
结合感知边缘约束与多尺度融合网络的图像超分辨率重建方法
2020-10-18 12:58欧阳宁林乐平
计算机应用 2020年10期
欧阳宁,韦 羽,林乐平*
(1.认知无线电与信息处理省部共建教育部重点实验室(桂林电子科技大学),广西桂林 541004;2.桂林电子科技大学信息与通信学院,广西桂林 541004)
(*通信作者电子邮箱lin_leping@163.com)
0 引言
单幅图超分辨率(Super-Resolution,SR)重建[1]是一个不适定的逆问题,旨在从低分辨率(Low-Resolution,LR)图像中恢复出高分辨率(High-Resolution,HR)图像。近年来,卷积神经网络(Convolutional Neural Network,CNN)在各种计算机视觉领域如目标检测[2]、图像识别[3]、图像分割[4]取得的重大突破已经影响到超分辨率重建领域[5-10]。Dong 等[5]首次将卷积神经网络引入超分辨率重建领域,提出了基于卷积神经网络的超分辨率(Super-Resolution using CNN,SRCNN)重建方法。该方法通过端到端的方式学习LR 到HR 之间的非线性映射,是目前典型的基于CNN 的超分辨率重建方法;Kim 等[6]在用于大规模图像识别的深度卷积神经网络[3]的启发下,提出了一种基于深度卷积神经网络的精确图像超分辨率(accurate image Super-Resolution using Very Deep convolutional neural networks,VDSR)重建方法。该方法通过增加网络深度的方式扩大网络的感受野,使网络可以提取更为高级的特征,同时采用残差学习以及增加学习率的策略缓解梯度消失问题;Ren 等[7]根据集成学习的思想,提出了融合多个神经网络用于图像的超分辨率(image super resolution based on Fusing multiple Convolution neural Networks,CNF)重建方法。该方法利用多个不同深度的网络提取不同的上下文信息,由于不同深度网络提取的特征不同,融合多个支路的上下文信息后可以有效增强特征表达能力,从而提升网络重建精度;Lai 等[8]在图像金字塔的启发下提出了深度拉普拉斯网络用于实现快速准确的超分辨率(deep Laplacian pyramid Networks for fast and accurate Super-Resolution,LapSRN)重建方法。该方法构建了一种金字塔型网络结构,从粗到细逐步学习图像高频细节的残差映射,大大降低了模型的复杂度以及学习难度;同样基于由粗到细的思想,欧阳宁等[9]提出基于自注意融合网络的图像超分辨率(Self-Attention Network for image Super-Resolution,SASR-Net)重建方法。该方法首先通过CNN 初步重建高分辨率(HR)图像,然后通过自注意力模块捕捉初步重建图像的全局依赖,进一步地恢复图像高频细节。另外,为了获得视觉上更为逼真的重建图像,Ledig等[10]提出了使用生成式对抗网络的真实感单幅图像超分辨率(photo-realistic single image Super-Resolution using a Generative Adversarial Network,SRGAN)重建方法,将鉴别网络作为一种图像先验引入超分辨率重建领域,以对抗的方式优化生成网络和鉴别网络,促使生成网络获得更好的去模糊效果。
图像的多尺度表达被广泛应用于计算机视觉任务的分析建模中,对计算机视觉任务具有重要意义。与传统的多尺度表达不同,卷积神经网络中的多尺度表达主要为特征金字塔。该表达通过连续的卷积和下采样操作获得一系列感受野大小不同以及尺度不同的特征图,从而可以具备局部至全局的上下文信息。在超分辨率重建领域中,充分地利用图像上下文信息十分重要,融合图像局部至全局的上下文信息往往能够有效增加特征描述的准确性以及增强特征表达能力。比如CNF 方法通过融合多个网络的上下文信息增加特征表达能力,取得了良好效果。但受到目前主流的单阶段重建方式的影响,目前的超分辨率重建方法主要以先提取低分辨率(LR)图像特征再上采样的方式重建图像。由于输入LR 图像尺寸较小,难以进行特征的多尺度表达,为了增加网络感受野,该方式往往需要将网络堆叠得较深,因而,该方式容易导致模型复杂度较高且不能充分利用图像的多尺度上下文信息。另外,目前优化模型的损失函数中,使用L1和L2损失优化模型容易导致重建的图像边缘较为平滑,难以获得一个良好的视觉体验效果,虽然SRGAN 方法重建的高分辨率图像能够获得较好的视觉体验效果,但是该方法引入的判别模型不能精确地针对纹理和边缘进行优化,导致重建的图像中存在一定的高频噪声。
基于以上问题,本文提出了结合感知边缘约束与多尺度融合网络的图像超分辨率重建方法(image Super-Resolution reconstruction method combining Perceptual Edge Constraint and Multi-Scale fusion Network,MSSR-Net-PEC)。首先,针对目前的超分辨率重建方法不能充分提取和利用图像多尺度特征问题,本文受到SASR-Net以及LapSRN 多阶段重建的启发,设计了一个两阶段网络。该网络先通过第一阶段CNN 初步提取和上采样图像特征,避免了特征尺寸过小不能进行多尺度表达问题;然后再通过特征金字塔模块完成多尺度特征的提取以及多尺度特征的融合,从而充分利用图像的多尺度上下文信息来精细化第一阶段网络输出特征,增加特征表达能力。其中:第一阶段由卷积层、残差组C1,以及上采样操作组成,负责初步提取和上采样图像特征;第二阶段网络由多个残差组、下采样操作以及多个注意力融合模块组成,该网络先通过残差组和下采样操作捕捉图像的多尺度特征,再通过自底向上的逐步融合方式融合图像的多尺度特征,从而有效利用图像多尺度上下文信息,增加特征描述的准确性。在第二阶段中,考虑到不同尺度不同通道的特征重要性差异,本文在通道注意力的启发下,利用通道注意力捕捉不同尺度特征的通道权重,并通过该权重完成不同尺度特征的融合,以更有效融合不同尺度特征。其次,针对目前的损失不能良好地恢复图像高频细节问题,本文尝试在L1损失的基础上引入更丰富的卷积特征用于边缘检测(Richer Convolutional Features for edge detection,RCF)方法[11]作为感知边缘约束。其中,该边缘检测方法的边缘检测精度已经超越数据集本身人工标注平均值,能够精确地检测和识别图像边缘,受到感知损失中利用网络特征计算损失的启发,本文用该方法的特征提取网络的输出特征计算特征损失LD,以精确地针对图像的边缘进行优化,恢复图像高频信息。实验结果表明,本文的方法与SRCNN[5]、VDSR[6]、LapSRN[8]、SASR-Net[9]等相比较,在客观评价标准和主管视觉效果上都优于这些超分辨率重建算法。
1 本文方法
本文基于由粗到细的思想,设计了两阶段网络:第一阶段主要负责提取图像特征;第二阶段负责提取和融合图像多尺度特征,捕捉全局上下文依赖,以精细第一阶段特征。如图1所示。第一阶段以原始低分辨率图像作为输入,通过CNN 完成特征的提取以及上采样操作。第二阶段以第一阶段的输出作为特征金字塔模块的输入,提取和融合多尺度上下文信息。
第一阶段中,CNN 由卷积层、残差组C1 和上采样单元组成。其中,残差组如图1 中的残差组虚线框所示,该模块由N个残差单元依次堆叠而成,第N-1个残差单元的输入为第N-2个残差单元的输出,第N-1个残差单元输出为第N个残差单元的输入。在第一阶段网络中,残差组C1 的残差单元数量N为10,上采样方法为亚像素上采样[12]。
受到特征金字塔网络(Feature Pyramid Network,FPN)2]和LapSRN[8]的启发,本文设计了特征金字塔模块作为第二阶段网络。该模块以第一阶段输出为输入,先通过连续的卷积和下采样操作获得不同尺度的特征表达,再通过自底向上的注意力融合模块逐步融合不同尺度特征。其中该模块的卷积部分由多个残差组组成,下采样操作则通过步长为2的3×3卷积层来完成。
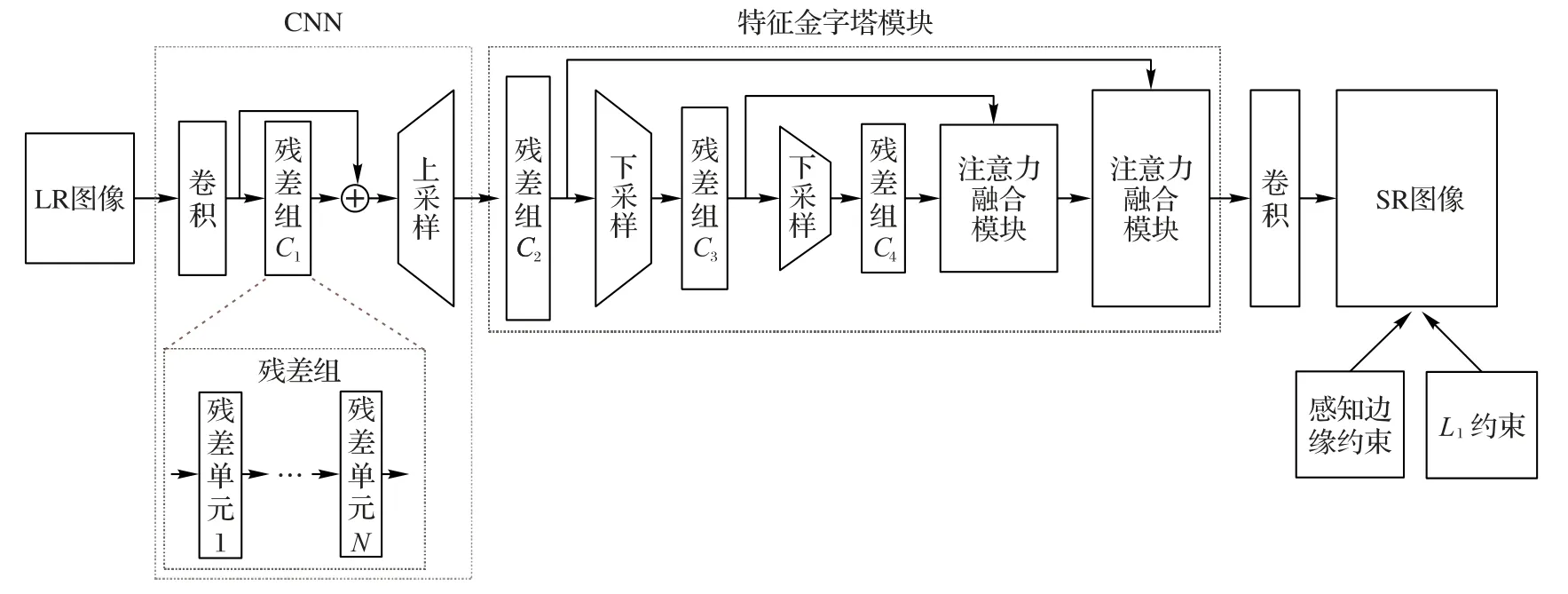
图1 网络结构Fig.1 Network structure
为了更有效且更精准地重建图像高频细节,本文在L1损失的基础上引入RCF方法作为感知边缘约束。RCF方法在边缘检测任务中表现优异,能够精确检测图像边缘,因此,将其引入作为图像感知边缘约束,能够有效地针对图像的边缘进行优化,从而更逼近目标函数全局最优点。本文对RCF 方法的特征提取网络中conv2-2 卷积层输出的第2 个通道特征图进行了可视化,如图2 所示,特征图中包含了丰富的高频细节信息。相对于以最终输出的单张边缘概率图计算损失,在特征层次计算损失能够更为充分地利用图像信息,因此,本文使用该方法特征提取网络中第三阶段卷积层输出计算特征损失LD,并与L1损失结合,进一步约束解空间。

图2 RCF网络特征可视化结果Fig.2 RCF network feature visualization result
本文算法如算法1 所示,其中:iteration 表示当前迭代次数,max-iteration代表最大迭代次数。
算法1 超分辨率重建算法优化。


2 特征金字塔模块设计
特征金字塔模块主要由多尺度特征提取支路和多尺度特征融合支路组成,旨在提取和融合多尺度上下文信息,更好地重建图像边缘和纹理。
2.1 特征金字塔模块
如何有效恢复图像的边缘和纹理是超分辨率重建中至关重要的问题,其中的关键点之一在于如何有效地捕捉全局上下文依赖。但在实际的研究过程中,为了能够有效捕捉全局上下文依赖,网络模型通常被设计得过于复杂。针对这个问题,本文设计了特征金字塔模块。其中,该模块具有以下几个优点:1)扩大网络感受野的同时不需要增加过多的网络参数,使得网络具备不同尺度的图像特征;2)提取和融合不同尺度特征,有效捕捉全局上下文依赖;3)多尺度特征融合过程中,通过通道注意力捕捉不同尺度特征的权重大小,更有效地融合不同尺度特征;4)多尺度特征融合过程中,采用逐步上采样融合方式,能够实现更为精细的图像重建。因此,特征金字塔模块的引入有望更好地恢复图像的边缘和纹理。
特征金字塔模块结构如图1 所示。该模块由两部分组成:第一部分由多个残差组和下采样单元组成,负责提取图像的多尺度特征。由于过多丢失图像细节信息不利于图像的重建,本文只提取3 个尺度的上下文特征。其中,残差组C1、C2、C3 的残差单元数量N分别为2、3、5。第二部分由两个注意力融合模块组成,该部分通过注意力融合模块自底向上逐步融合多个尺度特征,完成多尺度特征的融合。
2.2 注意力融合模块
鉴于不同的尺度的特征可能具有不同的重要性[13],本文引入通道注意力机制[14]以生成可训练的权重进行特征融合。注意力融合模块如图3所示。
假设Fc和Fk分别代表两个相邻的不同尺度特征,分别被送入到注意力融合模块的两个支路,下方支路首先将Fk特征图通过亚像素上采样2 倍至Fc大小,紧接着上下两个支路分别经过卷积和通道注意力模块后加权,得到融合后的特征F′。
假设第i个通道中两个不同尺度的特征分别为,对应生成的注意力权重为,文中的注意力融合模块可以被表示为:

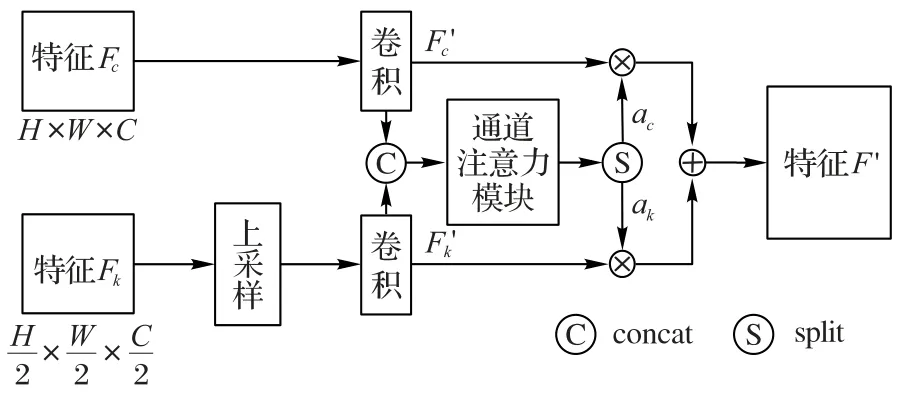
图3 注意力融合模块Fig.3 Attention fusion module
3 感知边缘约束
近年来基于卷积神经网络的边缘检测方法在边缘检测领域取得了重大突破[11],精度已经超越数据集本身人工标注平均值。相较于Canny 算子[15],基于CNN 的边缘检测方法能够精准识别和定位图像边缘。RCF方法作为其中最具代表性的算法之一,在BSDS500 测试集上最佳数据集规模ODS(Optimal Dataset Scale)值达到了0.811,而与之相比,Canny算子在该数据集上的测试结果ODS 值仅达到了0.611,远远低于RCF 方法,表明了RCF 方法能够更为精准地检测图像边缘。考虑到L1和L2损失不能很好恢复图像的边缘和纹理,本文引入RCF 方法作为感知边缘约束以更好地恢复图像的高频细节。
RCF方法于2017年由Liu等[11]提出,边缘检测结果如图4所示。该方法所设计的特征提取网络在VGG(Visual Geometry Group)提出的VGG16 的基础上进行了以下几个调整:1)将VGG16 网络的全连接层以及最后一个池化层去除;2)将第四阶段的池化层步长改为1;3)将第五阶段的三个卷积改为扩张率为2 的空洞卷积。由于该特征提取网络应用于边缘检测任务,能够提取丰富的边缘特征,因此本文将其作为感知边缘约束以更好地恢复图像边缘。
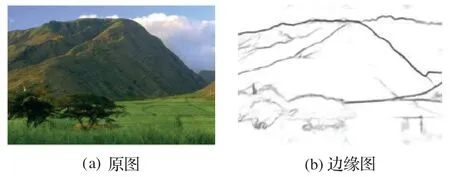
图4 RCF方法的边缘检测结果Fig.4 Edge detection result of RCF method
在具体的实施过程中,本文借鉴感知损失的做法,使用其中的特征提取网络的某卷积层输出计算特征损失。其中,该网络中第二阶段的第二个卷积层conv2-2 输出的第2 通道特征图可视化结果如图2 所示,可以看到,该网络具备优秀的边缘和纹理特征提取能力。考虑到该特征提取网络中浅层提取的边缘特征语义信息较少,深层提取的边缘特征定位不精准,文中使用该特征提取网络的第三阶段的所有卷积层输出特征计算L2损失,同时,由于本文仅使用第三阶段卷积输出特征计算特征损失,本文将RCF 网络其他的部分全部去除,仅保留特征提取网络的前三个阶段网络。训练时,本文通过自己训练的预训练模型进行模型初始化。假设φ表示为RCF[11]网络中的特征提取网络映射,本文的感知边缘约束具体可以表示为:

4 实验与结果分析
本文实验使用的DIV2K 训练集[16]是一个高质量数据集。DIV2K 数据集由800 个训练图像、100 个验证图像和100 个测试图像组成。文中在训练过程中随机地将低分辨率图像裁剪为32×32 大小的子图像,并通过水平、垂直翻转和旋转对数据进行扩充。测试集则由Set5、Set14 和BSDS100 组成,分别有5、14、100张图片。
本文实验过程中使用两种损失训练网络:第一种为L1损失;第二种为感知边缘约束和L1损失的结合体——联合损失。其中,联合损失函数L可表示为:

本文在模型训练过程中采用双阶段训练法,先训练第一阶段网络,待其接近收敛再训练整体网络。在使用联合损失训练时,在已训练好的网络上进行微调,β参数设置为0.001,该参数通过4.1 节中的多组实验分析进行确定。本文网络模型基于pytorch 框架进行搭建。训练过程中优化器选择Adam。初始学习率设置为1E-05,每迭代60 个周期学习率衰减50%,最大迭代周期为400 epoch。网络训练平台为双显卡的P104 6 GB的计算机。
4.1 感知边缘约束权重对模型的影响分析
为了探索感知边缘约束(Perceptual Edge Constraint,PEC)权重大小对模型的影响,本文以第一阶段网络SR-Net作为基础网络,通过设置不同β值的联合损失训练网络。其中,以β值为0.1、0.01、0.001以及0.000 1的联合损失分别进行4组实验,并记录了每个实验最终损失收敛情况以及在Set5 数据集的峰值信噪比(Peak signal-to-noise Ratio,PSNR)测试情况,实验结果如表1和图5所示。

表1 4倍放大因子下不同β值训练的基础网络最终收敛损失大小以及在Set5中测试的PSNR值对比Tab.1 Final convergence loss and PSNR tested on Set5 by basic network trained with different β when magnification factor is 4
如表1 所示,β越大,L1损失越大,PSNR 和PEC 越低;反之,β越小,L1损失越小,PSNR和PEC越高,这表明PEC与L1损失在某种意义上是互相矛盾的。其中,当β为0.000 1时,PEC基本不收敛,与单独使用L1损失训练最终结果基本一致。而从重建的图像来看,如图5 的脸部图像所示,随着感知边缘约束权重的增大,图像头发部分的边缘清晰度先增强然后基本稳定,这表明感知边缘约束的引入能够一定程度地提升图像边缘部分的恢复效果。但与此同时,随着感知边缘约束的权重增大,图5 中脸部皮肤的纹理重建部分出现了明显的栅格现象,这表明感知边缘约束不能精确地重建图像纹理,存在一定的栅格现象,但该现象可以通过调整感知边缘约束权重进行减弱。如图5(c)所示,虽然重建的皮肤纹理处有细微的栅格现象,但该图像视觉效果相较于图5(b)中更清晰,因此,适当地引入感知边缘约束可以提升重建图像的视觉效果。

图5 不同β值训练的基础网络在Set5数据集上head图像的4倍重建结果对比Fig.5 Comparison of reconstruction results on head image of Set5 by basic network trained with different β(×4)
4.2 消融实验分析
为了探究各模块对本文方法(MSSR-Net)的影响,本文进行了消融实验。
首先,本文以基础网络SR-Net(Super Resolution Network)为基础,分别设计了两个不同深度的网络MSSR-Net-l 以及MSSR-Net-o。其中,MSSR-Net-l 的金字塔模块中残差组C2、C3、C4的残差单元数量N分别为1、2、2,MSSR-Net-o的金字塔模块中残差组C2、C3、C4 的残差单元数量N分别为2、3、5。两个网络统一去掉注意力融合模块,损失函数统一使用L1损失。
其次,为了探究注意力融合模块对模型的影响,本文在MSSR-Net-o 的基础上加入注意力融合模块,即网络MSSR-Net。
最后,为了探究感知边缘约束对本文模型的影响,本文使用联合损失对MSSR-Net 进行训练,即本文方法MSSR-Net-PEC。实验的结果如表2、图6~7所示。
从表2 和图6 可看出:SR-Net 的收敛最慢,且PSNR 值最低;随之往上,MSSR-Net-l、MSSR-Net-o 以及以及MSSR-Net 的收敛逐渐加快且PSNR 值逐步提升。说明了本文所提出的各模块能够有效提高模型性能。而在PSNR 值的比较中,MSSRNet-l 比SR-Net 提升了0.23 dB,MSSR-Net-o 比MSSR-Net-l 提升了0.1 dB,MSSR-Net 比MSSR-Net-o 提升了0.04 dB。表明了特征金字塔模块对模型的影响最大,其次为特征金字塔模块的深度,最后为注意力融合模块。另外,在图像的重建质量方面,如图7 所示,蝴蝶翅膀部分的纹理重建中,MSSR-Net 的边缘重建效果比SR-Net 要清晰一些且PSNR 值更高,这说明了本文方法的特征金字塔模块能够有效地捕捉全局上下文依赖。而使用联合损失比使用L1损失的PSNR 值降低了0.3 dB左右,但如图7 所示,使用联合损失重建的边缘更为清晰,可以重建出更多的高频细节,说明了加入感知边缘约束能够更有效地针对边缘纹理进行优化,可以重建出更为清晰的边缘。
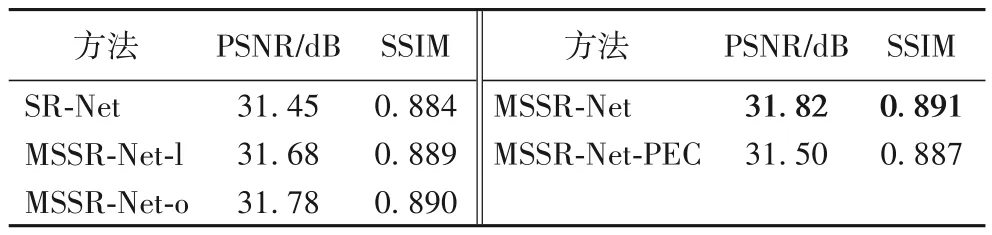
表2 消融实验在Set5上4倍的测试结果Tab.2 Test results of ablation experiment on Set5(×4)
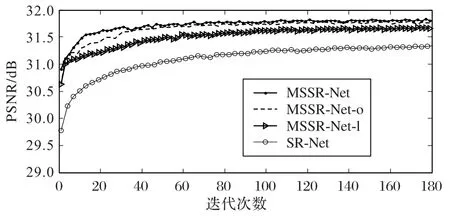
图6 消融实验在Set5上4倍训练结果Fig.6 Training results of ablation experiment on Set5(×4)

图7 不同超分辨率重建方法在Set5上butterfly的4倍重建结果比较Fig.7 Comparison of reconstruction results of different super-resolution reconstruction methods on butterfly of Set5(×4)
4.3 本文方法整体性能分析
将本文提出的MSSR-Net 以及MSSR-Net-PEC 与Bicubic[17]、SRCNN[4]、VDSR[6]、CNF[7]、LapSRN8]、SASR-Net[9]共6 种超分辨率重建方法分别从重建速度、图像质量指标以及图像重建视觉效果三方面进行详细比较。其中,MSSR-Net以及MSSR-Net-l与各方法在BSDS100 数据集上4 倍的重建速度如表3 所示,MSSR-Net 与各方法在不同放大倍数下的峰值信噪比以及结构相似度比较如表4 所示,MSSR-Net 和MSSRNet-PEC与各方法重建的图像视觉效果比较如图8~9所示。

图8 不同超分辨重建率方法在Set14上baboom 的3倍重建结果比较Fig.8 Comparison of reconstruction results of different super-resolution reconstruction methods on baboom of Set14(×3)
如表3 所示,由于本文需要对不同尺度的特征进行卷积操作,大幅增加了计算复杂度,所以本文方法的重建速度最慢。如表4 所示,MSSR-Net 在Set5、Set14 和BSDS100 数据集上的PSNR 和结构相似度(Structural SIMilarity index,SSIM)基本超过了其他超分辨率重建方法,尤其在3倍和4倍的放大因子中提升更为明显,虽然本文方法在2 倍放大因子时稍逊于SASR-Net 和CNF,但在较大放大因子上的表现更佳。如图8所示,本文方法MSSR-Net在毛发的边缘和纹理重建效果比其他方法更清晰,并且PSNR以及SSIM指标更高,表明特征金字塔模块能够更好地恢复图像纹理和边缘。如图9 所示,加入感知边缘约束后的MSSR-Net-PEC 方法在PSNR 以及SSIM 指标虽然有所降低,但该方法在图8和图9中毛发和头饰的边缘重建更为锐利,表明了本文所提出的感知边缘约束能够有效增强图像细节的恢复。
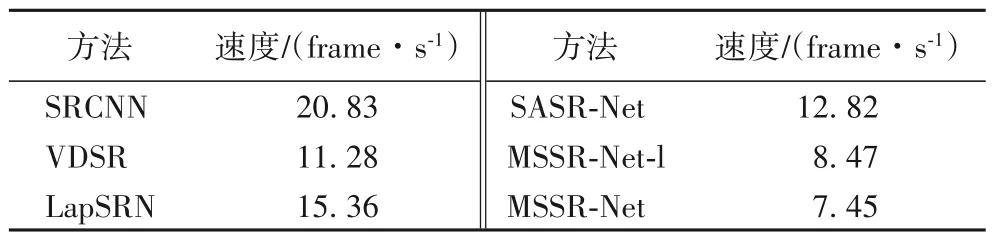
表3 各方法在BSDS100数据集上的4倍的重建速度对比Tab.3 Comparison of reconstruction speeds of different methods on BSDS100 dataset(×4)
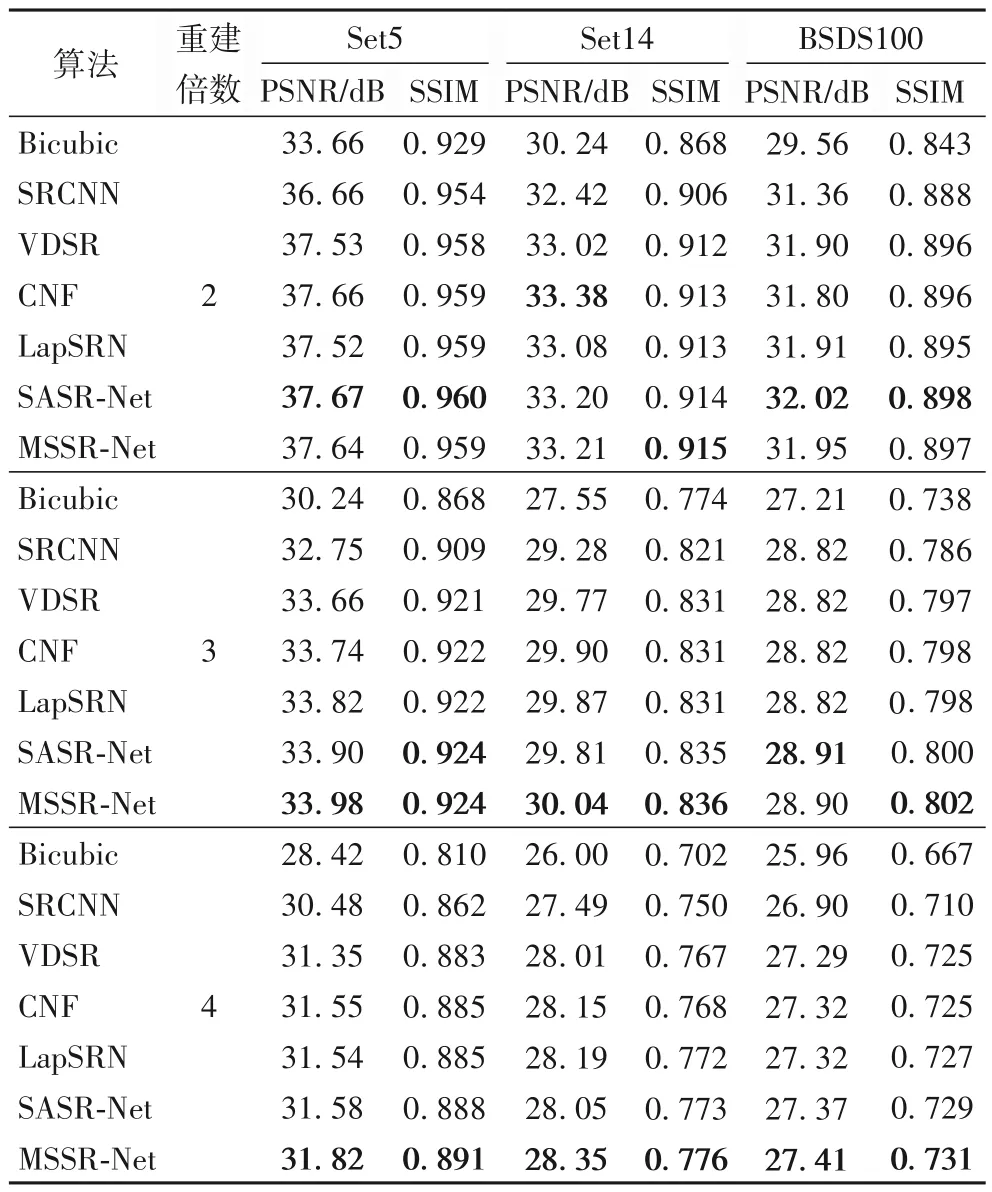
表4 使用不同超分辨率重建方法在Set5、Set14、BSDS100数据集上的测试结果Tab.4 Test results of different super-resolution reconstruction methods on Set5,Set14,BSDS100 datasets
因此,本文的特征金字塔模块针对大放大因子具有更好的重建效果但重建速度较慢,感知边缘约束的引入能够获得更为锐利的边缘但不能良好地恢复图像纹理,在图像的纹理处存在着细微的栅格现象。

图9 不同超分辨率重建方法在Set14上comic 的3倍重建结果比较Fig.9 Comparison of reconstruction results of different super-resolution reconstruction methods on comic of Set14(×3)
5 结语
本文提出了结合感知边缘约束与多尺度融合网络的图像超分辨率重建方法。该方法提出的特征金字塔模块能够充分地提取和融合图像的多尺度特征,有效地捕捉全局上下文依赖,在大放大因子时能够更好地重建图像边缘和纹理,但该模块存在着计算量较大的问题。另外,本文引入的感知边缘约束能够有效地针对边缘进行优化,获得更为锐利的边缘,但在纹理部分的重建存在一定的不足。本文下一步工作将针对以上两个问题进行进一步优化。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2020年10期)2020-11-14
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
北京航空航天大学学报(2019年9期)2019-10-26
通信产业报(2016年44期)2017-03-13
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
雕塑(2000年2期)2000-06-22
雕塑(1999年2期)1999-06-28
