
改进AdaBoost 算法的WiFi 室内定位
2020-10-22 01:13:02张玉金
导航定位学报 2020年5期
贺 超,吴 飞,张玉金,朱 海
(上海工程技术大学 电子电气工程学院,上海 201620)
0 引言
随着社会的进步和科技研发能力的迅速发展,基于位置的服务(location based service, LBS)业务需求也在不断增长。文献[1-3]借助太空中的卫星和地面基站的组合方式对室外场景进行定位与导航,为室外出行提供方便快捷的定位导航服务。但是,由于电磁信号的干扰与屏蔽,在室内无法通过此种方式进行室内导航。伴随着移动互联网的高速发展以及智能终端设备的普及,无线路由器广泛地应用在人们的室内生活场景中。因此,如文献[4-7]研究的利用无线保真(wireless fidelity, WiFi)指纹库的室内定位方式受到了研究人员的广泛关注。
国内外已经提出了很多基于WiFi 指纹库定位算法。常见的单一分类器算法的WiFi 指纹库定位算法有很多,如k 最近邻(k-nearest neighbor,KNN)、支持向量机(support vector machine, SVM)等。文献[8]中通过建立WiFi 离线位置指纹库,并利用KNN 算法实现室内定位,但是由于KNN 算法基于距离相似性准则进行判别,多轮的计算容易产生累计误差并降低定位时效性;文献[9]利用SVM算法进行WiFi 室内定位,但SVM 算法复杂度高,对于大规模数据的计算有一定的困难。
相比于单一分类器的决策分类过程,文献[10]采取自适应增强(adaptive boosting, AdaBoost)算法这种增强学习过程,对WiFi 定位数据进行有监督的学习分类,能够取得较好结果。但是,在实际的室内定位应用中,真实数据常常因为环境因素而夹杂较多难以处理的噪声和异常值。传统的AdaBoost 算法存在对于异常值较为敏感以及算子分类器的决策权重对定位结果影响大的问题。
基于此,本文提出基于改进AdaBoost 算法的WiFi 室内定位方法。主要过程如下:
1)通过1 种判决式特征选择机制,保证基分类器间的多样性,优化特征属性的权重,以提高算法整体的鲁棒性。
2)采用1 种联合投票决策方法,该投票决策结合子分类器自身的精度和特征属性权重信息,在提高预测结果的精确度的同时,更加切合不确定且多变的指纹库数据,可以提高模型的鲁棒性。
1 AdaBoost 算法
AdaBoost 算法[11]的主要思想是对于所搜集到的WiFi 接收信号强度信息(received signal strength, RSS)样本进行有监督的增强学习。训练集合为D = {( x1, y1) , ( x2, y2) ,… , ( xi, yi) ,… , ( xN,yN)},其 中 xi为RSS 样本的因子属性特征, yi表示定位所在空间坐标信息,作为标签变量,N为样本个数。在选定好弱分类器后,初始状态下,所有样本权重相等,根据AdaBoost 思想,不断串行迭代训练,并且在训练过程中,后1 个弱分类器将会着重训练被前 1 个弱分类器错分的样本,最终得到加权后的最终结果。
其主要流程如下:
1)输 入。( x1, y1) , ( x2, y2) ,… , ( xi, yi) ,… , ( xN,yN),其中 xi∈ X,且 yi∈ Y。
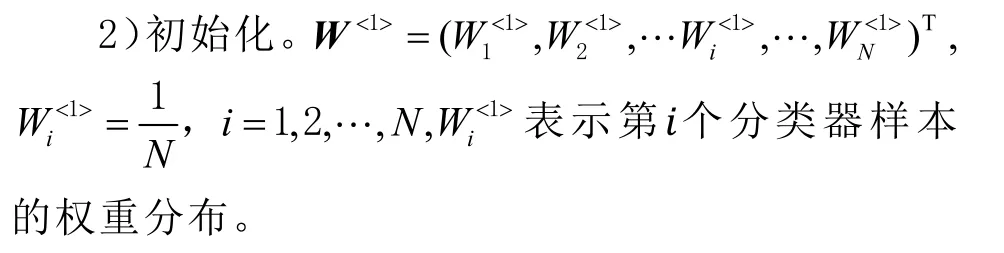
3)训练过程。for m in range(M):
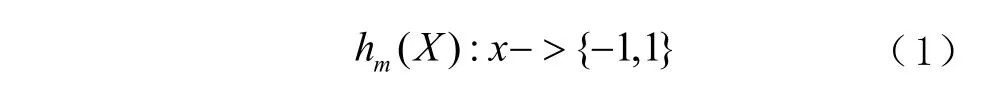
②通过 hm( X )在训练集上的效果,计算分类误差率,可表示为
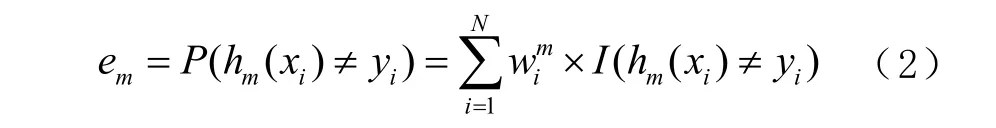
若分类误差率 em≥ 1/2,则算法提前停止,整体构建失败。
③为基分类器分配相应的构建权重系数,可表示为

2 改进AdaBoost 算法
为了保留随机采样阶段基分类器的多样性,减少异常值对模型决策权重的影响,本文算法分别对特征因子选择方式与投票决策集成机制进行了改进。
2.1 判决式因子选取
如文献[12]所述,随机子空间(random subspace method, RSM)树结构采样方法是在建立子分类器的过程中,从整个数据集中随机采样得到每个子树空间样本集的方法。实验表明,当数据样本数量足够大时,此种采样策略最终得到的分类结果精度要高于传统的AdaBoost 算法。但是,上述随机采样过程在多次采样的过程中,会出现有的样本被多次重复提取,而有的样本仅有少量的机会甚至未被在建模阶段采样,进而制约基分类器的多样性的问题。
受上述现象的启发,本算法采用判决式因子选择方式,力争在保证基分类器间的多样的同时,优化特征属性的权重。假设给定的数据集D 中有N个样本,如果在缺少特征ia 的状态下,导致本轮基分类器的错误分类个数为n,则认为本轮数据集属性判决iJ n= 。相反,如果因为缺少特征属性ia ,错误分类个数为n,本轮数据集属性判决为iJ n=- 。此种现象表明,某个属性的判决值的绝对值越大,则该属性对于整个数据集的重要程度越高。因此,为了提高子树之间的多样性,从所有特征属性中选择前T 个属性作为数据集 kD 用于创建子树kC ,并且所有属性的权重初始化为1/ac,其中ac 表示对于训练集的特征属性个数,并且T由经验可启发式地设置为ar/2。进一步聚焦至单个节点d的属性划分选择,随机选取 ( )ar ar T< 个特征属性用于计算其基尼系数,其中ar 可表示为
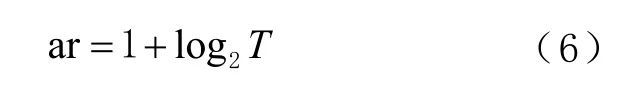
并不是利用整个数据集的所有特征进行计算,而是选择基尼系数小的特征属性计算分割点,可表示为
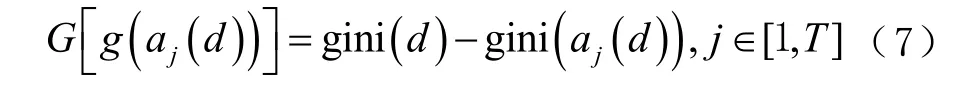
式中: gini (d )为为该节点分割前的基尼系数,对应的 gini ( aj( d ))为在节点d 中以最佳特征属性 aj分割后的基尼系数。由于采取特征属性随机采样的机制,因此在构建基分类器的过程中会出现某些特征属性被多次采取的情况,这样在样本个数相同的情况下,从特征属性采样的角度分析,必然造成了数据的不均衡。基于此,在基分类器建成后,对于被多次选择的特征属性 aj,可进行处理
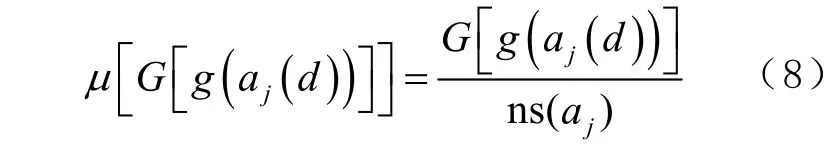
式 中: ns ( aj)为 选 择 特 征 属 性 aj的 次 数;μ G g ( aj( d ))为其均值,在子决策树中选择所有 的 G g ( aj( d))和 其 对 应 的 m 个 特 征 属 性( m ≤ T),可推导计算出整体对应的均值 μ ( G(g))和标准差 σ ( G ( g )),当 μ ( G ( g ))和 σ ( G ( g ))之间的差值是正数时,提高特征属性 aj的权重,反之减少其对应的权重。
通过对于样本特征属性进行随机采样的方法,提高了各子分类器之间的多样性,更贴近真实数据多变的情况。
2.2 改进决策机制
改进AdaBoost 算法采用包外估计的方法,采用2/3 的训练数据用于构建子树基分类器,1/3 的数据用于模型构建完后的验证和相关学习权重的验证。利用训练数据集 Dk去构建子树基分类器Ck,将测试数据作为输入时,由上述切割原理可知,通过计算特征属性的基尼系数得到最佳切割属性 aj,并且将测试数据通过基分类器得到分类结果的平均精度作为子树基分类器 Ck的属性 aj的决策权重 wk,j。在线使用阶段,对于任何1 个未知的样本属性,改进后的算法综合考虑属性分割点 aj的决策权重 wk,j和子分类器的自身精度去计算最终的联合投票权重,最终分类预测结果可表示为
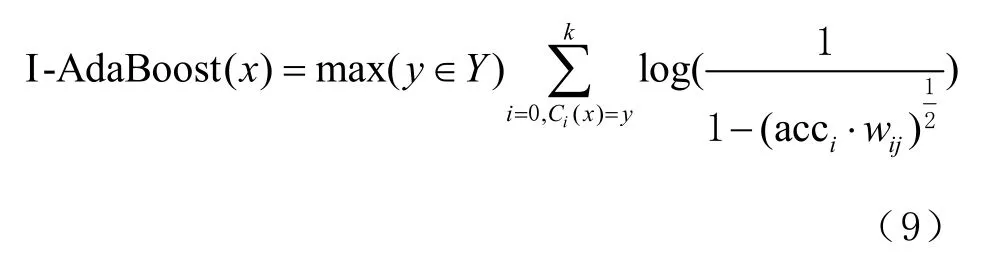
式中:I-AdaBoost(χ)为改进算法的预测结果;y 表示真实的分类标签; Ci( x )表示子树基分类器的预测结果;acci为子树 Ci的精确度; wij即为切割属性 aj的决策权重。
通过新的决策集成机制,充分保留了对特征属性随机采样而导致的子树之间的多样性。算法结合传统的投票决策方式,提高了预测结果的精确度,更切合真实数据的不确定性和多变性,提高了模型的鲁棒性。
3 实验与结果分析
3.1 实验设计
实验场地选用上海工程技术大学现代工程实训楼4 楼,实验场有5 个区域,共计738 个采样点,实验采用50 Hz 的采样频率,场地采用1.25 m×1.25 m的网格划分,图1 为区域5 的实验场地图,区域5 共140 个采样点。
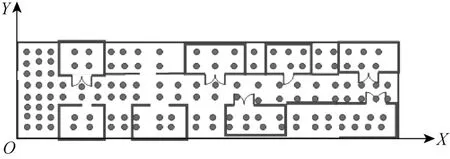
图1 区域5 实验场地
为了更好地对定位效果进行量化评判,引入评判误差函数
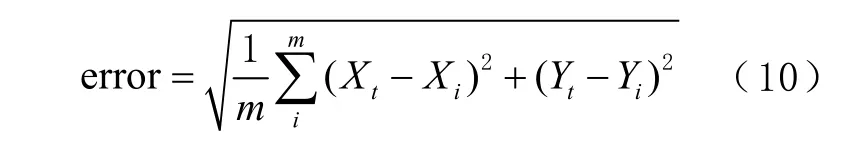
式中:( Xt, Yt)为真实位置坐标;( Xi, Yi)为算法所输出的位置坐标。根据均方误差求得误差函数error,如图1 所示,上述坐标均为2 维空间的相对O点位置坐标。
3.2 结果分析
在实验阶段,选用改进AdaBoost 算法、SVM算法以及KNN 算法和传统AdaBoost 算法进行定位效果对比,表1 为原始采集数据经填补缺失值处理后的数据。
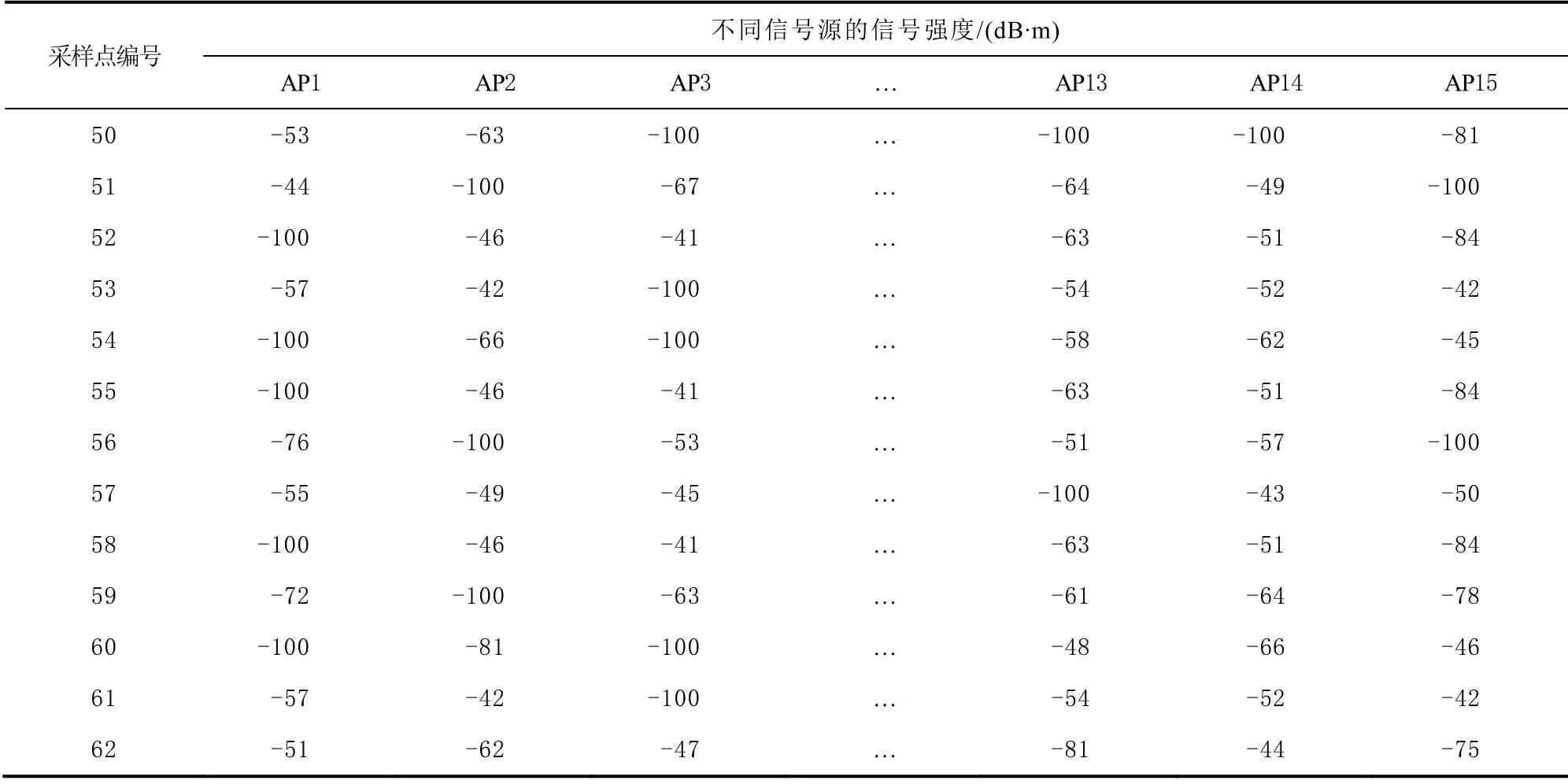
表1 部分真实定位数据
图2 为KNN、SVM、AdaBoost 以及I-Adaboost 4 类算法定位误差分析后的结果折线统计图。
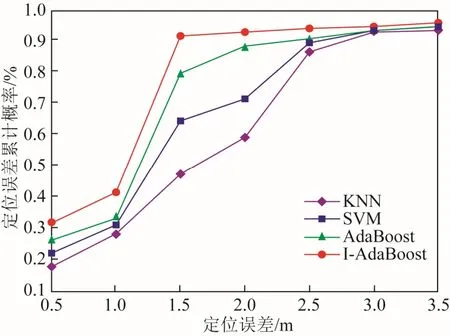
图2 定位误差分析
由于KNN仅考虑了所采集到的RSSI 特征因子的距离相似度,其算法思想较为简单,因此实际定位效果不佳,在1.5 m 范围内的误差为47%。对于SVM 而言,由于其基于最大化分类边缘信息,拥有更好的分类性能,但是模型对于大规模数据的处理仍然存在问题。相比于上述2 种单分类器算法,AdaBoost 算法集成多个分类与回归树的弱分类器,能够较为全面地考虑数据特征每次迭代分类中的误差,有利于分类错误的矫正。
由于传统的AdaBoost 算法对于数据中存在的异常值较为敏感,容易引起模型较大的波动,从而影响最终的定位效果。因此,针对上述存在的隐患,加入了判决式因子选择,以保证模型的多样性,充分利用设备端所采集到的特征数据。同时,算法对于最终的联合分类器投票过程做了改进,在分 析特征因子对精度影响的基础上,考虑了分类器自身给出的判决结果,最终提高了定位效果。实验结果表明,改进后的AdaBoost 算法在1.5 m 误差范围内的概率提高至 91%,相比于传统的AdaBoost 算法提高了12%。
然后选取实验范围内的5 个区域对上述算法进行定位准确率评测。表2 为KNN、SVM、AdaBoost, 以及I-AdaBoost 算法在上述5 个区域的定位准确率结果。

表2 4 类算法在5 个定位区域定位准确率结果
改进后的AdaBoost 算法运用新的判决式因子选择机制,保证了基分类器间的多样性,提高了算法整体的鲁棒性,因此算法在5 个定位区域均有较高的定位准确率,在区域5 定位准确率甚至达到96.1%。实验结果表明,相对于SVM 算法与传统的AdaBoost 算法,改进后的AdaBoost 算法自身性能上较为稳定,且有好的定位效果。
4 结束语
随着室内定位应用的不断发展和研究的深入, 室内定位技术将在各种实际生活场景发挥重要作用。改进AdaBoost 算法的WiFi 室内定位技术,利用新的判决式属性选择机制保持基分类器的多样性,更加符合实际的定位数据情况,增强了整体的鲁棒性;新的投票机制中融合了特征因子自身的精确度与基分类器的精确度评分,提高了算法最终的决策性能,从整体上增强了定位准确率。在今后工作中,针对大规模的定位数据运算,可引入大数据领域技术要点,采用分布式原理,对大体量的数据进行并行处理和模型部署,从而进一步提高定位业务整体性能。
猜你喜欢
纺织科学研究(2021年9期)2021-10-14 08:52:10
当代陕西(2020年17期)2020-10-28 08:18:18
中学生数理化·七年级数学人教版(2019年6期)2019-06-25 01:01:34
人大建设(2018年5期)2018-08-16 07:09:00
电子测试(2018年1期)2018-04-18 11:52:35
电信科学(2017年6期)2017-07-01 15:44:57
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
电测与仪表(2014年15期)2014-04-04 12:05:20
河南科技(2014年15期)2014-02-27 14:12:51
