
一种基于深度学习网络的输电杆塔智能检测算法
2020-10-23 01:55:26韦汶妍刘晓立杨传凯菅永峰沙洁韵杜建超
广东电力 2020年9期
韦汶妍, 刘晓立,杨传凯,菅永峰,沙洁韵, 杜建超
(1. 国网陕西省电力公司电力科学研究院,陕西 西安 710100;2.国网陕西省电力公司经济技术研究院,陕西 西安 710075;3. 西安电子科技大学 通信工程学院, 陕西 西安 710071)
杆塔是输电线路中的重要设施,是电力巡检的主要监测对象。当前对杆塔的巡检主要依靠人工、无线传感器等手段,巡检方法的智能化水平较低[1]。随着人工智能和无人机技术的发展,将其应用于输电设备的自动巡检,将极大提高电力巡视的智能化水平[2]。在自动巡视过程中,利用视频摄像头采集图像,并对画面中的杆塔进行自动识别和定位,可进一步判别杆塔状态,引导无人机自主飞行[3]。
一些研究采用传统的图像处理方法对杆塔进行检测。例如文献[4]使用自相似性特征提取高分辨率合成孔径雷达图像中的杆塔。文献[5]结合无人机载摄像机标定,对杆塔进行投影变换,提取投影后的直线段特征进行聚类分析。文献[6] 使用融合地理位置信息后的可变形部件模型的方法检测杆塔。传统算法普遍处理速度慢,算法效率低,易受到噪声干扰,存在一定的虚警概率。随着机器学习在目标检测领域的应用,一些文献使用机器学习中监督学习的方式,利用方向梯度直方图特征训练支持向量机来检测输电线路中的杆塔位置[7],但漏检率高于虚检率,检测效果还有进一步提升空间。文献[8]使用无人机拍摄不同方位的杆塔,提取方向梯度直方图特征作为输入训练多层感知机。这虽然缩短了检测时间和具有较好的检测精度,但是输入图像要求近距离拍摄3个方位的杆塔。
近几年深度学习在图像处理领域有了普遍的使用[9]。深度学习中的CNN算法放弃了传统方法的手工描述特征,通过对大量数据进行标注和训练,得到能自动提取目标深层特征[10]的网络参数,这类算法在目标检测任务中表现出高准确率,且训练得出的模型泛化能力强。文献[11]指出:各类卷积神经网络性能优异,计算能力强,还拥有超过100万张图片的大型数据库ImageNet。实际的杆塔检测任务中,数据集达不到此规模,训练得到的模型存在提取目标深层特征困难、检测准确度低、误检率高的问题。为了解决这些问题,图像增广和迁移学习是2种可行的方法。图像增广技术采用一些方式改变原始图像的状态,例如图像旋转、随机裁剪及加噪声等方法,使之与原图存在不同但又不改变杆塔的特征,这一方法能扩充数据集数量,提高模型的检测精度[12]。文献[13]提出,将在大型数据集上训练好的网络参数迁移到小型数据集进行训练,能解决小数据集规模不足以支撑深度学习网络训练的问题。针对这2点,本文对实际采集的杆塔图像,采用镜像、旋转、锐化等图像增广技术进行扩充以提高训练样本数量,同时使用基于ImageNet训练得到的VGG16网络作为特征提取器,利用迁移学习的原理,将VGG16已训练得到的参数作为初始化值,迁移浅层网络的基础特征提取能力,对这部分网络层参数进行冻结,输入的杆塔图像进行训练时反向传播调整其他层参数,最终得到能提取杆塔浅层基础特征以及深层抽象特征的模型。将调整好的VGG16特征提取器结合深度学习网络Faster 区域卷积神经网络(regional convolutional neural networks,R-CNN),即Faster R-CNN[14],实现了输电杆塔的准确检测。算法的整体方案如图1所示。
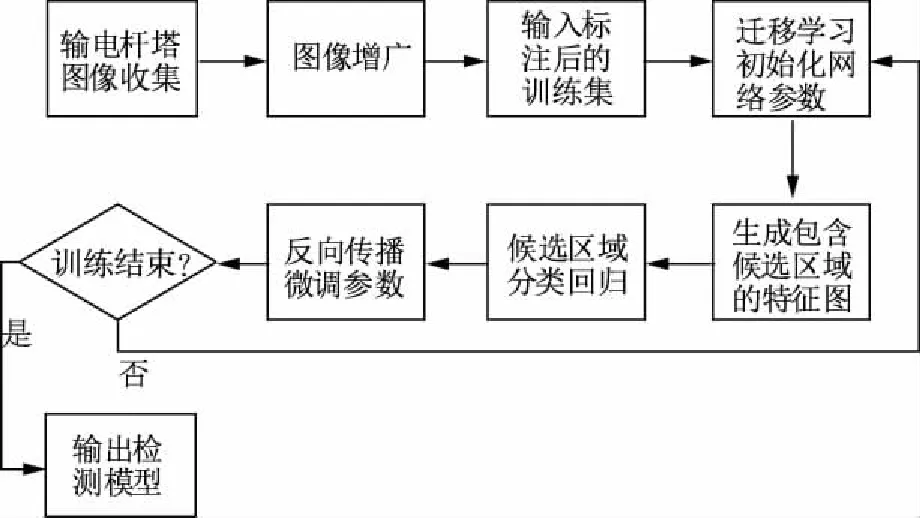
图1 杆塔检测方案总体框架Fig.1 Overall framework of tower inspection scheme
1 杆塔图像增广
图像增广可有效增加训练样本集数量,改善深度学习模型的性能。基于实际采集的巡检图片,采用3种方式进行增广:镜像、锐化和旋转。镜像不改变原图内容,只在水平方向上进行对称处理;旋转分为顺时针和逆时针,分别旋转5°、10°、15°、20°,旋转一定的角度产生了区别于原图的杆塔状态但是不改变杆塔特征的图像;对旋转后的图集采用非锐化掩蔽的方法进行锐化,增强杆塔的边缘,使其轮廓更加清晰[15]。非锐化掩蔽的原理为
A(m,n)=B(m,n)+θK(m,n).
(1)
式中:m,n分别为像素点横、纵坐标;A(m,n)、B(m,n)分别为锐化输出图像和输入图像;θ为缩放因子;K(m,n)为校正值,且
K(m,n)=B(m,n)-G(m,n),
(2)
G(m,n)是图像经过高斯模糊处理后得到的值。具体做法是使用1个3×3的高斯权重矩阵遍历图像上每个像素点,将权重矩阵上的每个权重乘以对应位置的像素点得到新的像素值,每个像素点经高斯模糊后的值为周围8个点和自身的新像素值之和。
利用增广将训练数据集扩充了19倍。一些增广的图例如图2所示。

图2 图像增广Fig.2 Image augmentation
2 杆塔检测
标注过的图像被输入VGG16网络进行特征提取,此网络已经基于ImageNet图像库进行了分类任务的学习。ImageNet图像库包含了1 400万张以上的图像,共分为2万多个类别,大类包括了鸟类、花卉、食品、乐器、人、交通工具等[16],VGG16网络从中学会提取目标边缘、纹理特征的参数。本文的杆塔不包含在ImageNet图像库中,并且与其收录的图像相似性低,但VGG16网络的浅层学习是学会提取目标的色彩斑点的权重,与输入图像集类别关系不大[17],可以采用迁移学习的方式,利用VGG16已训练得到的参数作为初始化值后,冻结网络浅层的参数不参与训练,将这部分网络提取目标基础特征的能力直接迁移到杆塔的特征提取中,结合输入杆塔图像集反向传播微调其他层的参数,达到最好的检测结果。与随机初始化特征提取网络或者参数从零开始训练相比,使用迁移学习能提高训练速度,得到更好的特征提取效果[18]。
2.1 基于迁移学习的模型训练
VGG16网络[19]结构如图3所示,包括13个卷积层和3个全连接层,每个卷积层Conv3使用的卷积核大小Kernel_size为3×3,步长stride为1,边界填充pad为1。池化层使用大小为2×2的卷积核,步长为2,边界填充为0,采用极大值函数max()的池化方式。输入图片的长和宽分别为M和N,每一层处理后的图片长W按式(3)计算,同理可以计算宽H。卷积层的处理不改变长和宽,而经过一次池化层Maxpool处理,长和宽都变为前一层的二分之一。每层经过卷积后使用非线性的ReLU[20-23]函数f(x)作为激励函数,表达式见式(4)。在存在导数时,ReLU函数导数f′(x)为常数1,不会出现梯度消失的情况,而且反向传播求误差梯度时计算量更小,x为神经元的输入。
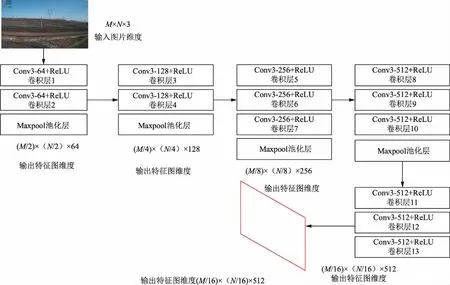
图3 VGG16网络结构Fig.3 Vgg16 network structure
W=(M-Kernel_size+2pad)/stride+1,
(3)
(4)
经过上述处理,最终输出W=M/16和H=N/16,且维度为512的特征图。
VGG16共有13个卷积层,前4个卷积层主要提取目标的浅层特征,可以不进行迁移学习,直接保留初始参数;后9个卷积层用来提取目标的深层特征,故对它们进行迁移学习。学习前后部分参数变化情况见表1。表1中列出了4组网络参数的值,对每组网络参数而言,上面1行为迁移学习前的值,下面1行为迁移学习后的值。由表1可以看出:迁移学习后这些参数在初始值基础上出现了微调,这些参数的变化体现了新模型对本地目标进行特征提取的适应性改变。利用此种迁移学习,提高了特征提取网络的训练速度,实现了模型的本地化训练。
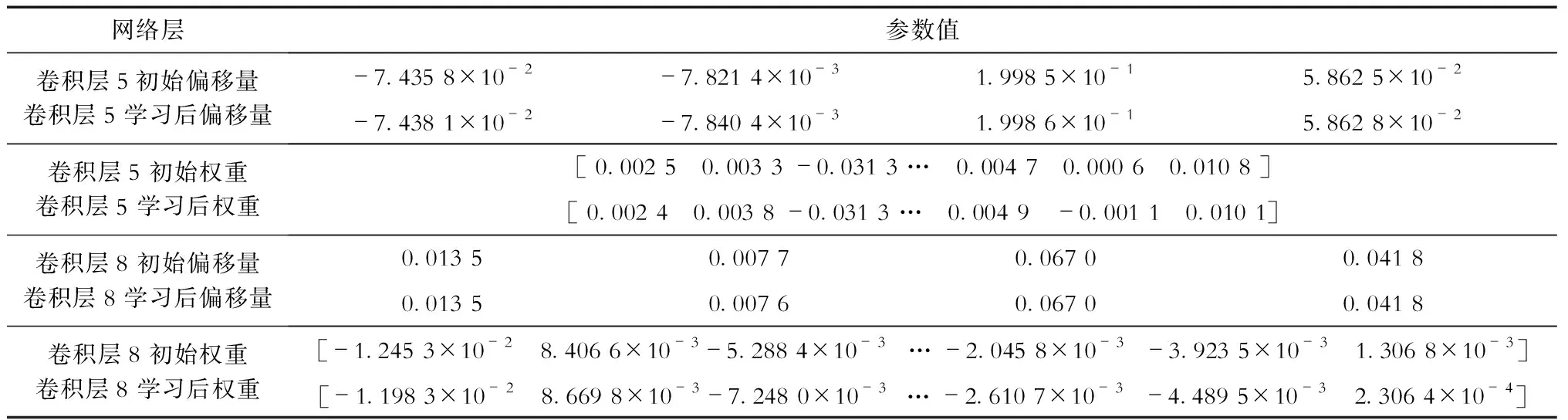
表1 迁移学习前后部分网络参数的变化Tab.1 Changes of some network parameters before and after transfer learning
2.2 杆塔检测
将由VGG16网络进行特征提取生成的杆塔特征图送入Faster R-CNN的区域生成网络(region proposal network,RPN)进行进一步处理。此网络分为2部分,分别使用softmax分类器的分类层和微调候选框的回归层。经过RPN的卷积层和池化层处理得到的特征图,每个特征点都被配备了k个锚,具有3种长宽比{1∶1,2∶1,1∶2}和覆盖整个输入特征图。下一步使用softmax分类器对每个锚进行二分类判断,判断是目标还是背景。VGG16网络输出的特征图中每个特征点经二分类之后转化为2k个目标和背景的得分值。结合锚和softmax分类得到的候选框与正确的边界框存在一定的偏移量,用中心点坐标和长宽偏移表示为:
(5)
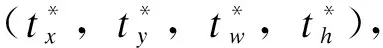
(6)
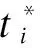
(7)
最后一部分采用全连接层和softmax分类器处理RPN网络生成的包含候选区域的特征图,计算特征图中每个候选区域属于哪个类别并输出其概率,同时再次使用回归层微调候选区域边界框,得到最终的目标检测框。
3 实验结果
3.1 模型训练
原始图像和增广后的数据集规模见表2。将191张原始图像和3 706张增广后图像,按7∶3分为训练集和测试集训练2个模型,训练模型时的学习率均设置为0.001。因原始图像数量较少,批量训练图片数量设置为64,增广后的数据集为256,迭代次数都为20 000次。

表2 数据集规模Tab.2 Dataset size
3.2 杆塔检测性能
VGG16迁移学习原始图像集训练后的模型称为A模型,VGG16迁移学习增广图像集训练后的模型称为B模型,下面对2个模型在测试集上的检测结果进行比较。首先根据网络输出的检测精确度计算得到A模型和B模型检测杆塔的精度均值分别为52.7%和90.5%;其次,采用精确率和召回率进行评价,即将检测结果按照正确检出与否进行分类统计,其中:正确检出杆塔的数量记为TTP,误检的数量记为TFP,漏检的数量记为TFN,按照式(8)、(9)计算精确率fprecision和召回率frecall:
(8)
(9)
根据式(8)、(9)计算可得精确率-召回率曲线如图4、5所示。由图4、5可以看出:A模型效果较差,精确率只有0.7左右,而召回率只有0.6;B模型在测试集上的精确率和召回率均接近1,说明B模型的误检率和漏检率都很低,B模型的检测效果具有较大幅度提升。
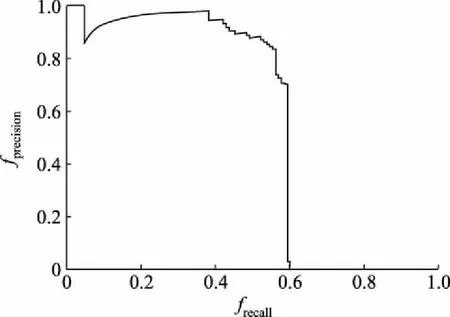
图4 A模型精确率-召回率曲线Fig.4 Precision-recall rate curves of model A
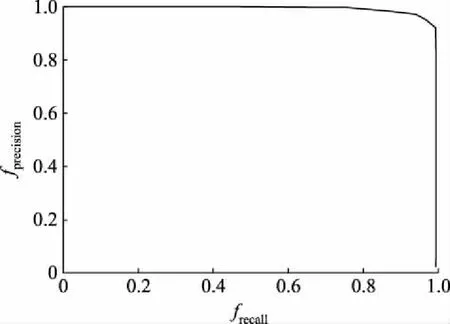
图5 B模型精确率-召回率曲线Fig.5 Precision-recall rate curves of model B
1张图像中通常会出现多个杆塔,在检测结果中,有些图像中的杆塔能全部正确检出,有些图像则只能部分检出,或存在误检。在下面的统计中,设全部送检的图像总数为I、杆塔全部正确检出的图像数量为I1、部分正确检出的图像数量为I2及存在误检的图像数量为I3。
式(10)用来计算I1、I2、I3在送检图像总数中分别所占的比率p1、p2和p3,统计结果见表3。

表3 A模型及B模型检测结果对比Tab.3 Comparison of test results between model A and model B
(10)
从表3可以看出:A模型的检测结果中,p1仅为32.8%,而p2和p3高达62.1%和5.2%,说明有大量未完全正确检出的图像,特别是存在漏检的图像数量超过了总图像数的一半;B模型的检测结果中,p1提升为97.8%,而p2和p3仅为1.8%和0.5%,误检和漏检的情况明显改善。
一些检测结果的图例被列在图6中。由图6可以看出:左侧的A模型检测出的结果中,图例1和图例5的边界框回归效果差,包含了许多图像背景,图例3和图例4漏检和误检现象较为严重,一些尺度较小的杆塔未被检测出,准确度不高;而右侧的B模型能检测到多种尺度的杆塔(如图例1和图例3所示),小尺度杆塔被准确检测,图例5中背光模糊的杆塔也被检测出;并且B模型的边界框定位的准确度明显高于A模型,更准确地给出了杆塔在图像中的位置。由此可见,增广图像集训练后的模型可以更充分地学习到杆塔的浅层特征和深层特征并加以融合,提高了对图像中多尺度目标的检测准确度,降低了漏检和误检概率,增强了模型的泛化性。

图6 A模型和B模型检测效果对比图Fig.6 Comparison of inspection effects between model A and model B
4 结束语
文章提出了一种基于深度学习网络的输电杆塔智能检测算法,即将VGG16网络作为Faster R-CNN深度学习框架的特征提取器。该算法首先使用锐化、旋转、镜像的方式大幅扩充杆塔图像数据集,然后基于ImageNet图像库分类任务的迁移学习对VGG16网络进行参数调整。实验结果表明:文章所提算法提高了精度均值、精确率-召回率和正确检出图像数量等多个性能评价指标,对于1张图片中包含多个不同尺度杆塔具有良好的检测效果,对背光和模糊图像的检测也有较好的效果。
猜你喜欢
卫星应用(2022年1期)2022-03-09 06:22:30
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
电子制作(2019年11期)2019-07-04 00:34:36
电子制作(2018年19期)2018-11-14 02:37:08
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
自动化学报(2017年11期)2017-04-04 02:52:58
电测与仪表(2016年23期)2016-04-12 00:23:14
噪声与振动控制(2015年4期)2015-01-01 07:08:21
电视技术(2014年19期)2014-03-11 15:38:20
