
改进YOLOv3网络在图像中评价空气质量
2020-10-19 04:41:14邓益侬罗健欣金凤林毕鹏程
计算机工程与应用 2020年20期
邓益侬,罗健欣,张 琦,刘 祯,胡 琪,金凤林,毕鹏程
1.陆军工程大学 指挥控制工程学院,南京 210007
2.南京小吉狗网络科技有限公司,南京 210000
1 引言
空气质量指数(AQI)是定量描述空气质量状况的无量纲指数。空气质量按照AQI的大小分为六级,一到六级分别为优,良,轻度、中度、重度和严重污染。同时针对单项污染物还规定了六项空气质量分指数,分别描述细颗粒物、可吸入颗粒物、二氧化硫、二氧化氮、臭氧、一氧化碳的含量。其中可吸入颗粒物与其他污染物相比,能够直接进入肺泡,对人类健康的危害最大。世界各国普遍使用PM2.5浓度值作为可吸入颗粒物污染指数的衡量指标,近十年人们进行了大量研究旨在评价各种环境下的空气质量指数,特别是PM2.5浓度值的估计。目前对于PM2.5的精确测量主要依托传感器实现,例如中国环境监测总站利用动态加热系统检测PM2.5的β 射线吸收[1],然而,现有的高质量PM2.5监控传感器花费在数万美元以上,而且维护成本高,导致其大范围部署不切实际。以北京为例,16 411平方公里的城市面积仅部署了35 个固定传感器来收集PM2.5数据(见图1(a)),即使是居住密集区也只有22个空气质量监测站点(见图1(b))。因此稀疏分布的PM2.5监控系统无法在城域范围内提供细粒度的测量。由于部分特殊区域例如工厂,交通枢纽附近的PM2.5浓度值可能会远高于城市平均水平,所以人们更关注于实时的空气质量检测结果,以避免接触到空气中的致癌物。虽然设计低质量便携式传感器是一种解决思路,但是由于技术问题在没有被集成到智能手机之前,人们不会随身配备专门的空气质量检测器。与此同时如图2 所示[2],随着图像识别技术的发展,利用城市空气质量视觉日志并基于图像检测的环境空气质量评价方法得到了广泛研究。相比于传感器采集局部空气物理数据的方式,基于图像检测的方法只需使用摄像头就可以采集到各种尺度(最大数公里级别)区域的环境图片信息,然后通过视觉分析或者深度学习算法提取和分析图片中的数据特征,即可便捷和高效地完成对环境空气质量的评价,这也促进了使用智能手机实时估计周围空气质量的模式成为可能。
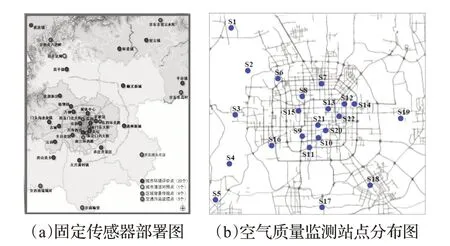
图1 北京市空气质量监测站分布图
本文在图像检测算法的框架下,提出了一种基于卷积投票模型的空气质量评价方法,对传统直接套用深度学习模型进行空气质量检测的算法做出了改进。卷积投票网包含多锚点检测机制和卷积投票网两个模块,适用于非固定场景下的空气质量指数评估,以及固定场景下的PM2.5浓度预测,旨在得到当前周围环境下空气质量的实时评价。应用场景如图3 所示[3],其中空气质量指数分为优、良、轻度污染、中度污染、重度污染以及严重污染六个级别,而PM2.5浓度单位为μg/m3。
2 相关工作
目前,基于图像检测的空气质量指数和PM2.5浓度预测方法有三种[4],分别基于视觉特征[5-6]、能见度特征[7-9]以及深度特征[10-11],其评价示例如图4所示[12]。
Yang 等人[5]利用相对湿度校正从预处理图像中提取的传输特征,并提出了一种基于学习(LB)的方法来估计PM2.5浓度。Spyromitros-Xioufis 等人[6]结合深度学习的方法对视觉特征进行处理,首先利用GoogLeNet[13]自动提取图像的天空部分,然后对检测区域的像素颜色值的统计量进行操作估计。但是由于视觉特征主要是人工设定的HOG[14]和SIFT[15]等特征,以及颜色直方图这类原始的图像参数信息,很难通过处理这些与空气质量的相关性较低的特征得到满意的检测结果。

图2 北京空气质量视觉日记

图3 两种空气质量评价问题
图4 基于图像检测技术的空气质量指数评价
相比于视觉特征,能见度特征更加适用于表征空气受污染的程度,大多数方法基于光学物理模型和亮度对比度进行分析。例如Kim 等人[7]基于HIS 模型,利用颜色差估计场景的可见性。Liu 等人[8]则提出一种雾度模型,通过环境传输图的混浊度来反映空气质量。此外Poduri等人[9]将截取的局部天空区域的光强特征与天空亮度模型进行比较进而得到评价结果。然而由于能见度特征的表现受光圈、快门等相机参数的影响较大,在手机上使用摄像头进行能见度评估的可行性仍有待进一步探讨。
相比之下近年来基于深度学习挖掘环境图像深度特征的方法成为了研究热点,利用LeNet[16]、AlexNet[17]、VGG[18]、GoogLeNet 以及 ResNet[19]等卷积神经网络模型结构可以提取到语义信息更为丰富的深度特征。例如Wang 等人[10]基于AlexNet 构建了一个双通道卷积神经网络,利用每个通道训练环境图像的不同部分进行特征提取,同时提出一种特征权重自学习方法,对提取的特征向量进行加权和连接,并使用融合的深度特征向量来测量空气质量。还有的方法[11]尝试结合空气质量变化的规律特征信息,基于长期短期记忆网络(LSTM)[20]构建模型,对城市空气质量指数进行检测甚至是预测。
但是由于无法直接解释深度特征与空气质量的相关性,任何模型对深度特征的理解都需要基于大量训练数据的统计特性,因此在得到表征能力更强的深度特征时,也会伴随产生较多的噪声特征,干扰模型的评价结果。总体上,基于图像检测的空气质量评价方法的对比举例如表1所示。

表1 基于图像检测的空气质量评价方法对比
3 本文的研究内容和主要贡献
总体上,将基于深度学习的方法应用到空气质量评价中有以下两点问题:一方面,如前文所述,由于空气质量特征本身抽象度较高,经过卷积操作往往与其他噪声特征糅杂在一起,因此需要将噪声特征进行过滤;另一方面,相比于其他物体检测任务,反映空气质量的特征并不集中于图像的某一块区域,而是散布于整幅图像,因此需要加强网络模型针对细节提取小尺度特征的能力。目前很多方法借鉴了目标检测领域比较成熟的检测方法,并在此基础上,围绕上述问题对现有的网络模型进行了针对性的改进。例如张富凯等人[22]对传统的YOLOv3[23]算法进行了改进,首先增强深度残差网络,而后通过多尺度特征提取以及特征图融合机制,提升网络模型对复杂环境下小目标的检测能力。徐诚极等人[24]则将一种注意力机制引入YOLOv3算法,将通道注意力及空间注意力机制加入特征提取网络之中,使用经过筛选加权的特征向量来替换原有的特征向量,达到过滤特征噪声的目的。另外陈幻杰等人[25]提出了一种改进的多尺度卷积特征目标检测方法,用以提高SSD[26]模型对中目标和小目标的检测精确度。该方法对SSD 模型低层特征层采用区域放大提取的方法以提高对小目标的检测能力。还有的方法直接对图像质量进行评估,例如Li等人[27]将显著性检测与人类视觉系统(HSV)相结合,使用HSV空间中的灰色和颜色特征训练模型对图像进行去噪。类似于上述方法的研究思路,本文在现有网络模型的基础上,设计了专门的机制来提取图像细节特征并过滤掉深度特征中噪声的干扰。首先在训练网络模型之前对数据集进行了预处理,将空气质量的检测转换为一个多锚点(anchor)的回归和分类过程,有效地监督了网络对图像各个区域的细节特征进行学习,然后使用卷积投票模块对所有锚点的检测结果进行分析和过滤,剔除掉不合理锚点位置上卷积产生的噪声影响,形成最终的空气质量指数和PM2.5浓度评价。
鉴于YOLOv3在图像检测上的优越性能,本文利用该网络模型提取和分析空气质量深度特征,并基于darknet[28]框架以方便算法在不同平台间进行移植。一方面,YOLOv3 使用darknet-53 作为主要的特征提取网络,其结构是从各主流网络选取性能比较好的卷积层进行整合得到,同时由于各层使用了3×3和1×1的小尺寸卷积核,减少了各层的卷积操作数目,保证了较高的检测效率。除此之外,小卷积核也有利于网络模型对小尺度的目标进行检测。由于空气质量信息反映于图像的像素细节,因此基于小卷积核进行特征提取有利于捕获与空气质量相关的细节特征;YOLOv3的具体网络结构如图5 所示。另一方面darknet 框架本身完全由C 语言实现,没有任何依赖项,虽然最初构建于Linux环境,但darknet 作为轻型的深度学习框架便于移植。由于评估空气质量的工作需要在不同的手持设备上进行,因此选择darknet 框架,有利于在不同平台终端进行检测模型的本地端部署。本文在进行空气质量的检测研究时,使用的是darknet在Windows上的移植版本。
本文的主要贡献在于:
(1)本文针对非固定场景下的空气质量指数评估,以及固定场景下的PM2.5浓度预测两个问题,提出了基于卷积投票模型的空气质量评价方法,该模型包含多锚点检测算法和卷积投票算法两个模块,是对图像检测算法在空气质量评价任务中的扩展和改良。
(2)在卷积投票模型中,设计了多锚点检测机制用于提取和分析空气质量深度特征。通过在一幅图像上设置多个锚点检测位置,以及相对应的锚点检测框(anchor box),可以监督网络同时得到不同图像区域特征的检测结果,包括小尺度锚点检测框对图像局部域特征的检测结果,大尺度锚点检测框对图像全域特征的检测结果,以及中心位置锚点检测框对图像中心域特征的检测结果。
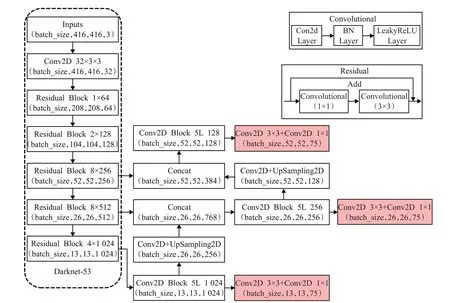
图5 YOLOv3网络结构图
(3)在卷积投票模型中,构建了卷积投票网对多锚点检测算法得到的结果进行进一步分析。基于所有锚点给出结果的置信度高低,过滤掉不合理卷积操作产生的噪声影响,修正多锚点检测机制的评价结果。同时对比了不同卷积投票策略下,算法估计精度的变化。最后通过竞赛印证了本文所述方法的有效性。
4 多锚点检测
目前效果较好的基于深度学习的图像检测算法,例如Faster-RCNN[29]、SSD、YOLO系列[23,30-31]都使用了锚点(anchor)作为基本的检测机制。本文所借鉴的算法YOLOv3,其做法是将图像平均划分为多个单元(cell),然后在每个cell里面放置一个锚点,每个锚点负责预测若干个子框(box)。YOLOv3 的锚点检测框(anchor box)机制相当于在图像上均匀散布密集的检测锚点,提取以锚点为中心,检测框大小的图像域进行分析。YOLOv3在每张图片上共产生10 647个锚点检测框,相当于对图像上以锚点为标记的各个区域特征进行穷举分析。
锚点检测框在回归边界盒大小时只参照图片有效区域的大小,即真实值(Ground truth),这种机制适用于目标检测任务,即图像上只有少量有效的目标区域特征,其余均为无效的背景特征。但是在空气质量检测问题中整幅图像都是有效目标区域,这使得一些直接套用目标检测网络模型的方法只能基于图像的全局域特征进行空气质量指数等级的大致分类。而本文的方法旨在发挥锚点检测框机制在分析和提取局部图像特征的优势,将传统方法的单一分类转化为基于锚点检测框机制的数值回归,使模型在估测具体的PM2.5浓度数值时也有较好的精度。但是本文所采用的多锚点检测有别于YOLOv3原始的锚点检测框机制,并不关心于锚点检测框的生成实现,这项工作由YOLOv3的原始算法完成。本文的方法是基于锚点检测框构建数据标签(label),显式指定锚点检测框标签(anchor box label)的锚点位置以及边长数据,并设置不同比例的锚点检测框标签监督训练网络,使模型能够同时给出对图像的全域特征和局部域特征的评价结果。为构建锚点检测框标签本文首先进行数据转换,将空气质量数据集的标签转换为训练YOLOv3模型所需的VOC[32]格式,然后通过数据增广完成多锚点检测机制的设置。本文使用的训练和测试数据集由2018年全球人工智能应用大赛赛事主办方提供。
4.1 锚点标签转换
本文基于锚点机制,针对两种不同的检测任务分别转换制作了用于非固定场景下空气质量指数分级评定的锚点分类标签(anchor Classification label),以及用于固定场景下PM2.5浓度预测的锚点回归标签(anchor Regression label)。数据标签格式参照VOC 数据集的标签,包括一个类别标签和一个检测框,其中检测框用中心点坐标(x,y)以及长w和宽h描述。具体格式形式化表示为class,x,y,w,h,其中x、y、w、h均用图像的尺寸进行归一化。
4.1.1 锚点分类标签
在预测非固定场景下的空气质量指数的具体问题中,官方给定数据集中空气质量指数标签分为6 个级别,标签从0 至5 依次代表优、良、轻度污染、中度污染、重度污染以及严重污染。因此视等级为类别来构建锚点分类标签。
如图6所示,基于class,x,y,w,h的格式,每幅图像的锚点分类标签包含一个class∈[0,5] 的类别标签和两种锚点检测框的中心位置记忆长宽比例Ground truth x,y,w,h。其中,第一种锚点检测框Ground truth(GT)的中心点坐标x,y为图像中心,边框长度w,h为图像长宽W,H,用以学习图像的全域空气质量特征并给出总体评价。第二种锚点检测框Ground truth的中心点坐标x,y为图像上的随机位置,然后本文基于YOLOv3最后一个输出特征图的尺度13×13,将边框长度w,h设置为图像尺寸的1/13,用以学习图像的局部域空气质量特征,并通过局部评价修正总体评价。最终锚点分类标签形式化表示为:


图6 锚点分类标签示意图
4.1.2 基于2D坐标的变换
在预测固定场景下的PM2.5浓度的具体问题中,官方给出了四个固定单一视角下的空气质量图片数据集。每幅图像的标签信息包括该场景对应的PM2.5浓度,拍摄时相对湿度大小(百分比形式),以及拍摄时间(精确到小时),形式化表示为 PM2.5,湿度,时间 。其中湿度和时间两个影响因子可以为PM2.5浓度的预测提供辅助作用。但是由于预测连续型数据值的难度较大,即使基于单一视角的固定场景并使用影响因子进行校正,依然无法利用分类模型直接检测精确的PM2.5浓度。本文摒弃了单纯的分类检测模式,通过构建锚点回归标签引入了回归过程处理此问题。如图7所示,标签的转化形式可以表示为:
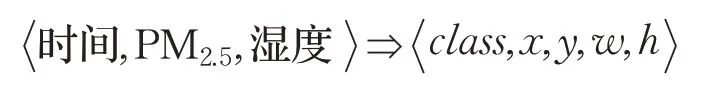

图7 锚点回归标签示意图
本文将锚点检测框的Ground truth 设定成一个长宽分别为PM2.5浓度和湿度的矩形框,然后通过回归算法对锚点检测框的边界盒进行预测,由此将对PM2.5浓度的检测转化为了一个回归过程,回归得到的锚点检测框的边界盒的长度即是PM2.5浓度。在具体的锚点回归标签构建中,由于Ground truth 的w,h取值不再依据图像边长的比例,而是被赋予了 PM2.5,湿度 的实际意义,为了不使Ground truth 超出图像范围,本文使用图像尺寸(W大于最大PM2.5浓度数值,H大于最大湿度值)进行归一化。锚点检测框Ground truth的中心点坐标x,y同样分为两种:第一种为图像中心点;第二种为其他图像随机位置,具体取值将依据4.2 节中的增广算法给出。除此之外,由于数据集中的时间因子以小时划分为离散数据,本文基于YOLOv3的分类算法对时间因子进行分类预测,其中类别class∈[1,24] ,模拟一天之中不同时刻光照强度带来的影响,校正PM2.5浓度的回归结果。最终锚点回归标签表示为:
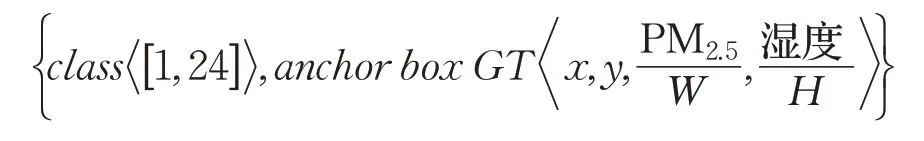
4.2 锚点数据增广
由于锚点检测框标签的优势在于监督网络模型提取和分析局部图像特征,使用单一的锚点检测框标签进行分类回归显然无法对整幅图像表征的空气质量情况进行全面的评价。因此需要对锚点检测框标签进行数据增广,通过锚点增广算法对锚点检测框Ground truth的中心位置x,y进行设定,将大量锚点检测框均匀地散布于图像上的有效区域,构建多锚点检测机制,促进网络模型学习并分析图像上所有的有效空气质量深度特征,进而给出完整合理的评价结果。
基于前文所述的YOLOv3区域提议方法,将图像划分为13×13 个单元(cell)区域,然后将锚点数量增广后散布于各个单元里面,为了得到均匀的散布,本文规定每个单元里面至多放置一个锚点检测框标签,负责监督该单元周围的空气质量深度特征的学习和评价。同时鉴于天空图像域的深度特征比地面图像域的深度特征更能表征环境空气质量,因此本文侧重对天空图像域中数据的分析,将图像上半部分(天空部分)与下半部分(地面部分)的增广比例设置为5∶1。基于本文对图像划分为13行13列,假设<i,j>是图像上某一个像素所处位置的行列号,则上半部划分为:i∈[0,12],j∈[0,6],用以大致包含图像的天空部分。下半部划分为:i∈[0,12],j∈[7,12] ,用以大致包含图像的地面部分。本文规定图像上半部分包含的锚点检测框标签个数为60,图像下半部分为12。下面分别介绍针对非固定和固定场景下两种空气质量检测任务的锚点增广算法,通过对锚点检测框标签的增广构建最终用于空气质量指数检测的非固定场景图像标签,以及用于PM2.5浓度检测的固定场景图像标签。
4.2.1 非固定场景图像标签
非固定场景图像标签的构建是基于对锚点分类标签的增广,如图8 所示,主要通过计算72 个锚点检测框Ground truth的中心点坐标x,y实现。

图8 非固定场景图像标签
首先指定一个大尺度的锚点检测框Ground truth,其中心点x,y为图像的中心点,尺寸w,h为图像尺寸,用于分析图像的全域特征并给出空气质量指数的总体评价。然后本文通过随机算法在图像上增广72个尺寸w,h为图像尺寸的1/13 的锚点检测框Ground truth,其中在图像的上半部分生成60 个anchor 位置,下半部分生成12 个anchor 位置。所有锚点检测框Ground truth 中心点坐标的计算过程基于所属单元在图像上的位置,以及x,y在单元内部的偏置给出:基于长宽分别为W、H的图像被等分为13×13个单元,每个单元的长宽分别为W/13、H/13,便有位于图像第i行第j列的单元,其左上角坐标为:(W/13 )×i,(H/13) ×j。于是中心点坐标可由如下公式得出:

其中,xoff∈[0,W/13] 和yoff∈ [0,H/13] 是锚点检测框Ground truth 中心点相对于所属单元左上角的偏置坐标,该值在相应单元区域内由随机算法生成。另外如前文所述i∈[0,12],j∈[0,6] 说明锚点检测框Ground truth的中心点位于图像上半部,i∈[0,12],j∈[7,12] 说明位于下半部。最后用W,H对x,y进行了归一化。
4.2.2 固定场景图像标签
固定场景图像标签的构建是基于对锚点回归标签的增广,如图9 所示,核心算法同样是计算72 个锚点检测框Ground truth的中心点坐标x,y。为加速和简化计算,本文将不同尺寸的图片缩放到650×650的同一尺寸下,并使用这个尺度对锚点检测框Ground truth的值进行归一化。
首先类似于非固定场景图像标签指定一个x,y为图像中心位置的锚点检测框Ground truth,这是由于考虑到卷积操作的原理,中心锚点的感受野(ReceptiveField)要大于其他位置的锚点,并且图像中心的特征会被多次提取,因此有必要设计一个的中心锚点检测框Ground truth,专门针对图像中心域的PM2.5浓度值进行评价。但是Static label中并没有使用图像尺寸设计锚点检测框Ground truth,这是因为基于整幅图像的全域特征信息(最大数公里级别),直接给出PM2.5的总体评价难以保证精度。因此在固定场景图像标签中,所有增广得到的72 个锚点检测框Ground truth的都被赋予唯一的尺寸。
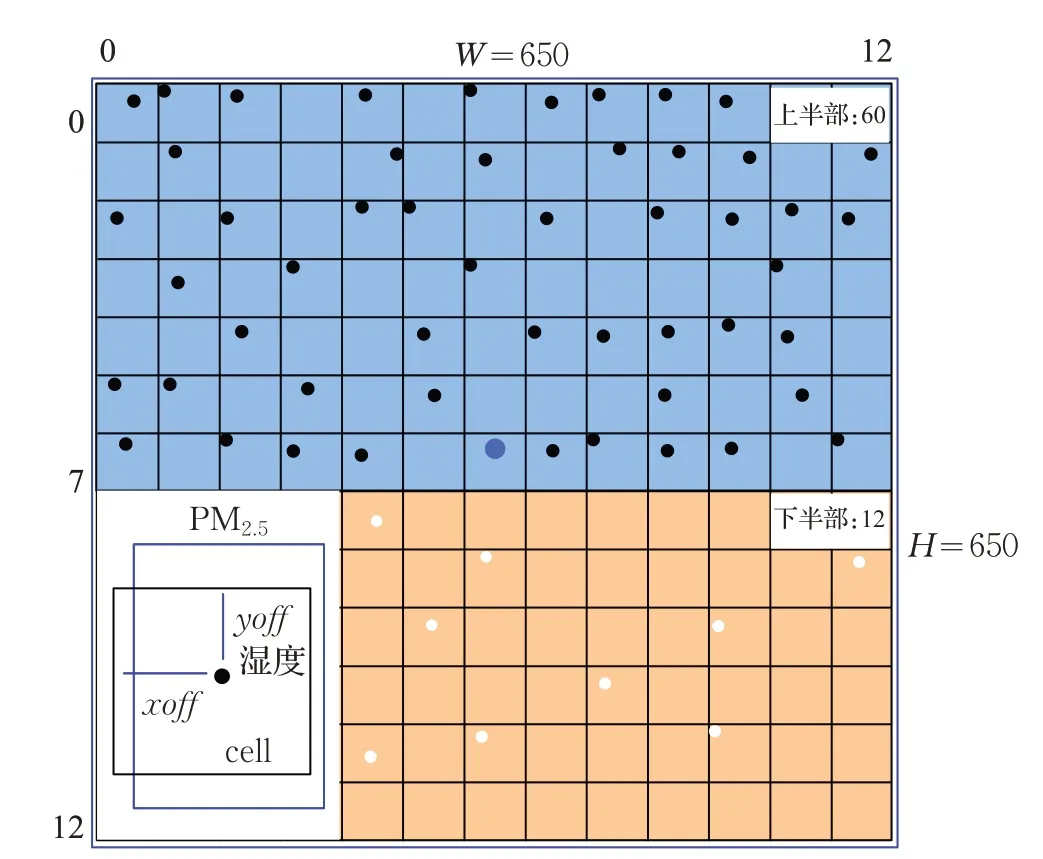
图9 固定场景图像标签

其中,xoff∈[0,50] 和yoff∈ [0,50] 是锚点检测框Ground truth中心点相对于所属单元左上角的偏置坐标,该值在相应单元区域内由随机算法生成。同样的,i∈[0,12] ,j∈[0,6] 说明锚点检测框Ground truth的中心点位于图像上半部,i∈[0,12] ,j∈ [7,12] 说明位于下半部。最后用 650,650 对x,y进行了归一化。
使用固定场景图像标签完成训练之后,网络在测试阶段首先通过darknet-53模块提取锚点位置周围区域图像特征,在此区域回归出一个与锚点检测框Ground truth具有较高IOU的锚点检测框,其边界盒的长度即是PM2.5浓度。
基于锚点增广机制,非固定场景图像标签或者是固定场景图像标签都有72 个锚点检测框的标注,图10 给出了非固定场景图片中锚点数据的增广效果。利用锚点增广机制训练完成的网络模型会根据输入的图片产生72个输出值。为得到反映整幅图像空气质量的统一评价,本文提出了卷积投票网,对来自于图像各个区域的72个卷积结果进行分析、筛选和综合。

图10 非固定场景图片中锚点数据增广效果
5 卷积投票网
实际上,卷积投票网是网络输出层的扩展,这种卷积投票的思想将本文的方法与其他基于深度特征的算法区别开来。卷积投票网总体上基于两个模块构建,分别是卷积置信度机制和投票算法。其中,卷积置信度机制可以过滤掉图像不同区域内无效的卷积操作,即噪声深度特征带来的影响。而投票算法则进一步基于卷积结果的置信度大小进行打分和加权计算,最终得出对整幅图像的唯一评价。图11分别将卷积置信度的估计值(a)和相应的类别评价(b),以及基于置信度阈值过滤的PM2.5浓度估计结果(c)进行了可视化表示。
5.1 卷积置信度机制
如上文所述,并不是所有图像域的卷积深度特征都可以表征空气质量,因此基于部分噪声特征产生的结果并不可信。为描述结果的可信程度,在YOLOv3的锚点检测机制中,每个锚点检测框在得到输出结果的同时会给出该结果的置信度得分,这些置信度分数反映了锚点检测框所在图像域包含空气质量有效特征的信心程度,以及锚点检测框中相关检测值的准确性。具体的,置信度被定义为:
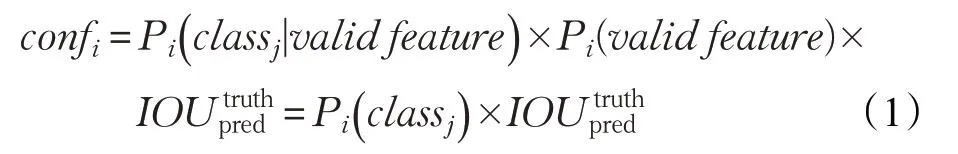

图11 (a)基于锚点的置信度估计效果

图11 (b)基于锚点的类别估计效果

图11 (c)基于置信度阈值过滤的PM2.5浓度估计效果
5.2 投票算法
投票算法的核心是将卷积网络的输出结果进行均值池化(meanpooling)或者最大池化(maxpooling),相当于综合考虑了全部有效深度特征对空气质量评价的投票结果。另外基于评价任务的难度不同,相比较于在非固定场景下评估空气质量指数等级,在固定场景下预测PM2.5浓度时,卷积投票网使用的投票算法种类更多。
为方便表达,做如下简称:
在非固定场景下评估空气质量指数等级问题为NotStatic Level问题;在固定场景下预测PM2.5浓度问题为Static PM2.5问题。
NoStatic Level最大投票算法:
在NotStatic Level 问题中,投票算法对所有N=72个输出值进行maxpooling,取置信度最大的第i个锚点检测框中的类别值classj作为空气质量等级检测值:

相比于 NoStatic Level 投票算法,Static PM2.5问题中的求解目标是锚点检测框回归得到的PM2.5浓度值,因此Static PM2.5问题并不基于类别进行投票,而是对锚点检测框的长度值应用投票算法。
Static PM2.5最大投票算法:
该投票算法基于maxpooling,在所有N=72 个检测结果中,取置信度最大的锚点检测框的长度值作为检测结果,则有:

其中boxi.right是网络输出的第i个锚点检测框右侧坐标值,其与左侧坐标值boxi.lef差值即为代表PM2.5浓度的检测框边长。于是表示第i个锚点检测框输出的PM2.5浓度。
Static PM2.5平均投票算法:
Static PM2.5问题中,考虑到PM2.5浓度值的非离散属性,如果采用maxpooling 会丢失较多有价值的信息,因此对所有N=72 个输出结果进行meanpooling,以综合图像上不同区域检测结果对总体结果的影响:
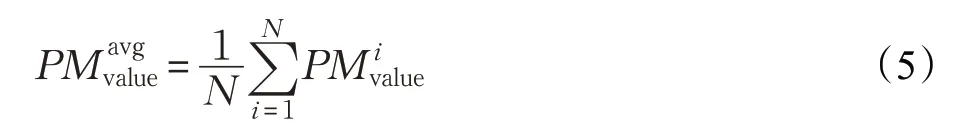
对所有结果meanpooling 存在一定问题,不希望那些conf不高的输出结果影响最终的检测值,因此本文设计了一种基于置信度门限(threshold)的投票算法,只对置信度大于门限的输出结果进行meanpooling,这里门限值μ取0.95。
Static PM2.5基于置信度门限的投票算法:

其中,n为置信度大于门限的输出结果个数。应该注意到,即使取置信度在0.95 以上的输出,仍不能保证单个样本锚点检测框的检测结果没有误差,甚至个别锚点检测框的检测结果会与其他样本框的结果偏差较大,以至于成为噪声样本。为消除这些噪声结果,本文设计了一种基于置信度门限的排序投票算法。
Static PM2.5排序投票算法:
由于本文选取的置信度门限较高,因此可以认为所有高于门限的输出值都具备最高置信度,即confi≈1。在理想情况下,对于相同的检测内容,所有最高置信度的PM2.5检测值应该相近,因此,如果某个检测框输出结果的置信度在门限以上,但是与其他最高置信度结果的平均值相差较大,那么该检测框的输出值就可以被判定为噪声。于是本算法旨在过滤掉那些异常的输出结果,挑选出置信度和相似度都比较高的输出值来拟合最终的PM2.5检测值:

6 结果分析
本文详细分析了不同权重的网络模型基于不同检测策略时,在官方测试数据集上的结果。相比于NotStatic Level 问题,Static PM2.5问题更为复杂且改进的空间更大。在两个问题取得一定得分后,改变策略对Nostatic Level 问题分数的提升较小,相比之下Static PM2.5问题的分数提升更多。总体上虽然分数的提升并不是跨越式的,但是对于空气质量评价准确率的提升可以充分印证本文提出的多锚点检测机制和卷积投票算法的有效性。表2 分别列出了解决两个问题所采用的方案,以及各个方案在每个问题上取得的成绩和总成绩。其中10Kweights代表网络权重经过1万次epoch迭代的训练;MAX代表NoStatic Level最大投票算法或者Static PM2.5最大投票算法;Aug 代表锚点增广算法;Conf_0.95 代表基于置信度门限为0.95 的投票算法;Sort_top5代表取置信度前五个值的排序投票算法;Total为两个问题的总成绩。下面本文基于NotStatic Level问题和Static PM2.5问题的评分结果,对多锚点检测机制和卷积投票网的作用进行评价。
6.1 多锚点检测机制的评价
在NotStatic Level 问题中,由于只有6 个空气质量等级类参与分类,因此卷积投票网可以认为置信度较大的类别输出值是准确的,进而只采用最大投票算法给出评价。基于卷积投票网在此处的算法固定,通过分析评测结果主要验证了锚点增广算法的有效性。第一次测试时,采用权重经过1 万次epoch 训练的网络模型进行检测,然后结合最大投票算法得到34.41 分的评价结果。接下来本文对锚点增广算法进行了验证。在下一次测试前,基于锚点增广训练网络模型迭代2 万次epoch,这一策略的使用在第二次测试中将评分提高到38.22,表明采用锚点增广算法和增加的训练次数带来了3.81 分的改良。第三次测试前没有进行策略上的改进,继续增加的1 万个epoch 训练带来了1.19 分的提升。从结果来看模型训练到3 万个epoch 已基本收敛,总体上,增加训练伦次带来了一定程度的改进,但是锚点增广算法的使用才是检测效果提升的关键,如图12所示。

图12 NotStatic Level问题对多锚点检测机制的验证
在Static PM2.5问题中,多锚点检测机制同样帮助网络提升了检测准确度。该问题的第一次评价,基于训练次数为2 万个epoch 的权重和最大投票算法,得到3.07分,之后同样进行了锚点增广。这一策略与增加的1万个epoch 训练将评分提高到5.70 分。同时,通过与Not-Static Level问题结果的对比发现,2万个到3万个epoch训练次数的提升只能带来39.41-38.22=1.19 分的改进,这说明在Static PM2.5 问题中,第二次评价产生的5.70-3.07=2.63 分的提高主要源于锚点增广算法的应用,这也印证了多锚点检测机制在空气质量评价中的核心作用。

表2 不同检测策略下的得分结果
总体上,不论是针对NotStatic Level 问题或者是Static PM2.5问题,只依赖于检测算法本身得到的评价结果精度都比较低,并且单纯地增加训练迭代次数并不能带来检测效果的提升。但是采用多锚点检测机制可以打破YOLOv3 模型的检测瓶颈,大幅度地提高检测精度。其中对于NotStatic Level 问题的提升基本来自于多锚点检测机制的作用。而在Static PM2.5问题中,多锚点检测机制也可以在少量的训练次数之内带来较大的精度提升。
6.2 卷积投票网的评价
鉴于在NotStatic Level 问题中只采用了最大投票算法,因此卷积投票网对于检测能力的改进主要反映在Static PM2.5问题的评价结果上。基于前文所述,在Static PM2.5问题的第二次测试中,锚点增广算法将得分提高到5.70分。由于第三次测试前没有进行策略上的改进,而且增加的1 万个epoch 训练并没有带来成绩的提升,这说明网络模型的训练已达到泛化能力的瓶颈,后面评价结果的提升完全来自于卷积投票网中投票算法的作用。在第四次测试中,由于使用了Static PM2.5基于置信度门限的投票算法,帮助模型取得9.61 分的评价结果,相比前一次实现了3.91 分的较大提升。最后一次测试中,基于卷积投票网对策略做出进一步改进,利用Static PM2.5排序投票算法剔除了高置信度数值中离散程度较大的噪声项,同时结合经过7 万次epoch 训练的网络权重,得到了目前为止Static PM2.5问题上的最高分10.09,如图13所示。
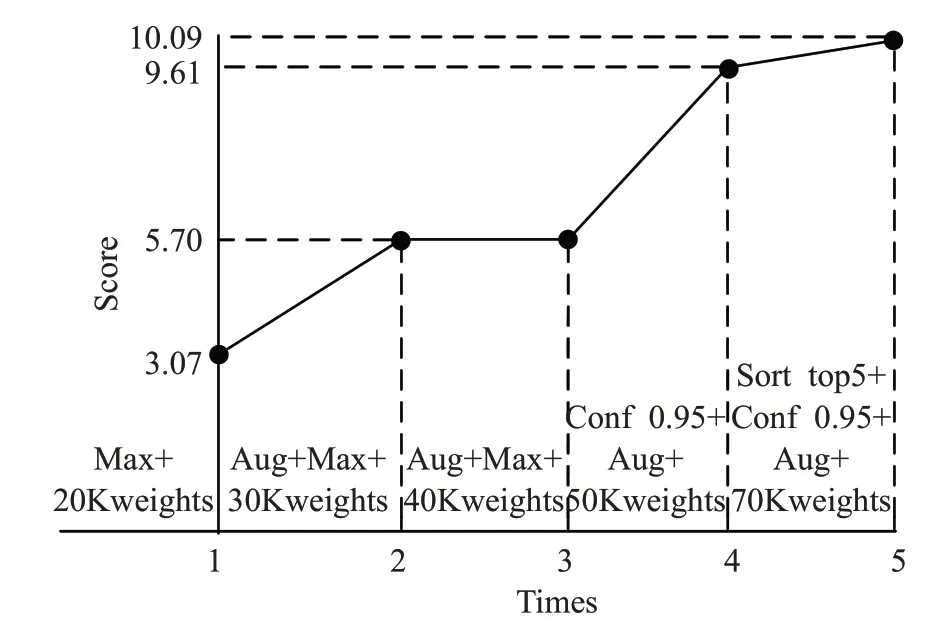
图13 Static PM2.5问题对卷积投票网的验证
可以看出,对PM2.5浓度值这种连续型数值进行检测的难度要远远大于对空气质量等级等离散数据的估计。YOLOv3 作为目前深度学习中效果较好的图像检测算法,其对于离散数据的分类能力同样要强于对边界框坐标值的回归,YOLOv3只能给出目标边界框的粗略坐标,难以将其回归机制直接移植到PM2.5浓度的估计任务上。虽然多锚点检测机制突破了YOLOv3 的检测瓶颈,但是由于检测连续型数值本身固有的难点,多锚点检测机制难以保证所有锚点的检测结果都可信,实验结果表明,算法直接对所有锚点检测结果进行meanpooling得到的分数仅为最高分数的56%,这说明由于多锚点检测在此问题中带来了多噪声,极大地干扰了最终结果的输出,因此本文进一步采用基于门限的卷积投票策略过滤置信度较低的检测噪声,这使得检测效果得到了69%的提升。但是考虑到实际情况中高置信度的检测结果也有可能为噪声,算法最后基于排序投票策略,将与平均值相差较大的输出结果视为噪声,并且通过过滤掉这部分噪声,将检测精度进一步提升了5%。
总体上,卷积投票网主要用于Static PM2.5等连续型数值的预测问题,相比于最初直接使用YOLOv3进行浓度值回归的做法,卷积投票网带来了229%的提升,相比于受噪声影响较大的多锚点检测机制,投票策略得到了77%的提升。同时由于卷积投票网是针对YOLOv3 模型的输出端进行进一步处理,因此并没有增加太多的运算量。具体实验中,算法基于检测精度最高的Static PM2.5排序投票算法,对官方给出的Static PM2.5问题测试数据集进行结果输出,处理67 张图片的检测结果仅需要0.01 s左右的时间。
7 结语
本文在基于深度特征的图像检测算法基础上,提出了一种使用多锚点检测和卷积投票网进行空气质量评价的方法,分别适用于不固定场景非静态环境下的空气质量指数评估(NotStatic Level 问题),以及固定场景静态环境下的PM2.5浓度预测(Static PM2.5问题)。与传统的借鉴深度学习网络,对空气质量深度特征进行无差别分析的方法不同,本文提出的多锚点检测机制和卷积投票网,不仅可以给出对全域特征的分析结果,还能够实现对局部域特征的具体评价,并且可以在一定程度上过滤掉噪声深度特征带来的干扰。本文所述方法在2018年全球人工智能应用大赛中得到了总分第3 名的成绩。为减少时间耗费,本文在darknet 框架下基于单模型网络进行端到端的训练,以达到实时的需求。下一步的工作包括:(1)进一步提升多锚点机制对于深度特征提取的准确度。本文的多锚点机制是基于固定的上下图比例,随机地设置各个区域的锚点。为得到更为合理的锚点,可以预先分析出图像上大致的有效区域。例如文献[6]利用深度学习模型自动检测和提取图像的天空部分,虽然只分析天空部分的做法有待商榷,但是其思路可以被借鉴。(2)进一步探索基于时序模型的卷积投票网。目前有一些工作[33]利用时序卷积网络模型(例如LSTM、RNN等),对时间维度上的长程深度特征进行分析。可以基于卷积投票网对相同环境属性的深度特征进行跟踪分析,综合它们在不同时刻的投票结果,进而将卷积投票网应用于多锚点和多时间点两个维度上。
猜你喜欢
核科学与工程(2021年4期)2022-01-12 06:30:22
通信电源技术(2021年2期)2021-05-21 02:33:46
电子技术与软件工程(2020年22期)2021-01-30 05:29:42
数字技术与应用(2020年12期)2021-01-22 13:40:40
移动通信(2020年5期)2020-06-08 15:39:51
计算机应用(2018年5期)2018-07-25 07:41:26
环境保护与循环经济(2017年3期)2017-03-03 20:08:30
汽车与安全(2016年5期)2016-12-01 05:22:14
汽车与安全(2016年5期)2016-12-01 05:22:13
中国环境监察(2016年11期)2016-10-24 05:25:12
