
Mapping aboveground biomass and its prediction uncertainty using LiDAR and field data,accounting for tree-level allometric and LiDAR model errors
2020-10-20 08:13SvetlanaSaarelaAndrstlundEmmaHolmstrAlexAppiahMensahrenHolmMatsNilssonJonasFridmanandranSthl
Forest Ecosystems 2020年3期
Svetlana Saarela ,André Wästlund,Emma Holmström,Alex Appiah Mensah,Sören Holm,Mats Nilsson,Jonas Fridman and Göran Ståhl
Abstract
Keywords: Aboveground biomass assessment,Forest mapping,Gauss-Newton Regression,Hierarchical Model-Based inference,LiDAR maps,National Forest Inventory,Uncertainty estimation,Uncertainty map
Introduction
The interest in forest inventories is increasing due to the key role of forests in global carbon cycles and, thus, in the climate change discourse(e.g.,Bellassen and Luyssaert 2014).For a long time regional and national forest inventories have been based on field surveys of sparse networks of sample plots(e.g.,Tomppo et al.2010;McRoberts et al.2009). Such surveys rely on sampling theory and designbased inference (e.g., Gregoire and Valentine 2008). An advantage is that estimates of population parameters such as mean and total biomass,and the corresponding uncertainties,can be obtained without making any assumptions about the population studied. Examples of national forest inventories of this kind are given in Tomppo et al.(2008a, 2010) and Fridman et al. (2014). Currently, they are the backbones of national forest statistics and international reporting for compiling regional and global forest resources assessments(e.g.,Forest Europe 2015).
Some disadvantages of traditional forest inventories are that they are expensive to carry out in areas with poor road infrastructure and they provide only limited spatial information about the forest resources. Use of remotely sensed(RS)data is a means to overcome these disadvantages and an increasing number of studies suggests that RS data can be used in several ways to improve the efficiency of forest inventories and add new dimensions to the results.For example,RS data can be used for stratification in the design phase of forest inventories (e.g., Katila and Tomppo 2002;McRoberts et al.2002;Haakana et al.2019),unequal probability sampling(e.g.,Saarela et al.2015a),or balanced sampling(e.g.,Grafstrom et al. 2017a).The latter design was implemented in the Swedish NFI in 2018 for the temporary plots(Grafstrom et al.2017b).Gregoire et al.(2011)and Gobakken et al.(2012)have shown how RS data can be applied in the estimation phase to improve the precision of estimators through model-assisted estimation.Franco-Lopez et al.(2001),Tomppo et al.(2008b)and, recently, Esteban et al. (2019) have shown how RS data can be combined with field sample data to provide maps of forest resources as a complement to estimates of means and totals of the variables of interest.
When these types of maps are developed, RS and field data are used in regression analysis or other types of machine learning algorithms to predict the variable of interest for each map element based on the RS data,using an explicit or implicit model relationship between field and RS data (e.g., Andersen et al. 2005; Hudak et al.2008). Other examples are Wulder et al. (2008), who used regression analysis to map predicted forest biomass over a large spatial domain in central Saskatchewan,Canada, using Landsat Thematic Mapper (TM) multispectral data at a spatial resolution of 30 m×30 m, and Zald et al. (2016) who applied the random forest algorithm to map forest attributes using a combination of airborne Light Detection and Ranging (LiDAR) sample data and wall-to-wall multispectral data derived from Landsat TM and the Enhanced Thematic Mapper Plus (ETM+) imagery over a large spatial domain in Saskatchewan, Canada. An increasing number of studies of this kind address forest mapping not only at local and national scales,but also at regional and global scales.For example, Saatchi et al. (2011) used a fusion of wall-towall spatial data from multiple sensors and sampled forest height data collected by the Geoscience Laser Altimeter System (GLAS) onboard the Ice, Cloud and land Elevation Satellite-1 (ICESat-1) to construct a global map of forest carbon stocks at a 1-km spatial resolution.Hansen et al.(2003)compiled a global map of percent tree cover through a supervised regression tree algorithm using MODIS data at a 500-m spatial resolution; and in the GEDI project(Dubayah et al.2014;Qi and Dubayah 2016;Qi et al.2019;Patterson et al.2019)a space-borne laser is applied for mapping biomass with almost global coverage at a 1-km spatial resolution.
Following the introduction of LiDAR-assisted forest inventories (e.g., Nelson et al. 1988; Næsset 2002) forest resource maps of this kind have become accurate enough to support management decisions at local level,ranging from the scale of individual map units,to stands and aggregates of forest stands. Examples are harvesting decisions at the level of stands and valuation at the level of forest properties (e.g., Nilsson et al. 2003). Thus,sparse samples of field data can now be used for several purposes,e.g.,they can be used to provide traditional forest statistics as well as maps of forest resources and environmental conditions, when combined with RS data(e.g.,Nilsson et al.2017).
However, it is far from trivial how maps of forest resources should be used for producing reliable forest statistics.For example,McRoberts et al.(2018)point out that land cover statistics will be subject to systematic errors if classifications for map units are merely summed across a study area.Further,Gregoire et al.(2016)identify several problems related to how uncertainties are typically computed and reported in LiDAR-supported studies.For example,in many cases uncertainties are merely assessed intuitively based on subjectively selected sets of map units where predicted values are compared with the corresponding field measurements.It is not straightforward to use data from such comparisons for estimating variances or mean square errors of estimated means and totals for an entire study area.
One way of using RS auxiliary data (e.g. in the form of forest maps)in a statistically rigorous way for producing forest statistics is to apply model-assisted estimation(e.g.,Gregoire et al.2011;Saarela et al.2015a).With this design-based inference technique model predictions are subtracted from field reference values for a probability sample of map units. The mean of the observed deviations is added to the mean of the model predictions across all map units to obtain an estimate of the mean of the variable of interest. While this approach has a potential to make cost-efficient use of RS data that correlate strongly with study variables of interest, a drawback of model-assisted estimation is that it requires a fairly large probability sample of field data(Ståhl et al.2016).
An alternative approach to using RS auxiliary data in a statistically rigorous manner for producing forest statistics is to apply model-based inference (e.g., Magnussen 2015).Model-based inference relies on an assumption of a model that is assumed to generate random values for each map unit based on the auxiliary data available for the map units. This model is sometimes referred to as a superpopulation model, from which the actual population is realized (Cassel et al. 1977; Särndal et al. 1978;Gregoire 1998).Since the individual values of the population elements are random variables,so are the population means and totals. While many concepts and estimation procedures related to model-based inference tend to be more complicated than design-based inference(e.g.,Gregoire 1998), model-based inference also has advantages(e.g., Magnussen 2015) e.g., with regard to combining forest mapping and compiling forest statistics, since the same basic procedures can be applied for both purposes.Moreover, model-based inference can be used for producing maps of uncertainties for the variables of interest,although this opportunity seems to be seldom exploited.An example is Esteban et al. (2019), who presented a map of uncertainties for forest attribute predictions using the random forest algorithm.The uncertainties were estimated through bootstrapping.Such uncertainty maps are important for assessing to what extent the map information is accurate enough for making different kinds of decisions.
Interestingly, uncertainty estimation under modelbased inference is fairly straightforward both at the level of individual map units and at the level of totals and means across large study areas(e.g.,Ståhl et al.2016).For small aggregates of map units it is more complicated,due to the need for information about how strongly model errors are correlated across space(McRoberts et al.2018).Still, many different techniques have been presented for small area estimation(e.g.,Breidenbach and Astrup 2012;Magnussen et al.2014).
Conventional model-based inference utilizes auxiliary information from all map units and a single model for the relationship between auxiliary data and the variable of interest.However,in many important applications several models need to be combined in a hierarchical manner,such as when biomass models are first developed for single trees and then applied to predict aggregate plot level biomass, which is used as training data for developing a model linking RS data with plot level biomass. In such cases it is not trivial how uncertainties should be estimated. Saarela et al. (2016) developed a method called hierarchical model-based (HMB) estimation and showed that neglecting the uncertainty associated with one of the two models involved might lead to severe underestimation of the uncertainty.The method was further developed in Saarela et al.(2018),although both studies were restricted to use of linear models.
Objectives
The objective of this study was to clarify the link between producing forest statistics for large areas through modelbased inference and mapping of forest resources,providing high spatial resolution maps of aboveground biomass(AGB) and the corresponding uncertainties in terms of root mean square errors (RMSE).This link may be obvious, since model-based inference requires predictions for each map unit, but it is seldom acknowledged in research studies. Data were available from single trees,harvested and measured for developing allometric tree biomass models, field plots from the Swedish National Forest Inventory(NFI),and wall-to-wall airborne LiDAR data acquired in 2009 - 2011. The map units were 18×18 meters large.HMB inference was applied,through an individual tree biomass model and a biomass model linking LiDAR data with aggregate plot-level biomass.An important part of the study was to further develop the HMB inference theory to incorporate nonlinear models.
Material and Method
Overview
Forest attribute maps are usually based on wall-to-wall RS data. In our example, we used airborne wall-to-wall LiDAR data, collected on a national scale in Sweden.Regression analysis was employed to regress the forest attribute plot-level AGB on LiDAR metrics. The AGBLiDAR regression model was trained on field plot data from the Swedish NFI. The plot-level AGB value is a sum of tree-level AGB predictions using field measurements of height and diameter at breast height (DBH),i.e. tree-level AGB was regressed on tree height and DBH. To train the tree-level regression models, hereafter referred to as AGB allometric models, datasets collected by Marklund(1987,1988)were used.Therefore,in our estimation procedure there are two modelling steps involved: the AGB allometric models and the (plot-level)AGB-LiDAR model.
HMB inference was employed to estimate the RMSE and the relative RMSE (RelRMSE) accounting for uncertainties due to both modelling steps. New theory was developed for incorporating nonlinear models in the HMB framework. Through the new theory, the previous derivations of HMB estimators Saarela et al.(2016,2018)could be simplified. A graphical overview of the study is shown in Fig.1.
Study area
Our study area was a rectangular 5005 km2large block located in south-central Sweden. The forest area was approximately 3909 km2, i.e. 78% of the total area. Agricultural lands and urban areas were masked out using land-use maps available through the Swedish National Mapping Agency(Lantmäteriet 2019).The study area was tessellated into 18 m×18 m grid-cells (map units). The map unit size(324 m2)is approximately equal to the area size of the NFI circular field plots described in “Swedish NFI data and AGB-LiDAR regression model”section.The locations of the study area and the clusters of NFI plots are shown in Fig.2.
Swedish national airborne LiDAR survey data
In 2009 the Swedish National Mapping Agency initiated a national airborne LiDAR survey to obtain a new digital elevation model(DEM)with 2 m×2 m spatial resolution.By 2015 almost all forest lands in Sweden were scanned(Nilsson et al. 2017). The scanning altitude was between 1700 m and 2300 m, and the pulse density about 0.5-1 pulses·m-2.
For each map unit and NFI field plot, LiDAR metrics were derived using the Fusion software(McGaughey 2012) following the area-based approach proposed by Næsset(2002)from the height distribution of laser returns between 1.5 m and 50 m height above ground. The upper and lower height thresholds were set to exclude non-vegetation returns (e.g., Lindberg et al. 2012). As regressors in our AGB-LiDAR model,we used two LiDAR metrics:the laser height 80%percentile(hp80)and the vegetation ratio (vr), which is a ratio between the number of first returns above 1.5 m and the total number of first returns. The choice of these variables follows findings in Nilsson et al.(2017).
Swedish NFI data and AGB-LiDAR regression model
Plot-level field data were obtained from the Swedish NFI,which applies a systematic design of clusters with 4-12 plots. We utilized data collected during 2009-2011 from 504 permanent plots located in the study area and in the neighbourhood of the study area(Fig.2).The plot radius was 10 m. A criterion for the plot selection was that the same LiDAR instrument as the one used to collect LiDAR over the study area had been applied.Information on individual tree locations, species, and DBH was available for each tree in all plots. However, tree height was available only for a subsample of the trees (Fridman et al. 2014).Table 1 provides descriptive statistics of the NFI data,separated for each species on trees with and without tree height measurements.
Figure 3 shows a histogram of plot-level AGB, aggregated from the tree-level AGB predictions,and converted to tonnes per hectare (Mg·ha-1). The tree-level AGB values were predicted using the AGB allometric models described in“Tree-level data and AGB allometric models”section.
The plot-level AGB-LiDAR model, denoted as theGmodel in our study, has a model form similar to Nilsson et al. (2017). However, whereas Nilsson et al. (2017)used a standard square root transformation model, we applied a similar nonlinear model with additive errors including the same LiDAR metrics (see Table 2). We employed the restricted maximum likelihood estimators available in the R package nlme (Pinheiro et al. 2016)through the gnls() R function. To overcome problems due to heteroskedasticity, we fitted a random error variance model to estimate the individual error variance for every predicted plot-level AGB value.Table 2 presents the estimated model parameters.Figure 4 shows the standardized residuals for plot-level AGB predictions from LiDAR metrics,displayed versus predicted plot-level AGBs using LiDAR metrics, and (lower) LiDAR-based predictions ofplot-level AGB displayed versus AGBs obtained from field measurements, i.e. the AGBs obtained from aggregating tree-level AGB predictions to plot level. Although the Swedish NFI applies clusters of plots, the long distance between plots in a cluster implied that we treated each plot as an independent observation in the regression analysis(cf.Nilsson et al.2017).
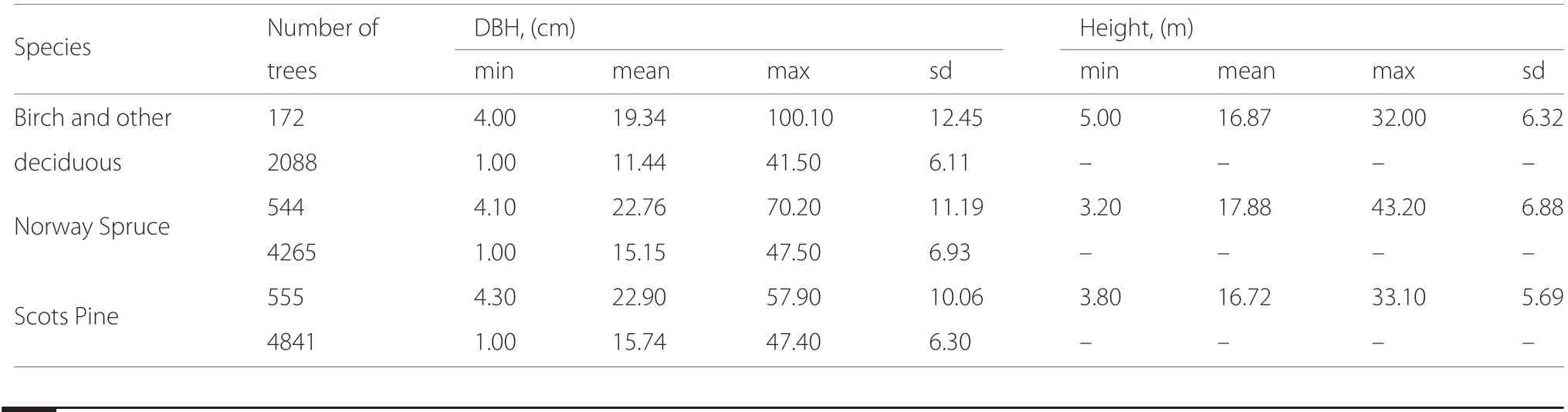
Table 1 NFI tree-level data descriptive statistics separated for each tree species on trees with and without height measurements
Tree-level data and AGB allometric models
The tree-level data used for developing AGB allometric models were collected across Sweden by Marklund(1987,1988).We used data collected only from the central and southern parts of Sweden(Table 3).
Since heights were not available for all trees on the NFI plots (Fridman et al. 2014), we developed two AGB allometric model types for each tree species: one with DBH(cm) and height (m) as regressors (type I), and the other with DBH(cm)only(type II).In our study we used AGB allometric model forms by similar to Repola (2008) for birch and Repola (2009) for pine and spruce. Table 4 presents the models forms by species.
In Table 4,ykis a tree-level AGB (kg) for thekthtree based on data from Marklund (1987, 1988);dtrk= 2 +1.5×DBHkis a transformation of DBH (cm) to approximate the stump diameter (Laasasenaho 1982),hkis the tree height (m), andβ0,β1andβ2are AGB allometric model parameters to be estimated.
The R function gnls()(Pinheiro et al.2016)was used to fit model parameters accounting for heteroskedasticity.Table 5 presents the estimated model parameters.
Figure 5 shows residual scatterplots,and Fig.6 presents scatterplots for AGB versus predicted AGB at tree level.

Table 2 Estimated AGB-LiDAR model parameters
Generalized hierarchical model-based estimation with nonlinear models
HMB inference is based on the model-based inference philosophy (Saarela et al. 2018). The target population(of map units with AGB as the population attribute in our example) is seen as a random realization shaped by a superpopulation model involving some auxiliary information.If there is more than one superpopulation model involved and if the estimation procedure employs the models in a hierarchical order, we can speak of HMB inference(Saarela et al.2018).We denote the first superpopulation model, linked to the AGB allometric models(as will be shown in more detail below),asF

Table 3 Tree-level data;descriptive statistics(Marklund 1987,1988)

Table 4 AGB allometric model forms by species
The model describes the relationship between AGB(y)andpfield-measured variables at plot level, i.e. x =(1,x1,x2,...,xp). The dataset, used to estimate the model parameters,is denotedS.
AGB predictions for the NFI plots are denotedFSa,i.e.a vector of predicted AGB using theFmodel. Here,Sadenotes the 504 NFI field plots, for which LiDAR metrics also available. The datasetSawas used to train the AGB-LiDAR model described in “Swedish NFI data and AGB-LiDAR regression model”section.The model is the second model in our modelling chain, and its general form is:
Here, AGB (y) is regressed onqLiDAR metrics, z =(1,z1,z2,...,zq). However, instead of the unknown actual AGB(y)the predicted AGB(FSa)is used in the analysis to estimate the model parameters in theGmodel(Eq.(2)).
Covariance matrix of estimated model parameters when applying two models in hierarchical order
The covariance matrix of estimated model parametersSais a core component model-based inference (e.g.,McRoberts 2006; Ståhl et al. 2011, 2016, Saarela et al.2015b).Since theSaestimator is dependent on the AGB predictionsFSa,Cov(Sa)can be expressed conditionally onFSausing the law of total covariance (e.g., Rudary 2009)
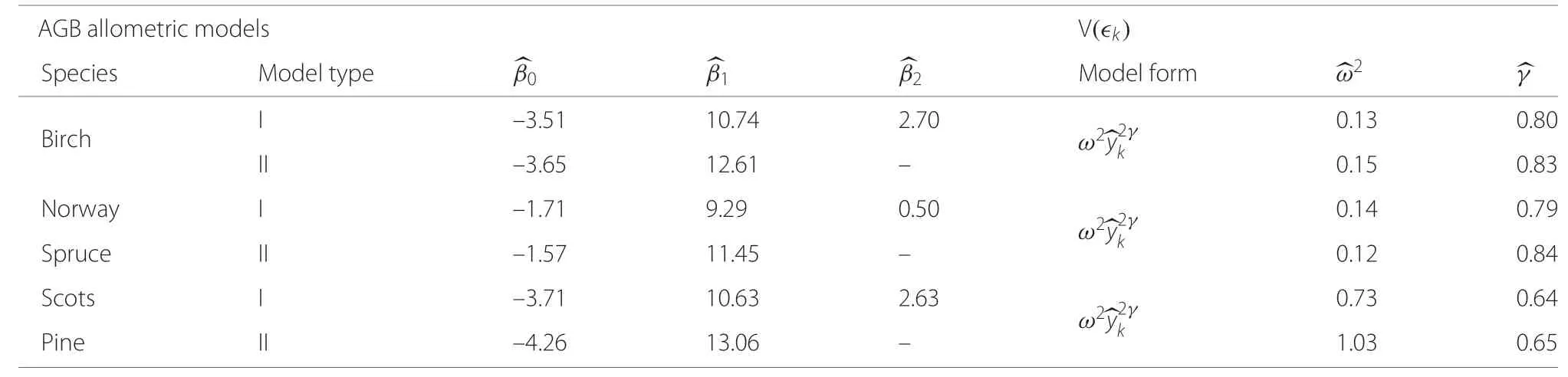
Table 5 Estimated parameters in the AGB allometric models
This is a new way of deriving HMB estimators, compared to Saarela et al. (2016) and Saarela et al. (2018), in which cases only linear models could be applied.The new approach, through conditional covariance, simplifies the theoretical procedure and allows use of nonlinear models within the HMB estimation framework.Details are given in Additional file 2.
It can be observed that the first term on the rightside part of (6) can be expressed as the model-based,generalized nonlinear least squares (GNLS) covariance of estimated model parameters (e.g. Davidson and MacKinnon 1993)conditionally onFSa,i.e.
Results
The mean and total AGB in the study area were estimated through HMB estimation,thus combining tree level allometric modelling, aggregation of tree level predictions to NFI plot level, developing AGB-LiDAR models from the aggregated predictions,and applying the AGB-LiDAR models to all non-masked map units in the study area.The resulting estimates and uncertainty estimates are presented in Table 6.In the table the proportion of the total MSE that is due to the tree-level allometric model uncertainty is also shown.It can be observed that it accounts for a large portion,about 75%,of the total MSE.
As an add-on to these basic estimates for the study area,HMB also allows for mapping of AGB and the RMSE of the AGB estimates at the level of 18 m×18 m map units.In Fig.7,maps of predicted AGB,estimated RMSE,estimated RelRMSE,and the relative contribution of allometric modelling variance to the total MSE are shown for a small portion of the study area. The map products for the entire study area are available via the link:Supplementary Material.1It is a‘tif’file,which can be opened in any GIS software or in R Statistical Environment.
It can be noted that RelRMSE was mostly large at small predicted AGB values,which is normal due to the denominator being a small number. Exploring this relationship further,in Fig.8 the RMSE is displayed vs predicted AGB(left), the relative RMSE vs predicted AGB (right), and the proportion of the total MSE due to the allometric modelling (below). The proportion of the total MSE due to the allometric modelling reached a minimum when the AGB predictions were about 55 tonnes per hectare,corresponding to the estimated population mean.
Discussion
In this study we have demonstrated the correspondence between mapping and formal model-based estimation of aboveground forest biomass for a large study area in south-central Sweden.While a large number of RS-based studies focus on biomass mapping (e.g., Wallerman et al. 2010; Santoro et al. 2012; Nilsson et al. 2017), fewer studies address statistically sound estimation for large areas (e.g., McRoberts 2010; Ståhl et al. 2011; Saarela et al. 2015a; Gregoire et al. 2016), and even fewer studies the link between mapping and large-area estimation,although,e.g.,Esteban et al.(2019)is an exception.
In our study we show how the integration of mapping and estimation can be further elaborated, through mapping not only the biomass as such but also of its uncertainty.Uncertainties from two modelling steps were accounted for, i.e. both the uncertainty due to AGB allometric models at tree level and due to the model linking plot-level biomass with LiDAR metrics, the AGB-LiDAR model. We showed that the relative uncertainty (Rel-RMSE)was largest at small biomass values,but decreased rather quickly and remained more or less constant at biomass predictions for biomass values of 75 Mg·ha-1.and greater.Compared to Esteban et al.(2019),who studied biomass change in Norway and Spain, our estimated uncertainties appear to be larger, most likely as a result of our inclusion of two modelling steps in the uncertainty estimation.
An interesting pattern was observed when the proportion of the total MSE due to the allometric model uncertainty was displayed versus predicted AGB (Fig. 8).The pattern was U-shaped,with large contributions from the allometric modelling at small and large biomass predictions,but with rather limited contribution around the average predicted value.The likely reason for this pattern is that regression models tend to be precise around mean observed values but less precise towards the extremes,with regard to the observations (Davidson and MacKinnon 1993).Thus,this pattern is likely due to the pattern of tree-level data from the tree biomass dataset in Marklund(1987,1988)combined with the AGB-LiDAR model.
Another interesting pattern is visible in the scatterplots of Fig. 8. The point clouds appear to be forked with a large number of observations at the lower and upper extremes. A likely reason for this is the combined effect of species-specific models and the two allometric model types developed for each species.Obviously,the AGB allometric models using only DBH as a predictor variable will result in larger prediction uncertainty than models based on both tree height and DBH.
The development of a theoretical framework for incorporating nonlinear models into HMB estimation was an important part of the study, which required a new approach for developing HMB estimators compared to previous studies Saarela et al.(2016,2018).With the proposed decomposition of the covariance matrix estimator any nonlinear models could be applied in HMB, in case the objective is to estimate the variance of an estimator of the expected value of the superpopulation mean or total.However, in case the objective is to estimate the MSE of the actual superpopulation mean or total,or the MSE for predictions at the level of map units,only nonlinear models with additive error terms can be applied. Since our objective was to construct uncertainty maps at the level of individual map units a nonlinear model with an additive error term was selected.
The new framework makes it possible to trace uncertainties due to several modelling steps. In our case two modeling steps were included. However, the covariance decomposition approach makes it straightforward to derive variance estimators also for cases with three or more modelling steps. Thus, the new HMB framework would also allow for targeted improvement ofAGB maps, since it can be evaluated what modelling step(s) would be most beneficial to improve from the point of view of obtaining small overall uncertainty.

Table 6 Estimated population mean and total,and corresponding uncertainties,and the allometry uncertainty contribution to overall MSE
Maps of stand characteristics,such as biomass and volume, constructed using LiDAR data, can be expected to be increasingly demanded for planning forestry operations in the future. Our results indicate that the type of models involved provides accurate results,in terms of Rel-RMSE, in old and middle-aged stands, i.e. stands with intermediate and large AGB values. However, in young forests(small biomass values)the uncertainties were large,suggesting that other types of data should be applied. In future applications it might be possible to bring additional modelling details into the HMB framework,making it possible to distinguish uncertainties not only betweendifferent estimated biomass levels, but also between different species and site conditions.This would require new types of data,such as tree species data derived from multispectral LiDAR (Axelsson et al. 2018). The uncertainty maps would then provide additional information to forest planners.
An interesting next step regarding uncertainty mapping would be to move from map units to stands. This would require aggregation of map units through segmentation(e.g., Olofsson and Holmgren 2014). Stand level uncertainty maps would also require information about the spatial autocorrelation of model errors within stands,which would be a challenge.However,several approaches for this type of small area estimation are available (e.g., Breidenbach and Astrup 2012;Magnussen et al.2014)and should be evaluated for application in the HMB framework.
A final remark concerns the difference between hierarchical model-based inference and similar techniques such as conventional model-based inference (e.g., McRoberts 2006),hybrid inference(e.g.,Ståhl et al.2011),and designbased inference through model-assisted estimation (e.g.,Gregoire et al. 2011). A large number of studies performed during the last decades focus on assessment of biomass and carbon, and related uncertainties, applying techniques that may appear similar to the technique applied in this study. Examples include Petersson et al.(2017);McRoberts and Westfall(2016)and McRoberts et al. (2016). In the latter study, Monte-Carlo simulation is applied to assess the overall uncertainty in growing stock volume estimation schemes involving several modelling steps.
Conclusions
In this study a new approach to developing HMB estimators was derived, making it possible to apply nonlinear models, as well as combinations of linear and nonlinear models, in the HMB estimation framework.The estimators were applied to a study area in southcentral Sweden, and it was shown that the relative uncertainties in the biomass predictions were largest when the predicted biomass was small. Further it was demonstrated how biomass mapping, uncertainty mapping, and estimation of the mean biomass across a large area could be combined through HMB inference.Uncertainty maps of the kind presented in this study allow for judgments about whether or not the forest attribute map is accurate enough for the intended decision making.
Supplementary information
Supplementary informationaccompanies this paper at https://doi.org/10.1186/s40663-020-00245-0.
Additional file 1:Supplementary material.
Additional file 2:Appendix.
Acknowledgements
The authors are thankful to the two anonymous Reviewers,whose comments helped to improve the clarity of the article.
Authors’contributions
Conceptualization,Svetlana Saarela;Data curation,Svetlana Saarela,André Wästlund,Alex Appiah Mensah,Mats Nilsson and Jonas Fridman;Fundingacquisition,Svetlana Saarela;Investigation,Svetlana Saarela,André Wästlund,Emma Holmström,Alex Appiah Mensah,Sören Holm,Mats Nilsson,Jonas Fridman and Göran Ståhl;Methodology,Svetlana Saarela,Sören Holm and Göran Ståhl;Project administration,Svetlana Saarela;Software,Svetlana Saarela,André Wästlund,Alex Appiah Mensah and Mats Nilsson;Writing–original draft,Svetlana Saarela;Writing–review&editing,Svetlana Saarela,André Wästlund,Emma Holmström,Alex Appiah Mensah,Sören Holm,Mats Nilsson,Jonas Fridman and Göran Ståhl.The author(s)read and approved the final manuscript.
Funding
Fundingwas provided by the Swedish NFI Development Foundation and the Swedish Kempe Foundation(SMK-1847).The computations were performed on resources provided by the Swedish National Infrastructure for Computing(SNIC)at the High Performance Computing Center North(HPC2N).
Availability of data and materials
The data are available upon a reasonable request to the Authors.
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare no conflict of interest.
Received:10 October 2019 Accepted:24 April 2020

- Forest Ecosystems的其它文章
- Soil-plant co-stimulation during forest vegetation restoration in a subtropical area of southern China
- Addressing soil protection concerns in forest ecosystem management under climate change
- Species richness,forest types and regeneration of Schima in the subtropical forest ecosystem of Yunnan,southwestern China
- Effects of afforestation of agricultural land with grey alder(Alnus incana(L.)Moench)on soil chemical properties,comparing two contrasting soil groups
- Delineating forest stands from grid data
- Tree diversity effects on forest productivity increase through time because of spatial partitioning