
基于CNN-BiGRU模型的操作票自动化校验方法
2020-10-23 01:55周达明李黎
广东电力 2020年9期
周达明,李黎
(华中科技大学 电气与电子工程学院,湖北 武汉 430074)
操作票是智能变电站中支线、开关或变压器进行投运、检修与备用等操作的基本凭证,对变电站操作票进行校验是保证上述操作准确无误的关键步骤。当前操作票的校验方法主要是基于待操作任务人工检查操作票的操作对象与拟票逻辑,然而人工校验存在诸多问题:①在智能变电站中,二次设备待投退软压板数目繁多,不存在肉眼可辨的电气断点,检验人员无法直观地辨析设备关联结构,人工判定拟票逻辑时易造成压板投退的错判或漏判;②人工校验极大地依赖于校验人员的经验判断,校验结果存在一定程度的不确定性,导致后续操作可靠性的下降;③人为进行操作条目校验效率低下,不利于变电站的智能化发展。因此,实现智能变电站中操作票的高精度自动化校验势在必行。
目前智能变电站中操作票自动化校验方法的核心思想是构造专家系统,即通过罗列正确的校验规则构造知识库,并将票内文本条目处理为逻辑语言输入推理机完成校验[1-2]。由于操作票文本结构性较弱,为保证校验精度,知识库中的校验规则势必穷举,这一方面导致规则相似度高,另一方面存在遗漏规则的可能,同时文本转化为逻辑语言的过程人为干预度高,方法自动化程度偏低;因此,在保证操作票校验精度的基础上,减少校验方法的人为干预度,提高检验方法的泛化能力是自动化校验方法的发展方向。
操作票校验正误本质上是票中文本二分类问题,流程包括文本分词、文本的向量化、特征向量值提取与分类判定。文本分词通常在文本各汉字可能成词的有向无环图中进行最大概率路径规划,进一步切分文本[3];文本的向量化通常基于文本各词语在词典中的索引值进行向量化处理[4];特征向量值是提取借助特征值函数来计算典型向量值[5-6];分类判定常选用机器学习模型,包括决策树[7-9]、贝叶斯分类器[10-11]、支持向量机[12-13]等。然而基于词索引值的文本向量化手段语义映射困难,且向量高维稀疏,计算量大;而大部分特征值函数与分类模型过于局限,泛化能力偏弱,分类精度不够高[14]。
深度学习理论框架是有效融合了特征向量值提取与分类预测的多层次神经网络深度耦合的结构,常用的核心网络层主要包括卷积神经网络(convolution neural network,CNN)与循环神经网络(recurrent neural network,RNN),其中RNN包括长短期记忆(long short term memory,LSTM)神经网络与门控循环单元(gated recurrent unit,GRU)神经网络。相比一般机器学习模型与浅层全连接神经网络,基于深度学习理论框架构造的深层神经网络针对向量特征值的挖掘更为全面与典型,分类精度更高,目前已有许多将其应用于电力系统的研究:文献[14]利用循环卷积神经网络(recurrent convolution neural network,RCNN)模型成功实现对变压器运维文本的语义分析,从而进行变压器故障诊断;文献[15-16]分别基于双向LSTM与CNN模型分析变压器文本数据,实现了对变压器运行状态的评估;文献[17-18]基于注意力机制与纵横交叉算法改进后的CNN实现电网负荷预测,提高了预测精度。
本文首先基于智能变电站全站配置描述(subsubstation configuration description,SCD)文件相关信息,在操作票中写入设备关联关系,并利用词向量分布式表达模型word2vec进行文本向量化,在向量中映射文本语义关联信息;然后基于深度学习理论构造具有CNN和双向门控循环单元(bidirectional gating recurrent unit,BiGRU)神经网络结构的操作票正误校验模型;最后,通过算例对基于CNN-BiGRU深度文本挖掘模型的智能变电站操作票校验方法的正误校验准确度进行验证。
1 智能变电站操作票文本处理
1.1 智能二次设备关联关系的获取
智能变电站中,智能电子设备(intelligent electrical device,IED)之间使用采样值报文(sampled value,SV)或面向对象的变电站事件报文(generic object oriented substation event,GOOSE),报文经由光纤进行信息传输,其关联关系包含在SCD文件中,文件由变电站配置描述语言(substation configuration description language,SCL)撰写,结构包括标签、子标签及标签属性,其中IED标签囊括了与该IED相连的所有其他设备,本文利用Python3中的xml.etree.ElementTree模块解析SCD文件并获取单个IED所有发送与接收关联设备,IED关联关系解析如图1所示。
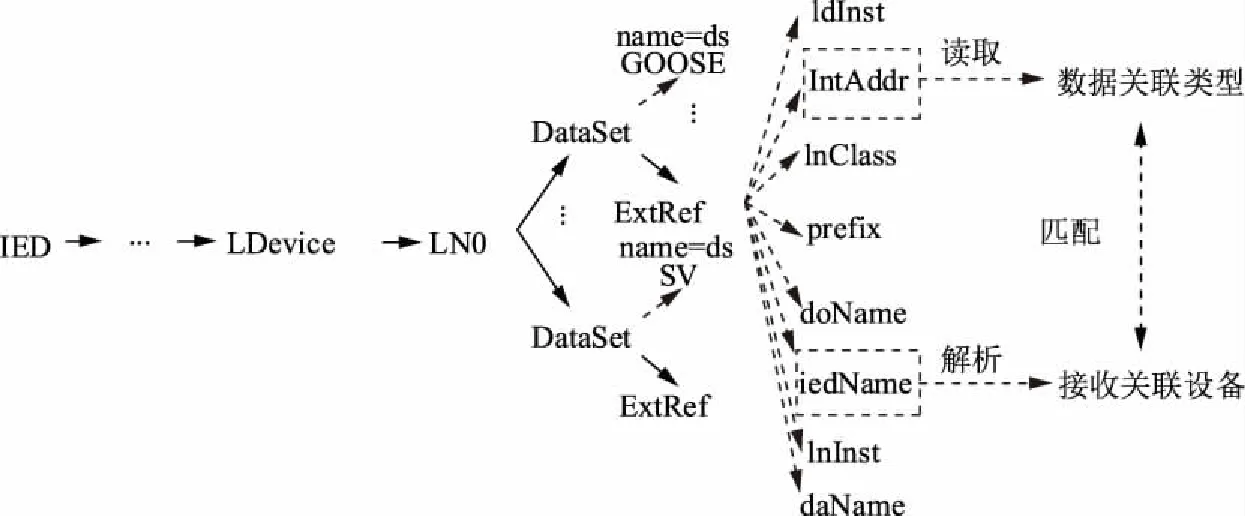
图1 IED关联关系解析Fig.1 Analysis of IED’s connection relationship
以某IED(iedName赋值为a)为例,遍历其他IED标签中DataSet标签,查找其子标签ExtRef中iedName是否包含a,以获取接收关联设备为a的IED,这些设备即为设备a的发送关联设备;遍历a所有ExtRef中的iedName以获取a的接收关联设备。intAddr属性描述了发送与接收报文的逻辑地址,据此可判定报文类型,所有IED均实行上述操作,可得各自的关联设备。获取关联设备后,操作票单项任务后将写入这些关联设备名称,例如操作命令与某支线相关时,操作条目后将写入该支线智能终端的GOOSE信号发送/接收设备与合并单元的SV信号发送/接收设备。
1.2 操作票文本内容与特征
与常见中文文本相比,智能变电站操作票文本有3个显著的特征:①文本专业性强,票中各条目常常出现各种专业名词,这些名词需要事先导入分词模块保证文本分词的准确性;②文本结构性偏低,由于拟票人的主观理解与语言组织能力有区别,不同变电站类似操作可以有不同的表述,导致传统的语义信息挖掘技术如命名实体识别等应用受限;③文本各条目间遵循严格的执行顺序,条目具体内容与操作任务相关联的各设备关联关系密切相关,在进行语义分析时需充分考虑。
1.3 操作票文本的向量化
常用的基于词典索引值表示的词向量是利用各词组在词典中的索引值构造的词向量,各词组的词向量仅将数值“1”赋予该词的索引值维度,其余维度均赋值“0”,该方法无法映射词组间的语义关联关系,且向量过于稀疏,计算量较大。由Miklov等人[19-20]构造的word2vec模型针对词典索引值表示的词向量进行了改进,其利用语义文本框依序选定局部文本,并将上述文本的词向量输入精简后的BP神经网络,以最大化文本框内待求向量词的出现概率为目标训练网络权重值,最后基于权重值求解能有效反映语义关联紧密度的低维稠密词向量,单句文本可表达为M×N的向量矩阵,其中M为句长,N为单个词向量的维度。
本文将待训练语料基于词典索引值表示的词向量输入word2vec,并输出N=64的词向量。随机选取2段条目样本中的部分词向量为例,将其基于主成分分析法降维至三维语义空间,并以其坐标间的几何距离作为语义关联紧密度,得到关联度对比见表1,2个词向量i与j的关联紧密度βij计算如式(1)所示,其中Lmax为所有选择词间的最大几何距离,可见源于同一条目文本的词向量语义关联紧密度高,空间中的几何距离较短,不同条目文本间的词向量紧密度则偏低。相比词典索引值求取的词向量,经过word2vec处理所得的词向量更能体现词间的语义关联关系,从而更好地适用于下游判定任务。
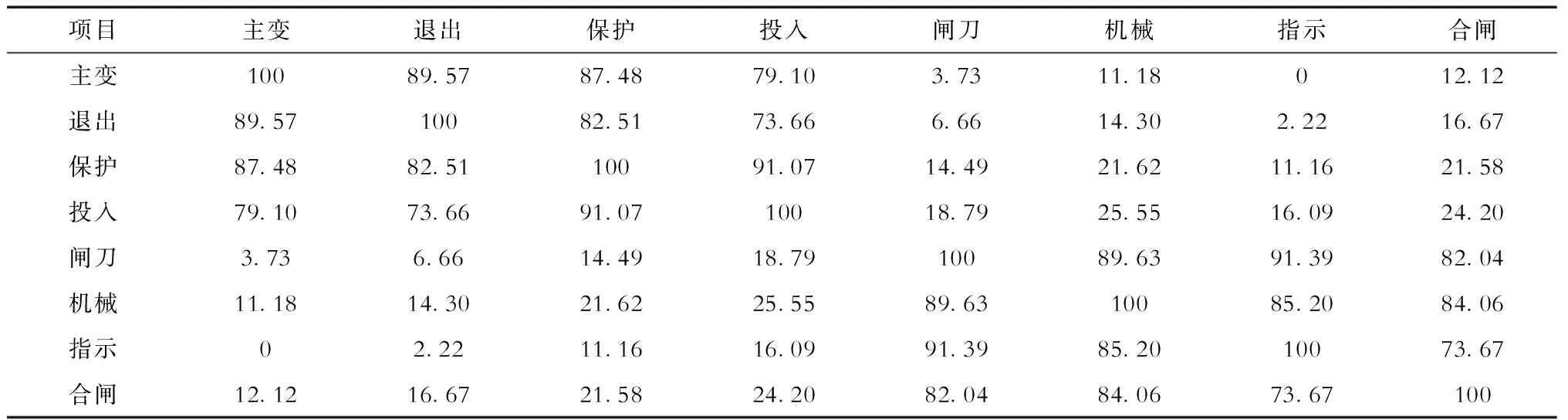
表1 词向量关联紧密度对比Tab.1 Comparisons of tightness between different word vectors %
(1)
式中:xi、yi、zi为词向量i经主成分分析法降维后的三维坐标值;xj、yj、zj为词向量j经主成分分析法降维后的三维坐标值。上述词向量所在的原始样本文本包括“退出投入#1主变第一套主变保护差动保护投入软压板,并检查。”以及“检查某支线线路闸刀机械位置指示在合闸位置。”
2 智能变电站操作票文本挖掘模型
在深度文本挖掘模型中,CNN可以利用卷积核针对文本矩阵进行赋权求值,有效挖掘局部语义信息点,但是由于卷积层利用一定尺寸的卷积核框定确定数目的词向量进行卷积操作,无法考察长距离词向量间的语义依赖关系;RNN中各神经元均引入了记忆机制,词向量值与上一个神经元输出值均能输入下一个神经元,从而保证网络对前后词依赖关系的有效储存,然而文本序列过长容易出现长期依赖与梯度爆炸的问题。鉴于此,本文提出基于CNN-BiGRU的智能变电站操作票文本挖掘模型,在利用CNN实现局部语义信息点捕捉的基础上考察序列依赖关系,从而实现语义的高效挖掘与分类判定。
2.1 基于CNN-BiGRU的文本挖掘模型
基于CNN-BiGRU的文本挖掘模型如图2所示,包括输入层、CNN层、BiGRU层、池化层与全连接层。
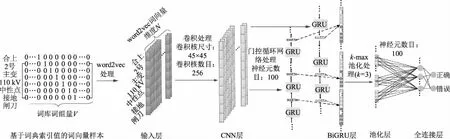
图2 智能变电站操作票文本挖掘模型Fig.2 Text mining model of intelligent substation operation ticket
输入层为操作票中单句条目的词向量矩阵,由word2vec模型输出,在后续CNN与BiGRU层作用时词向量相对位置保持稳定,象征原始样本中词组序列保持不变。
CNN层中,卷积核是实现卷积操作的基本单元,其表现为具有特定权重值的矩阵。各卷积核对框定词向量进行的卷积操作,指的是对不同词向量值进行赋权求和加偏置,并利用非线性函数进行激活。设单个卷积核尺寸为p×q,待卷积处理的单个词向量值为xk,卷积层输出结果为c,模型偏置设为b,各卷积核计算过程为:
(2)
(3)
式中:wk为卷积核中对输入词向量所赋权重值;xk为卷积核框定区域内的单个词向量值。
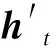
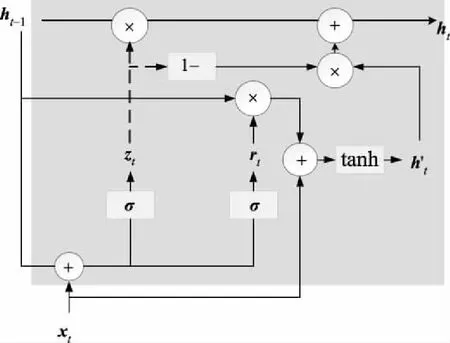
图3 GRU结构Fig.3 GRU structure
(4)
式中:σ为sigmoid函数;xt为输入数据;Wr、Wz、Wh分别为重置门、更新门与本神经元隐状态对输入数据所赋权重值,br、bz、bh为对应的偏置;Ur、Uz分别为重置门、更新门对上一神经元传递隐状态数据所赋权重值;Uh为本神经元输出隐状态对本神经元内隐状态数据ht与上一神经元传递隐状态数据的Hadamard乘积所赋的权重值。上述参数均随着模型训练而不断更新。
BiGRU层基于正反2层GRU神经网络构造,各层GRU分别以文本序列的首尾两端点值作为网络输入的起始点,依序正反向输入,通过双向输入文本加强网络挖掘语义的能力,从而有效获取词向量前后文的依赖关系。最终各单向GRU层输出向量值拼接形成BiGRU层输出向量。
池化层采取k最大池化(kmax-pooling)方法针对输入向量进行特征值提取,通过池化可固定输出向量维度,获得输入向量中代表能力最强的向量值。若输入向量为x=(x1,x2,…,xn),则输出向量
y=(x1,x2,…,xk),
(5)
其中
xi∈{x1,x2,…,xn},i∈{1,2,…,k},
x1≥x2≥…≥xk≥xk+1≥…≥xn.
全连接层接收池化层输出,并进行赋权、加偏置、与非线性激活,非线性激活函数选取σ函数如式(3)所示,全连接层输出向量判定为“正确”与“错误”2个类别的概率,最终以概率大者作为输入样本判定结果。
2.2 文本挖掘模型性能评定指标
在文本二分类判定任务中,准确率P用于形容判定为正例的样本正例数目TP占所有判定正例数目的比值﹝式(6)﹞,其中,判定为正例的样本反例数目FP决定了模型判定付出的代价,FP越小,模型对错误操作票的辨识能力越强,而对于错误操作票的零容忍是校验工作的底线,因此高准确率表征了校验模型可靠性的下限。
(6)
召回率R则表示判定为正例的样本正例数目TP占所有样本正例数目的比值﹝式(7)﹞,判定为反例的样本正例数目FN越小,模型对正确操作票的辨识能力越强,当正确操作票能够尽可能地通过校验时,运维人员纠正错误操作票的时间会大大减少,校验效率能够有效提升,这是校验工作的高要求,因此高召回率表征了模型校验可靠性的上限。
(7)
本文选取的常用二分类模型评估指标Fscore是模型准确率与召回率的调和平均值,从模型可靠性的上下限2个角度综合评估模型性能,其计算表达式为
(8)
评测指标关联关系见表2。由上述计算式可知,准确率与召回率的理想峰值均为100%,因此当Fscore越接近100%,模型综合校验性能越强。

表2 评测指标关联关系Tab.2 Correlation between evaluation indicators
3 算例分析
为了验证本文操作票正误校验模型的校验能力,选取某3个变电站共1 010条实例操作票样本,各样本的文本描述完整准确,基于正确样本随机错序排列操作条目或删改部分描述,构造负例样本1 175条,样本总数为2 185条。将样本按8∶1∶1的比例分为训练集、验证集与测试集,训练集用于训练模型参数,验证集用于防止模型过拟合,测试集用于评估模型校验正误的能力。单个操作票样本举例如下:
“110 kV桥开关由运行改为热备用(停#1主变)
人工操作:
合上#1主变110 kV中性点接地闸刀,并检查
将遥控总开关QK由“调度允许”切至“调度禁止”位置,并检查
执行顺序控制{110kV桥开关由运行改为热备用(停主变)}操作任务
检查110 kV桥开关无电流
拉开110 kV桥开关
检查110 kV桥开关在分闸位置
顺控结束,核对以上操作监控后台设备状态正确,执行以下人工操作:
检查110 kV桥开关位置指示在分闸位置
检查110 kV桥开关机械位置指示在分闸位置
将遥控总开关QK由“调度禁止”切至“调度允许”位置,并检查
拉开#1主变110 kV中性点接地闸刀,并检查
GOOSE关联关系:110 kV内桥测控;110 kV备自投保护;#1主变保护A;#1主变保护B;#2主变保护A;#2主变保护B。
SV关联关系:110 kV I段母线合并单元;110 kV Ⅱ段母线合并单元。”
模型采用Python语言编程,并采用Tensorflow工具包高度集成模块keras构造CNN-BiGRU模型,CPU为Intel Core i7-3537U,主频2.0 GHz,模型超参数设置见表3。
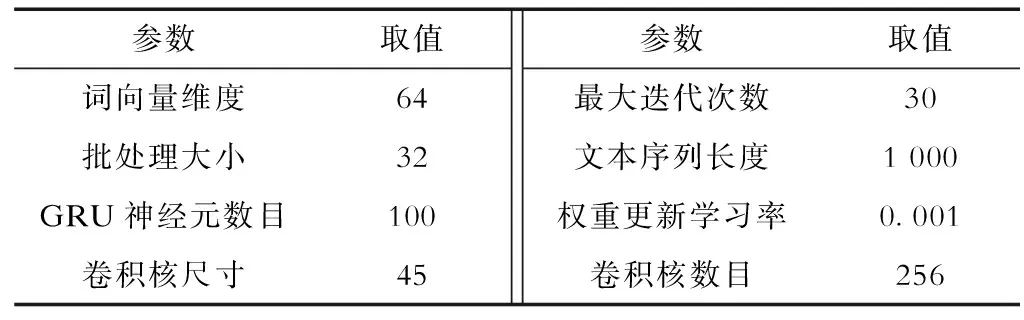
表3 模型超参数设置Tab.3 Model hyper parameter settings
基于上述超参数构造的操作票校验模型训练集、验证集与测试集宏评估综合指标Fscore的对比如图4所示。随着迭代次数增加,训练集、验证集与测试集Fscore逐渐收敛,最终训练集Fscore为97.01%,验证集Fscore为96.77%,验证集Fscore为93.07%,波动幅度在3%之内。
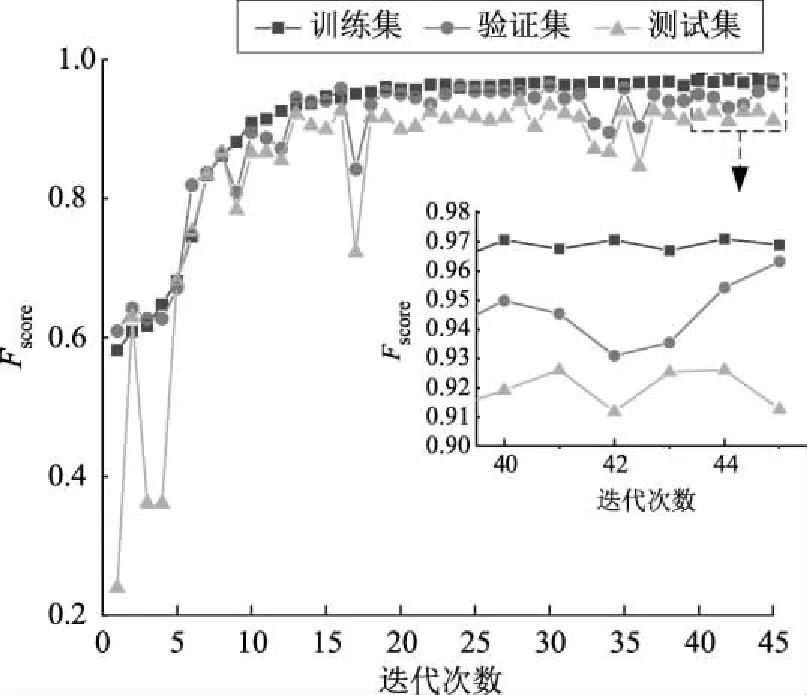
图4 CNN-BiGRU模型性能综合分析Fig.4 Comprehensive analysis of CNN-BiGRU performance
在本文关注的操作票校验任务中,影响判定精度的关键模型参数主要为卷积核数目(kernal_number)和批处理样本数目(batch_size),卷积核数目值直接决定后续GRU神经网络提取局部语义时序依赖关系所考察样本的规模,批处理样本数目极大地影响了模型权重单次迭代更新速度与精度。本文结合样本规模并参考常见卷积核数目与批处理样本数目设置值,分别设置了3组不同卷积核数目(kernal_number为128、256、512)与不同批处理样本数目(batch_size为16、32、64)的对照组,实验结果如图5所示。可以看出:当卷积核数目为512、批处理样本数目为32时,模型收敛速度较快,Fscore最高可达95.23%。
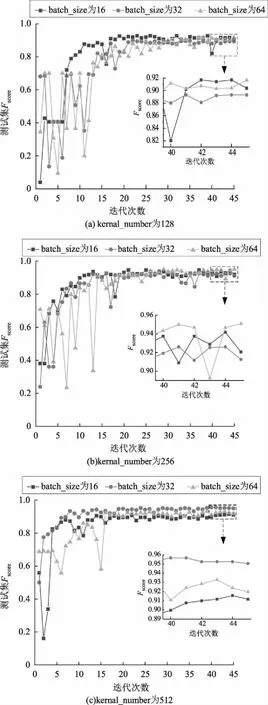
图5 CNN-BiGRU模型对照组实验结果对比Fig.5 Comparison of CNN-BiGRU models with different hyper parameters
此外,BiGRU层的神经元数目一定程度上影响了语义依赖关系的辨析能力。本文在确定训练批次样本数目与CNN层相关参数基础上,设置了BiGRU层的GRU神经元数目为10、100与200的3组对照组,实验结果如图6所示。可以看出:神经元数目偏少时,语义挖掘能力一定程度地被削弱;神经元数目增多时,模型过于复杂,过拟合现象严重,测试集精度不高。因此,最终确定模型的BiGRU层神经元数目为100。
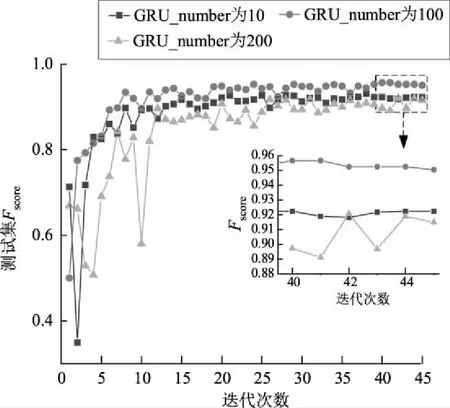
图6 GRU神经元数目对照组实验结果对比Fig.6 Comparison of CNN-BiGRU models with different GRU numbers
为体现CNN-BiGRU深度文本挖掘与正误判定模型的优越性能,本文选取5种典型常用文本挖掘浅层神经网络进行对照,包括LSTM、双向LSTM(BiLSTM)、GRU、BiGRU以及多层感知器(multilayer perceptron,MLP)。其中:LSTM、BiLSTM、GRU、BiGRU中神经元数目与本文BiGRU层保持一致,取100;MLP中全连接神经元数目与本文全连接层神经元数目保持一致,取100。上述模型均基于训练集与验证集更新模型参数,利用测试集Fscore进行评估。文本向量化方法均采用word2vec模型,实验结果见表4。可以看出:CNN-BiGRU模型无论收敛速度还是训练精度均明显高于其他模型,文本挖掘能力优异。
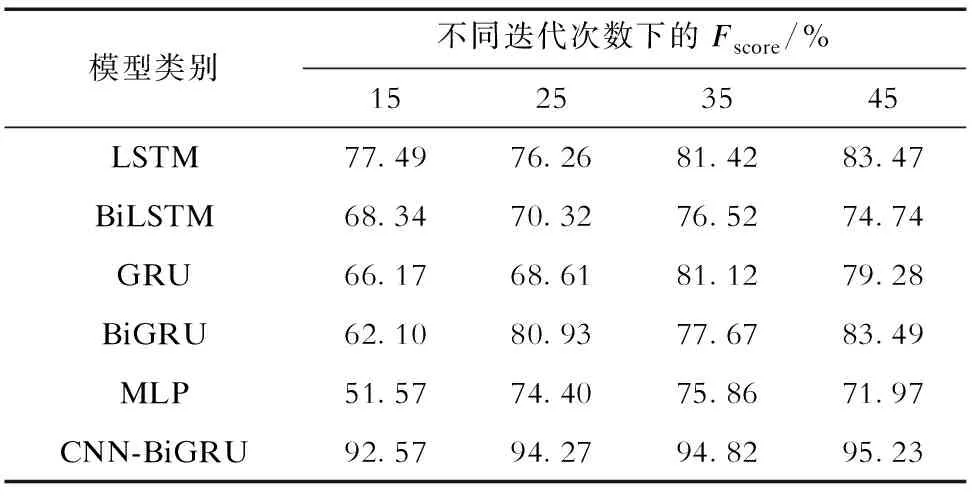
表4 各文本挖掘模型在测试集上的Fscore对比Tab.4 Fscore comparisons of text mining models on test set
4 结束语
本文针对智能变电站中操作票人工校验效率低、可靠性不高的现状,提出了基于CNN-BiGRU深度文本挖掘模型的操作票自动化校验方法:首先采用CNN层提取局部文本特征值,进行一定范围内的短文本语义挖掘;然后将提取特征量输入BiGRU层,从正反双向考察长距离文本间的依赖关系;最终通过训练文本挖掘模型实现对操作票文本的深度语义分析与正误判定。实例分析结果表明,该方法校验评估指标Fscore高达95.23%,模型性能优异,有效提高了操作票自动化校验的效率与准确性。
猜你喜欢
中学生学习报(2022年15期)2022-04-17
新世纪智能(数学备考)(2021年9期)2021-11-24
小猕猴智力画刊(2021年6期)2021-08-05
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
中国铸造装备与技术(2017年6期)2018-01-22
电子制作(2017年1期)2017-05-17
读者(2017年5期)2017-02-15
中国民族医药杂志(2016年5期)2016-05-09
作文大王·低年级(2016年3期)2016-03-11
