
基于改进空间金字塔池化卷积神经网络的交通标志识别
2020-10-18 12:57邓天民周臻浩
计算机应用 2020年10期
邓天民,方 芳,周臻浩
(重庆交通大学交通运输学院,重庆 400074)
(*通信作者电子邮箱1336261072@qq.com)
0 引言
随着计算机、人工智能、深度神经网络等技术迅猛发展,自动驾驶已成为当今世界最热门的研究领域之一,而交通环境感知是自动驾驶技术的重要组成部分。交通标志的有效识别对交通环境的理解至关重要[1],对自动驾驶的路径规划、辅助定位与导航等环节起着决定性作用,同时为驾驶员和智能汽车提供超速预警、安全预警等自动辅助驾驶功能。
交通标志识别是针对检测的交通标志进行分类。在自然环境条件下的交通标志标牌,存在天气环境、光照条件、背景、遮挡、形变、视角等客观因素的干扰,严重影响交通标志识别的准确性。目前主流的交通标志识别算法识别率较高,但泛化性较差,难以满足实用性的要求[2]。因此,交通标志识别的泛化性、实时性等方面研究仍具有一定挑战性。
传统的交通标志识别方法通过提取或设计合适的特征,然后利用强判别力的分类器判别交通标志类型。对于特征提取,主要基于交通标志的颜色、形状、纹理等信息,分类器包括支持向量机(Support Vector Machine,SVM)、最近邻分类器、极限学习机等。Huang 等[3]和Gudigar[4]等提取交通标志的GiST(Generalized Search Tree)特征描述符,并分析了极限学习机和最近邻分类器的分类性能,极限学习机准确率超过99%,但耗时接近2 ms,实时性较差。单一方法提取的特征有限,可以采用多特征融合方法进行交通标志特征的提取。如赵宏伟等[5]将颜色空间HSV(Hue,Saturation,Value)特征和形状描述ART(Angular Redial Transform)特征融合,提出了交通标志图像检索方法;梁敏健等[6]提出了基于方向梯度直方图(Histogram of Oriented Gridient,HOG)和Gabor 的融合特征与Softmax 的识别算法;刘亚辰等[7]提出了基于融合式空间塔式算子和直方图交叉核支持向量机分类算法;韩习习等[8]、王斌等[9]将颜色特征、方向梯度直方图和局部二值特征等融合,利用SVM进行交通标志分类,提高了识别率。
传统的交通标志识别方法提取的是低级特征,所以识别模型精度较低,泛化性和实时性差。通过深度学习网络学习更高维、抽象的特征,结合不同的低级特征,通过Sotfmax 等分类器进行分类,识别性能显著提高。深度学习是机器学习极其重要的分支,相较于传统机器学习方法,深度学习的显著特征是拥有深层结构模型,即网络层数超过三层的神经网络,实质为将特征表示和学习合二为一。深度学习过程主要分为训练阶段和预测阶段,训练阶段利用大量样本数据对深度学习模型进行训练,调节模型参数使得目标函数最小化;预测阶段利用训练完成后的模型对数据进行预测。图像属于空间性分布数据,故主要利用卷积神经网络(Convolutional Neural Network,CNN)对图像的空间性分布进行分析。
Jin 等[10]采用了结合hinge loss 的CNN 进行分类,在德国交通标志识别数据集(German Traffic Sign Recognition Benchmark,GTSRB)上取得了比人类分类更好的准确率。Natarajan 等[11]改进CNN 的参数,利用加权多任务CNN 训练模型,精度超过99.6%,但结构复杂,实时性较差。Shao 等[12]和Cao等[13]在传统CNN的基础上,利用Gabor过滤器替代初始卷积核,并结合批量归一化(Batch Normalization,BN)方法,交通标志识别率较高,但识别速度有待提升。孙伟等[14]提出了多尺度卷积神经网络,引入不同池化层针对不同特征提取层提取特征以获取多尺度融合特征,提高了模型的识别精度和泛化性。
本文提出一种基于改进空间金字塔池化卷积神经网络的交通标志识别算法。首先进行图像预处理改善图像质量,利用图像去雾算法增强图像对比度;然后设计改进空间金字塔池化卷积神经网络(CNN with Spatial Pyramid Pooling and batch Normalization,SPPN-CNN)特征提取网络,提取融合特征作为交通标志图像特征;最后,利用Softmax 分类器实现对交通标志的识别。为了提高模型的泛化性,基于仿射变换预处理后的扩展GTSRB 数据集,并开展算法性能比选实验,确定了最佳的交通标志识别模型参数和结构。
1 基于改进SPPN-CNN的交通标志识别模型
交通标志识别系统由图像预处理、CNN特征提取、空间金字塔池化特征融合和分类器四部分组成,系统框架如图1 所示。首先,通过图像预处理方法提高交通标志图像质量,并增强数据集;然后,通过CNN 提取交通标志图像低级颜色、纹理、形状特征及高级语义特征,基于改进的空间金字塔池化网络进行特征融合;最后,将融合特征输入分类器中实现交通标志识别。
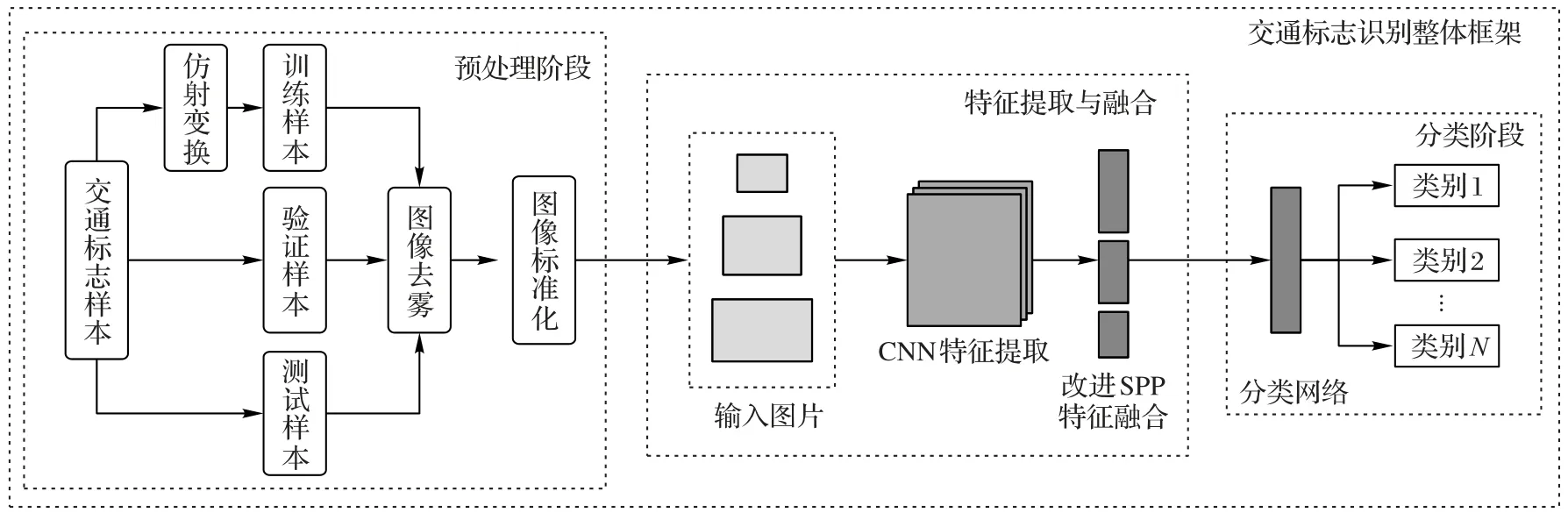
图1 交通标志识别系统整体框架Fig.1 Overall framework of traffic sign recognition system
1.1 交通标志图像处理
1.1.1 图像预处理
自然场景复杂多变,拍摄的实景交通标志图像存在树木与车辆遮挡、磨损等情况,同时天气(阴天、雾天、夜晚)、光照(光照强、光照弱)等影响图像采集质量,造成图像模糊、颜色失真等问题。通过图像处理方法可以改善交通标志图像质量,有利于交通标志图像的有效识别,预处理结果如图2所示。
1)图像归一化。
不同图像数据分布不同,利用图像归一化方法将消除图像数据间数量级差异,提高训练迭代速度,提高模型精度和泛化性。


图2 交通标志预处理示意图Fig.2 Preprocessing of traffic signs
2)图像灰度化。
图像灰度化将交通标志原始图像的RGB(Red,Green,Blue)三通道转换为单通道,有效减少了计算量,同时减弱光照的干扰。本文利用加权平均法将RGB 三通道IR、IG、IB以不同的权重转换为单通道灰度图像Igray,转化公式为:

1.1.2 图像去雾增强
由于光照、天气的影响,交通标志图像容易存在低对比度(模糊、黑暗)的情况。直方图均衡化可以有效增强图像的对比度。使用直方均衡化增强图像对比度,达到交通标志图像去雾效果,有效改善图像质量。直方均衡化主要包括三种方法:
1)全局直方图均衡化(Histogram Equalization,HE)。它对交通标志整幅图像的像素使用相同的直方图变换,对于像素值分布均衡的图像来说,图像增强效果较好。但是交通标志图像由于阴影、光线等因素导致图像中存在明显比图像其他区域暗或者亮的部分,全局直方图均衡化无法增强该区域的对比度。
2)自适应直方图均衡化(Adaptive Histogram Equalization,AHE)。它将图像划分为不重叠的区域块,对每个块分别进行直方图均衡化;但存在噪声时,每一个分割的区域块执行直方图均衡化后,噪声会被放大。
3)限制对比度自适应直方图均衡化(Contrast Limited Adaptive Histogram Equalization,CLAHE)。它通过限制局部直方图的高度减小局部对比度的增强幅度,从而限制噪声的放大及局部对比度的过度增强。
由图3 的图像去雾方法对比可知:原图中较亮区域,经过HE 处理后图像失真,并且带有明显的噪声;AHE 处理后失真情况有所改善,但是噪声明显增多;而CLAHE 能够避免上述情况,因此采用CLAHE方法对交通标志图像进行去雾处理。
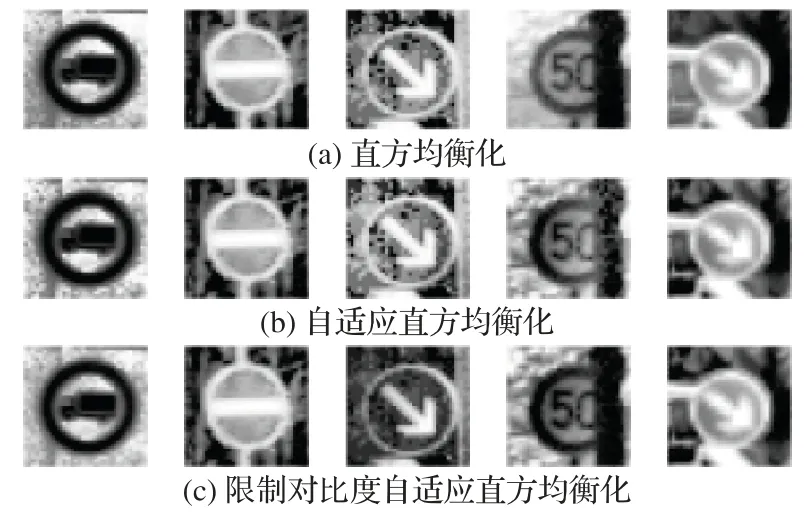
图3 图像去雾方法效果对比Fig.3 Effect comparison of image dehazing methods
1.1.3 图像仿射变换
训练集中各个种类图像的数量通常不平衡,可能导致训练后的模型偏向于代表性过高的种类。通过数据增强改善数据极度不平衡的情况,增强模型的识别精度及泛化性。
图像仿射变换包括平移、缩放、旋转等操作。假设图像原始坐标为(x,y),仿射变换后的新坐标为(x′,y′)。故任意点旋转变换将相当于两次平移与一次原点旋转变换的复合,即先将轴心(x0,y0)移到原点,然后将目标图像以轴心顺时针旋转θ,最后将图片左上角置为图像的原点,即变换关系为:

其中,平移变换、缩放变换和以及原点旋转变换均为任意点旋转变换的特殊情况。
1.2 改进的空间金字塔池化卷积神经网络模型
传统的特征提取基于颜色、形状和纹理等低级特征,通过CNN 可以实现高级特征的提取,提高交通标志的识别精度。CNN 在目标分类中被广泛应用并取得了优异的识别精度。CNN 利用局部感受野和权值共享大幅度减少了网络参数量,能在保证模型性能的情况下极大降低计算量。
SPPN-CNN 模型(见图4)在CNN 的第一、第二、第三卷积层后加入归一化层,对池化后的特征进行图像归一化处理,增强模型的泛化性。然后在三个池化层后分别加入空间金字塔池化层,空间金字塔的多尺度分块使分块呈现一种层次金字塔的结构,且局部空间块在聚合时的空间位置信息仍得到保留,从而使图像特征具有多尺度性,这些多尺度特征恰好能适应交通标志的尺度变化,实现多尺度的特征提取。改进SPPN-CNN参数如表1所示。

表1 改进SPPN-CNN参数Tab.1 Parameters of improved SPPN-CNN
1.2.1 改进的CNN结构
1)输入层。
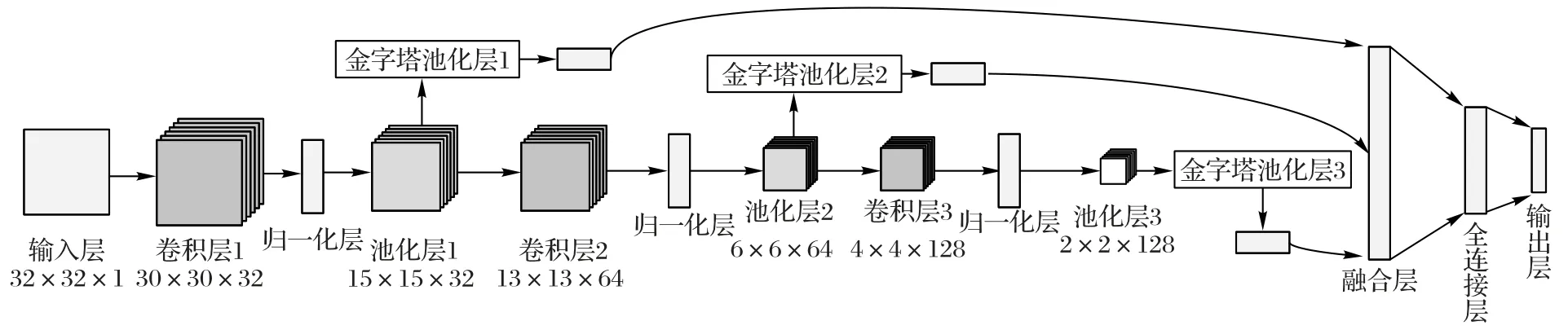
图4 改进空间金字塔池化卷积神经网络结构Fig.4 Network structure of improved convolutional neural network with spatial pyramid pooling and batch normalization
2)卷积层。
卷积层采用权值共享和局部感受野的策略,通过一定大小的卷积核,以合适步长从左往右,自上而下地遍历图像得到卷积特征图,用于表示图像的局部特征信息。卷积核实质上是权重值矩阵,通过网络训练得到最优值。不同尺寸、不同参数的卷积核提取图像的不同特征图,底层卷积层一般提取颜色、形状、纹理等低级特征,通过多层卷积层的特征提取,可以得到更高层次的语义特征。本文利用三层卷积层构建CNN,相较于典型CNN 模型GoogLeNet、VGG(Visual Geometry Group)提出的VGGNet 等网络层数和参数量较少,故计算量小,耗时少,模型较为轻量。
设卷积层l的卷积核为,则特征图尺寸为:

其中:l表示第几层卷积层,l≥1,l∈N+;Hl、Wl分别表示第l层卷积层提取特征图的高度、宽度;Kl×Kl表示卷积核的大小;sl为卷积步长;Dl为卷积核数量。卷积层的特征提取计算公式为:
非线性激活函数用于映射卷积核提取的特征图,通常与卷积层结合用于增加网络的非线性表达能力。通常采用广泛用于深度学习的线性整流(Rectified Linear Unit,ReLU)函数,函数表示如下:

3)池化层。
在卷积层后得到维度较大特征,将特征切成几个区域,取其最大值或平均值,得到新的、维度较小特征。本文使用尺寸为2×2 且步长为2×2 的重叠最大值池化方法,避免平均池化的模糊化效果,并增加数据的丰富性。
4)批量归一化层。
批量归一化(BN)表示对批量图像进行归一化处理,在CNN 的卷积层后加入BN 层对卷积层后形成的特征图进行归一化处理,求取所有样本所对应的一个特征图的所有神经元的平均值、方差,然后对特征图神经元做归一化处理。BN 层解决在训练过程中,中间层数据分布发生改变的问题,防止梯度消失或爆炸、加快收敛,提高精度。
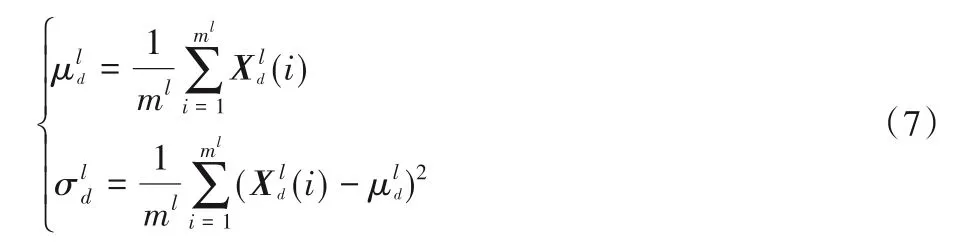
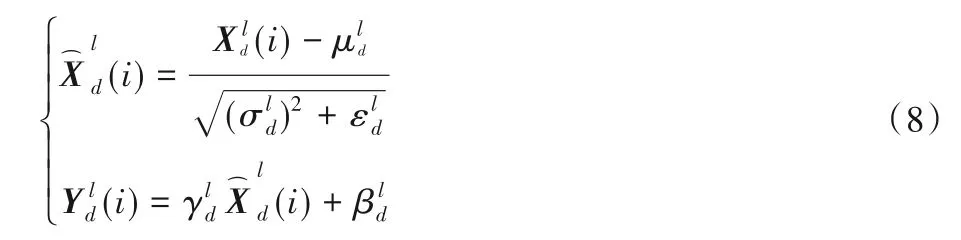
5)改进多尺度空间金字塔池化层。
图像空间金字塔是图像的多尺度处理,利用多分辨率分解并表征图像的强有力简单结构[15]。图5 表示空间金字塔池化结构及其改进,传统空间金字塔池化层提取同一张图像的不同尺度特征,而交通标志图像原始尺寸较小,经过多层卷积、池化等操作后生成的特征图很小,直接对其进行空间金字塔池化操作,难以获取更多的特征信息。

图5 改进多尺度空间金字塔池化结构Fig.5 Improved multi-scale spatial pyramid pooling structure
改进多尺度空间金字塔池化在传统空间金字塔池化基础上,结合CNN 特征图尺寸大小,利用多尺度金字塔策略采用3×3、2×2、2×2不同分辨率分别提取池化层1、池化层2、池化层3 的特征图。结合三层池化层特征图层数,生成的对应特征向量维度分别为9×32、4×64和4×128,将三个特征向量线性级联,可以得到1 056维度的融合空间金字塔池化特征向量。该融合特征包含了不同尺度、不同层级的特征信息,提取了低级形状、纹理等特征和高级语义特征,保留了不同特征细节,提高了模型的精度及鲁棒性。
6)全连接层。
把所有局部特征结合变成全局特征,用来计算最后每一类的得分。一般在全连接层使用分类器进行分类,包括SVM、Sigmod、Softmax 等。而Softmax 主要用于多分类目标识别,将全连接层的多个神经元的输出映射至(0,1)区间内,通过概率数值实现多分类。

1.2.2 训练优化器
1)Adam优化器。
Adam 优化器是结合AdaGrad 和RMSProp(Root Mean Square Prop)两种优化算法的优点所提出的一种利用梯度的一阶和二阶矩计算每个参数的自适应学习率方法。
首先,计算时间步的梯度:

梯度φt及梯度平方vt的指数衰减平均数为:

其中:δ1、δ2分别为0.9、0.999。
由于φ0/v0初始化为0,会导致φ0/v0偏向于0,故对梯度均值φ0/v0进行偏差纠正:

其中:默认学习率为η=0.001,为了避免除数为零,一般设置τ=10-8。因此,通过Adam 优化器能够从梯度均值及梯度平方两个角度对步长进行自适应调节更新。
2)小批量随机梯度下降算法。
训练过程中的权值更新一般包含标准梯度下降法、随机梯度下降法和小批量梯度下降法。小批次随机梯度下降法每次取总训练集的一个小批次进行训练,根据批次数据的误差更新权值。相较于随机梯度下降法,损失的下降更加稳定,同时由于是小批量的计算,相较于标准梯度下降法可以减少计算资源的占用。
小批量随机梯度下降法,k表示每一个批次的总样本数:

要优化的参数为a,b,分别对其进行微分,即偏微分,再求和的均值:
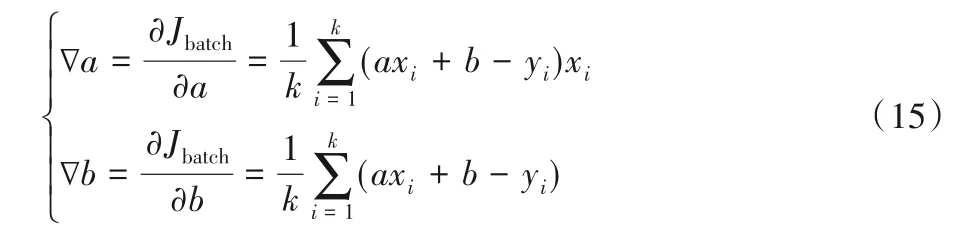

1.2.3 代价函数
目标函数用于衡量预测值与真实值的误差,主要有二次代价函数、交叉熵代价函数和对数似然损失函数。二次代价函数对于S 型激活函数的收敛具有局限性,而对数似然代价函数均能够快速准确地进行收敛,公式如下:

其中:J表示代价函数,表示批量样本数量;和P(i)分别表示第i个神经元的实际值和输出值。
2 实验与结果分析
本实验是在Windows 10 中基于Tensorflow 深度学习框架下完成的,硬件配置如下:处理器为Intel Core i5-8250U,内存为8 GB,GPU为NVIDIA GeForce MX150。
2.1 实验数据集
2.1.1 GTSRB
GTSRB 是一个用于交通标志识别的多类别大型数据集,所有的交通标志都是在实境下拍摄,包含不同光照、遮挡、扭曲、歪斜等不利于识别的交通标志图像。
GTSRB 数据集共有43 类交通标志(如图6 所示),包含51 839 张交通标志图片,其中训练集39 209 张,测试集12 630张。为了有效验证训练过程中模型效果,将总训练集分为训练集和验证集两部分,训练集34 799 张,验证集4 410 张。数据集包含的图片大小不等,在15× 15~250 × 250像素之间。

图6 GTSRB的43类交通标志示意图Fig.6 Schematic diagram of 43 traffic sign classes in GTSRB
2.1.2 数据扩充
交通标志训练集中各个种类图像的数量明显不平衡,从图7 所示的GTSRB 训练集的43 类交通标志数量分布可知,不同交通类别交通标志数量差异较大,最少为180 张,最多为2 010 张,这可能导致训练后的模型偏向于代表性过高的种类,部分类型交通标志识别精度较低,模型泛化性较差。
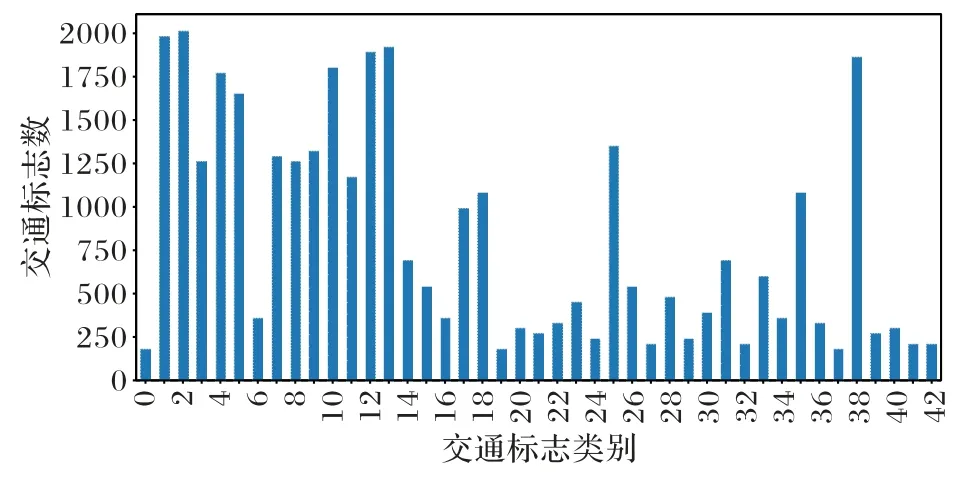
图7 GTSRB训练集不同交通标志种类数量分布Fig.7 Number distribution map of different traffic sign classes in GTSRB training set
为了提高交通标志识别模型的精度以及泛化性,通过仿射变换方法扩展数据集。使用各种类型的转换矩阵对训练图像进行平移、缩放、旋转、剪切等操作,增加训练样本的数量以及多样性,能提高模型的通用性;同时,提高测试和验证的准确性,特别是对失真的图像。部分样本仿射变换如图8所示。

图8 GTSRB中部分样本仿射变换示意图Fig.8 Affine transformation diagrams of some samples in GTSRB
2.2 实验过程与结果
针对图像处理、模型参数和模型结构三方面进行实验。图像处理包括图像预处理、图像增强和数据扩展;模型参数主要为卷积核尺寸、批尺寸、Dropout 参数。模型结构主要探讨模型不同改进方案的性能。
交通标志识别模型的初始设定包括:采用高斯正态分布初始化权重,使用ReLU 作为激活函数,优化器为Adam 小批次随机梯度下降算法,初始学习率为0.001,卷积层和全连接层的Dropout 初始参数值分别为1.0 和1.0,初始训练批次大小为512,使用SoftMax分类器进行分类,损失函数为对数似然代价函数。
将输入图片的尺寸归一化为[32,32,*],“*”代表不同深度,对于RGB 图像为3,对于灰度化图像为1。卷积层为3 层,三层卷积核数量分别为32、64和128,卷积核步长为1;池化层均采用最大池化方法,池化核尺寸为2×2,步长为2;全连接层为2层,神经元数量分别为120和84;训练次数设置为100。
2.2.1 图像处理实验
通过仿射变换扩展数据集,并在不同的照明条件和方向上提供其他图片;提高测试和验证的准确性,特别是对失真的图像。
通过各种仿射变换将GTSRB 中的每一类交通标志数量增加5%、10%、15%的图像,测试效果如表2所示。
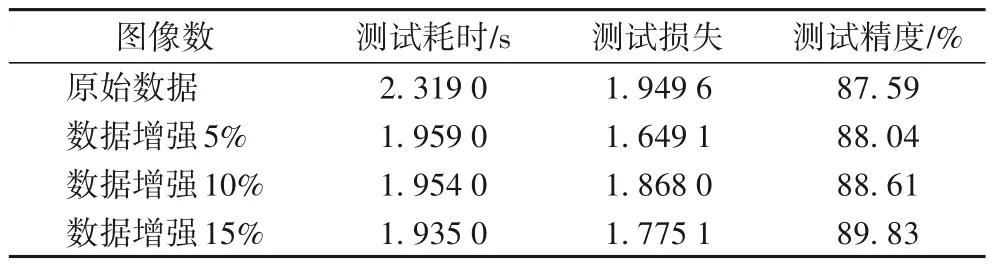
表2 不同数据量的性能对比分析Tab.2 Performance comparison and analysis of different data sizes
由表2 可知,GTSRB 数据集增强5%~15%范围内,随着数据量及数据形式的增多,准确率提高,即扩展后的训练样本种类数量分布更加合理,有利于减小不同种类交通标志之间的差异,增强泛化性。考虑训练耗时,选择数据增强10%作为训练数据量。
图像处理直接决定识别模型的输入图像特性,采用不同的图像处理方法获取包含不同特征的图像,通过模型训练将得到不同的模型,识别效果也有所不同。因此对比原始RGB图、灰度图、去雾图像及其归一化后的识别效果。
根据表3 可知,灰度图像对于精度的提高和计算量的减少有一定作用。而经过图像去雾处理后,精度有显著提高。同时,图像经归一化后,精度均有所提升,耗时有效缩短。
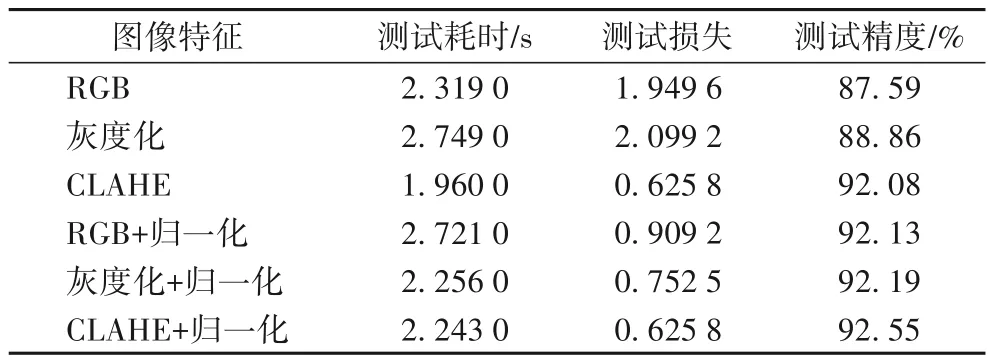
表3 不同图像处理方法的性能对比分析Tab.3 Performance comparison and analysis of different image processing methods
根据图像处理结果可知,将GTSRB 训练数据集扩展10%,然后对数据集所有图像灰度化后进行去雾处理,最后归一化图像作为模型的输入图像。
2.2.2 网络参数比选
神经网络模型性能受到卷积核尺寸、训练批次大小、随机梯度下降值等参数的影响。针对模型重要参数或方法进行比选以改进模型结构,选取性能更佳的交通标志识别模型。
1)卷积核尺寸。
卷积神经网络的卷积核通常设置为3×3、5×5 或7×7三种尺寸。不同卷积核尺寸提取不同的特征图,故对比不同尺寸的特征提取效果。
由表4 可知:对于测试耗时,3×3 卷积核耗时较少,7×7卷积核次之,5×5 耗时较多;对于损失,7×7 损失较大,5×5较小,3×3中等;对于精度,3×3和7×7略优于5×5。

表4 不同卷积核尺寸性能对比分析Tab.4 Performance comparison and analysis of different convolution kernel sizes
综合考虑耗时、损失和精度指标,采用3× 3卷积核,它可以提取图像更本质的特征,同时耗时较少,损失最小,精度最高,整体性能最优。
2)批量大小。
小批量随机梯度下降法中的批量尺寸会直接影响训练效果。批量尺寸表示一次迭代的样本数目,它的大小影响内存效率和内存容量的平衡,不同的配置及数据量拥有不同的最佳平衡。
在训练集中选择一组样本用来更新权值。批量尺寸的正确选取有利于内存效率和内存容量的平衡,故针对批量尺寸取值进行比选实验。批量尺寸通常为2n,常用的包括64、128、256 和512。如果数据集数量很小,可以采用全数据集,全数据集确定的方向能够更好地代表样本总体,网络较小时选用512,较大时选用64。
由表5 可知:随着批量大小的增加,测试精度降低,耗时减少;但相较于批量大小为128 时,批量大小为64 时精度更低,说明批量过小,在相同训练周期内模型训练效果欠佳。故综合考虑选取批量大小为128作为模型的批量大小。
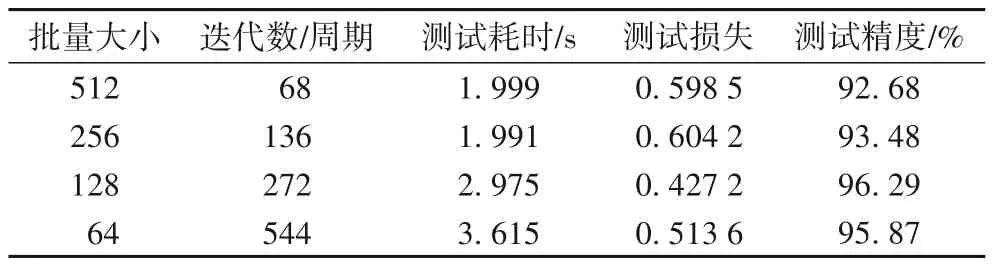
表5 不同批量大小性能对比分析Tab.5 Performance comparison and analysis of different batch sizes
3)Dropout参数。
在深度学习模型中,如果模型参数过多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象。因此,利用Dropout方法抑制过拟合的产生。
Dropout 表示在训练过程中以一定概率随机停止某些神经元的工作,让参数只经过部分神经元进行计算。使用Dropout 可以减少参数数量,有效防止过拟合现象的出现;同时能够减少对局部特征的依赖,增强模型的泛化性。
针对卷积层和全连接层进行Dropout,分别设置不同的Dropout 值,探究最佳方案。由于在卷积层之后进行了最大池化操作,为了预防流失过多的流失有价值的信息,卷积层的Dropout应尽量不低于0.5。
由表6 可知,当卷积层和全连接层的Dropout 值分别为0.7和0.5时整体效果最佳。

表6 不同Dropout参数性能对比分析Tab.6 Performance comparison and analysis of different Dropout parameters
2.2.3 模型结构改进实验
在传统CNN 的基础进行模型改进,对比三种改进策略:一是在训练过程中加入归一化层,包括LRN(Local Response Normalization)和BN;二是在第三层池化层后加入空间金字塔池化(Spatial Pyramid Pooling,SPP)网络,利用1× 1,2 × 2,3×3 三种池化层提取特征;三是在CNN 中引入改进的SPP 网络结构。
由表7可知,改进SPPN-CNN交通标志识别模型耗时略高于原始CNN 模型、SPP-CNN 模型和改进的SPP-CNN 模型,但其测试损失最低,并且测试准确率提高了超过0.5 个百分点,因此改进的SPPN-CNN模型性能最佳。
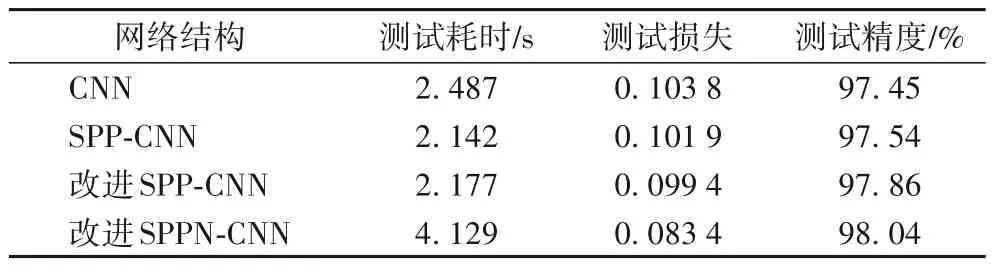
表7 不同CNN模型性能对比分析Tab.7 Performance comparison and analysis of different CNN models
2.3 实验分析
2.3.1 模型测试分析
通过上述实验验证可知,通过仿射变换将GTSRB 数据集扩充10%,并灰度化、CLAHE、归一化处理后,将交通标志图像输入改进的SPPN-CNN 模型结构进行识别。其中卷积核尺寸为3×3,全连接层为1 层,神经元数量为120。批量大小为128,卷积层和全连接层的Dropout 分别为0.7 和0.5;其余保存初始设定不变。
根据改进SPPN-CNN模型训练过程曲线图9可知,训练与验证数据的精度的损失曲线拟合度较好,表明模型不存在欠拟合或过拟合的情况;同时模型训练和测试精度高、损失小,表明模型鲁棒性较强。
由改进SPPN-CNN 模型测试图10 可知,在测试的所有批次中,测试精度较高,最低准确率高于94%,同时误差较小,最高误差不高于0.3,表明模型具有较强的泛化能力。
2.3.2 模型对比分析
对比HOG-Gabor 和MFC-ELM(Multi-layer Feature CNN and Extreme Learning Machine)算法可知,改进SPPN-CNN 模型相较于HOG-Gabor方法,识别准确率更高,耗时稍多。相较于MFC-ELM 模型,准确率稍低,但耗时大幅缩短。综合考虑识别准确率和耗时,改进SPPN-CNN 具有更均衡优良的识别性能。
2.3.3 模型识别效果
选择曝光、雾天和阴暗环境下交通标志图像,利用原始模型和改进SPPN-CNN 模型预测,分类效果如图11 所示。在曝光情况下,原始模型分类错误,但改进SPPN-CNN 模型分类正确,且正确率高。对比雾天和阴暗环境下预测精度可知,在恶劣天气情况下,利用改进SPPN-CNN 模型能够实现交通标志的准确分类,并且分类效果远高于原始模型。
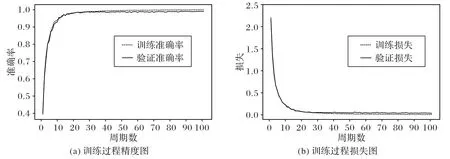
图9 改进SPPN-CNN模型训练过程曲线Fig.9 Training process curves of improved SPPN-CNN model
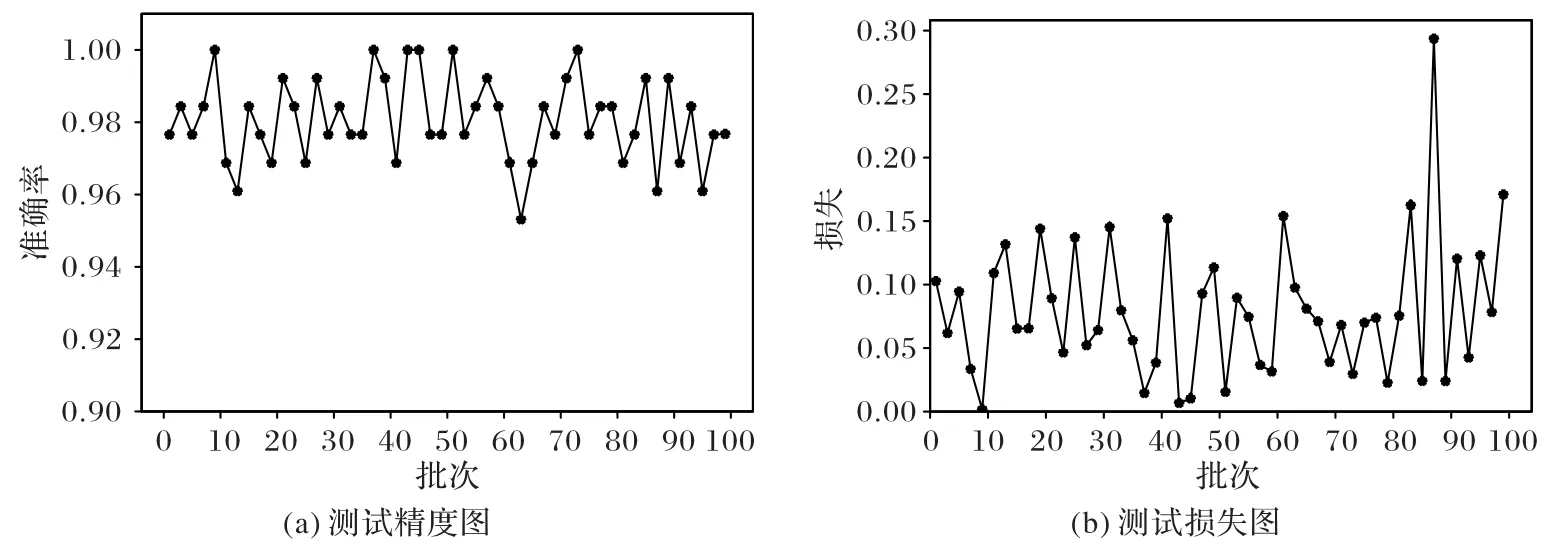
图10 改进SPPN-CNN模型测试曲线Fig.10 Test curves of improved SPPN-CNN model

图11 原始模型和改进SPPN-CNN模型对不同交通标志图像的预测精度对比Fig.11 Prediction accuracy comparison of original model and improved SPPN-CNN model on different traffic sign images

表8 不同交通标志识别模型性能对比Tab.8 Performance comparison of different traffic sign recognition models
3 结语
本文提出了一种高精度轻量级交通标志识别模型,利用图像归一化、灰度化和限制对比度直方均衡化等图像预处理方法消除光照、雾霾等环境因素的影响,提高模型分类精度和泛化性。在传统卷积神经网络的基础上,通过空间金字塔结构实现图像多尺度特征的提取,并利用批量归一化方法增强模型的图像表征能力,构建实时高精度的改进SPPN-CNN 交通标志识别模型。
利用仿射变换扩充GTSRB 训练数据集,并基于卷积核尺寸、训练批量大小和Dropout等网络参数比选实验对模型进行调参,同时对比分析不同改进模型的训练效果并验证模型性能。通过Python 编程算法实现实验结果表明,本文模型在网络量级小的情况下,达到了98.04%的分类精度和低配GPU下3 000 frame/s 的识别速率。改进SPPN-CNN 交通标志识别模型准确率高、泛化性和实时性强,满足自然环境下交通标志实时识别的实际应用需求。
猜你喜欢
计算机应用(2022年9期)2022-09-25
环球时报(2022-09-19)2022-09-19
汽车实用技术(2022年9期)2022-05-20
软件导刊(2022年3期)2022-03-25
考试与评价·七年级版(2020年4期)2020-10-23
计算机技术与发展(2019年1期)2019-01-21
智能计算机与应用(2018年2期)2018-05-23
小学教学研究·新小读者(2017年9期)2017-10-25
小天使·一年级语数英综合(2016年8期)2016-05-14
小天使·一年级语数英综合(2014年7期)2014-06-26
