
Allometric models for estimating aboveground biomass in the tropical woodlands of Ghana,West Africa
2020-10-20 08:21RaymondAabeyirStephenAduBreduWilsonAgyeiAgyareandMichaelWeir
Forest Ecosystems 2020年3期
Raymond Aabeyir ,Stephen Adu-Bredu,Wilson Agyei Agyare and Michael J.C.Weir
Abstract
Keywords: Charcoal, Diameter at breast height, Tree height, Wood density,Savannah woodland
Introduction
Forest and woodland ecosystems are important carbon stocks and their conservation is one of the sustainable mitigation strategies for the increasing global warming that confronts the world today (Löf et al. 2019). As atmospheric CO2concentration and its effect on global climate change continues to increase, modelling aboveground biomass (AGB) of forest and woodland ecosystems is needed to provide information on the global carbon budgets (Litton and Kauffman 2008; Henry et al.2011; Ekoungoulou et al. 2018).
Currently, there is an urgent need for reliable and accurate biomass estimates from forests and woodlands,especially in Africa, where inadequate biomass and carbon emission data exist (Jibrin and Abdulkadir 2015). It has been observed that countries in sub-Saharan Africa do not have sufficient biomass models to report national carbon stocks and their variation under the Tier-2 and Tier-3 approaches of Intergovernmental Panel on Climate Change (IPCC) (Henry et al. 2011). A tier represents a level of methodological complexity and accuracy in the estimation of tree biomass. The Tier-1 method is based on the use of generalized equation to estimate biomass, while Tier-2 method is based on the use of species-specific volume equations to convert the volume of trees to biomass using wood density and default biomass expansion factors (Henry et al. 2011). The Tier-3 method consists of application of species-specific biomass equations to calculate the biomass of trees (ibid).Thus, the Intergovernmental Panel on Climate Change(IPCC) Tier-2 or Tier-3 approaches requires that national greenhouse gas estimates be based on countryspecific data or models (IPCC 2006).
Accurate biomass and carbon estimates in Africa cannot be adequately realized without accurate allometric models (Henry et al. 2011; Adu-Bredu and Birigazzi 2014). These models are fundamental tools for estimating biomass based on easily measurable variables of a tree, in particular, diameter at breast height, total height and wood density (Williams et al. 2008; Adu-Bredu and Birigazzi 2014; Roxburgh et al. 2015). The development of allometric models for Africa will significantly improve the quality of biomass estimates under the UN-REDD+programme (Henry et al. 2011; Adu-Bredu and Birigazzi 2014; Ekoungoulou et al. 2018). This will enable Africa to gain meaningful financial benefits from carbon sequestration, or CO2emission reduction through management of terrestrial woody biomass (Henry et al. 2011;Adu-Bredu and Birigazzi 2014). Furthermore, it will reduce uncertainty in the estimation of AGB carbon due to spatial variability of AGB, which has been acknowledged as the largest source of uncertainty in estimating tree biomass (Henry et al. 2011; Chave et al. 2014; Adu-Bredu and Birigazzi 2014).
Although allometric models for Africa exist (West 2004; Brown et al. 2005; West 2009; Henry et al. 2010;Henry et al. 2011; Mbow et al. 2013; Addo-Fordjour and Rahmad 2013), these are generally limited in their applications by the dbh range used for the model calibration,uneven distribution of the dbh within the dbh range, the type and number of tree species used in developing the models, ecological zones, and the type and number of explanatory variables used (Chave et al. 2005; Basuki et al. 2009; Henry et al. 2011; Mbow et al. 2013; Youkhana et al. 2017; Weber et al. 2017). Due to lack of local allometric models for some ecological zones, some sub-Saharan African countries rely on pantropic models such as the ones developed by Chave et al. (2014) for the estimation of local AGB. Although such pantropic models have a wide range of species from different ecological zones with wide calibration ranges, they are still not a panacea to the growing need for local allometric models across the continent.In view of this, more efforts are required to develop local allometric models for assessing tree carbon stock of forests and woodlands to enable a better understanding of the contribution of local anthropogenic influence on atmospheric CO2in Africa (Bjarnadottir et al. 2007; Henry et al. 2011).
In Ghana, the need for more locally applicable allometric models remains a national issue despite the efforts of Adu-Bredu et al. (2008), Henry et al. (2010) and Addo-Fordjour and Rahmad (2013) in the development of allometric models. Adu-Bredu et al. (2008) developed species-specific stem profile model for Tectona grandis in the forest and savannah ecological zones of Ghana,but it is for the estimation of stem volume, while Henry et al. (2010) and Addo-Fordjour and Rahmad (2013)modelled above-ground biomass of mixed-species in the forest ecological zones. Currently, there is no existing local allometric model to estimate AGB in the savannah woodlands of Ghana, where charcoal production greatly influences the AGB of the woodlands. Therefore, any estimation of AGB in the savannah woodlands will require the applications of pantropic models or local models from other geographic areas. However, the existence of important variations in wood density, volume and biomass between and within ecological zones and tree species make the application of local models from other geographic areas and pantropic models a serious challenge as they lead to significant bias and error in estimating AGB (Navar 2009; Henry et al. 2011). The lack of local allometric models to estimate AGB and CO2emissions in these ecosystems of the country is a major setback to efforts aimed at determining accurate carbon budgets for both national and global uses.
As part of its obligation to the United Nations Framework Convention on Climate Change(UNFCCC),Ghana submitted its Intended Nationally Determined Contribution (INDC) in 2015 (GH-INDC 2015), in which both mitigation and adaptation measures were put forward.Seven economic priority sectors were proposed, with sustainable forest management, which serves as both mitigation and adaptation measures, being one of them.Ghana is developing Good Practice Guidance (GPG) for estimating, measuring, monitoring and reporting on carbon stock changes and greenhouse gas emissions from land use, land-use change and forestry (LULUCF) activities (IPCC 2003). Currently, it is not certain how Ghana would be able to meet Tier 2 and 3 of IPCC requirements and develop GPG for monitoring, measuring and reporting carbon stock without developing local allometric models for the savannah woodlands ecosystem. There is the need to develop allometric models for accurate carbon accounting within the savannah woodlands where the use of trees for charcoal production is a primary livelihood activity (Aabeyir et al. 2016; Sedano et al. 2016).
There is the need for effective accounting of the contribution of woodlands to both national and global carbon budgets, and also in the estimation of AGB for payments of ecosystem services provided by forest-based climate change mitigation activities (Wunder 2005). Accurate estimation of AGB will contribute to the achievement of Ghana’s commitments under the United Nations Framework Convention on Climate Change(UNFCCC) (Cienciala et al. 2006). However, pantropic models are being widely used although significant bias in their estimates has been reported by Henry et al. (2010),Alvarez et al. (2012) and Lima et al. (2012) in Ghana,Columbia and Brazil, respectively. This emphasizes the need to test the validity of the pantropic models in specific environments. It is therefore hypothesised that locally developed mixed models are superior to pantropic models in estimating AGB. The objectives of this study are to (i) develop a local mixed-species allometric model for use in estimating AGB in the savannah woodlands of Ghana; and (ii) assess if there is a significant difference between the estimates of the local model and the pantropical model of Chave et al. (2014).
Materials and methods
Study area
The Kintampo Municipality of Ghana, lies between latitudes 7°45′ N and 8°50′ N and longitudes 1°0′ W and 2°5′ W with a surface area of about 5108 km2(Fig. 1). It is located at the centre of Ghana and serves as a transit point between the northern and southern parts of the country. The municipality is part of the Forest-Savannah transition zone of Ghana which is located between the forest ecological zone in the south and the savannah ecological zone in the north of the country (Codjoe and Bilsborrow 2011). The area exhibits aspects of both savannah and forest conditions, although it is more inclined to savannah conditions than forest ones since it has lost most of its original forest cover due to anthropogenic activities (Afikorah-Danquah 1997; Codjoe and Bilsborrow 2011). Common trees species adapted to this environment are Daniellia oliveri, Burkea africana,Khaya senegalensis, Parkia biglobosa, Terminalia macroptera, Acacia sp., Pterocarpus erinaceus and Vitelaria paradoxa. These trees have relatively more branches than a typical tree in the forest zone of Ghana. One major use of these trees (i.e. trunk, branches, and twig of trees) is charcoal production (Blay et al. 2007; Quaye and Stosch 2008; Iiyama et al. 2014).
Charcoal production is based on selective harvesting of tree species and, in recent years, has become such an important land use that its place in the carbon budget cannot be ignored or categorized along with other land uses. Charcoal producers normally prefer trees of hard wood and large sizes depending on the experience and tools available for harvesting the trees (Aabeyir et al.2016).
Mean monthly temperature in the area ranges from 30°C in March to 24°C in August, with a mean annual temperature between 26.5°C and 27.2°C. Relative humidity varies from 90% to 95% in the rainy season and 75% to 80% in the dry season (Codjoe and Bilsborrow 2011). Mean annual rainfall is between 1400 and 1800 mm, and shows a bimodal pattern, with the major season occurring between May and August and a minor season between September and October (Codjoe and Bilsborrow 2011).
Sampling
Data for the study were collected from October 2013 to May 2015 in the Asantekwa, Attakura and Kunsu communities of the Kintampo Municipality. In allometric modelling, representation of tree population in terms of species types, diameter at breast height (dbh) and wood density are critical. This is usually achieved through stratification of the study area into homogenous sections and stratification of the tree sizes into dbh classes (Pearson et al. 2007). However, it is very challenging and expensive to harvest a representative sample of each tree species under field conditions. One strategy is to harvest all trees of the desired dbh range within a given small area and repeat the harvest in other areas within the larger study area in order to increase the sample size (Picard et al. 2012). This has the advantage of providing both a biomass estimate for the stand and individual observations for the construction of a model, although the dbh size class distribution in the sample might not correspond to the desired dbh class distribution (ibid).
In this study, an approach similar to Picard et al.(2012) was adopted. Portions of woodlands acquired for charcoal production were selected for the destructive harvesting of trees. The study area was stratified into three strata based on geographic location: north, east and west with reference to the municipal capital. This was done to increase the variability of the tree species harvested for the modelling. One community was selected from each stratum based on its role in charcoal production. Asantekwa community was selected from the western stratum, Attakura from the north and Kunsu from the eastern stratum (Aabeyir et al. 2016).Asantekwa and Kunsu were further stratified to increase variability due to locations of production sites because the majority of the charcoal producers were in these communities. Asantekwa was stratified into three using the Kintampo-Asantekwa-New Longoro and Asantekwa-Sabuli roads while Kunsu was stratified into two strata based on the Kunsu-Urukwan roads. A total of 23 sites were harvested, 10 in Asantekwa, 1 in Attakura and 12 in Kunsu.
Measurements on harvested trees
The dbh, height and coordinates of each tree, earmarked for harvesting, were measured before being felled by the charcoal producers. The dbh was measured at 1.30 m above ground (Zianis and Mencuccini 2004) with a dbh fibre tape while the height was measured with a Haga Hypsometer. The trunk and large branches of the felled trees were cut into smaller logs suitable for charcoal production. The girths at both ends of the logs, as well as their lengths were measured. In the case of curved logs and branches, the length was measured along the inner curve (Purser 1999). Disk samples were collected from the base, middle and top of the trunk, and also from large branches. The samples were taken in such way to capture the variation of the wood density along the trees since density is typically greater at the base of the stem than at its top (Weber et al. 2017). The disk samples were taken to the laboratory for wood density determination. They were then cut into rectangular samples of 2 cm × 2 cm × 10 cm, from the periphery to the pith to capture density variation within the tree. The width, breadth and length of each rectangular sample were re-measured with a vernier calliper to avoid errors due to cutting. The measurements were used to compute the volume of the rectangular samples.The samples were then oven-dried to constant mass at 105°C to ensure that all the bound water was removed from the wood. The choice of the oven temperature was based on recommendations of Williamson and Wiemann (2010)that temperatures of 101°C to 105°C drives off bound water in wood.
The small branches, twigs and leaves were grouped separately and their fresh weight determined using a hanging balance. Samples were taken from the small branches, twigs and leaves and oven-dried at 60°C to constant mass of for dry to fresh mass ratio determination.
The density (ρ) of each sample was thus calculated from the volume and dry mass using Eq. 1:
where ρiis the density of species i, miis the mass of sample from species i,and viis volume of the sample.
Data processing and analysis
The dry mass of the small branches, twigs and leaves was computed from the total fresh mass and the sample dry to fresh mass ratio of the respective organs. For the trunk and large branches, each log was treated as a truncated cone and the truncated cone formula (Eq. 2) used for computing the volume (Mattson et al. 2007; Picard et al. 2012; Akossou et al. 2013).
where, VLis the volume of the log, L is the length, G and g are the girths of the larger and smaller ends of the log, respectively. Although there are several formulae for estimating log volumes (Hubert, Newton, Smalian, truncated cone formulae, etc.), the truncated cone formula was chosen for estimating the log volume since it is less influenced by length of the log compared to the others.Soares et al. (2010) observed that length of logs influenced the accuracy of estimated volume. A Microsoft(MS) Excel Pivot Table was used to aggregate volumes of logs according to individuals of various tree species.
The wood density (ρ) of each species was finally computed as the average of the densities of all samples of each tree species. The wood density was multiplied by the volume to obtain dry mass of the log. The use of this indirect method of estimating the mass of harvested trees was based on field trials conducted in early October 2013 prior to the data collection. During the trial, it was difficult, time consuming and labour intensive to weigh large logs directly in the field, as observed by Henry et al. (2011). The total mass of each tree was thus computed as the sum of the mass of individual logs,small branches,twigs and leaves.
Modelling process
Data description
The data used for the modelling comprises the diameter at breast height (dbh, cm), total tree height (m) and wood density (g·cm-3) of 745 individuals of 31 tree species (Tables 1 and 2) that were harvested for charcoal production in 23 different sites in the study area. The dbh of individual trees ranged from 5.0 to 48.2 cm, average total tree height from 6.6 to 18.6 m and wooddensity from 0.52 to 0.89 g·cm-3. The dbh of most of the individual trees in the data were within the 5.0 to 14.9 cm and 15.0 to 24.9 cm dbh classes, the number of trees being 367 and 285, respectively.Only three individual trees were within the uppermost dbh class of 45.0-54.9 cm. The height of most of the trees were within 5.1 to 10.0 m and 10.1 to 15.0 m height classes (354 and 312 trees, respectively). Only four trees were in the 20.1 to 25.0 m height class. Most of the species harvested in the study area (Table 2)have been cited by the charcoal producers as suitable species for charcoal production.
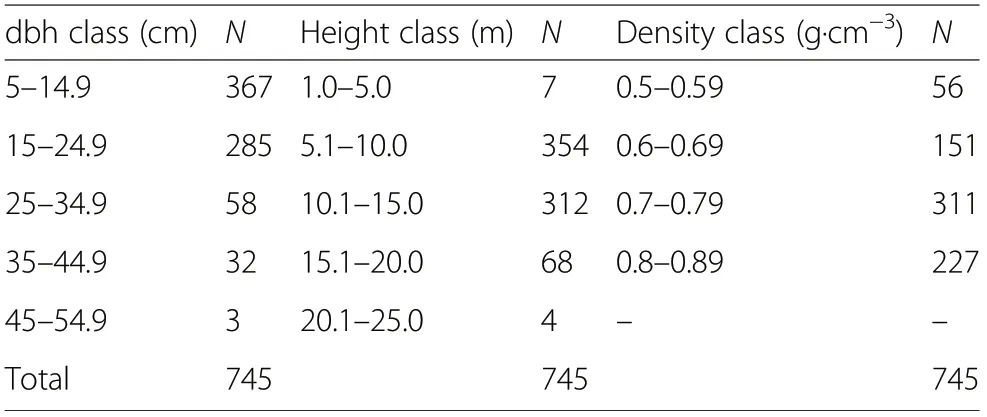
Table 1 Distribution of number of harvested trees within diameter at breast height(dbh), total tree height(Ht) and wood density (ρ) classes
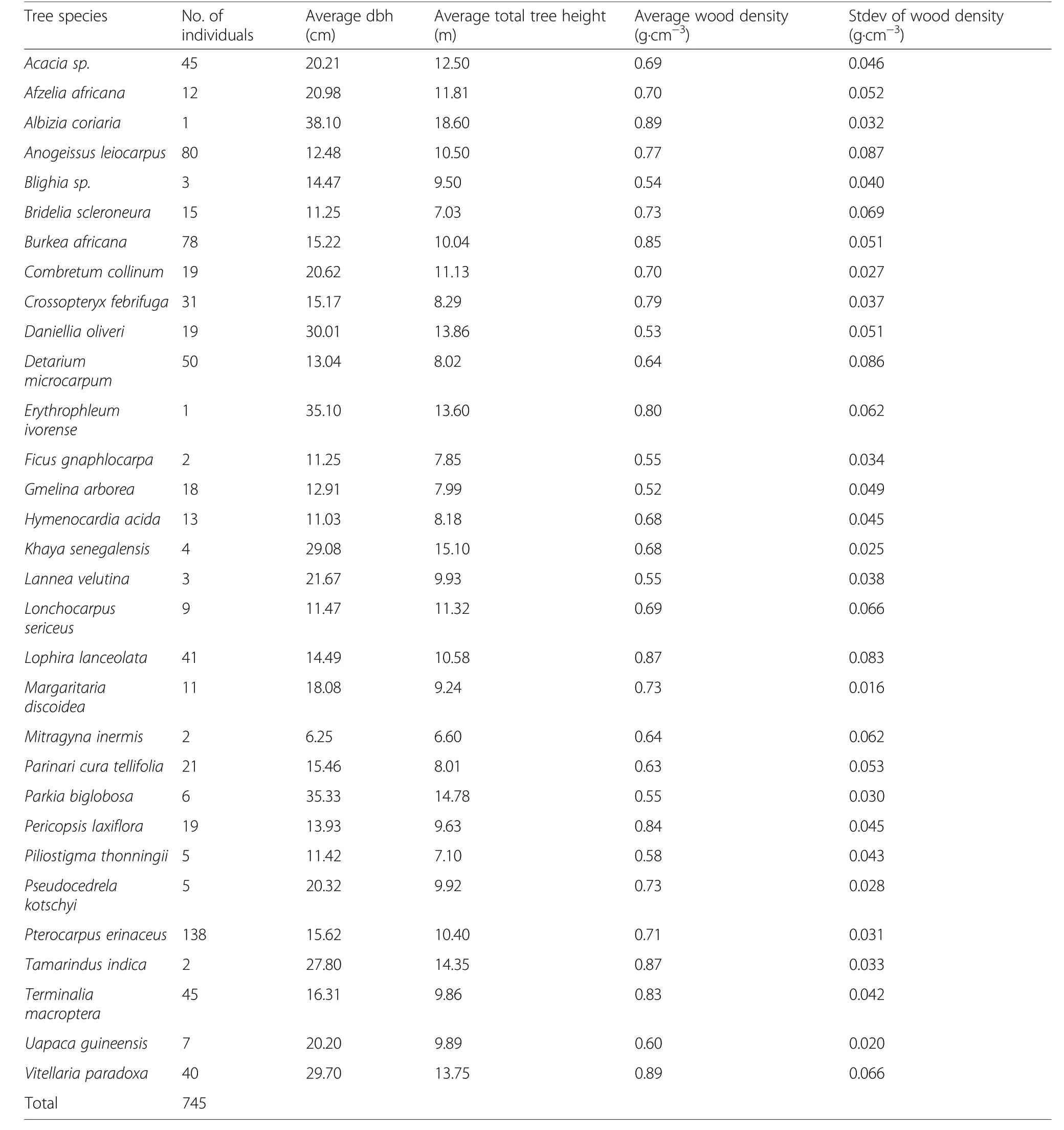
Table 2 Average diameter at breast height(dbh), total tree height(Ht) and wood density (ρ) of the harvested tree species
Model formulation and fitting
The power-law function formed the basis of the allometric model,with diameter at breast height (dbh),total tree height (H) and wood density (ρ), as predictors of biomass (Chave et al. 2005; Chave et al. 2014; Sileshi 2014). This assertion was validated during data exploration in MS Excel by fitting a power function to the data. The use of only dbh alone as a predictor of AGB is widely acknowledged compared to the inclusion ρ and H (Chave et al.2005;Chave et al.2014).However,Chave et al.(2005)and Chave et al.(2014)observed that H(dbh)2,ρ(dbh)2and ρ(dbh)2H are also suitable predictors of aboveground biomass (AGB). In their experience, the inclusion of wood density as a predictor improves the prediction of AGB, especially when a wide range of species is used.
Chave et al. (2004), Sileshi (2014) and Youkhana et al.(2017) observed that the choice of model form, in terms of both predictors and model parameters,is important because it constitutes a significant source of error in biomass estimation. In view of this, seven different forms of allometric models were formulated based on different combinations of the predictors[(dbh)2b1,ρ(dbh)2b2,(ρ(dbh)2)b3,H(dbh)2b4, ((dbh)2H)b5, ρ((dbh)2H)b6, (ρ(dbh)2H)b7] in order to observe and compare the effects of the different model forms on AGB estimates and how the allometric exponent influences the model form (Table 3). The seven model forms were categorized into four (I, II, III and IV)based on the combinations of the predictors. Category I had dbh as the only predictor and formed the basis for the other categories. Category II combined dbh and ρ, while category III combined dbh and H as predictors. The last category,IV had all the predictors(dbh,ρ,H).
Model parameterization
In Table 3, a1,a2, a3, a4, a5, a6, and a7are allometric coefficients, whereas b1, b2, b3, b4, b5, b6, and b7are the allometric exponents. The three predictors were tested for collinearity based on the Variance Inflation Factor(VIF). Sileshi (2014) recommended that VIF of more than 5 is an indication of significant collinearity between predictors. The VIF of the predictors were all less than 5(Table 4).
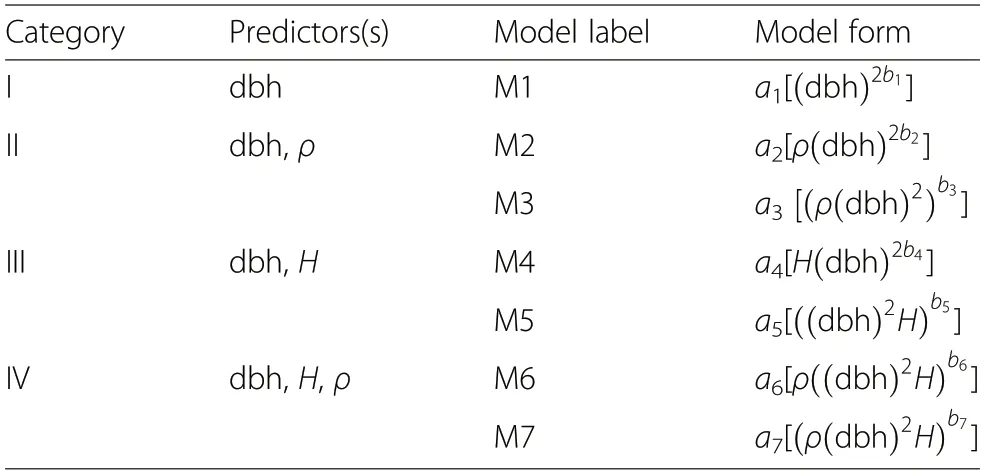
Table 3 Combination of predictors and model forms to be calibrated

Table 4 Test of collinearity of predictors based on the Variance Inflation Factors (VIF)
The choice of an appropriate method, namely linear or non-linear regression, for estimating model parameters has been a subject of debate (Packard and Birchard 2008; Xiao et al. 2011; Mascaro et al. 2011; Packard et al. 2011;Packard 2013;Mascaro et al.2014).However,Xiao et al. (2011), Lai et al. (2013) and Sileshi (2014) are of the view that the choice between linear and nonlinear regression should be informed by the statistical distribution of the error. They recommend that if the statistical error is normally distributed and additive, then non-linear regression is appropriate whereas, if the error is lognormal and multiplicative, then linear regression is appropriate.
However, Ketterings et al. (2001) argued that it makes no difference whether the biomass of individual trees is considered to vary by an amount with a mean of zero(as applied to non-linear models) or varying around a mean of one (as applied to linear models). What is most important is the variance of deviations of the biomass.They observed that either the standard deviation of biomass is proportional to its mean, or the variance is proportional to the square of the mean of the biomass.Hence in this study, non-linear regression (Eq. 3) was used, assuming the variance is proportional to the square of the mean of the biomass as recommended by Ketterings et al. (2001).
where Biis mass of tree i, Diis diameter at breastheight, μiis mean biomass of all trees with diameter Di,a and b are the allometric coefficient and exponent, respectively and φ is the dispersion parameter.
The scaling coefficient and exponents of Eq. 3 are reported to vary with species, stand age, site quality, climate and stocking of stands (Zianis and Mencuccini 2004).The allometric constant is a normalization or proportionality constant (Sileshi 2014). It is observed that when b >1, total AGB increases relatively faster than the predictor, and allometry becomes positive (Bervian et al.2006). The reverse occurs when b <1 and the relationship is said to be negative allometry. When b=1, allometry is said to be isometric, implying that AGB and predictor(s) are proportional to each other. The scaling exponent (b) influences AGB significantly and has been given prominence in literature (Zianis and Mencuccini 2004; Bervian et al. 2006; Sileshi 2014). Thus a theoretical value of b=8/3 has been referred to in literature and has been the basis of comparison of empirical values of b.However, Zianis and Mencuccini (2004) are of the view that having a universal value for b does not allow for flexibility in different datasets, implying that the ratio of the specific growth rates of mass (B) and D for different tree species growing in totally diverse environments should remain constant, contrary to the understanding of physiological and ecological processes. The models were parameterized using SAS 9.0 software PROC NLIN.
Model evaluation and comparison
A combination of graphical and statistical evaluation methods was used to assess the goodness-of-fit of the models since no single method is adequate enough (Hui and Jackson 2007; Soares and Tomé 2007; Hevia et al.2013; Tewari et al. 2014). Pineiro et al. (2008) observed that for graphical evaluation of model performance, a plot of observed versus predicted is preferred to predicted versus observed. In the case of the former, it is expected that for a perfect fit, the slope would be 1.0,while the y-intercept would be 0, then dispersion in data is due to random error. Deviations from values indicate a bias (systematic error) in the predictions.
The statistical criteria used in this study were Model Efficiency (MEF) (Eq. 4), model bias (Ē) (Eq. 5) and Corrected Akaike Information Criterion (AICc) (Eq. 6). The MEF quantifies the proportion of the total variance that is explained by the model, accounting for the number of parameters and observations (Soares and Tomé 2007;Hevia et al. 2013). It provides a simple index of performance on a relative scale with 1.0 indicating a perfect fit,0.0 showing a model performance not better than average, and negative values indicating very poor model performance (Soares and Tomé 2007). The bias is a measure of systematic deviation of model predictions from observed data. Huang et al. (2003) recommended that a bias (%)<± 10% at 95% confidence level is acceptable.
where yiis the observed AGB, ŷiis predicted AGB, ȳ is the mean of the observed AGB, n is the number of individual trees and k is the number of parameters.
The Corrected Akaike Information Criterion (AICc)(Eq.6)was used to compare and select the best performing model among candidate models (Chave et al. 2005;Fayolle et al. 2016). AICcis a measure of the trade-off between model goodness-of-fit and the model complexity (number of input parameters) (Chave et al. 2005;Heikkinen et al. 2006; Migliavacca et al. 2012; Tang et al. 2014). It measures the goodness-of-fit of models and penalizes models with more input parameters, according to the principle of parsimony (Burnham and Anderson 2002). The candidate models were ranked based on AICc. The model with the lowest AICcwas considered the most likely “true” model that fitted the data well. In this comparison, if the difference between the best model and each of the rest of the models is less than 2, the two models are considered to be approximately equivalent (Migliavacca et al. 2012; Cai et al.2013).
where n is the number of data points (observations), k is the number of model input parameters and RMSE is root mean square error of the model(Eq. 7).
Model validation
The models were validated by examining (1) the model parameters and (2) testing the equivalence of the predictions of the best model (model M6) with the predictions of the pantropic model of Chave et al. (2014). In the validation of the parameters, Sileshi (2015) strongly argued that besides the analysis of variance of the parameters,there is still the need to validate model parameters because all or some of the parameters could be nonsignificant (i.e. estimate of parameter=0) while the ANOVA result is still significant, in which case the study could contradict itself, earlier findings or theoretical predictions. The parameters were therefore validated based on the recommendations of Sileshi (2014, 2015) that the percent relative standard error (PRSE) (Eq. 8) should not exceed 20% if the estimates of the parameters are accurate and reliable. This was complemented by the recommendations of Stellingwerf (1994) that for biomass estimation, the 95% confidence interval (CI) should be within ±20% of the estimated parameter.
The PRSE was computed as follows:
Where; |θ is point estimates of the parameter and SE is the standard error of the estimate of the parameter.
The best model (M6) was validated using a two-onesided test (TOST) of equivalence in which the best model was compared with pantropic model of Chave et al. (2014) for equivalence. The pantropic model developed by Chave et al. (2014) was chosen because it is an attractive option in areas where there are no locally developed allometric models and because many species of varying dbh, heights and wood density were used in its calibration. It is more appropriate in testing the validity of methods, tools or datasets compared to the conventional statistical tests that are designed to test statistical point difference (Meyners 2012). Equivalence testing provides empirical evidence of equivalence within a specified bound (Meyners 2012; Lakens 2017; Dixon et al.2018). In this case, the equivalence region was set at ±10% error (standardized difference between the two measures) (Dixon et al. 2018) to ensure that close to 80% of statistical power is achieved with a sample of 745 trees based on the Power Analysis and Sample Size(PASS) table generated by Walker and Nowacki (2010).For an equivalence margin of 10% or less, there is no significant practical difference between μM6/μCand μC/μM6, i.e. 0.9 <μM6/μC<1/0.9 and 1/1.1 <μM6/μC<1.1 as noted by Dixon et al. (2018). However, smaller equivalent bounds of less than 10% would require very large sample size for 80% statistical power, which is very expensive to achieve in the case of destructive sampling for allometric modelling.
Thus, with an equivalence margin of ±10% the mean of the predictions of the two models, this means that the mean of model M6 and that of Chave et al. (2014) are within ±10% of each other and the hypotheses of the equivalent test are then stated as follows:
where μM6is the mean of model M6 and μCis the mean of the model developed by Chave et al. (2014).
With these two inequalities, there is the need to ensure that the equivalence bounds of ±10% are the same for both μM6/μCand μC/μM6since equivalence is a symmetric concept (Meyners 2012; Lakens 2017; Dixon et al. 2018). This means if model M6 is equivalent to the model of Chave et al. (2014), then it also means that model of Chave et al. (2014) is equivalent to model M6.
As the equivalence bound is set at ±10%, this means that 1/0.9=1.111, and 1/1.1=0.91 would enable the setting of new upper and lower bounds that would be symmetric about the difference between the means of model M6 and Chave et al. (2014) (on the ratio scale) (Meyners 2012). In that case, the test decision would not depend on any of the two models (M6 or Model of Chave et al.(2014)) as a reference (idem).
Therefore, the new symmetric equivalence bounds for the two hypotheses were then stated as below for the ratio scale:
These two equivalent bounds do not differ significantly and can be considered as referring to the same interval.Therefore, any of the two equations in Eqs. 10 could be used to test the equivalence of the two models. In this study, Eq. 10a was used.
It is important to test the one-sided null hypotheses for the lower and upper bounds of each of Eq. 10a. To avoid the problem of ratios, each one-sided hypothesis should be stated as a linear combination of a normally distributed random variable as in:
These two one-sided hypotheses, μM6-0.9μC<0 and μM6-1.1111μC<0 were then tested by computing DM6and DCas below based on the assumption that random variables YM6-0.9YCand YM6-1.111YCare normally distributed when the sample averages of YM6and YCare normally distributed:
where YM6and Ycare the predictions of model M6 and the model developed by Chave et al. (2014), respectively.
Two one-sample t-tests were then performed using DM6and DCvalues. The one-sided null hypothesis μM6-0.9μC<0 is rejected if the average of the DM6values is sufficiently greater than 0. The one-sided null hypothesis μM6-1.1111μC<0 is rejected if the average of the DCvalues is sufficiently smaller than 0. If both null hypotheses are rejected, then the alternative hypothesis of equivalence is accepted.
A paired t-test was also performed to compare the predictions of the best model among the seven models with the Chave et al. (2014) pantropic model(Eq.13).
In this comparison, the null hypothesis being tested is that the mean difference between the estimates of selected local model and that of Chave et al. (2014) is zero at 95% confidence level, with the alternative being that the mean difference is not zero as stated below:
Results
Model parameters
The ANOVA for the models revealed that the parameters of each model were significantly different from zero(P <0.001) at the 95% confidence level (Table 5). This indicates that the estimated parameters were within the 95% confidence interval. The allometric coefficients for models M1, M2 and M3 were both larger and less precise relative to the rest. Also, estimates of allometric exponents for models M1, M2 and M3 were large, but precise, compared to the rest. The trend shows that the models without tree height as predictor (M1, M2 and M3) had larger allometric exponents than those with total tree height (M4, M5, M6 and M7) as a predictor.All the CIs were within the reference CIs except the CI of the allometric coefficient of model M1.
Model Evaluation
Models efficiency
The variability in AGB as explained by the MEF values ranged from 91% to 97% (Table 6). Model M1 explained 91% of the variability in AGB while models M6 and M7 explained 97% of the variability. The biases ranged from-0.07% for M5 to 1.66% for M7. The AICcvalues for the models also ranged from a minimum of 2538.78 for M7 to 2854.67 for M4. The MEF within each model category of models were the same, however that of bias and AICcvaried within the model categories although the variation was small. Model M7 had the least AICc and the difference between the least AICcvalue and each of the models revealed that the models with wood density(M2, M3, M6 and M7) were better model than those without wood density (M1, M4 and M5).
Effects of model predictors on model bias
The model biases were evaluated against each of the predictors to observe the effect of classes of each predictor on the model biases. The effect of wood density class on the bias of models M2, M3, M6 and M7 was assessed(Fig. 2). The relationship between wood density classes and model bias revealed that wood density class 0.5-0.59 g·cm-3influenced the magnitude of model bias more than the other classes. Furthermore, the mean bias of the same density class had the widest CI for all the four models (M2, M3, M6 and M7). The theoretical bias,0, is within the CI of all the wood density classes except the reference model which had the reference bias outside the CI of wood density classes 0.60-0.69, 0.70-0.79,0.80-0.89 g·cm-3.
All the models were biased toward dbh class 45.0-54.9 cm with M5 exhibiting the largest (95%) margin of error (Fig. 3). Based on the 95% CI, model M6 is more precise relative to the other models for all dbh classes.The dbh class 45.0-54.9 cm contributed the largest bias in all the model biases relative to the other dbh classes.Similar trend of the effect of the dbh classes on model bias is observed with the reference model (Chave et al.2014). However, the effect of dbh class 45.0-54.9 cm on model bias is minimal in M6 compared to the other models, including the reference model. The high influence of dbh class 45.0-54.9 cm on model bias could be attributed to the relatively low number of trees (3) in this dbh class (see Table 1). Model M6 is relatively moreaccurate and precise than the other models since the mean bias for all the dbh classes are virtually equal to the theoretical value of zero and the 95% CI are relatively narrow.
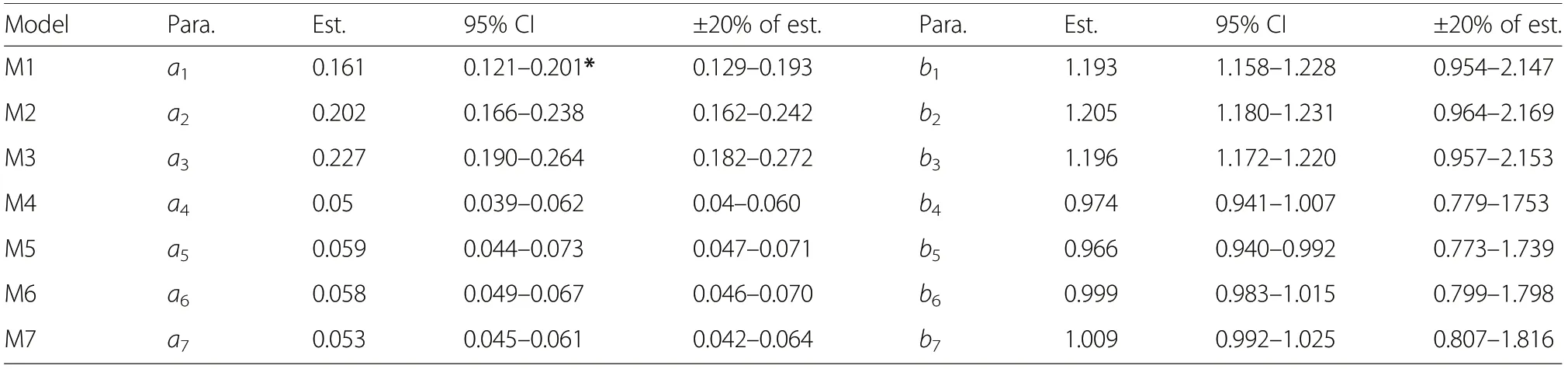
Table 5 Estimates of model parameters with their standard errors (S.E.)and 95%confidence interval(CI) together with recommended confidence intervals by Stellingwerf(1994). The±20% of the estimated parameters are used as reference CI for those of estimated parameter

Table 6 Statistical goodness-of-fit measures (MEF, Bias,AICc and ΔAICc) for the models
The relationship between model bias and tree total height class revealed that height class 20.1-25.0 m influenced the magnitude of the bias and its deviation from zero (Fig. 4). The same total tree height class had more effect on the bias of models without wood density as a predictor (M4 & M5) compared to those that had wood density (M6 & M7, including the reference model).
Evaluation of goodness-of-fit plots
Linear regression of observed AGB versus predicted AGB revealed that M6 had the narrowest prediction interval (PI) and the fewest points outside the PI compared to the rest (Fig. 5). From the plots, it is apparent that the models with wood density as predictor (M3 and M6) had narrow prediction bands relative to those without wood density as a predictor.
The plot of the residuals verses the predicted AGB(Fig. 6), revealed that M1, M2, M3, M4 and M5 exhibits increasing residuals with increasing predicted AGB (heteroscedasticity of residuals) while M6 and M7 together with the reference model, Chave et al. (2014) model,showed general constant trend of residuals with increasing predicted AGB. Furthermore, the first five models produced larger residuals (between ±6 and±8 kg·tree-1) than the last two which produced residuals within ±4 kg·tree-1.
Model comparison
AICcvalues of the models showed significant differences only across model categories (I, II, III & IV). The best performing model in terms of AICcis M7 and comparison of the AICcvalue of M7 with the rest showed differences in AICcvalues of greater than the recommended value of 2 for M1, M2, M3, M4 and M5. However, the difference in the AICcvalues (0.45) for M6 and M7 is much less than the recommended value and are said to be similar.
Model validation
Parameters
Comparison of the 95% CI and the recommended intervals revealed that the CIs of both the allometric constants (ai) and the allometric exponents (bi) were within±20% of the estimated parameters except the confidence interval of the allometric constant of model M1, which has its lower and upper bounds [0.121-0.201] outside the ±20% of the estimate [0.129-0.193] (Table 7). This suggests that the parameter a1of model M1 is not accurately estimated and would not be reliable with 95%CI. However, the rest of the allometric constants and exponents of the models were accurately estimated and are therefore reliable.
The Percent Relative Standard Error (PRSE) for the allometric constants varied from 7.93% to 12.99%whereas that for the allometric exponents ranged from 0.82% to 1.72% (Table 8). These PRSE values are less than 20%suggesting that the estimates of the parameters of the models are reliable in estimating AGB.
Test of Equivalence between best model (M6) and Chave et al. (2014) pantropic model
The TOST results revealed that there is no sufficient evidence in support of the null hypotheses for both the upper and the lower bounds at 10% confidence interval(Table 9). Therefore, the two null hypotheses are rejected in favour of the alternative hypotheses. It therefore concluded that model M6 and the pantropic modelof Chave et al. (2014) are equivalent in terms of their predictions.
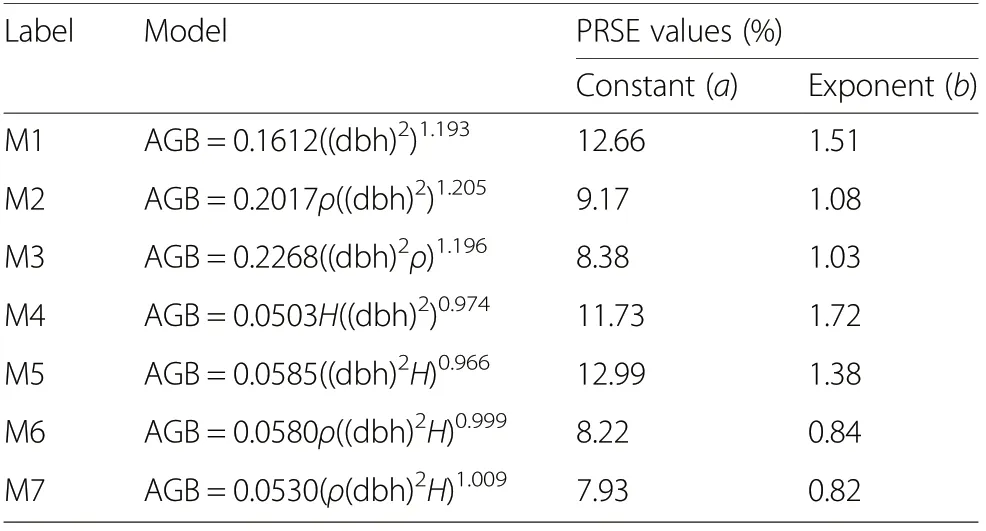
Table 8 Results of test of reliability of model parameters a and b using the percent relative standard error (PRSE)
Test of difference in model predictions between M6 and Chave et al. (2014) pantropic model
A comparison of model M6 with the pantropic model developed by Chave et al. (2014) [AGB=0.0673(ρ(dbh)2H)0.976] based on a paired t-test (n=745,mean diff. = 16.50±2.45 kg; S.E. = 1.25 kg; p <0.001) revealed significant evidence (p <0.001) that the difference in means of their estimates (16.50 kg) is significantly different from 0 (p <0.001) at the 95% confidence level(Table 10). Therefore, the null hypothesis that the mean difference between the two models is zero is rejected in favour of the alternative hypothesis.
The analysis provided sufficient evidence to reject the null hypothesis that the observed AGB and model predictions for the pantropic model is zero, implying that there is significant difference between the means of the observed and the predictions in the case of the pantropic model.
Plots of observed AGB against predictions AGB revealed deviations of the slope and intercepts of the 1:1 line from 1 and from zero (0), respectively for both model 6 and that of Chave et al. (2014). However, both models were similar as indicated by the values of coefficient of determination (R2) (Fig. 5). The slight departureof the slope and the intercept of model M6 from 1 and 0 is an indication of the presence of minor prediction errors. A comparison of the plots also showed that while model M6 under-predicted by 2.506 kg, Chave et al.(2014) over-predicted by 4.049 kg (see equations in the plots) within 95% prediction interval (PI). Also, 98.5% of the standardized residuals of both models fall within ±3 with six standardised residuals (1.5%) outside ±3 range(Fig. 5).
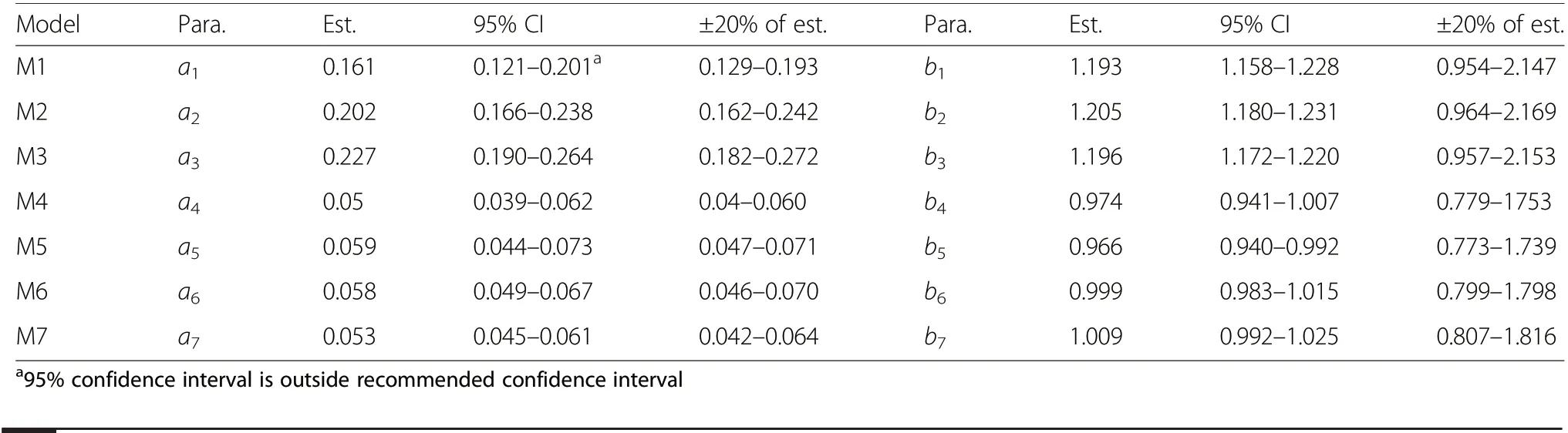
Table 7 Comparison of 95%confidence intervals of the estimated(est.)parameters (para)with recommended confidence intervals by Stellingwerf(1994)

Table 9 Results of the two one-sided t-tests of euivalence between model M6 and Chave et al. (2014) pantropic model
Discussion
Model parameters and accuracy
The accuracy of the estimated parameters has significant effects on the predictive power of the models particularly model M6 which has been selected as the best model among the seven models. The accuracy of estimated parameters constitutes a source of error in the application of the model and are therefore key factors that determine whether model is applicable or not. It is important to examine the model parameters critically. Comparison of the 95% CI and the recommended intervals revealed that the CIs of both the allometric constants (ai) and exponents (bi) for all the models except the CI of parameter a1of M1 were within ±20% of the estimated parameters as recommended by Stellingwerf (1994). This suggests that the parameter a1of model M1 was not accurately estimated and would not be reliable with 95%CI.
Comparison of the scaling exponents with literature also indicates that the observed scaling exponents (ranging from 1.00 to 1.21) are somewhat lower than those reported by Sileshi (2014), which ranged from 1.64 to 3.83. The differences in the scaling exponents could be attributed to differences in sample size since large uncertainty is associated with estimates of the exponent with small samples. In this study, the sample size is 745 while the sample size of the studies cited by Sileshi (2014)ranged from 12 to 264.
Furthermore, when the allometric exponents of M1(which is of the generic form), 2.386 (2×1.193) was compared with the empirical allometric exponent(2.3679) as stated by Zianis and Mencuccini (2004) for the generic relationship between AGB and dbh [M=a(dbh)b], it shows close similarity between the two values. However, when the allometric constant of M6 was compared with Ebuy et al. (2011), it is apparent that the allometric constant of M6 (0.058) is relatively less than that of the Ebuy et al. model (1.603) while the allometric exponent of M6 (0.999) is relatively larger than that of Ebuy et al. model (0.657). Considering the effects of sample size on model parameters, it is more likely and credible that the coefficients of M6 are more accurate and reliable than those of the model of Ebuy et al.(2011). This is because the model of Ebuy et al. was calibrated using a very small sample of 12 trees while M6 was calibrated using a large sample of 745 trees.This assertion is consistent with Sileshi (2014), who criticized the allometric exponent of the Ebuy et al. (2011) model as being very small compared to the theoretical value of 2.67 while the intercept was excessively large.
The scaling exponents have significant practical implications for the estimation total AGB. In this study, it is observed that models M1, M2, M3 and M7 have scaling exponents greater than 1.0, implying that the total AGB predicted by such models increases relatively faster than the predictors as observed by Bervian et al. (2006). Similarly, models M4, M5 and M6 have allometric exponents of less than 1, which means that these models will predict total AGB that is presumed to accumulate relatively slower than the growth in the predictors of the AGB.Therefore, models M1, M2, M3 and M7 are likely to over-predict the mean AGB marginally while M4, M5and M6 will under-predict it marginally. The explanations of over-prediction and under-prediction of these models are generally consistent with observations of Feldpausch et al. (2012) and the regression parameters of the relationship between observed and predicted AGB(Figs. 2 and 5). Feldpausch et al. (2012) observed that allometric models without H usually over-estimate AGB.For instance, among the category of models that are likely to over-predict, models M1, M2 and M3, are without H as a predictor. However, the deviation of M7 from the observation of Feldpausch et al. (2012) could be attributed to fact that it exhibited the largest bias among the seven models.

Table 10 Results of statistical comparison model 6 with Chave et al. model using the Paired t-test
Furthermore, the relationship between the observed and predicted AGB (Figs. 2 and 5) as an evaluation of model predictions also revealed marginal deviations of slope and intercepts from the theoretical values of 1 and 0 (1:1 line) respectively for a perfect model (see Pineiro et al. 2008). These marginal deviations are expected under empirical conditions where measurements of variables are subject to random errors. Thus, the prediction accuracy and reliability of the models should not be subjected to the judgement of Sileshi (2014) that deviations of slope from 1 and intercept from 0 are an indication of significant prediction errors.This is because marginal errors in estimates of empirical parameters are unavoidable. The same trend of over- and under-predictions among the seven models are also revealed by the linear relationships between observed and predicted AGB.
The validation of the model M6 using the equivalent test and the paired t-test revealed different conclusions.While the conclusion of the equivalent test suggests that model M6 and model of Chave et al. (2014) are equivalent within 10% of their mean predictions, the paired ttest suggests that the mean of the predictions of Chave et al. (2014) is significantly greater than that of M6. The difference in the outcomes of the two tests can be attributed to the nature of each of the two tests and the sample size as argued by Dixon et al. (2018) that the nature of the difference test (t-test) is such that it is more likely to find statistically significant difference with large sample data. In this study, a sample size of 745 is large enough to support the argument of Dixon et al. (2018).The study agrees with the results of the equivalence test that the predictions of the two models are equivalent.However, the evidence of equivalence between the two models must be placed within the practical ecological relevance and be emphasized that the fact of equivalence of the two models does not mean that one cannot be superior to the other in times of practical local needs and applications. Certainly, the question of Tier 2 and 3 of IPCC requirements and develop of GPG for carbon stock reporting suggest that accurate local allometric models cannot be substituted for pantropic allometric models. For instance, if the accuracies for reporting carbon stock for IPCC requires smaller accuracies than ±10% of the means of the predictions of the two models,the assumption of equivalence would not be appropriate and the M6 will be superior to the pantropic model.Also, the pantropic model of Chave et al. (2014) may not provide the required accurate estimate of AGB at the local level and similar ecological areas for purposes of the REDD+ programme and IPCC carbon stock reporting at the local level. This is consistent with the view of Nam et al. (2016) that regional and pan-tropical models could lead to erroneous biomass estimates at the local level.
Model forms
The observations of the different model forms indicate that the model form influenced the model efficiency, bias and AICcvalues. For instance, model M1 which has dbh as the only effect variable explained 91.4%of the variability in AGB. This is expected and confirms why dbh is widely used as predictor of AGB (Baker et al. 2004; Chave et al.2005; Henry et al. 2011; Chave et al. 2014). However, the model efficiency of 91.4% is lower than 95% as reported by Gibbs et al.(2007)in tropical forest.The difference can be attributed to the ecological conditions and the age of the trees since these conditions have impact on the overall amount of AGB (Picard et al. 2012). The dbh therefore plays a significant role in tree allometry and has always been the first variable in relating tree attributes to total above ground biomass of trees.
The inclusion of wood density to dbh (category II models i.e. M2 and M3) increased the amount of predictability in AGB from 92.8% to 95.7%. This is a significant increase in the model efficiency and is in line with general view that wood density is an important predictor of AGB, especially for mixed species (Baker et al. 2004;Djomo et al. 2010; Chave et al. 2014; Dutcă 2019). Dutcă(2019) reported that wood density actually accounts for differences in tree species multispecies allometric models. It is therefore not surprising that Baker et al.(2004) observed that wood density alone explained 25.1% of the variation in AGB in the Tropics. The significant role of wood density as a predictor of AGB could also be attributed to the nature of the tree canopy in the study area; whether the tree canopy is open or closed. The canopy in the forest-savannah transition zone is an open type and the trees usually tend to have many branches, which add to the AGB of the trunk thus accounting for the total AGB relatively better than proportion accounted for by the dbh. This explanation is consistent with the view of Picard et al. (2012) that trees in open woodlands have more branches than those in dense stands even if the trees have equal height, dbh and are of the same age. This also suggests that despite the significance of dbh in AGB estimation, it is not sufficient in explaining the variability in AGB of mixed species as noted by Henry et al. (2011)and Dutcă(2019).
The inclusion of height to dbh (in the case of models M4 & M5) increased the MEF marginally from 91.4% to 92.8%. This is contrary to expectations as Feldpausch et al. (2012) emphasized the relevance of height in estimating tree biomass. The marginal increase in MEF could be attributed partly to difficulty encountered in the field in precisely measuring tree height with the Haga Hypsometer, especially when other tree crowns obstruct the tip of a tree.
The inclusion of both wood density and tree height to dbh improved the MEF significantly from 91.4% to 97.4% as in M6 & M7. Thus, in terms of MEF, model M6 and M7 accounted for the variability in AGB relatively better than the other models. The margin increase in the MEF as a result of the inclusion of total tree height affirms the observation of Chave et al. (2005) that the order of importance of predictors of AGB is dbh,wood density and tree height. This is further buttressed by Nam et al. (2016) who reported that in the case of multi-species, a model combines dbh, wood density and tree total height as predictors gives good estimate of site or plot level AGB.
Examination of the model bias (%) shows that all the models are acceptable based on the criterion of Huang et al. (2003) that bias percent of less than 10% is good.Despite the revelation that the best models in terms of model bias have height as one of their predictors, the general trend in the observed bias does not follow the observation by Chave et al. (2005) and Feldpausch et al.(2012) that the inclusion of height in estimating destructively sampled biomass reduced errors significantly. The difference in observations could be attributed to the methods of measuring the height of trees in the field since height measurement is easily prone to errors.
Comparing the seven models, the best performing model in terms of AICcis M7 since it has the least of the AICcvalues. Comparing AICcvalue of M7 with the AICcvalues of the rest of the models shows that the differences are greater than the recommended difference of 2, except M6 indicating that these models are significantly different from M7, based on the observation of Migliavacca et al. (2012). The difference in AICcvalues between M7 and M6 is less than 2 suggesting that the two models are similar. However, the performance of models M6 and M7 in terms bias shows that M6 is better than M7 for estimating AGB of the woodlands of savannah-forest transition zone.
The models in categories III and IV have indeed demonstrated the relevance of choosing an appropriate model form as pointed out by Chave et al. (2004), Nam et al. (2016) and Youkhana et al. (2017). Thus two different model forms, with the same predictors and different effect variables can produce different estimates of AGB as a result of the effect of the allometric exponent on the different predictors. Considering category IV, the results therefore revealed that the two model forms ρ((dbh)2H)band (ρ(dbh)2H)bperformed similarly in terms of MEF and AICcwith ρ((dbh)2H)boutperforming(ρ(dbh)2H)bin terms of model bias.
The relationship between standardized residuals and predicted AGB showed that models M1, M2, M3, M4 and M5 exhibited some level of heteroscedasticity, while M6, M7 and the reference model exhibited homoscedasticity of residuals (Fig. 6). It is apparent from the category of the models exhibiting heteroscedasticity, that the heteroscedasticity being exhibited by these models can be attributed to inappropriate model forms in terms of model exponents and sufficiency of predictors but not necessarily due serious variation in the dbh of the trees used in the models. This is consistent with the explanation of Knaub Jr. (2018) that nonessential heteroscedasticity is not due to the different sizes of members of a population in a sample. In terms of the size of the residuals, the models that have the smallest range of residuals(±4) are M6 and M7 together with the reference model.However,the±4 range is larger than the±2 range recommended by Sileshi (2014) who indicated that residual values exceeding ±2 represent outliers that can cause a model to exhibit serious heteroscedasticity. That notwithstanding,the best model is till reliable and applicable.
Attributes of tree species
While the species used in developing the models vary in terms of wood density, the individuals of each of these species also varied in terms of diameter at breast height,total tree height and even within tree wood density depending on the conditions of growth (see Picard et al.2012). These variations would have effects on the accuracy of models and should reflect in the seven different models developed in this study. That notwithstanding,Dutcă (2019) argued that more of the differences among species in multi-species allometric models is captured by wood density. In this study, 31 different tree species were used to develop the models. However, 70% of the 745 individual trees harvested belong to eight different tree species (Acacia sp., Anogeissus leiocarpus, Burkea africana, Detarium microcarpum, Lophira lanceolata,Pterocarpus erinaceus, Terminalia macroptera and Vitellaria paradoxa).
Diameter at breast height(dbh)
About 87% of the trees used in developing the models were within the dbh classes 5-14.9 cm and 15-24.9 cm.The number of species that constitutes these individual trees are 30 out of the 31 species. Only 13% of trees fell within the rest of the three dbh classes (25-34.9, 35-44.9 and 45-54.9 cm). It is therefore not surprising that all the models were biased toward dbh class 45.0-54.9 cm with M5 exhibiting the largest margin of error. The relatively large biases exhibited by this dbh class is attributed to the relatively few (3 trees) but large trees in this dbh class compared to the number of trees in each of the other classes. Despite their effect on the model bias, these trees could not be considered as outliers because they constituted a significant part of the trees in the study area and contained large proportion of the biomass of the vegetation as also observed by (Feldpausch et al. 2012). That notwithstanding, model M6 proves superior in relation to model accuracy and precision among the seven models for all dbh classes. It showed lower bias within the 45.0-54.9 cm dbh class compared to the rest of the models. Similarly, model M6 is still relatively better when compared with the pantropic model of Chave et al. (2014). However, the application of model M6 in estimating the biomass of trees beyond the upper bound of the 45.0-54.9 cm dbh class might lead to the introduction of serious bias into the estimated biomass (see Roxburgh et al. 2015).
Wood density
The wood density of harvested trees varied within trees as observed from the standard deviations. The standard deviations ranged from 0.016 g·cm-3, for Margaritaria discoidea, to 0.087 g·cm-3for Anogeissus leiocarpus. The observed variation within the wood density in the harvested tree species is not surprising as Woodcock and Shier (2002), Knapic et al. (2008) and Lehnebach et al.(2019) observed a decreasing trend of wood density from pith to the cambium of the oak tree. Variation is attributable to growth conditions, age and succession of the tree. Pioneers and early successional species exhibit increasing wood density from the pith to the bark, while late successional species exhibit decreasing wood density from pith to bark (Woodcock and Shier 2002).
About 72% of the individual trees used to develop the models were from 16 of the 31 species and were of densities ranging from 0.7 to 0.89 g·cm-3. These species are
Afzelia africana, Albizia coriaria, Anogeissus leiocarpus,Bridelia scleroneura, Burkea africana, Combretum collinum, Crossopteryx febrifuga, Erythrophleum ivorense,Lophira lanceolata, Margaritaria discoidea, Pericopsis laxiflora, Pseudocedrela kotschyi, Pterocarpus erinaceus,Tamarindus indica, Terminalia macroptera and Vitellaria paradoxa. Wood density is an important predictor in multispecies allometric models since it accounts for the differences in the species (Dutcă 2019). Available wood densities for three Combretum species observed in Niger, Bukina Faso and Mali which ranged from 0.666 g·cm-3to 0.758 g·cm-3(Nygard and Elfving 2000; Sotelo Montes et al. 2012; Weber et al. 2017). This revealed that the observed wood density for Combretum collinum(0.70 g·cm-3) in this study is within the range of existing wood densities for Combretum species in similar geographic areas. Additionally, the wood density of 0.63 g·cm-3for Parinari cura tellifolia is consistent with the range of density values for Parinari spp. reported in Ketterings et al. (2001).
The relationship between wood density classes and model bias revealed that the extreme wood density classes (0.5-0.59 and 0.8-0.89 g·cm-3) influenced model precision and accuracy negatively more than the intermediate classes with model M3 being more accurate and precise compared to model M6. These two wood density classes contain trees across all the dbh classes compared to the intermediate classes that do not contain trees in the dbh class with the largest trees. Although tree size(dbh) is not explicitly stated as one of the factors that influence variation of wood density (see Woodcock and Shier 2002), it can be inferred from the growth conditions of the trees and could be contributed to the large bias in these density classes. Additionally, low density class (0.5-0.59 g·cm-3) contained the least number of trees(8%)which could have also influenced the bias negatively. That notwithstanding, the evidence of variation in wood densities within trees and between species certainly has influence on the performance of multispecies models.
Total tree height
About 90% of the trees harvested for the modelling fell within two height classes 5.1-10.0 and 10.1-15.0 m.Knowledge of dbh and total tree height is fundamental to the development and application of allometric models(Sharma and Parton 2007). The relationship between bias and height classes revealed that height class 20.1-25.0 m influenced the precision of both models negatively. Comparatively, model M6 is more accurate and precise relative to model M5.
Conclusions and recommendations
This study developed and compared seven models for assessing AGB of mixed trees species used for charcoal production in the savannah woodlands of Ghana. The best model among the seven models based on a comparison of model efficiency (MEF), bias (%), AICcis AGB=0.0580ρ((dbh)2H)0.999. Diameter at breast height and wood density were the main predictors that significantly influenced variability in AGB. The model parameters were evaluated and found to be accurate and reliable. The best model and that of Chave et al. (2014)were compared and found to be equivalent within ±10%of the means of their predictions. Despite the equivalence between the two models, the best allometric model in this study is considered to be a better tool for estimating AGB in the savannah woodlands of Ghana,compared to the Chave et al. (2014) pantropic models.The allometric model of this study is therefore a relevant local allometric tool which fills a critical gap in the estimation of AGB for the tropical woodlands of Ghana. It is therefore recommended for use in the REDD+ process of estimating relevant emission levels for Ghana to facilitate effective accounting of the contribution of charcoal production to both national and global carbon budgets.It is further recommended that similar research be conducted in other parts of West Africa (e.g. the Sahelian ecozones) and in other regions in Africa for a comprehensive and better understanding of variation in AGB in the West African sub-region and in Africa as a whole.
Acknowledgements
We acknowledge the support of the Federal Ministry of Education and Research (BMBF) of Germany, which fully and solely funded the study through the West African Science Service Centre for Climate Change and Adapted Land use (WASCAL) under its Doctorate Research Programme on Climate Change & Land use (DRP CCLU) at the Kwame Nkrumah University of Science and Technology, Kumasi. We are thankful to Kwame Nkrumah University of Science and Technology for offering the lead author the opportunity to be part of WACAL DRP CCLU. We are also grateful to the University for Development Studies, Tamale - Ghana, for granting the lead author study leave to enable him conduct this study without any conflict of interest. We thank the Faculty ITC,University of Twente, Enschede - The Netherlands, for allowing us to use their facilities during the writing of this manuscript. We appreciate the support of the Kintampo Municipal Assembly,as well as all those who assisted in one way or the other during the data collection and reviewing the manuscript.I also appreciate the invaluable Mr.Franklyn Dono of Atomic Energy Commission,Accra.
Authors’contributions
This paper is extracted from PhD thesis of Raymond Aabeyir. Raymond Aabeyir collected the data, analysed, and drafted the manuscript under the supervision of Stephen Adu-Bredu, Wilson Agyei Agyare, and Michael J.C.Weir. The Co-authors also reviewed the manuscript.The author(s) read and approved the final manuscript.
Authors’information
Authors’ information is provided under the authors’affiliation.
Funding
Federal Ministry of Education and Research (BMBF) of Germany, funded the PhD programme of the lead author through the West African Science Service Centre for Climate Change and Adapted Land use (WASCAL).
Availability of data and materials
The data is available for use for non-commercial purposes. It will be willingly provided upon request through raypacka2012@gmail.com.
Ethics approval and consent to participate
The authors have complied with ethical standards during the data collection process. Permission for the fieldwork was sought from the Kintampo District Forest Office, traditional authorities and the Kintampo Municipal Assembly.
Consent for publication
Apart from the literature cited and duly acknowledged, the data used in this manuscript were collected by the lead author under the supervision of the co-authors.
Competing interests
The lead author obtained study leave from his employer, University for Development Studies. The funding institution, Federal Ministry of Education and Research (BMBF) of Germany, has been duly acknowledged.
Author details
1Department of Environment and Resource Studies, UDS-Wa Campus, Wa,Ghana.2WASCAL Graduate Research Programme on Climate Change and Land Use, KNUST,Kumasi, Ghana.3Biodiversity Conservation and Ecosystem Division, CSIR-Forestry Research Institute of Ghana, Kumasi, Ghana.
4Department of Agricultural and Biosystems Engineering, KNUST, Kumasi,Ghana.5Department of Natural Resources, Faculty of Geoinformation Science and Earth Observation (ITC), University of Twente, Enschede, the Netherlands.
Received: 17 November 2019 Accepted: 5 June 2020

- Forest Ecosystems的其它文章
- Soil-plant co-stimulation during forest vegetation restoration in a subtropical area of southern China
- Addressing soil protection concerns in forest ecosystem management under climate change
- Species richness,forest types and regeneration of Schima in the subtropical forest ecosystem of Yunnan,southwestern China
- Effects of afforestation of agricultural land with grey alder(Alnus incana(L.)Moench)on soil chemical properties,comparing two contrasting soil groups
- Delineating forest stands from grid data
- Tree diversity effects on forest productivity increase through time because of spatial partitioning