
向量型二元语义密度集结算子及其应用
2020-10-19 11:53:36易平涛李伟伟
东北大学学报(自然科学版) 2020年10期
易平涛, 王 露, 李伟伟
(1. 东北大学 工商管理学院, 辽宁 沈阳 110167; 2. 东北评价中心, 辽宁 沈阳 110167)
多属性决策是指根据决策问题描述的多种属性信息,对有限个决策备选对象进行综合排序,并从排序结果中选择最优的备选对象.多属性决策愈来愈成为诸多领域如管理、军事、医学等的重要研究工具,是现代决策领域的重要研究内容.迄今为止,精确值信息形式的决策方法[1]成果积累较多,但随着信息技术的高速发展,决策环境变得日趋复杂,决策者面临的决策信息也更加多样,其中非精确值形式,如模糊信息[2-3]、语言信息[4-10]等的决策问题近年来引起众多学者的广泛关注.然而,就语言信息而言,属性信息有时与事先定义的语言评价集不能完全契合,只能近似表达,导致属性信息的失真和决策结果的偏差.为使属性信息可以更精确地反映语言集,Herrerα等于2000年率先提出了二元语义信息的分析方法及二元语义有序加权平均(T-OWA)算子[4].在二元语义有序加权平均(T-OWA)算子的基础上,韩二东等[11]将不同数据类型的偏好信息转化为二元语义形式的判断矩阵,对偏好判断矩阵进行处理,得到决策者对各方案的偏好程度.张茂竹[12]认为决策者面向语言型群决策问题时存在犹豫的情况,鉴于此,在犹豫模糊的环境下提出区间值犹豫模糊二元语义BA算子.文献[13-14]基于二元语义的犹豫模糊语言信息对多属性决策问题进行探讨.王洪强等[15]基于灰色关联分析法对二元语义信息的评价指标进行集结,为PPP项目的私人合作伙伴的选择提供决策参考.Chen等[16]提出EMGeoBM(extended modified geometric bonferroni mean)集结方法应用于二元语义信息环境中,并与已有的二元语义相关的集结算子进行比较,说明该方法的有效性.于婷等[17]基于二元语义信息提出了时序激励加权平均算子集结群体语言评价信息.Liu等[18]提出了直觉二元语义信息广义集结算子,用于处理直觉二元语义信息的群决策问题.
上述研究就二元语义信息形式的集结方法进行了探讨,但未考虑信息的内部结构,如数据分布的疏密程度.文献[19]考虑了属性值的分布结构特征,提出了密度加权平均(DWA)中间算子.该算子的主要特征是通过分组的方式对决策信息进行集结,从而能够为已有算子(如AA,WAA,OWA,Min,Max等)的融合提供了统一框架.
文献[20]在密度中间集结算子的基础上,基于二元语义信息提出了二元语义密度(T-DW)算子,并将其应用于不确定多属性决策问题中.该研究只针对一维二元语义信息展开了讨论,而在复杂决策问题中,二维向量数据形式的评价信息也较为常见,尤其当决策信息量较大时,以向量的方式进行数据的合成处理,更能有效提高决策效率.为此,在文献[20]的基础上,对一维二元语义信息密度加权算子做进一步的拓展研究,提出面向二维二元语义信息的向量型密度加权算子,并分析了该算子的性质.数据聚类及不同聚类组对应的密度权重的确定是其中需要解决的关键问题,因而本文进一步对向量形式的二元语义信息的分组方法及密度加权向量的求解进行了探讨.
1 问题界定
1.1 二元语义信息简介
关于二元语义信息,通常可由二元组(sk,ak)来表示,其中元素sk和ak的含义描述如下:
1)sk为事先设定好的语言标度评价集S中的第k个元素.例如:可将由7个元素构成的语言标度评价集S定义为S={s6=FZ(非常重要),s5=HZ(很重要),s4=Z(重要),s3=YB(一般),s2=C(差),s1=HC(很差),s0=FC(非常差)}[4,21].
2)ak为符号转移值,满足ak∈[-0.5,0.5),表示实际判断(或偏好)值和sk的偏差.
设β∈[0,T]为语言评价集S的元素经过处理得到的实数,其中T表示语言标度评价集S中元素的个数,二元语义信息通过β表示如下[4,21]:
Δ:[0,T]→S×[-0.5,0.5),.
(1)
其中round函数表示四舍五入取整.若(sk,ak)为二元语义信息,sk为S中的第k个元素,ak∈[-0.5,0.5),则存在函数[4,21]:
Δ-1:S×[-0.5,0.5)→[0,T].
使其转化为相应的数值β∈[0,T],即
Δ-1(sk,ak)=k+ak=β.
(2)
1.2 基本思路
假设O={o1,o2,…,on}为方案集,X={x1,x2,…,xm}为评价参与者集或指标集,其中M={1,2,…,m},N={1,2,…,n},Q={1,2,…,q}.为简便起见,将方案oi(i∈N)关于专家或属性xj(j∈M)的评价信息记为xij.本文主要针对xij取值为二元语义信息形式的多属性或群体决策问题展开研究.
首先对向量型二元语义密度加权(V-TDW)算子及其合成算子的性质进行了分析,然后基于信息分布的疏密程度,提出了基于向量相似度的聚类方法,对向量型二元语义信息进行分组.在聚类组的基础上,通过最大熵值法对不同聚类组的密度加权向量进行求解.最后通过算例对向量型二元语义密度集结算子的应用进行简要说明.
2 V-TDW算子及性质分析
2.1 V-TDW算子的构建
设有m位专家对n个方案的语义决策信息矩阵为X=[xij]n×m,xij=(sijk,aijk)为二元语义信息,sijk为第xj个专家关于方案oi的评价信息对应的某语言评价集S中的第k个元素,aijk代表相应偏差),可将第j位专家对应的所有方案的决策信息写成如下向量形式:Xj=[(s1jk,a1jk),(s2jk,a2jk),…,(snjk,anjk)]T.据此,可进一步将决策信息矩阵表示为X=[X1,X2,…,Xm].
对决策信息矩阵X=[X1,X2,…,Xm],设A1,A2,…Al为X的非空子集合.若满足①Ak∩At=∅;k≠t;k,t=1,2…,l.②A1∪A2∪…∪Al=X,则称A1,A2,…,Al为X的一个划分,也称A1,A2,…,Al为X的l组二元语义向量信息的聚类.
定义 1对决策信息矩阵X=[X1,X2,…,Xm],设V-TDW:In→I,
(3)
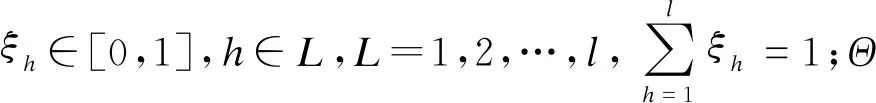
由式(3)可知,V-TDW算子作为中间算子,需要与已有的信息集结算子进行结合,下面以WAA算子为例,对密度算子的具体表达式进行定义.
定义 2设V-TDWAWAA:In→I,

(4)
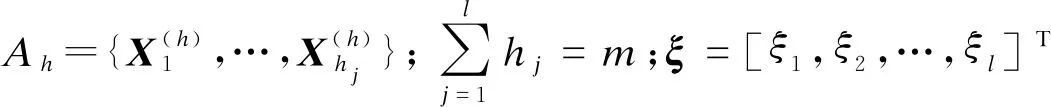
2.2 性质分析
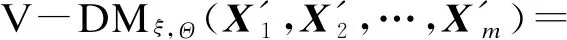
证明 根据式(3)知,

V-DMξ,Θ(X′1,X′2,…,X′m)=V-DMξ,Θ(X1,X2,…,Xm)
成立,结论得证.
性质2 幂等性:对任一二元语义决策矩阵X=[X1,X2,…,Xm],Xj=[(s1jk,a1jk),(s2jk,a2jk),…,(snjk,anjk)]T,Y=[(s1,a1),(s2,a2),…,(sn,an)]T,二元语义信息向量Y对应的数值向量为β=[β1,β2,…,βn]T.若∀j∈M,二元语义信息向量Xj=Y,则
V-DMξ,Θ(X1,X2,…,Xm)=β.
证明 由于Xj=Y,Xj可写为Xj=[(s1,a1),(s2,a2),…,(sn,an)]T,二元语义决策矩阵可写为X=[Y,Y,…,Y].设其降序排序后的l组聚类A1,A2,…,Al,Ah(h∈L)中元素为hj个,则
性质3 介值性:对于任一二元语义决策矩阵X=[X1,X2,…,Xm],有
min(βj)≤V-DMξ,min(A)≤V-DMξ,Θ(A)≤V-DMξ,max(A)≤max(βj),j∈M.

而
且
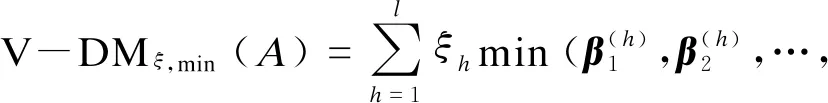
故V-DMξ,Θ(A)≥V-DMξ,max(A)≥min(βj),j∈M成立,结论得证.
3 基于向量相似度的二元语义向量信息的聚类
3.1 聚类方法
根据式(2)将多属性语言语义信息决策矩阵
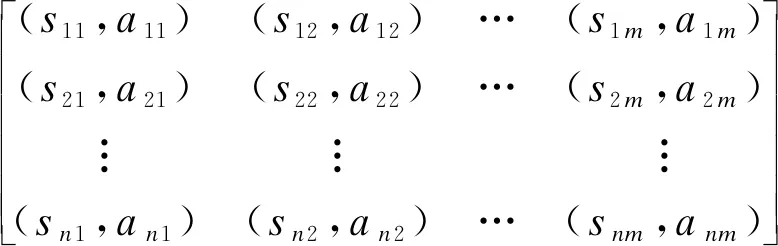
转化为
此时有Xj=βj=[β1j,β2j,…,βnj]T.
在此基础上,基于夹角余弦法[22]将二元语义转化为数值矩阵中任意两组向量之间的相似性进行衡量,并在此基础上给出相应的聚类方法.
设βp,βq表示二元语义信息决策矩阵的任意两个向量,令
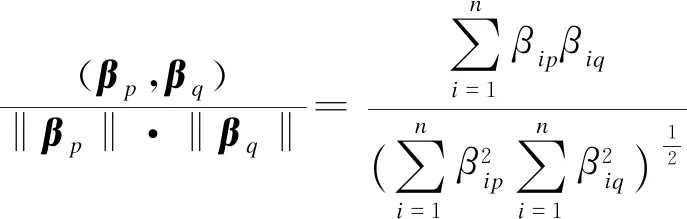
(5)
为向量βp,βq之间的相似度,取值范围为[0,1],且值越大,相似度越高,反之越小.
在上述分析的基础上,将矩阵β中的m个二元语义向量β1,β2,…,βm的具体聚类方法总结如下.
1) 求出两两向量βp,βq(p,q∈m)之间的相似度,构成相似度矩阵S=[sim(βp,βq)]m×m,其中sim(βp,βq)=sim(βq,βp),当p=q时,sim(βp,βq)=1.
3) 按从小到大的顺序依次选取l-1个最大的有序增量φt,在选中的φt的数据之间进行分割,得到相应的l个向量集A1,A2,…,Al,即为所求聚类组.
3.2 组内权重求解
求解向量βj内元素的均方差αj:
(6)

(7)
4 密度加权向量
令密度加权向量为ξ=(ξ1,ξ2,…,ξl)T,
(8)
式中:hj为序化后第h个聚类组Ah中向量元素的个数;λh∈(-,+)为密度影响因子,满足
密度加权向量可根据决策者对数据信息分布的偏好进行设置,当决策者偏好群体共识信息,密度加权向量应体现趋同性;当决策者偏好少数信息时,密度加权向量应体现趋极性;若决策者没有偏好,则密度加权向量应体现趋中性.
令密度加权向量ξ=(ξ1,ξ2,…,ξl)T的“组间同性”程度表示为
(9)
“组间极性”程度表示为
Te(ξ)=1-Ts(ξ).
(10)
当决策者偏好主体共识信息,则Ts(ξ)∈(0.5,1];当决策者偏好少数信息,则Ts(ξ)∈[0,0.5);当决策者没有偏好,则Ts(ξ)=0.5..
(11)
其中,En表示密度加权向量ξ=[ξ1,ξ2,…,ξl]T的熵.
熵值反映了向量中各元素的离散程度,熵值越小,元素间的差异越小,彼此的平衡状态越好.决策者可以根据信息分布的偏好,给出组间偏好水平,然后通过构建规划模型求解密度加权向量:
(12)
上述规划模型中,通过最大熵值法在密度加权向量的最大信息量的基础上,保证组间权重向量的均衡性,同时决策者可以表达自身的偏好,使决策结果更好地服务于决策者.
5 应用算例
随着市场经济的快速发展,企业之间的竞争日趋激烈.企业的竞争终究是人才的竞争,人才的选拔对企业的发展尤为重要.某单位邀请12位专家x1,x2,…,x12对8位在岗人员O1,O2,…,O8进行考核选拔,专家均以二元语义信息的形式给出被评价对象的评价信息,具体见表1.
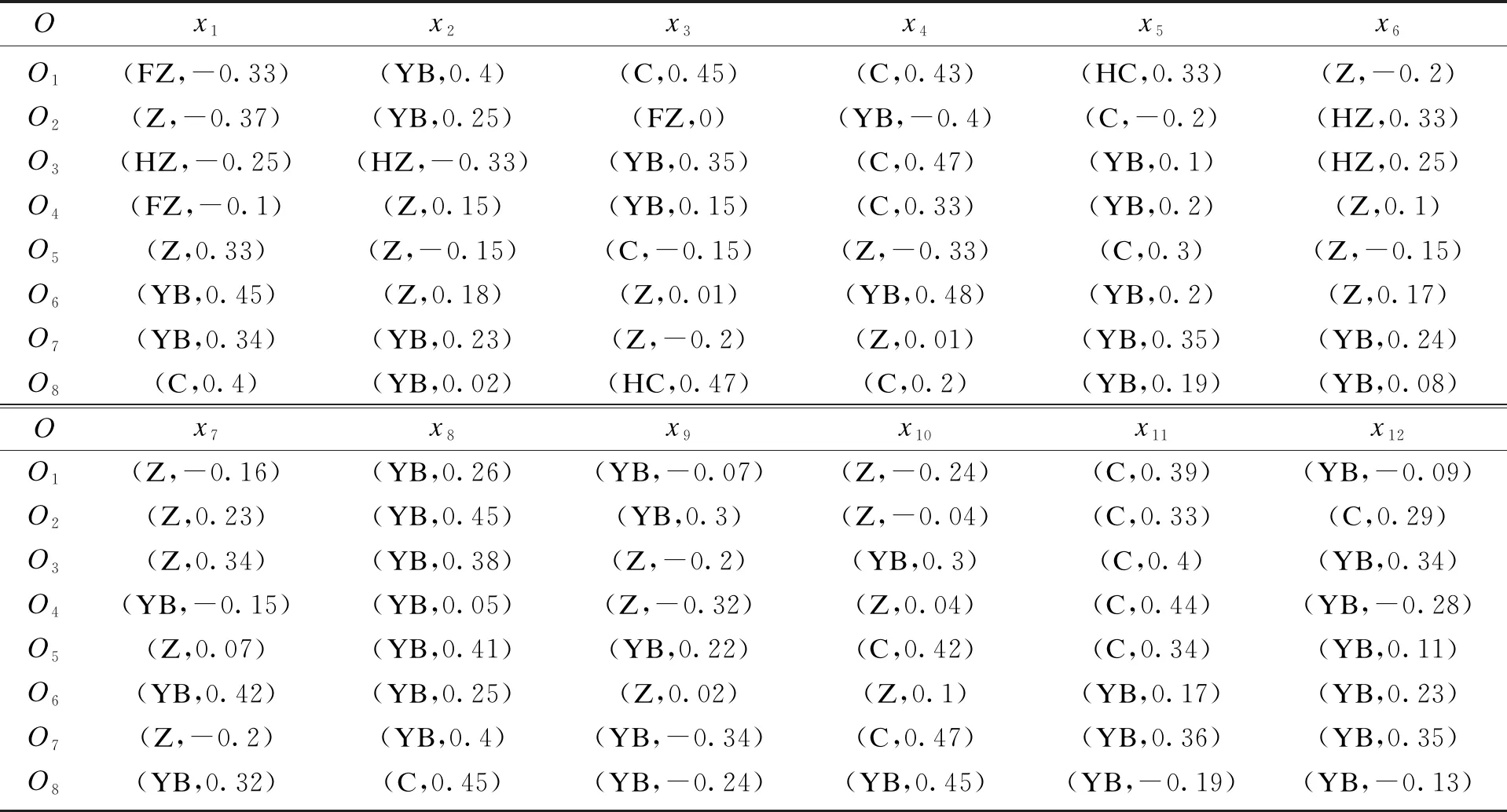
表1 二元语义评价信息
下面给出向量型二元语义密度算子的具体计算步骤:
1) 数值矩阵确定:表1中的二元语义决策信息每一列视为每位专家原始决策信息矩阵的列向量,将二元语义决策信息根据式(2)转化为相应的数值,得到如下转化后的数值矩阵,记为
2) 二元语义信息聚类组和组内权重确定:根据聚类方法,按式(5)计算向量β1,β2,…,β12两两之间的相似度sim,相似度矩阵为
从相似度矩阵中获取各向量的综合相似度集合为A={0.945 3,0.976 7,0.930 2,0.959 9,0.954 1,0.971 8,0.974 9,0.979 7,0.978 6,0.966 2,0.973 8,0.974 9},将集合A中的元素按从大到小的顺序进行排序,得到的有序组仍记为A={0.979 7,0.978 6,0.976 7,0.974 9,0.974 9,0.973 8,0.971 8,0.966 2,0.959 9,0.954 1,0.945 3,0.930 2},相应的专家排序集为{x8,x9,x2,x7,x12,x11,x6,x10,x4,x5,x1,x3},根据有序组A计算有序增量φt,t=1,…,11,得到有序增量集{0.001 06,0.001 97,0.001 72,0.000 05,0.001 06,0.002 05,0.005 62,0.006 25,0.005 79,0.008 86,0.015 03}.给定组数为4,选择有序增量集中前3大元素0.015 03,0.008 86,0.006 25为分割点,得到相应的向量集为{β1},{β3},{β4,β5},{β2,β6,β7,β8,β9,β10,β11,β12},对应的专家聚类组为A1={x1},A2={x3},A3={x4,x5},A4={x2,x6,x7,x8,x9,x10,x11,x12}.
以聚类组A4为例,根据式(8)得向量集{β2,β6,β7,β8,β9,β10,β11,β12}中8个向量的均方差分别为0.581 8,0.825 7,0.506 1,0.331 6,0.501 0,0.672 9,0.409 3,0.359 9.根据式(7)求得聚类组A4内的向量权重分别为w1=0.138 9,w2=0.197 1,w3=0.120 8,w4=0.079 2,w5=0.119 6,w6=0.160 7,w7=0.097 7,w8=0.085 9.同理,聚类组A3的组内权重为w1=0.477 2,w2=0.522 8.聚类组A1和A2的组内权重均为w1=1.
3) 密度加权向量的确定:假设决策者偏好主体共识信息,提前给出偏好程度为Ts(ξ)=0.6.由于后两组的元素个数相同,所以后两组的密度加权向量相等.通过规划模型(12)求得组间的密度权重为ξ1=ξ2=0.185 2,ξ3=0.274 0,ξ4=0.355 6,相应的密度影响因子为λ1=λ2=-2.572 8,λ3=0.573 1,λ4=0.723 3.
4) 决策信息集结:该算例根据式(4)的V-TDWAWAA算子计算得到评价对象O1,O2,…,O8的最终评价值向量为[3.214 6,3.711 9,3.683 2,3.695 1,3.136 4,3.646 4,3.445 6,2.537 9]T,排序结果为O2≻O4≻O3≻O6≻O7≻O1≻O5≻O8.
5) 与一维聚类方法和WAA算子的比较:与一维聚类方法的比较是以被评价对象O3的评价信息为例,将O1的二元语义信息转化的数值信息为4.75,4.67,3.35,2.47,3.1,5.25,4.34,3.38,3.8,3.3,2.4,3.34,将数值信息按从大到小的顺序进行排序,并求得相应的有序增量集为{0.5,0.08,0.33,0.54,0.42,0.03,0.01,0.04,0.2,0.63,0.07},选取前三大有序增量0.63,0.54,0.5,得到相应的专家聚类组为A1={x6},A2={x4,x11},A3={x1,x2,x7},A4={x3,x5,x8,x9,x10,x12}.按式(6)得聚类组A1的组内权重为w1=1;A2的组内权重为w1=0.507 2,w2=0.492 8;A3的组内权重为w1=0.345 2,w2=0.339 4,w3=0.315 4;A4的组内权重为w1=0.165 3,w2=0.152 9,w3=0.166 7,w4=0.187 5,w5=0.162 8,w6=0.164 8.组间权重按模型(12)进行求解,得ξ1=0.167 2,ξ2=0.213 1,ξ3=0.272 2,ξ4=0.347 5,求得O3的评价值为3.825 7.其余被评价对象的评价值按上述方法求得,这里不再赘述.O1,O2,O4,…,O8的评价值分别为3.188 9,3.904 6, 3.912 3,3.079 7,3.623 1,3.367 2,2.439 4,最终的评价对象排序为O4≻O2≻O3≻O6≻O7≻O1≻O5≻O8.
从上述一维二元语义密度算子方法求解过程来看,相较于本文提出的向量型二元语义密度算子,评价结果基本一致,但计算量明显增加.若针对实际应用中的大型综合评价问题,本文提出的以向量型数据作为封装数据进行处理,能够在较大程度上降低计算成本,提高决策效率.

运用WAA算子得出的评价结论较之本文提出的V-TDWWAA算子求得的评价结论差别较大,直接运用WAA算子求得的结果没有考虑数据分布特征及决策者偏好,而本文提出的算子通过数据分布的疏密程度考虑群体共识问题,可以更好地为决策者提供更贴合其偏好的评价服务.
6 结 论
1) 以向量为基本运算单位给出了向量型二元语义密度集结算子,并对其性质进行了分析,得出该算子具有置换不变性、幂等性、介值性等基本性质的结论.
2) 根据二元语义信息对应的数值,给出了基于二元语义向量相似度的聚类方法.在此基础上,依据向量的局部差异性对聚类组内的向量进行赋权,然后通过规划求解确定组间密度权重.
3) 将向量型二元语义密度算子与已知的信息集结算子(WAA算子)进行合成,用于向量形式的二元语义信息的集结.
猜你喜欢
英语文摘(2021年12期)2021-12-31 03:26:20
数学物理学报(2021年2期)2021-06-09 08:54:26
应用数学(2020年2期)2020-06-24 06:02:44
开放教育研究(2020年2期)2020-03-31 01:54:14
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:54
当代陕西(2018年9期)2018-08-29 01:20:56
数学物理学报(2016年3期)2016-12-01 05:36:27
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
软科学(2014年8期)2015-01-20 15:36:56
