
嵌入式GPU滑动聚束SAR实时成像方法
2020-10-21 07:21:16胡善清李慧星李炳沂谢宜壮陈亮陈禾
北京理工大学学报 2020年9期
胡善清, 李慧星, 李炳沂, 谢宜壮, 陈亮, 陈禾
(1. 北京理工大学 信息与电子学院 雷达技术研究所,北京 100081;2.嵌入式实时信息处理技术北京市重点实验室,北京 100081;3.北京无线电测量研究所, 北京 100854)
星载合成孔径雷达(synthetic aperture radar,SAR)是空间对地观测领域的一个重要组成部分,由于其全天时、全天候的工作能力,星载SAR被广泛应用于地球遥感、军事侦察、资源勘探等诸多国防和民生的重要领域. 随着高分重大专项的开展以及高分三号卫星的发射,我国星载SAR领域进入了对多模式、多尺度和多粒度数据结合处理阶段,进一步丰富了SAR数据产品的检测、识别等后端应用形式. 然而,目前对于高分SAR数据处理依然停留在原始数据下传地面处理阶段,对于突发事件的响应能力严重不足. 在轨SAR数据实时处理是解决这一问题的主要途径.
在SAR在轨处理方面,麻省理工学院(MIT)林肯实验室[1]、美国空气动力学实验室(JPL)[2-4]、德国汉诺威大学[5]、加州理工大学[6-7]等机构开展了星上实时处理方面的研究. 现有的在轨处理通常采用DSP+FPGA的方式实现[8],但其扩展性较差、算法实现难度大、性能不强. 与此同时,计算硬件的快速发展,特别是功耗低、性能强、开放性好的嵌入式GPU的问世和持续发展为遥感数据在轨实时处理带来了新的可行方案. 针对光学应用,中科院遥感与数字地球研究所[9]、武汉大学[10]等国内高校已经开始验证嵌入式GPU在轨搭载的可行性.
目前GPU主要在地面站作为SAR数据处理加速器使用. 孟大地等[11]在NVIDIA K20c + INTEL E5645平台上做了基于距离多普勒(range Doppler,RD)算法SAR成像的优化加速,8 GB的数据量只用了7 s;Zhang等[12]做了基于多CPU/GPU的深度协同SAR成像处理研究,2 GB数据量耗时0.72 s. 地面的成熟应用为基于嵌入式的在轨SAR实时成像处理提供可能. 相比于传统插卡式GPU,Tegra系列具有功耗低、体积小、接口完备、易于嵌入式扩展等优势,但其劣势主要体现在处理性能相对较差,且内存空间不足等方面. 本设计基于Jetson TX2嵌入式开发板对滑动聚束SAR成像算法进行高效移植及优化加速. TX2的内存虽然高达8 GB,但由于其内存-显存共享设计的特性,若无法合理分配内存资源很容易导致内存不足. 对此,本设计依托滑动聚束式SAR处理流程,提出了一种基于TX2的内存复用方案,在一定程度上有效解决了TX2内存不足的问题;再利用zero-copy技术进行实时数据传输,解决了传统模式下通过PCIe数传带来的处理瓶颈与资源浪费. 在计算加速层次,本设计借助CUDA通用并行计算架构,将需要海量计算的环节,如方位向去斜、CS因子相乘、FFT等,都做了大规模并行化处理,最终实现16 384×8 192点滑动聚束SAR精确成像.
与现有研究相比,本文主要作出以下贡献:第一,通过算法分割,提出了一种基于嵌入式GPU的内存分割与重配置方案. 采取了一系列手段包括内存的原地写入、交替循环、动态释放等,有效减少了内存碎片化及重分配次数,节约了内存空间. 第二,借助页锁定内存和zero-copy技术,实现真正意义的零复制. 在ARM端开辟页锁定内存,通过无需任何开销的指针映射,杜绝传输耗时.
1 动聚束SAR成像CS算法
本设计采用的成像算法是基于CS(chirp scaling)原理的两步去斜法. CS算法无需距离多普勒算法(删除)中复杂的卷积,只需要若干次CS因子相乘和FFT即可实现条带式SAR成像[13-14]. 滑聚模式SAR是对条带SAR的改进,它兼备条带SAR的宽测幅与聚束SAR的高分辨率的优点[15]. 滑聚SAR成像算法的整体流程图如图1所示.
雷达每次接收一条距离向数据(NR点),共接收NA条,作为一景的原始数据,转置后便可进行方位向去斜操作,得到距离多普勒域数据,而后进入正常的CS处理流程. 首先,对方位向作变标处理;其次,距离向频域乘徙动因子进而完成距离向脉冲压缩操作;再次,方位向乘因子并作逆FFT完成方位向压缩;最后对图像作量化并输出成像结果.
由于滑聚模式针对的应用场景多为高分辨率成像,因此处理的原始数据量大多是GB级,且为保证精度,数据全程以单精度浮点形式处理,对内存需求极大. 结合如表 1所示TX2内存开销情况,假设一次可处理的最大数据量的理论值为xGB,则针对TX2 7.5 GB可用空间(除去操作系统占用),单批次可处理的原始数据量理论最大值约为1.8 GB. 本文旨在讨论嵌入式GPU独立处理方法,针对的原始数据量小于理论上限.
同时,针对滑聚算法实现本身,FFT、相位因子生成、二维数据转置的实现方式都关乎处理的时效性. 后文将着重阐述算法不同部分的并行优化方法.

表1 内存开销情况
2 优化设计
本文主要从以下两个角度对滑动聚束式SAR成像做了基于嵌入式GPU的优化加速:内存分割、配置与基于任务的重调度;基于算法映射的大规模数据处理并行优化方法. 规定采用的原始数据量是NA×NR,升采样后为NP×NR.
2.1 内存优化设计
2.1.1内存分割与重配置
频繁分配和释放内存不仅耗时,更容易导致内存的碎片化,因而内存分割与重配置在整体方案的设计中十分重要. 内存分割主要体现在对内存的有效划分上,根据用途,本设计将使用到的内存段主要分为工作区内存和数据缓冲内存两部分. 工作区内存专门用于执行FFT操作,因而需要长期占用;数据缓冲内存用于暂时存放中间输出,因而具有很大的可操控性. 本着相同数据量大小为一组的原则,将数据缓冲内存再根据大小划分为四组,如表 2所示.

表2 内存分割设计
内存段mem0用于存放输入和输出数据;mem11与mem12代表升采样前的数据存储;mem21与mem22代表升采样后的数据存储;另外还有一些中间变量用到的内存段,表格中以mem3表示. 设计利用这4组内存块,通过有效的内存复用与动态分配释放,达到了降低内存占用、减少分配耗时的目的.
如图2,内存的复用主要体现在以下3个方面.
① 原始数据缓存区mem0在处理过程中采用原位置换机制.M1为升采样后的数据量,该部分空间一景处理完成后再释放;
② 由于矩阵转置模块无法实现内存覆盖,使用同一段内存会导致数据混乱,因此将上一个转置的输入空间作为下一个转置的输出空间使用,实现内存交替复用.
③ 在执行FFT操作与因子复乘部分时,输出结果将输入数据覆盖,实现原地存储.
内存的动态分配与释放主要体现在两个方面:
① 用于存放升采样前数据的存储空间在升采样后便不复使用,因而升采样结束后将其立即释放;而用于放置升采样后数据的mem21和mem22分配将在mem11与mem12释放成功后进行.
② 中间变量,如CS因子、距离徙动因子、距离向时间轴、方位向频率轴等,都采取即分配、即利用、即释放的手段. 这些变量数据量较小,占用的空间往往是kB量级,因而可以顺利获取,不用担心由频繁释放带来的内存碎片化问题.
2.1.2任务分区与数据调度
在嵌入式GPU中,ARM作为SAR成像处理的主控及辅助计算部分,主要用于指令生成、调度与参数计算. ARM向GPU发布命令,激活GPU内核启动程序,继而GPU开始并行计算;计算完成后GPU向ARM返回成功标志,ARM开始着手准备激活下一条内核程序. 本设计里ARM用于计算的环节主要体现在轨道参数计算部分,该部分算法拥有大量迭代与串行操作,无法在GPU上实现并行加速,因而选择在ARM端串行计算.
另外,对于数据传输方式,由于数据的中间处理过程都是在GPU上进行的,故在传统的CPU+GPU异构平台上,是采取在CPU和GPU端分别开辟一段内存的方法,先将数据读取至CPU中,然后将数据由CPU再拷贝至GPU端作后续处理[16],如图 3(a)所示. 然而复制过程以及分别在主机端和设备端分配内存的过程相对于计算本身而言没有任何产出,且相当耗时,因而应尽可能地减少此类操作.
考虑到TX2的主机和设备的内存共享特性,若分别开辟内存,会导致两段内存中的内容重复. 故此处采用了zero-copy技术,借助免费的映射关系达到有效规避传输时间的作用,如图 3(b).
首先分配CPU页锁定内存,这段主机存储在经过指针映射后可以投入到设备空间中使用. 在读取与写入磁盘时用到的是主机端指针,在需要设备端做加速计算处理时,使用相应的设备端指针即可. 在传统GPU上,zero-copy是将数据传输与内核计算操作以流水线的方式执行,因而只能对该块内存读写一次,且性能提升不明显,通常不加以考虑;而TX2得益于其内存共享的特性,节约设备端存储器的同时省去了数据拷贝的时间,因而可以实现真正意义上的零复制.
综合上述分析,采用zero-copy技术的数据传输耗时为零,这正是因为zero-copy省去了一切不必要的显式复制,取而代之的是不需要任何开销的指针映射.
2.2 算法关键运算部分并行化处理
算法映射时,无论是矩阵转置、因子复乘,还是FFT、求最值,都用到了GPU的并行特点,使得整体计算效率相比较串行处理提升了上百倍.
2.2.1矩阵转置
对于全局内存读取,GPU要想达到高吞吐率,必须尽可能地采取合并访问的方式,即连续访问对齐内存. 当发生非合并访问时,GPU会传输多次来完成这个访存请求,这将极大地降低内存吞吐率,影响GPU的访存速度[17].
显然,矩阵转置过程中,读取矩阵的行时可以达到合并访问,然而转置后写入矩阵的列时会形成非合并访问(删除原始图4 非合并内存访问). (删除共享内存介绍)本设计借助共享内存来避免对全局内存的非合并访问. 然而,当分属不同块的线程访问到同一个块时,就会带来块访问冲突的问题[16]. 为了解决这一问题,本设计将共享内存块的大小设定为
Bdim*(Bdim+1).
(1)
Bdim代表共享内存块在一个维度上的大小. 这样在写入时分属相同块中的线程将访问到不同的共享内存块,示意图如图4所示.
图中,相同的数字代表矩阵的同一列;X代表为共享内存人为加入的附加列. 可以看出,在写入共享内存时不存在块内冲突;但在从共享内存中读取数据时由于要做转置操作,若不加处理(删除)会导致一个块中的所有线程读取到同一个块中的不同地址上,带来严重的冲突;而添加附加列处理后,每一列的数据会呈对角线式均匀分布在不同块中,每一个线程对应着不同块. 最后将读取到的列元素按行写入内存块完成矩阵转置.
经过以上优化,矩阵转置可以同时避免非合并访问与共享内存带来的块冲突问题,理论吞吐率达100%.
2.2.2因子复乘
在滑聚算法中,5次因子的计算以及它们各自与待处理数据的相乘都涉及到了因子复乘. 像素点之间的计算相互独立,故可以借助CUDA架构很容易地移植到TX2中并行计算,如图 5.
占用率表明了GPU中硬件发射时的并行情况,一般情况下,占用率越高,意味着程序的并发度越高,性能越好. 可以根据以下公式来计算硬件占用率. 其中,o为硬件占用率,Wact为实际活跃的线程束个数,Wmax为最大可活跃的线程束个数.
o=Wact/Wmax.
(2)
在TX2中,由于受到寄存器资源的限制,占用率有时无法达到100%,这时,减少每个线程块的大小可以有效地提升硬件占用率. 理论上,线程块越小,硬件占用率越高;然而过小的线程块又会导致GPU无法借助大量线程之间的流水操作来很好地掩藏访存延迟,这就带来一对矛盾. 可以参考以下公式计算一个内核中可以同时发射的线程块的个数.
(3)
式中:Bnum为实际活跃的线程块个数;Rmax为设备中的寄存器个数上限;R为每个线程中所需要使用的寄存器个数,与内核复杂度有关;Bsize为分配的线程块大小.
本文为了达到最高的性能收益,对上述矛盾做了折中. 对于寄存器个数充足的计算内核,采用最大线程块规模——1 024个线程,这使得占用率可达到100%,且最大限度地掩藏了访存延迟;对于寄存器个数不足的计算内核,则以2为基准,逐倍降低块规模,最小块为256个线程,从而达到性能最优.
2.2.3FFT
要想实现方位向和距离向压缩,需要执行多次FFT. CUDA库中已经集成了完备的cuFFT库以帮助开发人员实现高性能的FFT变换.
在调用FFT的库函数时,需要为FFT分配工作区,该区只能由FFT占用而不能用于其他操作. 经过测试,地址空间的分配十分耗时,消耗时间超出FFT本身操作的10倍以上,若每次FFT操作都重新分配工作区会导致执行效率大大降低. 分析整个SAR成像流程,共执行了包括IFFT在内的5次FFT操作,其中,方位向FFT 3次,距离向FFT 2次. 因此,本设计选择在5次FFT操作全部完成后再将FFT的工作区统一释放,从而提升了FFT计算在程序执行总时间中的占比. 输入和输出数据存放在同一块内存中,实现原位存储.
3 结果分析
3.1 成像效果及精度分析
本文基于GF-3地面测试数据[18],分别采取点目标与面目标成像结果作评估,输入数据均为1 m分辨率、10 km幅宽. 数据粒度为;16 384×8 192. (删除具体内存分配)
3.1.1点目标成像分析
在方位向与距离向均加-30 dB的5阶泰勒窗后,设计优化得到的点目标压缩图像如图 6.
选取景中心点目标(像素点坐标为(8 192,4 096))作评估,可以得到二维等高线图、方位向峰值曲线和距离向峰值曲线(加窗),如图 7和图 8是未加窗的成像结果.
SAR成像结果常用的几个评价指标为:峰值旁瓣比(peak side lobe ratio,PSLR)、积分旁瓣比(integrated side lobe ratio,ISLR)和分辨率[19]. 为了使评估结果更可靠,本文将图8中的9个点目标全部作评估再取平均值,得到结果如表 3.
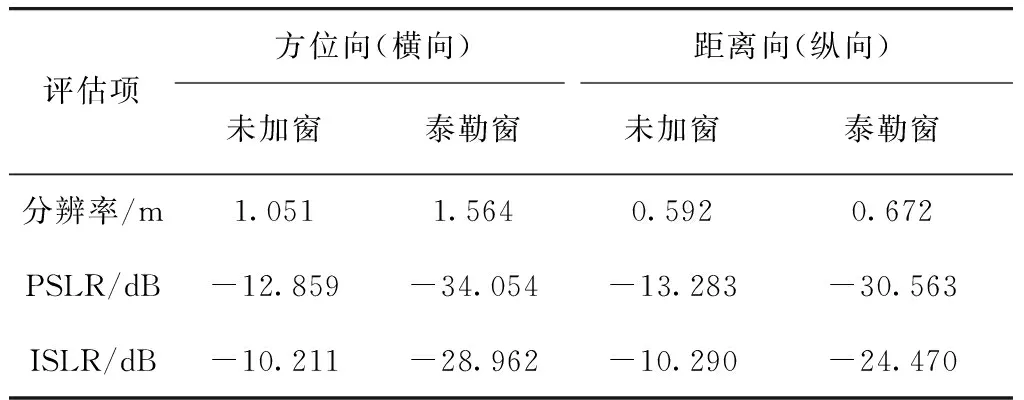
表3 点目标评估结果
理论上,在未加窗的情况下,PSLR应该为-13.4 dB;但在本设计中,由于构造参数本身的些微误差导致了成像结果的方位向PSLR增加了约0.55 dB,距离向PSLR增加了约0.12 dB. 为了使弱目标不被附近的强目标覆盖,通常要求PSLR取到-20 dB,ISLR取到-15 dB,此时,可以选择在脉压时对方位向和距离向分别加-30 dB的5阶泰勒窗抑制旁瓣,加窗后的结果满足要求.
3.1.2面目标成像分析
压缩后可得到面目标图像如图 9.
为了比较成像效果,本文采用了常用的面目标图像质量评估指标:均方误差(mean squared error,MSE)、峰值信噪比(peak signal to noise ratio,PSNR)、结构相似度(structural similarity index,SSIM)、辐射分辨率(γ)[20],将TX2处理后的全幅图像与CPU仿真结果图作比较,得到各指标如表 4.
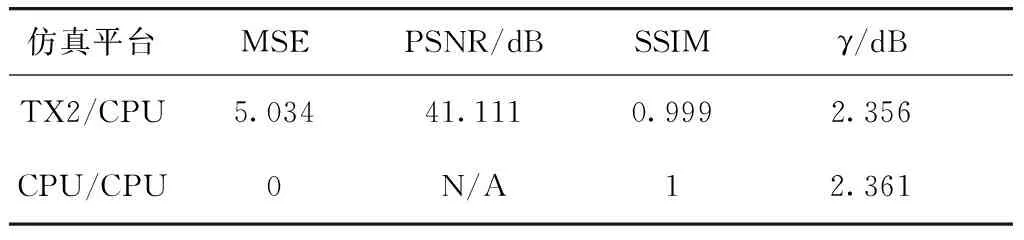
表4 面目标评估结果
3.2 实时性及功耗效能比分析
为了得到最佳方案,此处根据计算机硬件评估指标,定义SAR成像在GPU上实现的性能功耗比如下.
(4)
利用Nsight Eclipse平台的Profile分析工具对优化结果做分析可以知道,TX2在优化等级为-o2的情况下,完成数据量为1 GB的滑动聚束式SAR成像的总执行时间为12.660 s;其中,指令执行时间(包括文件读写以及ARM端的一些调度)占用了1.418 47 s,在GPU上的计算时间占用了8.599 83 s,内存分配与释放占用了2.641 7 s. 同样的数据量在Tesla K20c + Intel Xeon CPU E5-2697 v2平台上的总仿真时间为4.165 s. 再结合现有的SAR成像研究[12,21-22],可以得到对比结果如表 5所示.
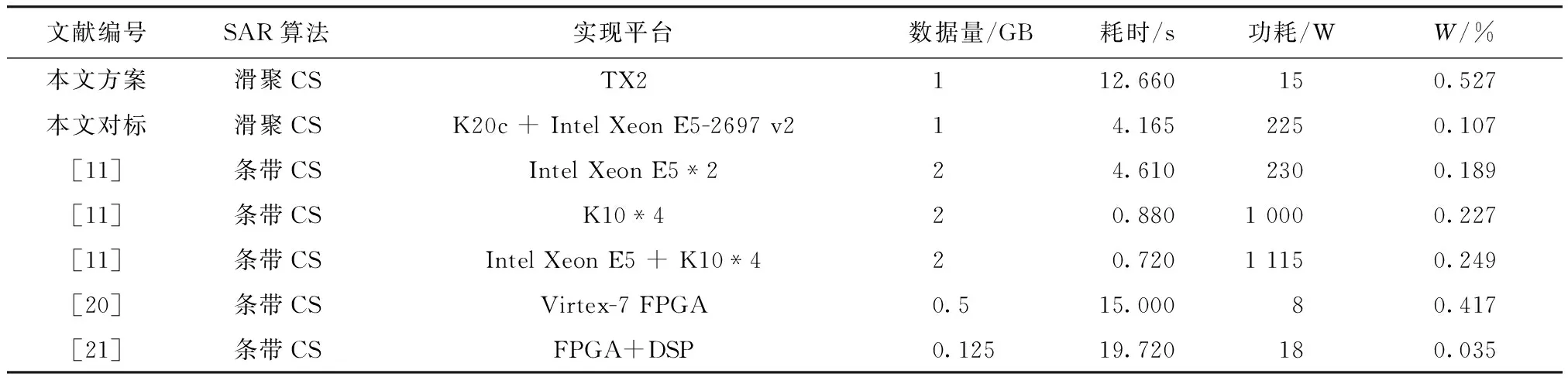
表5 不同优化方案的性能对比
可以看出,SAR成像在TX2上实现时的性能功耗比明显高于其他平台下的性能功耗比,这意味着单位功耗下嵌入式GPU可以提供更高的处理效率. 因此,在嵌入式GPU开发平台上实现星载SAR实时成像非常有发展前景.
4 结束语
主要研究基于Chirp Scaling处理算法的滑动聚束式SAR成像算法在嵌入式开发平台Jetson TX2上的设计与实现. 通过算法分析,对内存做到有效分割与重配置,借助原地内存写入、内存交替循环、动态内存释放等手段解决了TX2上内存不足的问题;在ARM与GPU的数据交互上,利用页锁定内存,通过指针映射过程实现零复制,使数据传输耗时降低至0 ms;最后,通过有效复用TX2中的共享内存、寄存器、全局内存等存储资源,合理分配线程个数,最大限度地开发了TX2的计算性能,实现大规模数据并行. 与现有研究相比,本设计在不损失精度的前提下,达到了最高的性能功耗比. 这为星载SAR实时成像开辟了良好的开端.
考虑到TX2现有的8 GB内存空间仍不足以满足大批量数据的星上实时处理,这可以通过PCIe扩展内存或数据分块来解决. 另外,随着嵌入式平台的不断发展,更高性能的硬件平台也可以投入使用,例如Jetson Xavier,内嵌16 GB的LPDDR4,将TX2的内存空间扩大了一倍;同时Xavier采用PCIe 4.0技术,当采用分块处理时,可以达到更大的传输带宽. 这都使未来基于嵌入式GPU的更大点数SAR在轨成像成为可能.
猜你喜欢
北京大学学报(自然科学版)(2021年3期)2021-07-16 07:13:40
东北师大学报(自然科学版)(2021年1期)2021-03-27 01:22:14
电脑爱好者(2020年19期)2020-10-20 06:02:06
电子制作(2019年13期)2020-01-14 03:15:18
山西电子技术(2019年4期)2019-09-07 08:00:34
魅力中国(2019年6期)2019-07-21 07:12:10
科技风(2017年20期)2017-07-10 18:56:06
武汉理工大学学报(交通科学与工程版)(2015年5期)2015-12-05 02:19:55
电子世界(2014年21期)2014-04-29 06:41:36
组合机床与自动化加工技术(2013年1期)2013-12-23 04:47:02
