了字词在不同的语境以及表达方式中的多意性问题。
而深度学习方法相较于机器学习方法最主要的是避免了人为构造大量的文本特征。最常见的深度学习方法有循环神经网络(Recurrent Neural Network, RNN),RNN算法可以有效联系上下文信息,在处理带有序列化的文本信息问题上有较好的表现。随着深度学习算法地发展,由RNN算法所演化的LSTM算法则有效解决了RNN算法天生的梯度消失和梯度爆炸问题。杨云龙[5]等人将门控循环单元GRU与胶囊特征融合结合起来建立情感分析模型G-Caps,G-Caps首先通过门控单元捕获文本的全局特征,再通过初始胶囊层迭代获取文本向量化信息,最后利用主胶囊曾求得各特征间的组合,因此G-Caps可以有效提升模型的准确率。霍社平使用带有注意力机制的双向LSTM算法对双语文本进行分析,其首先通过注意力机制对不同词语赋予不同的权重,再通过双向LSTM对新的特征进行分析,可以有效解决双语文本下的情感分析。
2jieba分词技术及原理
在数据处理过程中,中文文本语言处理与英文语言处理有着较大的不同。在英文文本中,英文的每一个单词都自然而然的被空格分隔开,如“Hello word”,而中文文本中每句话的词语却天然地结合在一起,如“你好世界”。所以在中文文本数据处理阶段分词技术是一个重要的步骤。在中文分词技术中,jieba分词有着较高的准确度,也是最为常用的分词技术之一。jieba分词其技术原理是基于统计字典,首先jieba分词构造一个常用字典,然后再根据这个字典对输入的语句进行切分,从而可以得到语句的所有切分可能,根据不同的切分可能得到有向无环图,再通过动态规划算法计算出各种切分可能的概率,从而找出最大概率的切分组合。而对于那些没有录入字典的词语,采用了隐含马尔可夫模型,并利用维特比算法进行计算和词性标注。jieba分词技术[6]有三种不同的模式:精确模式、全模式和搜索引擎模式。下图1为jieba分词技术路线:
3Bi-LSTM算法
在自然语言处理领域中,RNN算法有着较好的效果,但是RNN算法在训练过程中会出现长期依赖性的问题,这是由于RNN模型在训练过程中会出现梯度消失或者梯度爆炸的问题。而对于梯度爆炸问题,一般可以采用梯度修剪解决,但是对于梯度消失问题却很難解决。所以由RNN模型的变体模型LSTM模型应运而生,LSTM模型可以很好地解决RNN模型中的长期依赖性问题。下图2为LSTM模型的结构:
LSTM模型有两个传输状态,一个是一个是,其中对于传输状态改变得会很慢,一般为上个状态传递来的外加一些数值,而传输状态则在不同的节点下会有较大的区别。
首先LSTM的当前输入和上个状态传递而来的拼接可以得到四个状态:
其中、、是根据拼接向量乘以权重矩阵后,再通过sigmoid函数激活转换为0到1的数值,从而可以成为门控状态。是通过tanh函数激活转换为-1到1的数值。下图3为四个状态在LSTM中的应用情况。
内部结构的计算过程如下:
LSTM内部有三个阶段:
(1)忘记阶段。这一阶段针对上一节点传入进来的输入选择忘记。即通过计算得到的来作为门控,可以控制上阶段的哪些可以遗忘。
(2)选择记忆阶段。这阶段对输入有选择地进行记忆。此阶段由门控信号控制。
(3)输出阶段。此阶段可以决定哪些作为输出。主要用过控制,并且通过tanh函数对上一阶段的进行了放缩。
普通的RNN和LSTM模型都是只能根据之前的时序信息来预测下一时刻的输出,但是在长文本的自然语言处理中,当前的时刻输出不仅和之前的状态相关,也可能与之后时刻的状态相关。所以双向LSTM可以较好地解决这类问题,双向LSTM的输出由前面的输入与后面的输入共同决定。下图4为双向LSTM的网络结构。
上述网络结构的计算过程如下:
该模型在Forward曾从1时刻到t时刻正向计算一遍,得到保存每个时间单元前向隐含层的输出。在Backward层再从t时刻反向到1时刻计算,得到保存每个时间单元后向隐含层的输出,最终结合每个时间单元的Forward层和Backward层的输出得到最终的输出。
4带有注意力机制的模型搭建
下图5为带有注意力机制的双向LSTM算法的模型结构。
4.1 Embedding输入层
在数据进入算法层面之前,我们需要把数据转化成词向量的形式,采用word2Vec[7]可以把文本数据中的文本序列转换为词向量,并且Embedding层可以把大型稀疏向量转化为保留语义的低维空间。
4.2 BI-LSTM层
使用双向LSTM算法[8]对文本进行分类模型的建立。
4.3 Attention机制
注意力机制即attention机制,简单来说就是模仿人类观察行为的过程。例如:当人观看一幅画的时候,会首先扫描画的全部内容,然后再获得需要重点关注的部分,再对这些部分投入更多的注意力资源从而重点关注。因此,模型会自己去学得在不同时刻不同的权重系数。
参数表示当前时刻,表示序列中的第个元素,表示序列长度,表示对元素的编码。反映了元素对的重要性。反映了待编码元素和其他元素的匹配度,当匹配度越高说明该元素对其影响越大。
5实验
5.1 实验环境
本论文的实验运行环境为16G内存配备intel(R)Core(TM)i5-6300HQ处理器且GTX1060显存为6G显卡的个人计算机上。
5.2 实验数据
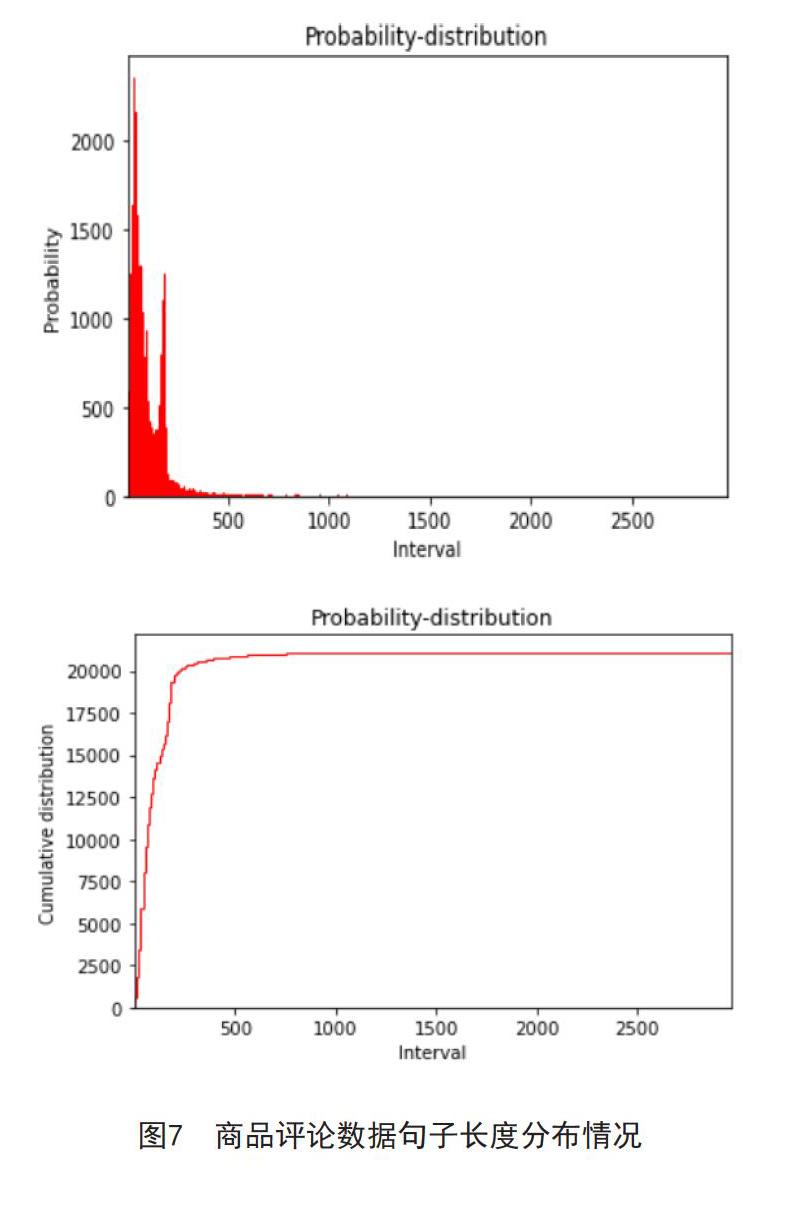
本论文使用的是从某一电商平台上爬取的对一本畅销书籍的评价,其中包含10672个正面的积极性评价和10428个负面的消极性评价。语料的前5条数据为图6,语料中的句子长度分布直方图和累计分布图如图7:
因为LSTM算法接受的序列长度是固定的,所以在数据处理中我们需要将句子裁成一样的长度。根据预料累计分布情况求得样本中90%概率的句子长度188作为裁剪后的统一长度。
5.3 语料处理
(1)语料清洗和分词
首先去除语料中的无效字符对语料进行清刷,然后使用jieba分词技术对语料进行分词,再使用停用词表去除语料中的停用词,本文使用的是哈工大停用词表[9]。
(2)创建词语字典进行词向量转化
使用word2vec技术将已经处理好的语料文本转化为词向量的形式,并且构建词语字典,再使用pd_sequences()对词向量序列进行填充,将所有句子序列长度统一。并对整个语料进行训练集和测试集地划分。
5.4 对比实验
本文使用以下三种模型与本文的模型进行对比:
(1)朴素贝叶斯模型
朴素贝叶斯模型作为自然语言处理技术中最为典型的模型,在文本语料处理中一般都会有很好的表现。
(2)支持向量机模型
支持向量机模型作为最具代表性的机器学习模型,其在二分类问题上一般都有着上佳的表现。
(3)LSTM模型
将由嵌入输出的数据经过两层堆叠LSTM模型的处理后,根据LSTM的输出值与本文的模型进行对比。
(4)BI-LSTM_Att模型
即本文所提出的含有注意力机制的双向LSTM模型,为了具有实验的对比度,该模型也含有两层堆叠的LSTM。
5.5 评价指标
因为本文是对积极性标签为1和消极性标签为0的两个大类进行分类,是一个二分类问题,并且样本的两个标签数也比较均衡,所以本实验指使用准确度作为评价指标。根据混淆矩阵,准确度precision簡写为p有以下公式:
混淆矩阵如下表1:
6实验结果与分析
6.1 实验结果
各个模型的情感分类结果如下图所示,可以看出传统的机器学习算法虽然有着不错的表现,但是深度学习算法表现得更为强力,相对的深度学习算法每轮的收敛时间要达到4分钟左右。各个算法的结果和运行时间为下表2。
6.2 结果分析
从上面结果可以看出基于统计方法的朴素贝叶斯算法进行训练,其速度很快,但是模型的表现能力不足,所以其性能不如其他模型。而基于核模型支持向量机模型准确率有了不错的提升,但是也远不如深度学习算法。LSTM模型通过神经网络联系上下文的信息,而BI-LSTM_Att模型利用注意力机制提取文本的重要特征,所以BI-LSTM_Att模型比LSTM模型性能要好,同时每轮收敛的时间也要更长。
7结束语
本文使用的是基于注意力机制的双向LSTM模型,利用注意力机制提取出文本数据中的核心特征,从而使分类的结果更加准确。实验结果表明,添加了注意力机制之后,模型的表现能力得到了不错地提升,取得了较好的结果。
本文数据采用于电商平台上的商品评论数据,这些评论的情感倾向性都比较明显,所以模型的表现能力都比较好。下一步工作将针对模糊性的语句分类进行深入研究。
参考文献
[1] 张美颀.基于电商产品评论数据的情感分析[J].电子技术与软件程,2020(11):186-187.
[2] 刘玉娇,琚生根,伍少梅,等.基于情感字典与连词结合的中文文本情感分类[J].四川大学学报(自然科学版),2015,52(1):57-62.
[3] 陈平平,耿笑冉,邹敏,等.基于机器学习的文本情感倾向性分析[J].计算机与现代化,2020(3):77-81,92.
[4] 王峥,刘师培,彭艳兵.基于句法决策树和SVM的短文本语境识别模型[J].计算机与现代化,2017(3):13-17.
[5] 翟社平,杨媛媛,邱程,等.基于注意力机制Bi-LSTM算法的双语文本情感分析[J].计算机应用与软件,2019,36(12):251-255.
[6] 曾小芹.基于Python的中文结巴分词技术实现[J].信息与电脑,2019,31(18):38-39,42.
[7] 蔡庆平,马海群.基于Word2Vec和CNN的产品评论细粒度情感分析模型[J].图书情报工作,2020,64(6):49-58.
[8] Qianli Ma. The Key Technology on Chinese Word Segmentation Based on Bi-LSTM-CRF Model[D].武汉:华中师范大学,2019.
[9] 崔彩霞.停用词的选取对文本分类效果的影响研究[J].太原师范学院学报(自然科学版),2008,7(4):91-93.
作者简介
孙庆阳(1995-),男,安徽芜湖人;毕业院校:安徽工业大学,专业:控制工程,学历:硕士,现就职单位:安徽工业大学 电气与信息工程学院,研究方向:自然语言处理。
猜你喜欢
计算机应用(2016年12期)2017-01-13
电子技术与软件工程(2016年22期)2016-12-26
数字技术与应用(2016年9期)2016-11-09
电脑知识与技术(2016年23期)2016-11-02
科教导刊·电子版(2016年23期)2016-10-31
科技视界(2016年24期)2016-10-11
电脑知识与技术(2016年10期)2016-06-16
求知导刊(2016年10期)2016-05-01
电脑知识与技术(2016年5期)2016-04-14
科技视界(2016年5期)2016-02-22
