
基于TensorFlow的并行化FBP方法
2020-10-23 07:48:04朱炯滔
数字制造科学 2020年3期
朱炯滔,王 成
(武汉理工大学 机电工程学院,湖北 武汉 430070)
计算机层析成像(CT成像)是医学影像领域一种十分重要的成像方法,该方法可以有效地反映人体内部的组织结构、组成成分等信息[1-2]。深度学习技术的迅猛发展为CT成像带来了新的机遇。2017年,BoZhu等[3]提出了在神经网络中构建全连层来学习医学图像中的重建算法,但构建全连接层必然会产生规模庞大的神经网络参数,运行时不仅对计算资源消耗巨大还会增加时间成本[4]。针对上述问题,笔者提出一种支持GPU(graphics processing unit)并行化计算的FBP(filter back projection)方法,该方法在深度学习平台Tensorflow下实现。
1 相关技术介绍
1.1 TensorFlow
TensorFlow是由Google DeepMind团队开发为机器学习和深度学习提供支持的一种开源软件平台[5],其具有高度的可移植性,用户可以轻松地将其部署在多种计算设备上。相对于市面上其他的深度学习框架,TensorFlow在性能、通用性、灵活性、语言支持等方面都具有较大的优势[6]。TensorFlow使用数据流图进行数值计算,节点(OP)表示数学操作,线则表示节点间相互联系的张量(tensor)。TensorFlow也开放了自定义的OP编程接口,用户可以根据自己的需求来添加数学函数。鉴于TensorFlow具有以上优点,笔者提出了在TensorFlow平台上并行化FBP实现方法。
1.2 FBP算法
滤波反投影算法(FBP)是一种经典的CT图像重建算法,该算法兼顾了重建质量和重建时间两个CT性能指标,是目前应用最广泛的CT重建算法[7]。因此使用支持GPU并行化计算的FBP方法具有重要的现实意义[8-9]。
2 FBP过程并行化实现
2.1 FBP算法的并行化计算分析
FBP算法的投影几何如图1所示,SO为X射线源,SOP为中心射线,点O为旋转中心,中心线向两端的张开角度都为γm,锥形的位置由中心射线SOP与y轴的夹角β决定,同一锥形中的任意射线SOE都可由转角γ确定。因此在笛卡尔坐标系中,射线的位置可由(β,γ)唯一确定。
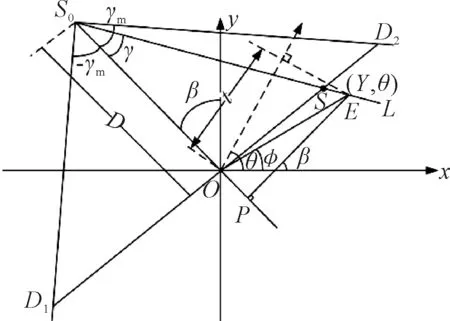
图1 投影几何示意图
设点E为重建图像内任意一点,极坐标为(r,φ),f(r,φ)为该点的像素值,pβ(s)为穿过该点像素的射线在探测器上的投影。FBP重建公式为:
(1)
算法的实现步骤分为三步执行:
(1)对投影函数进行修正,以校正投影偏移值。若探测器间距为Δd,则:
pβ(s)=pβ(nΔd)
(2)
Δd=dm/N
(3)
(4)
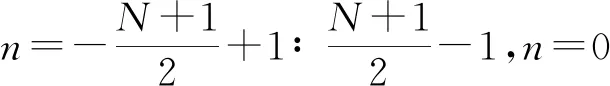
(2)对投影图进行卷积滤波。
(5)
式中:h(nΔd)为卷积函数,选用Ramp滤波函数。
(3)反投影,重建图像。在360°下共采集M个投影数据,即数据的采集步距为Δβ=2π/M,对应的离散重建表达式为:
(6)
式中:
(7)
(8)
设在360°角度下,采集投影个数为M,每个投影的采样点个数为N,重建图像大小为n×n,执行的伪代码如下:
修正阶段:
for x=0:N
for y=0:M
根据式(4)对每个点进行修正计算
end
end
卷积滤波阶段:
for y=0:M
根据式(5)进行卷积
end
反投影阶段:
for β=0:M-1
for x=0:n
for y=0:n
根据式(7)计算n,n差值取整,根据式(8)计算U。
end
end
end
由伪代码可知,在图像重建的3个阶段中,计算结果相互独立,算法具有明显的并行化能力,因此适合使用GPU进行加速计算。
2.2 TensorFlow平台下FBP并行化实现
FBP的并行化基于NVIDIA厂商推出的CUDA平台实现。FBP算法的重建过程如下:主机端将投影数据传入GPU显存当中并设置块(block)和线程(thread)的数量,因本实验中需要处理512×512大小的二维图像,故设置块数量为64×64,每个块包含的线程数量为8×8,即GPU一次可以对512×512个像素进行重建计算。然后GPU的处理器调用重建函数(kernel)进行计算,计算完成后将再将数据传回主机端内存。至此,FBP算法的实现方法为:①设备初始化,分配内存和显存。②设置block、thread。③设置投影角度数n。④主机将Projection按投影角度分批传入GPU显存中。⑤GPU对当前角度下的投影数据进行FBP。⑥GPU将Image传入主机内存。
使用系统自带的C++或者clang编译器将FBP重建代码编译为Linux系统下的动态链接库。然后使用TensorFlow的Python接口调用动态库将FBP重建算法作为一种新的数学操作(OP)注册到TensorFlow平台[10]。
3 实验结果分析
3.1 实验平台
实验PC采用的配置为Intel Core i7-4790(3.6 GHz)处理器,8 G内存,NVIDIA公司的GeForce GTX 1070 8 G显卡、运算能力6.1。操作系统Linux16.04,TensorFlow版本1.6。
3.2 重建算法运算结果分析
实验选取人体腹部组织第1、第50、第100、第150张的切片投影图进行重建,重建尺寸为512×512,重建图像如图2所示。其中,输入正弦图为设备扫描后的投影图像,并且正弦图在TensorFlow平台下进行图像重建。
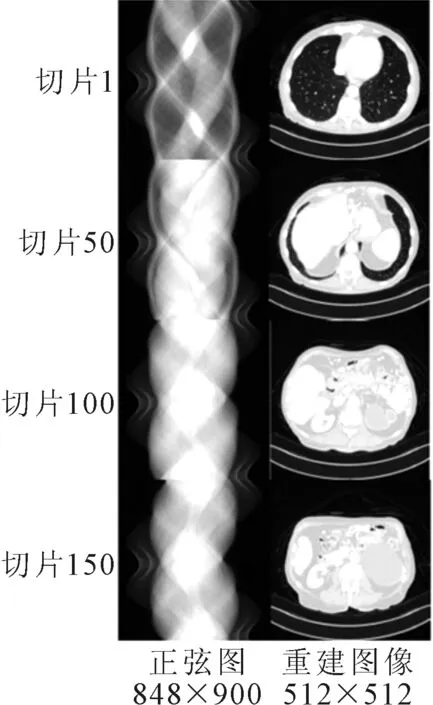
图2 512×512重建图
为了测量图像在网络训练过程中的图像重建速度,使用了Python自带的计时器函数time.time()进行FBP重建计时,该方法可以将GPU与内存交换数据的时间计算在内,提高了计时的准确性。FBP运行时间如表1所示。

表1 FBP运行时间
使用GPU进行FBP重建的方法属于硬件加速法,其运行性能不受计算数据的影响,由表1可以看出GPU在重建人体不同部位所需时间稳定且重建速度快,满足实际的使用需求。
3.3 网络的优化效果分析
GPU中显存的作用主要用来存放网络参数和计算数据,显存越大可以搭建的网络也就越大,其在GPU中的作用类似于内存。神经网络参数存储在显存中的数据类型主要为单精度浮点型(float),在GPU中占用4个字节(Byte)。
神经网络中全连层的每一个节点都与上一层的所有节点相连,用于提取上一层的所有特征。若使用全连层将848×900的投影数据重建出512×512的图像需要200 068,300 800个浮点数据,占用约745.3 G大小的显存空间,远超出所使用显卡的8 G显存。因此,参考文献[3]中提出的AUTOMAP网络,采用AUTOMAP网络引用全连层来进行图像重建,网络结构如图3所示。使用添加FBP算法的网络如图4所示。
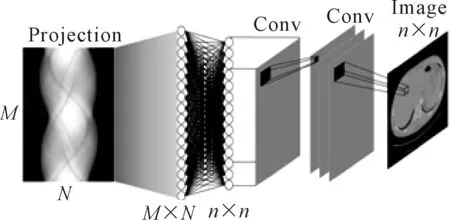
图3 AUTOMAP网络
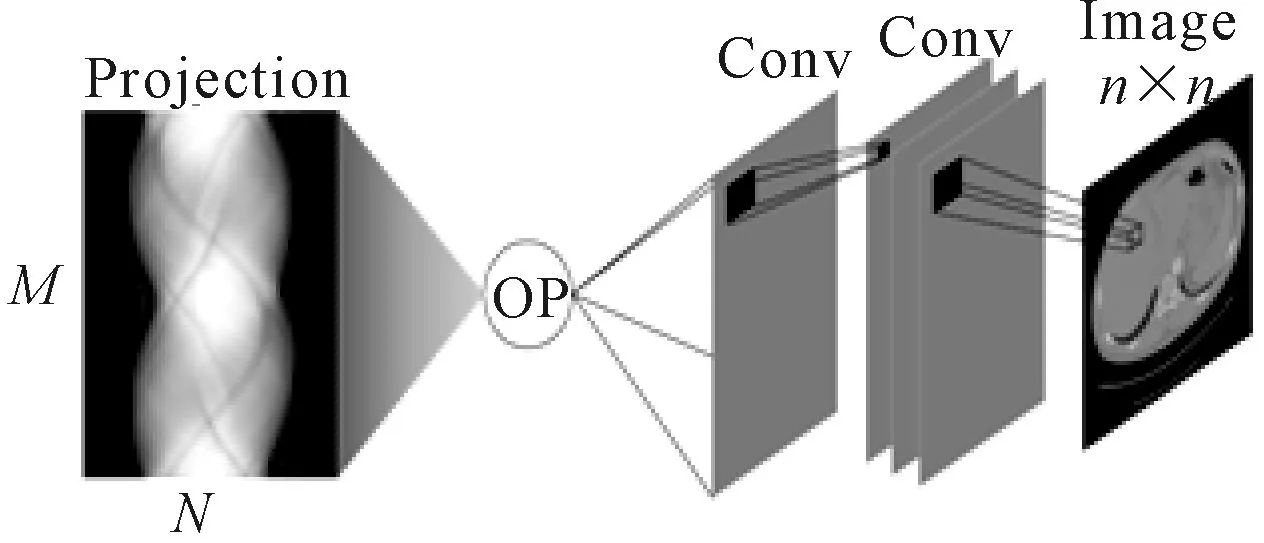
图4 自定义OP网络
图4使用OP网络相较于图3中的全连层网络,可以节省出大量的网络参数,减少GPU的运算负荷进而提升网络的训练速度。以本论文中的数据为例,图4中的OP只需要申请848×4个字节的单角度投影空间和512×512×4个字节的重建图像空间,共计约1 M的显存空间即可完成重建任务。使用市面上销售的普通显卡即可运行该网络,相对比文献[3]中使用两块NVIDIA P100(市面售价3.5万)显卡进行图像重建,节省了大量成本。
3.4 运算结果分析
为了对GPU的加速性能进行更直观的对比,采用文献[11]中提供的开源CPU重建代码,分别对重建尺寸为256×256和512×512的CT图像进行加速对比。其中,GPU重建图像采用GPU并行加速处理的结果图像,CPU重建图像为CPU处理的结果图像。重建效果对比如图5所示。GPU和CPU的重建时间对比如表2所示。
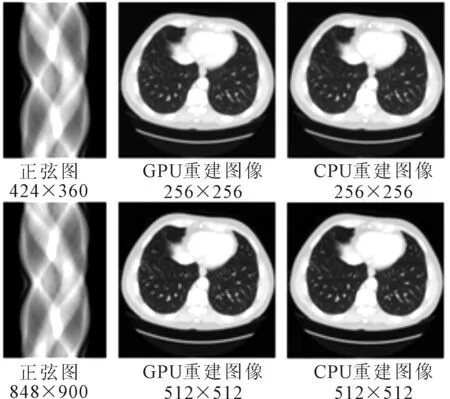
图5 重建效果对比

表2 重建时间对比
由表2可以看出GPU相对比CPU进行重建加速具有很好的加速能力,可以节省大量计算时间。
4 结论
以CT成像为研究内容,以支持GPU加速的并行化FBP方法为研究重点,借助深度学习的工具,提出了一种基于TensorFlow的并行化FBP方法。实验表明,该方法可以有效节省计算资源,降低时间成本和设备成本。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
数学物理学报(2021年1期)2021-03-29 03:14:42
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25 01:40:34
当代陕西(2019年13期)2019-08-20 03:54:22
电子制作(2019年11期)2019-07-04 00:34:38
学生天地·小学低年级版(2019年5期)2019-06-05 01:15:11
学生天地(2019年15期)2019-05-05 06:28:28
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电视技术(2014年19期)2014-03-11 15:38:20
测绘科学与工程(2014年5期)2014-02-27 07:06:14
