
犬Ⅰ型腺病毒E1A 蛋白的生物信息学分析
2020-10-21 00:56徐文悦廉士珍刘晓颖邓效禹胡博张蕾薛向红贾琳琳闫喜军朱言柱
特产研究 2020年5期
徐文悦,廉士珍,刘晓颖,邓效禹,胡博,张蕾,薛向红,贾琳琳,闫喜军,朱言柱※
(1.中国农业科学院特产研究所,吉林 长春 130112;2.吉林农业大学,吉林 长春 130118;3.华威特科技有限责任公司,江苏 泰州 100085)
腺病毒科中的犬腺病毒(canine adenovirus,CAdV)是一种具有高致病力、可大范围感染的病毒[1-2]。犬腺病毒基因组为线状双股DNA[1],无囊膜结构,呈二十面体对称,为30~32 kb,其末端为反向重复序列[3]。CAdV可分为犬Ⅰ型(CAdV-Ⅰ)和犬Ⅱ型(CAdV-Ⅱ)[4],2 种犬腺病毒(CAdV)间存在抗原亲缘关系和交叉保护免疫。
此病无明显季节性,CAdV-Ⅰ可感染狐狸和犬,分别引起脑炎和肝炎,肾、肝和呼吸道也经常出现病变。此病毒容易在睾丸和犬肾细胞内增殖,也可在猪、水貂和豚鼠肺和肾细胞中增殖,并出现典型的细胞病变(cytopathic effect,CPE),主要特征为细胞变圆肿胀、汇集成葡萄串状,也可产生蚀斑[5]。CAdV-Ⅰ除了可以感染狐与犬外,还可感染狼、虎和臭鼬等。血清学研究表明,兔、马和松鼠等动物也是犬腺病毒的易感动物。在人群中其抗体阳性率较高,而且可检出补体结合反应抗原,可见人也能隐性感染。CAdV-1 的易感性和致病性在不同动物上存在差异[6]。
1925 年狐狸脑炎被Green 发现;1947 年犬的传染性肝炎被Rubarth 发现;1954 年 Cabasso 等首次分离到 CAdV-Ⅰ;Kapsenberg 在1959 年获取到该病毒,并证实ICHV 和狐狸脑炎病毒是同一种腺病毒;1983 年我国发现此病;1989 年钟宏志等[2-7]在被感染的狐狸体内提取出CAdV-Ⅰ。肝炎型病犬体温呈现双相热型,常有蛋白尿,会出现凝血不良,恢复期会出现肝炎性蓝眼。狐脑炎是一种罕见的疾病,呈现急剧脑炎症状,死亡率达100%。由于此病毒抵抗力强,致病性和病死率高,并每年可重复发生,不仅会危害犬和毛皮动物养殖的经济效益,而且会危害野生食肉类哺乳动物的安全。
动物感染24 h 后,血、脾、尿和肾开始出现病毒,随后是肝脏,但在急性期后病毒将会从肝脏中消失,患病动物的肾及尿液中携带病毒的时间可长达半年以上[8];慢性死亡的动物,以肾脏作为分离病料,可能较容易获得成功,但分离的病料来自急性死亡动物时应使用肝脏,原因是肝脏细胞质脆,易于研磨,病毒可以充分被释放出来[8]。病毒接种到犬肾细胞(如MDCK)上,细胞病变最先出现是在接毒后30 h 左右,有时需要6~7 d,再通过中和试验可鉴别出病毒的类型。血清学检查一般采用发病初期和发病后14 d 的双份血清进行人O 型红细胞凝集抑制试验。
生物信息学是检索、存储和分析生命科学研究中获得大量数据的科学。王晨[9]利用此方法来预测绵羊ER基因的结构,探讨其参与许多肿瘤和生殖有关的信号通路;王元红[10]利用此方法来预测猫传染性腹膜炎病毒AH 1905 株N 基因,发现其具有优良的特异性和抗原性;刘一鸣等[11]采用此方法分析参与肝脏再生(LR)终止阶段调控的相关基因,结果表明;LR基因的主要特点是根据身体的需要,在终止阶段能阻止增殖和生产功能性肝细胞,其不同之处在于肝肿瘤的扩散。该试验利用生物信息学分析方法来预测E1A 蛋白的理化性质及结构。
E1A 基因是一种具有增强子和自身启动子的早期转录基因,所编码的早期蛋白正向调节腺病毒其他基因的活化,并对宿主细胞有调节作用[12]。E1A 参与哺乳动物细胞的致瘤转化,是病毒和某些细胞基因表达的激活物。目前尚不清楚ElA 是直接与DNA 聚合酶、RNA聚合酶、其他转录因子发生相互作用来诱导基因表达,还是通过影响其他细胞因子(如细胞阻遏物失活)来间接起作用。此外,E1A 在细胞转化中的作用是其基因激活潜能的结果,还是另一种不相关的E1A功能,目前也尚不确定。E1A蛋白是潜伏感染中腺病毒持续表达最重要的效应蛋白[13]。为进一步了解E1A,本研究通过在线数据库和分析软件来预测E1A 蛋白的理化性质和生物结构,以期为进一步研究E1A提供依据,为未来建立CAdV-Ⅰ的抗体检测方法和亚单位疫苗奠定基础。
1 材料与方法
1.1 材料
E1A 的DNA 序列,由中国农业科学院特产研究所朱言柱老师提供。
1.2 E1A 蛋白的一般理化性质的预测
通过SnapGene 软件(GraphPad Software 公司),获得E1A 蛋白的氨基酸序列;使用Protparam(http://web.expasy.org/protparam/,SIB 瑞士生物信息学研究所)对E1A 蛋白进行分析,预测并获得E1A 蛋白的一般理化性质,主要内容包括相对分子质量、不稳定指数、等电点、分子式、带正负电荷的氨基酸残基数及序列组成。
1.3 E1A 蛋白的亲疏水性、信号肽及跨膜区预测
使用 ProtScale 软件(https://web.expasy.org/protscale/,SIB 瑞士生物信息学研究所)对E1A 的亲疏水性进行预测;使用SignalP 5.0 Server 在线软件(http://www.cbs.dtu.dk/services/SignalP/,DTU Bioinformatics)测定E1A 的信号肽;使用在线软件TMHMM Server 2.0(http://www.cbs.dtu.dk/services/TMHMM/,DTU Bioinformatics)分析 E1A 的跨膜区。
1.4 E1A 蛋白的糖基化位点及磷酸化位点的预测
使用 NetNGlyc 1.0 Server(http://www.cbs.dtu.dk/services/NetNGlyc/,DTU Bioinformatics),预测 E1A蛋白的糖基化位点;使用NetPhos 3.1 Server (http://www.cbs.dtu.dk/services/NetPhos/,DTU Bioinformatics),预测 E1A 的磷酸化位点。
1.5 E1A 蛋白二级结构的预测
使用 SOPMA (https://npsa-prabi.ibcp.fr/cgi-bin/secpred_sopma.pl,PRABI 公司)对 E1A 蛋白的 -折叠、-螺旋、无规则卷曲等进行预测。
1.6 E1A 蛋白三级结构的预测
使用 Phyre2 (http://www.sbg.bio.ic.ac.uk/phyre2/html/page.cgi?id=index,伦敦帝国学院结构生物信息学小组)对E1A 蛋白生成蛋白质的三维结构模型,利用预测结果进行蛋白质三级结构分析,主要分析蛋白与模型的可信度和蛋白覆盖率。
1.7 E1A 蛋白抗原决定簇的预测
使用Predicting Anti-genic Peptides(http://imed.med.ucm.es/Tools/antigenic.pl,马德里康普卢滕斯大学)预测E1A 蛋白的抗原决定簇。
2 结果与分析
2.1 E1A 蛋白的一般理化性质
E1A 蛋白的氨基酸序列为
*S*LLSRHRAVFMNMFLSYWKIGSRNVSPVSTPMVARHHRVFMIFLILSWKILVLLLRCCVIGVRRLTVNLQFPRRLMLALL*TLRRFLLFLRIPLLLQVFLRTCCCV*RRCLPLMTGMRFGVRPPPLSTGKITLTLMLGLFLVVCVVPITRSRGRIPFVGFVT*RPLLKALRHACSRRTC*C*CRRG**GHFCVC*TWFQKEVSGDFPRLS*KQ*TPLLARA*TN*TFGSFPKATPAI。
E1A 蛋白的相对分子质量为25 789.61,等电点为11.86,分子式为C1176H1926N340O268S21,氨基酸数量为225 个,正、负电荷氨基酸残基的数量分别为36和2,不稳定指数为50.39,氨基酸组成,见表1。
2.2 E1A 蛋白的亲疏水性、信号肽及跨膜结构
E1A 蛋白是平均亲水系数0.524 的疏水性蛋白,见图1;E1A 蛋白的信号肽可能性为0.005 3,见图2;E1A 蛋白形成了跨膜结构,见图3。

表1 氨基酸组成Table 1 Amino acid composition

图1 E1A 的亲疏水性预测结果Fig.1 Hydrophilic and hydrophobic prediction results of E1A protein

图2 E1A 蛋白的信号肽预测结果Fig. 2 Signal peptide prediction results of E1A protein

图3 E1A 蛋白的跨膜区预测结果Fig. 3 Transmembrane region prediction results of E1A protein
2.3 E1A 的糖基化位点和磷酸化位点
E1A 蛋白无糖基化位点,见图4;E1A 蛋白存在9个丝氨酸磷酸化位点(4、16、22、26、125、149、195、202和217),存在10个苏氨酸磷酸化位点(30、66、81、126、130、132、188、205、214 和 222),不存在酪氨酸磷酸化位点,见图5。
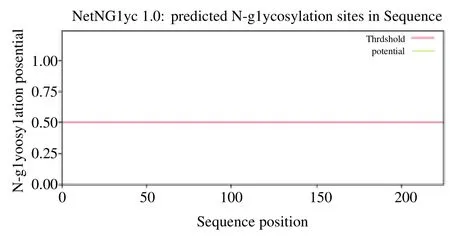
图4 E1A 蛋白的糖基化位点的结果Fig. 4 Prediction results of glycosylation site of E1A protein

图5 E1A 蛋白的磷酸化位点预测结果Fig. 5 Prediction results of phosphorylation site of E1A protein

图6 E1A 蛋白的二级结构预测结果Fig.6 The secondary structure prediction results of E1A protein
2.4 E1A蛋白的二级结构
从图6 可以看出,13 个氨基酸(5.78%)参与E1A-折叠的形成;84 个氨基酸(37.33%)参与E1A -螺旋的形成;46 个氨基酸(20.44%)参与E1A 蛋白延伸链的形成;82 个氨基酸(36.44%)参与E1A 蛋白无规则卷曲结构的形成。由此可见,-螺旋和无规则卷曲是E1A 蛋白二级结构中最主要的蛋白质元件。
2.5 E1A蛋白的三级结构
建立E1A蛋白三级结构的三维空间模型,见图7。从图7 可以看出,21 个残基(占9%)通过单个最高得分模板以19.0%的置信度建模。

图7 E1A 蛋白的三级结构空间模型预测结果Fig. 7 The spatial model prediction results of tertiary structure of E1A protein
2.6 E1A蛋白的抗原决定簇结果
预测结果(表2)显示,该蛋白有6 个抗原决定簇,分别为 24~69、73~110、118~127、129~146、152~192 和194~209 位,平均抗原倾向是1.0785。

表2 抗原决定簇的预测结果Table 2 Prediction results of antigen determination cluster
3 结论与讨论
通过生物信息学分析发现,E1A 是编码225 个氨基酸的疏水性蛋白。E1A 蛋白无信号肽,无信号肽结构的蛋白更容易形成包涵体。E1A 无糖基化位点。在E1A蛋白的磷酸化过程中,丝氨酸和苏氨酸的主要功能是为激活蛋白质的活力而变构蛋白质,即激活酶活力;结合蛋白,促进形成多蛋白复合物是酪氨酸的主要功能。苏氨酸和丝氨酸磷酸化位点在E1A 中占比较高,但无酪氨酸的磷酸化位点。在 E1A 的二级结构中,占比由高到低依次为 -螺旋结构、无规则卷曲、延伸链、-折叠。-折叠和无规则卷曲区域的二级结构松散,其稳定性较差,所以更容易扭曲和盘旋,与抗体分子结合。该研究结果发现,E1A 蛋白具有潜在的抗原决定簇,可作为诊断技术的候选蛋白靶点,将疫苗免疫与天然致敏动物区分开来,为犬Ⅰ腺病毒疾病的防控提供了新思路。
E1A 在等电点时,其分子的净电荷数为零,以两性离子的方式存在。由于不同颗粒的电荷的E1A 相互吸引作用,E1A 颗粒发生沉淀,有利于悬浮液的过滤。刘让东等[14]通过新研制的M-IPG 柱对蛋白质药物的等电点值进行测试,结果发现,在单克隆抗体药物和融合蛋白质药物的聚焦分离及等电点测定中新制 M-IPG柱和老式的HPC 涂层柱显示出相同的结果;利用蛋白质的一般理化性质,对于用来分离、鉴别不同的蛋白有很大的帮助;姜燕蓉等[15]利用等电点沉淀法提取牡蛎蛋白,测得其中盐溶性蛋白含量最高。E1A 蛋白的等电点为11.86,利用预测出的等电点数据,有助于测定氨基酸的含量和分离目的蛋白。
预测有无信号肽,对于判断E1A蛋白是否为分泌蛋白有较大的意义。魏蔷等[16]利用信号肽试验实现E2蛋白的分泌表达和 gp67 介导的 E2 蛋白在昆虫细胞杆状病毒的表达系统中的高效分泌表达,并纯化得到较高纯度的E2 蛋白,有利于其亚单位疫苗的研发;孙振文等[17]通过构建不同信号肽的O 型口蹄疫病毒重组表位蛋白的真核表达载体试验,结果发现,合适的分泌型信号肽可以促进 O 型口蹄疫病毒重组表位蛋白在CHO中的分泌;陈英等[18]研究不同信号肽对GLP-1-Fc 融合蛋白表达的影响,结果发现,信号肽的优良选择对于蛋白的分泌和关键质量属性都具有重要意义。E1A 蛋白无信号肽意味着其不是分泌蛋白,容易形成包涵体,有利于药物靶点筛选和疫苗研发。
糖基化是一种主要的蛋白质翻译后进行修饰的调控机制。对复杂生物样品中糖蛋白的全局和位点特异性分析可以促进对糖蛋白功能和细胞活动的理解。通过蛋白质糖基化修饰可以调节蛋白的生物活性、空间构象和细胞通信等,因此对E1A 蛋白的糖基化位点进行分析具有十分重要的意义。潘昱婷等[19]利用蛋白糖基化相关试验数据,推断出E 蛋白N 连接糖链(又称N的糖基化)不仅能维持抗原构象,而且与病毒的感染力及毒力有关。因此,通过N 的糖基化修饰可以开发出新型的黄病毒疫苗;Lombana等[20]利用n-连接聚糖的糖基化位点特异性插入到抗原表面来掩盖局部区域,发现通过与先前报道的切割位点相邻的GEM 表位结合的抗体可以有效抑制MICA 的脱落,而这些抗MICA/B 抗体可以在体内阻止肿瘤的生长;Arya 等[21]利用高分辨率质谱分析肽质量指纹图谱,系统分析了AAV8 衣壳糖基化谱,以确定衣壳糖基化的存在,得出AAV8 辣椒蛋白上确实有天然N-糖基化的存在。E1A蛋白没有糖基化位点,说明其没有与糖链连接的位点,可能与判断其是否为糖蛋白有一定的相关性。
由于在底物蛋白的氨基酸侧链上添加了附有强负电荷的磷酸基团,从而对蛋白的稳定性、构象以及与其他蛋白分子之间的相互作用有较大影响。大量研究表明,蛋白磷酸化在许多生理、生化过程中发挥着重要作用,包括细胞周期调节、信号转导和代谢途径等。洪涛等[22]通过分析缝隙连接蛋白Cx43 磷酸化位点在脑血管痉挛中的影响,发现其可能与脑血管痉挛密切相关,可能是CBX 缓解脑血管痉挛的机制之一;Chandra 等[23]通过绒毛蛋白的位点特异性磷酸化试验,发现Tyr499 是绒毛蛋白的关键磷酸化位点,并负责促进病毒巢细胞的融合。易和友等[24]研究了猪繁殖与呼吸综合征病毒的N 蛋白的磷酸化修饰,结果显示N 蛋白磷酸化位点突变影响PRRSV 的复制及亚基因组转录。E1A 蛋白具有10 个苏氨酸位点、9 个丝氨酸位点,无酪氨酸位点,可能说明无法给结合蛋白提供一个结构基因,无法促进形成多蛋白复合体,即不能构成细胞信号转导的基本机制。E1A 蛋白通过磷酸化修饰有利于CAdV 疾病的分子标志或治疗靶标研究。
预测E1A蛋白的二级结构与三级结构,有助于了解E1A的生物功能。齐宝坤[25]通过对大豆分离蛋白二级结构的相关试验,得出当蛋白质分子中 -螺旋含量低、-折叠及无规卷曲含量高时,蛋白质分子会变得更加无规律性;吴喆瑜[26]通过黑曲霉 -L-鼠李糖苷酶Rha1 的二级和三级结构预测试验验,发现Rha1 的晶体结构与已知的4 个 -L-鼠李糖苷酶相似,都具有一个( / )6 桶状结构域。E1A 蛋白的二级、三级结构有利于对犬腺病毒疾病的防治研究。
为探讨E1A蛋白是否具有抗原性,该研究预测了其抗原决定簇。吴文星[27]发现 3B 蛋白含有3 个抗原决定簇。E1A 蛋白有6 个抗原决定簇,但其是表面抗原决定簇还是内部抗原决定簇还需要进一步验证。CAdV-Ⅰ引起的2 种疾病是世界范围内最重要的动物腺病毒感染,所以运用生物信息学分析方法研究CAdV-Ⅰ的E1A 蛋白可使人们更加了解CAdV-Ⅰ。
以上研究结果有利于进一步开展E1A蛋白研究,为建立 CAdV-Ⅰ的抗体检测方法和亚单位疫苗提供基础。
本研究运用生物信息学分析方法预测E1A蛋白,但生物信息学是在已有知识基础上的预测,所以还需要未来对此进行进一步研究探讨。
猜你喜欢
传染病信息(2022年3期)2022-07-15
福建农业学报(2022年3期)2022-05-24
中国动物保健(2022年2期)2022-05-05
养殖与饲料(2021年11期)2021-11-15
复旦学报(医学版)(2021年5期)2021-10-13
临床医药文献杂志(电子版)(2020年39期)2020-07-23
三农资讯半月报(2020年8期)2020-05-13
江苏农业科学(2017年23期)2018-01-29
今日健康(2016年7期)2017-04-12
江苏农业科学(2016年5期)2016-07-23
