
混合阶通道注意力网络的单图像超分辨率重建
2020-10-18 12:58:02宋慧慧张开华
计算机应用 2020年10期
姚 鲁,宋慧慧,张开华
(1.江苏省大数据分析技术重点实验室(南京信息工程大学),南京 210044;2.南京信息工程大学大气环境与装备技术协同创新中心,南京 210044)
(*通信作者电子邮箱songhuihui@nuist.edu.cn)
0 引言
近年来,随着深度学习的重大发展,图像超分辨率重建领域得到广泛关注。单幅图像超分辨率(Single Image Super-Resolution,SISR)任务是个不适定的(ill-posed)逆问题,旨在从低分辨率(Low-Resolution,LR)图像中恢复出高分辨率(High-Resolution,HR)图像。目前主要算法是基于学习的将LR 图像经过非线性映射得到HR 图像[1]。以下简要回顾与本文相关的基于卷积神经网络的(Convolution Neural Network,CNN)超分辨率算法和通道注意力机制。
Dong 等[2]首先将CNN 引入图像超分辨率重建领域,提出基于卷积神经网络的超分辨率(Super-Resolution using CNN,SRCNN)。残差网络[3]解决了网络深度和模型退化之间的矛盾,使超分辨率网络逐渐往更深更宽方向发展。Kim等[4]提出了使用非常深的卷积网络构建准确的图像超分辨率(accurate image Super-Resolution using Very Deep convolutional networks,VDSR)。此网络深度达20层,采用残差网络和梯度裁剪解决梯度爆炸问题。Zhang 等[5]提出了非常深的残差通道注意力超分辨率(image super-resolution using very deep Residual Channel Attention Network,RCAN)算法。此算法以残差网络为基础构建了深度达400层的网络。
人类感知的关注通常指人类视觉系统能自适应处理视觉信息关注于显著区域[6]。近年来,学者已提出将多种注意力处理算法嵌入CNN 用于各种任务。Hu 等[7]提出压缩和扩张网络(Squeeze-and-Excitation Network,SENet)利用通道间相互关系提升分类性能;Zhang 等[5]提出全局平均池化(Global Average Pooling,GAP)构建的一阶通道注意力以自适应缩放通道间特征;Dai等[8]提出采用二阶通道注意力网络的图像超分辨率(Second-order Attention Network single image superresolution,SAN),采用二阶通道注意力模块解决之前超分辨率算法忽视对于CNN 内部层特征相互关系的研究,主要利用二阶统计特征构成的全局协方差池化(Global Covariance Pooling,GCP)自适应缩放通道间特征进行特征表达和特征相互性学习。
深度网络在图像超分辨率性能上取得重大提升,而现有SISR 算法对于通道间特征的研究算法只考虑一阶通道信息(RCAN)或二阶通道统计信息(SAN),并没有将一、二阶通道信息进行优势互补。此外,已有通道注意力算法采用升降维破坏了每个通道和其权重的直接对应关系,不利于通道间特征相互性学习,影响网络性能的提高。
因此,本文提出一种混合阶通道注意力网络的单幅图像超分辨率重建(Mixed-order Channel Attention Network for single image super-resolution reconstruction,MCAN)进行更强大的特征表达和相互性学习。本文的工作总结如下:
1)针对先前不同阶通道注意力破坏权重预测与通道不对应问题,本文首先改进先前一、二阶通道注意力模型,提出有效一阶通道注意力(Efficient First-order Channel Attention,EFCA)模型和有效二阶通道注意力(Efficient Second-order Channel Attention,ESCA)模型,这样能对应预测通道权重,使得特征加权更合理,具体可见1.2.1节和1.2.2节。
2)针对之前一、二阶通道注意力模型没有综合考虑将不同阶通道注意力优势互补的问题,本文将改进后的一、二阶模型融入残差网络构成基本组件混合阶残差通道注意力组(Mixed-order Residual Attention Group,MRAG),具体可见1.3节。
在一系列测试数据集上结果表明,与SRCNN[2]、RCAN[5]、SAN[8]等相比,本文算法无论在客观评价标准还是主观视觉效果上结果都更好,具体可见2.2.2节。
1 本文算法MCAN
本文算法采用生成对抗网络,生成器如图1~2 所示,包括4 个部分:1)浅层特征提取网络;2)共享资源的混合阶残差注意力网络(Shared-resource Mixed-order Residual Attention Group,SMRAG);3)上采样模块;4)重建模块。判别器结构如图3。
1.1 生成器
本文算法首先使用一个卷积从输入的低分辨率图像ILR提取浅层特征,可表示为:

其中:F0表示卷积后的浅层特征;HSF()表示卷积操作。再将浅层特征输入SMRAG网络以提取深层特征,增强网络非线性表达能力,可表示为:

其中:FDF表示深层特征;HSMRAG()表示提取深度特征模块SMRAG,由G个混合阶残差注意力组MRAG 组成。再将提取到的深层特征进行上采样,可表示为:

其中:H↑()是上采样操作;F↑是上采样后特征。本文上采样算法采用亚像素卷积[9]。最后上采样后特征经过一个卷积映射到放大4倍的重建后图像,此过程可表示为:
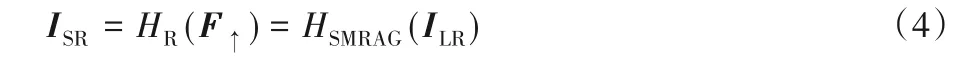
其中:HR()表示重建模块;ISR表示重建后图像。
1.2 共享资源的混合阶残差注意力网络SMRAG
如图1 虚线部分即为所提出的共享资源的混合阶残差注意力网络SMRAG,由G个混合阶残差通道注意力组MRAG(图2(a))和一个最长范围共享资源的跳跃连接(Shared-Source skip Connection,SSC)结构组成。每个MRAG 包括M个有效一阶残差注意力模型(EFCA)、一个中等长度的跳跃连接结构以及一个二阶通道注意力模型(ESCA)。此二阶模型使得网络更关注于信息量大的特征,增强了网络判别能力[8],提升了图像恢复质量。
简单重复堆叠残差网络虽然能构建非常深的网络,但由于梯度消失和爆炸问题导致训练困难和性能瓶颈,因此本文使用MRAG模块作为基本单元。而重复堆叠MRAG网络不能取得更好的性能,本文又引入最长范围共享资源的跳跃连接结构(SSC)。这样不仅能促进深层网络的训练,还能将LR 图像信息逐层向后传递大量低频信息,减少信息丢失。SMRAG网络中的第g个MRAG可表示为:

对每个MRAG 模型,首先将改进后的一阶模型EFCA 模型嵌入残差块,构建改进后一阶残差注意力(Efficient Firstorder Residual Attention,EFRA)模块,多个(M个)EFRA 级联和最后的二阶通道注意力模型(ESCA)构成MRAG。最后以MRAG 为基本单元构成SMARG 模型。SMRAG 模型利用改进后的一、二阶通道模型EFCA 和ESCA 使得通道权重预测与每个通道直接对应,权重预测更准确合理,网络判别能力得以提高;同时混合使用不同阶通道注意力以进行优势互补,这样使得重建后图像纹理细节得到更好的恢复。
1.2.1 有效一阶通道注意力模型(EFCA)
如图2(b),对于每个EFCA 模型,前一层输出特征z首先经过全局平均池化HGAP(),再经大小为k的一维卷积WC,最后再将sigmoid 函数所产生的权重向量和此模块输入的每个特征通道做点乘。和RCAN 中的通道注意力所不同的是,这里的通道特征在经过全局平均池化后,直接经过参数为k的一维卷积[10],而不是原来的二维卷积升降维,这避免了权重向量与通道特征不直接对应问题,使得通道注意力预测更准确。权重可表示为:

其中:σ()是sigmoid函数;WC是一维卷积。
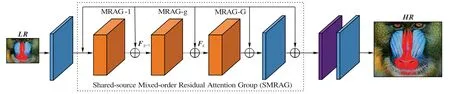
图1 生成器框架Fig.1 Framework of generator
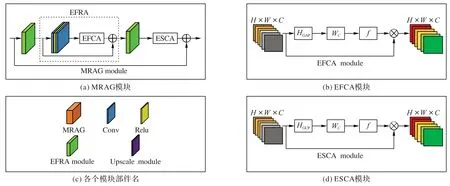
图2 生成器的子图Fig.2 Submodules of generator
1.2.2 二阶通道注意力模型(ESCA)
如图2(d),与以上EFCA 相比,本文二阶模型采用全局协方差池化HGCP()而非全局平均池化HGAP(),其余均相同。受Dai等[8]启发,本文采用全局协方差池化以增强网络判别能力的学习。以下阐明此模型如何利用二阶信息。
协方差归一化:
对于H×W×C特征图F=[f1,f2,…,fC],首先改变其维度,得到S=W×H,C维特征。则样本协方差矩阵可表示为:

其中:I、1 分别是S×S的单位矩阵和数字1 的矩阵。之后再对协方差矩阵进行归一化。由于协方差矩阵Σ是半正定矩阵,有如下特征值分解:

其中:U是正定矩阵;Λ=diag(λ1,λ2,…,λC)是对角阵。则协方差归一化可转化为特征值的幂运算,即

其中:α是正实数,本文中α取1/2。则

全局协方差之后是核为k的快速一维卷积WC。之前的一阶模型采用升降维操作,本文改为一维卷积实现。原本的升降维破坏了每个通道与其对应权重之间的直接对应关系,且利用这种方式的通道注意力也不高效。因此本文采用局部跨通道交互作用策略预测通道权重,即改为核为k一维卷积。这不仅让通道注意力预测更直接,且是局部作用,计算也更高效。具体来说此二阶模型对于每个通道考虑其相邻的k个通道以捕捉局部跨通道的相互作用。k即局部跨通道的范围,即有多少相邻通道参与一个通道注意力预测,显然k会影响模型效率。由于相互作用范围与通道数有关,本文设计核大小由自适应通道函数φ()决定,即

其中:|y|odd是最接近y的奇数。这种改变避免升降维,使得通道注意力预测更高效合理
最后,将sigmoid()函数产生的权重向量和原始输入特征做点乘。通过2.2.1 节消融实验部分可以看出,改进后的直接对应式权重预测方式比之前升降维方式对于感知效果提升确实有一定效果。
1.3 判别器网络结构
训练判别器以区分真实图像GT(Ground Truth)和生成的超分辨率(Super-Resolution,SR)图像。如图3,首先,将GT或SR送入4 个基本模块构成的判别器。每个模块包含两组卷积、批归一化和Leady ReLU 激活函数。这4 个模块通道数逐级递增,分别是64、128、256 和512。最后利用两个全连接层构成的二分类器判断网络输入图像的真假。

图3 判别器框架Fig.3 Framework of discriminator
1.4 损失函数
按照Vu等[11]设计,生成器和判别器分别以各自目标函数LG、LD进行迭代更新训练。
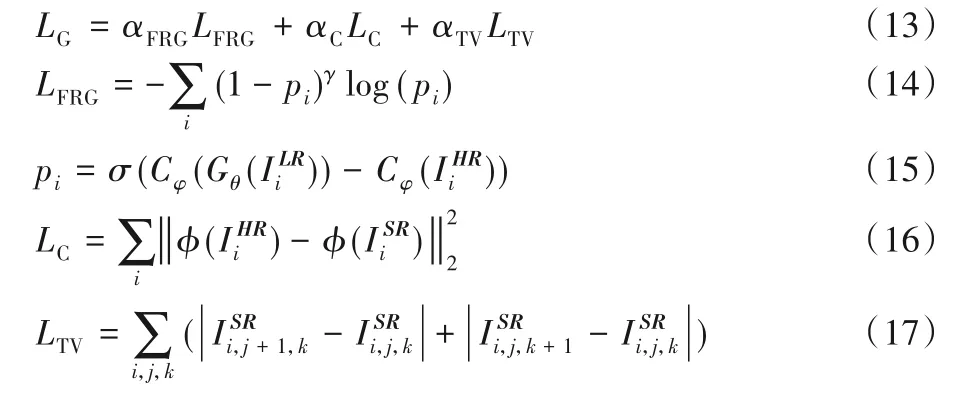
其中:LFRG是结合焦点损失(focal loss)的相对生成对抗网络(Generative Adversarial Network,GAN)损失;LC是内容损失;LTV是总方差损失;αFRG、αC、αTV是每个子函数对应权重。
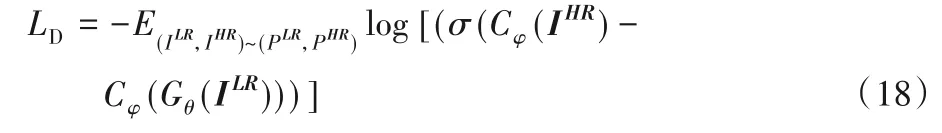
2 实验与分析
2.1 数据集
本文算法在DIV2K[12]数据集上训练。此数据集包括800个训练图像、100 个验证图像和100 个测试图像。测试采用6个基准测试集Set5、Set14、BSD100(Berkeley Segmentation Dataset)、Urban100、DIV2K 验证集(DIVerse 2K resolution image dataset)和PIRM(Perceptual Image Restoration and Manipulation)自验证集。定量评估模型采用Blau 等[13]提出的感知质量评估标准。
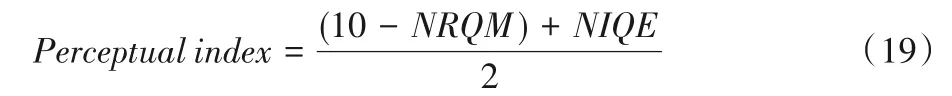
其中:NRQM是非参考质量评估方法(Non-Reference Quality assessment Method)[14]的评估指标;NIQE是自然图像质量评估器(Natural Image Quality Evaluator)[15]的评估指标。
1)数据集和预处理。
实验首先对真实图像双三次下采样4 倍,再减去DIV2K的RGB 均值预处理所有图像。最后对训练集进行随机旋转90°、180°、270°和水平翻转的数据增强。本模型也用于放大2倍、3 倍情形,需调整卷积核个数,本文只针对更具有挑战性的4倍情景。
2)训练设置。
实验时,为提高计算效率,每个小批中将16 个低、高分辨图像分别裁剪为48× 48和196 × 196的小块。为控制变量以便和相对生成对抗网络的感知增强图像超分辨(Perception-Enhanced image Super-Resolution via relativistic generative adversarial networks,PESR)算法[11]公平比较,设置MRAG 数量G=4,M=8。EFCA、ESCA 模型之外卷积和通道数设置为3× 3和256。
2.2 实验设置
本文算法采用Adam 优化器,设置动量β1=0.9,β2=0.999。批量大小为16。L1 损失初始化生成器迭代2 × 105次,再用全损失函数式(13)、(18)交替优化生成器和判别器2 × 105次。损失函数权重参数设置为αFRG=1,αC=50,αTV=10-6。
预训练学习率初始化为10-4;GAN 训练学习率初始化为5×10-5,每1.2×105次批更新后减半,采用Pytorch 框架,使用一块Nvidia 2080 Ti训练30 h左右,少于RCAN和SAN所需约7 d训练时间。
2.2.1 消融实验
为探究将通道注意力升降维改为一维卷积以及混合不同阶通道注意力对MCAN 影响,以下采用升降维一阶通道注意力模型(RCAN)、二阶模型(SAN)与本文快速一维卷积实现的一阶模型(EFCA)、二阶模型(ESCA)分别在BSD100 数据集上做对比实验。为保持参数一致,设置G=4,M=8,结果如表1所示,评价指标为感知指数(Perceptual Index,PI),PI 值越小越好。①和②是训练时分别采用升降维的一、二阶模型,③和④是分别采用改进后一、二阶模型EFCA、ESCA。①和③,②和④对比表明,将一阶或二阶通道注意力由升降维改为一维卷积,通道预测权重和每个通道特征一一对应,注意力预测更准确;⑤和⑥对比表明,改进后一阶(EFCA)二阶(ESCA)通道模型融入残差块混合使用相比单独采用一阶或二阶模型性能更好。这表明采用改进的通道注意力模型不仅权重预测更准确合理,更关注于信息量大的特征,还提高了网络判别性学习能力,故比其他算法结果更优。
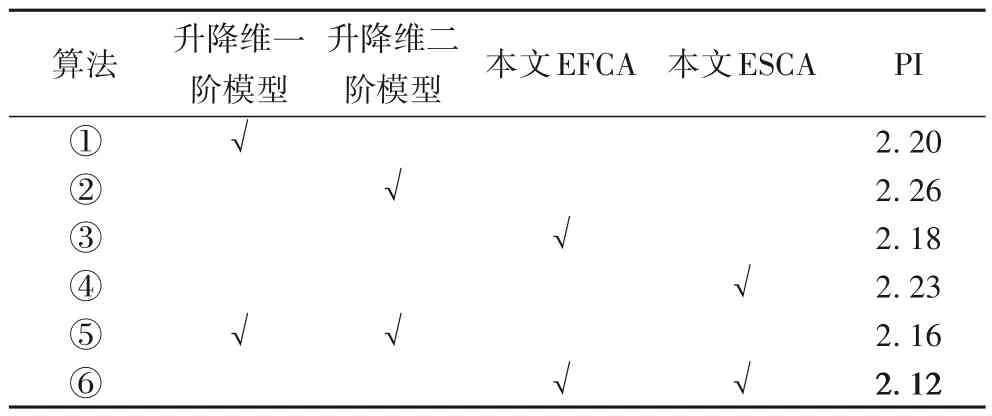
表1 BSD100数据集上不同通道注意力模型的对比实验Tab.1 Comparative experiments of different channel attention models on BSD100 dataset
2.2.2 和其他算法相比
本文算法MCAN 与现有超分辨率算法Bicucic[16]、SRCNN[2]、增强深度残差网络的单幅图像超分辨(Enhanced Deep residual networks for single image Super-Resolution,EDSR)[17]、RCAN[5]、SAN[8]、生成对抗网络的单幅逼真图像超分辨率(photo-realistic single image Super-Resolution using a GAN,SRGAN)[18]算法、自动纹理合成实现的单幅图像超分辨率(Enhancenet: single image super-resolution through automated texture synthesis,ENET)[19]以及PESR[11]相比,利用峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)和感知指数PI对放大4 倍重建结果进行评估,结果如表2 和图4。从表2 可以看出,MCAN 在Set5、Set14 等数据集上PI 均超过其他超分辨率算法;且从图4(j)可以看出,相较于图4(i)等其他算法,本文算法恢复出的图像总体效果如杂草和木桥纹理更清晰直观。这表明直接进行通道注意力预测以及二阶统计信息的利用能增强网络判别性能力的学习,提升网络性能。
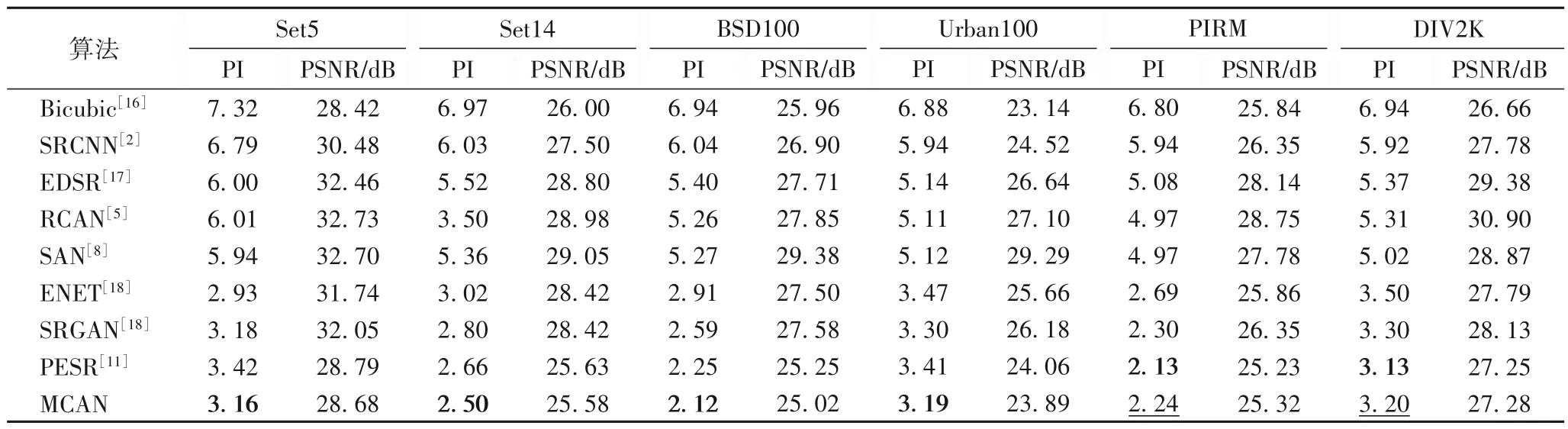
表2 放大4倍时不同算法在基准测试集上的比较Tab.2 Comparison of different methods on benchmark test sets at 4x magnification

图4 不同算法定性比较(PI/PSNR)Fig.4 Qualitative comparison of different methods(PI/PSNR)
3 结语
本文提出混合阶通道注意力网络的单幅图像超分辨率算法以增强网络判别能力恢复出高分辨率图像。首先网络去除先前一、二阶通道注意力模型升降维改为一维卷积,使得通道注意力预测更直接准确且简单;再结合一、二阶通道注意力特别是二阶统计信息,以增强网络判别性学习能力使得重建后图像具有更多纹理细节。与其他算法相比,本文算法不论是客观评价标准还是主观感觉都有所提高,重建出图像具有更高的质量且能显示更精细的纹理。下一步打算添加一些符合原图的先验信息,使得恢复出的图像更接近真实图像。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
应用数学(2020年2期)2020-06-24 06:02:46
自动化学报(2019年6期)2019-07-23 01:18:32
数学物理学报(2019年3期)2019-07-23 01:15:40
数学物理学报(2018年6期)2019-01-28 08:58:02
中央民族大学学报(自然科学版)(2018年3期)2018-11-09 01:16:34
家庭影院技术(2018年9期)2018-11-02 05:31:32
Acta Mathematica Scientia(English Series)(2018年6期)2018-03-01 03:13:44
自动化学报(2017年5期)2017-05-14 06:20:52
