
一种用于SLAM的嵌入式光束平差法加速器设计
2020-10-16 07:44秦书臻刘少山
天津大学学报(自然科学与工程技术版) 2020年12期
刘 强,秦书臻,俞 波,刘少山
一种用于SLAM的嵌入式光束平差法加速器设计
刘 强1, 2,秦书臻1, 2,俞 波3,刘少山3
(1. 天津大学微电子学院,天津 300072;2. 天津市成像与感知微电子技术重点实验室,天津 300072;3. 深圳普思英察科技有限公司,深圳 518000)
光束平差法是一种广泛应用于视觉SLAM系统后端的优化算法,但在实际应用中一直存在实时性差、能耗高的问题.本文在嵌入式FPGA平台上实现了一款针对相机位姿已知的光束平差算法的加速器.该加速器为计算中最耗时的雅可比矩阵更新和成本函数计算模块定制化硬件计算架构.首先分析算法结构去除冗余计算,再根据算法数据相关性设计流水线和并行处理单元,利用时分复用的方法将雅可比矩阵更新和成本函数计算在同一硬件上实现,同时在算法中引入猜测执行进一步提高计算速度,既满足了性能要求,又减小了硬件消耗.在Xilinx xc7z020上的实验结果表明,本文设计的光束平差法加速器,相对于嵌入式ARM处理器有5.9倍的性能提升,同时节约能耗68.7%.
光束平差法;现场可编程门阵列;同步定位与地图构建
光束平差法(bundle adjustment,BA)在三维重建中同时优化相机参数和三维结构特征点位置,广泛应用于三维立体场景的重建[1]、同步定位和地图构建(simultaneous localization and mapping,SLAM)[2]. BA通过最小化重投影误差来找到最优的参数估计,即三维空间点位置和相机参数.该误差被定义为三维点在图片上的位置与根据输入参数计算三维点在相机投影平面上位置差的L2范数[3].
移动机器人可以利用SLAM在没有预知地图信息的条件下定位自身和对周围环境建图[4].BA主要应用于SLAM后端,对前端已经建立的地图进行优化[5].在SLAM发展的初期,其后端多使用扩展卡尔兹曼滤波算法[6].之后,基于BA的SLAM系统[7-8]逐渐被开发出来,而且已经证明基于BA的图优化方法在性能和精度上相较滤波算法更适合作为SLAM 后端[9].
但是SLAM算法中密集的计算限制了SLAM在实际中的应用.现场可编程门阵列(field programmable gate array,FPGA)拥有高并行和低功耗计算等优势,得到了研究人员的重视.2014年,苏黎世联邦理工学院设计了可以应用于小型无人机的SLAM系统,其上搭载了4个摄像头,使用FPGA对输入图像做预处理[10].2017年帝国理工学院在FPGA上实现了SLAM中轨迹追踪模块的加速器,处理速度比嵌入式ARM处理器快了10倍以上[11].同年,北京理工大学设计了一款基于FPGA的ORB特征提取器,帧率达到了67帧/s[12].
目前SLAM算法在嵌入式端距实际应用仍有一定的距离,其中BA是限制应用的性能和功耗的瓶 颈[13].针对BA的FPGA加速器研究处于起步阶段. 2019年天津大学设计了可以加速典型BA计算中最耗时的舒尔消除的FPGA加速器[14],对光束平差硬件加速器进行了探索.但是,在SLAM应用设备已知自身的位姿[15]、仅需要对环境建图时,或者应用设备全球定位信号良好并搭载有高精度的实时动态设备可以获取位姿时,BA计算中的舒尔消除可以省略,雅可比矩阵更新和成本函数计算成为了提高性能的瓶颈.
为了解决该问题,本文在嵌入式FPGA上设计了软硬件协同的BA加速器,将已知相机位姿时BA计算中最消耗时间的雅可比矩阵更新和成本计算部分利用硬件进行加速.通过对投影函数及其雅可比矩阵算法进行分析,拆分了相机旋转与重投影计算,减少了冗余计算.同时采用时分复用的方式在同一硬件下实现雅可比矩阵更新和成本函数计算,通过共享中间计算结果,进一步省略了不必要的计算,节省硬件消耗,降低功耗.另外,根据算法的数据依赖性设计相机旋转与重投影计算的内部流水线,同时可以复制重投影计算模块以提升计算速度.该加速器设计可应用于嵌入式SLAM,使设备能够快速地完成建图优化任务.
1 算法基本原理
1.1 光束平差法
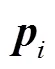

式中表示第个三维点是否被第张图片观测到.由于空间位置遮挡的关系,一张图片并不能观测到所有的三维点,当第个三维点被第张图片观测到时,否则.图1为简单的BA问题模型.
1.2 相机模型


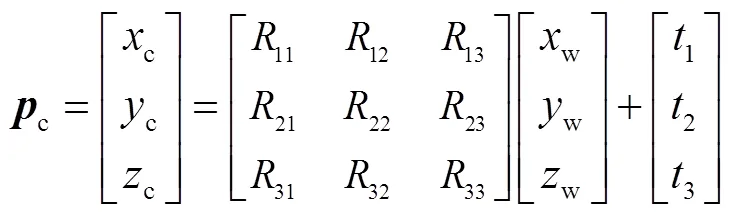


1.3 Levenberg-Marquardt优化算法
Levenberg-Marquardt(LM)算法是一种非线性最小二乘法,被广泛用于寻找非线性函数的局部最小 值[18].LM算法结合了最速下降法和高斯-牛顿法的优点,使它可以从各种给定的初始条件中收敛.目前,LM已成为在视觉SLAM应用中解决光束平差问题的标准算法[9].


图2 LM算法流程

2 硬件架构设计
本文设计基于Xilinx Zynq系列处理器.该系列FPGA包含处理系统(processing system,PS)和可编程逻辑(programmable logic,PL)两部分.PS部分为双核ARM Cortex-A9处理器,执行软件程序.PL为可编程逻辑电路,可以实现硬件加速器.PS与PL之间通过AXI4总线进行数据交互.本文所设计的硬件加速器架构如图3所示.该架构将雅可比矩阵更新和成本函数计算两个耗时的部分在PL上采用硬件电路进行计算加速,其他部分在PS上使用软件实现.软件与硬件交互数据采用基于AXI4总线的直接内存读取单元(DMA),硬件中使用FIFO做软硬件数据交互的缓存.

图3 硬件设计的架构



图4 旋转矩阵处理器的架构


图5 重投影处理器的架构
3 实验结果与分析
本文使用搭载Xilinx xc7z020clg484-1 FPGA芯片的Zedboard开发板对提出的加速器设计进行评估.本文的设计与Google公司的开源最优化库Ceres-Solver[20]软件进行比较.Ceres-Solver运行在两个处理器平台上:x86平台使用带有8GB内存的Intel Core i5-8400,主频为2.8GHz;ARM平台使用Zynq-7000系列FPGA中内置的双核ARM Cortex-A9,带有1GB内存,主频为667MHz.软件实现使用双精度浮点数,硬件设计使用单精度浮点数.RMP最大的时钟频率为50MHz,RPP最大的时钟频率为150MHz.评估的数据集选自华盛顿大学Bundle Adjustment in the Large(BAL)数据集[21]中图片数量小于50的5个数据集,其所含有的照片数、三维点数目和观测数见表1.该选用的数据集可以满足小型SLAM中全局BA建图和大型SLAM中局部建图的要求[7].本节主要评估了硬件设计的资源使用情况、性能和功耗.
表1 实验所使用的数据集

Tab.1 Datasets used for the experiments
表2评估了本文硬件设计的资源消耗,前两行分别列出了RMP模块和RPP模块的资源消耗情况.RMP模块占用了FPGA芯片中17%的查找表(look up table,LUT)、11%的触发器(flip-flop,FF)、0.5个块随机存取存储器(block-RAM,BRAM)和12个数字信号处理单元(digital signal processor,DSP).RPP模块占用了13%的LUT、9%的FF、15个BRAM和30个DSP.因为计算所需要暂存的数据较少,RMP使用的是利用LUT组成的分布式RAM,同时因为近似串行的设计也减少了片上DSP的用量.考虑到FPGA片上资源和布局布线的问题,最终在FPGA上实现了5个RPP,相比仅使用一个RPP可以缩短近80%的处理时间.
表3评估了雅可比矩阵更新和成本函数计算模块在3个平台上运行各数据集的执行时间,表格括号中为成本函数的计算时间和加速比.利用Intelx86处理器处理5组数据集,更新雅可比矩阵平均要消耗35.497ms,成本函数计算平均需要5.971ms,而本文设计的硬件加速器平均使用4.199ms即可完成上述的两项工作.相比x86平台,本文设计在雅可比矩阵更新和成本函数计算分别有8.453倍和1.422倍的加速效果.对比低功耗的ARM平台,本文的加速器在雅可比矩阵更新上实现248.608倍的加速效果,在成本函数计算上也有22.570倍加速.
表2 硬件设计的资源消耗

Tab.2 Hardware resource utilization
表3 软硬件实现在雅可比矩阵更新和成本函数计算上的性能比较

Tab.3 Performance comparison of Jacobian Update and Cost Calculation between hardware and software implementations
此外,本文还评估了整体光束平差法在3个计算平台上的性能和所消耗的能量,结果如表4所示.Intel CPU的功率为65W,Xilinx功耗评估器分别给出了ARM平台和FPGA平台的功率,分别为1.5W和2.8W.在Intel x86,ARM和FPGA平台上处理5个数据集,单次BA迭代的平均执行时间分别为51.029ms、1363.232ms和228.646ms.FPGA平台的性能比嵌入式ARM处理器有5.962倍的提升,可以满足实时建图的要求.由于算法中还存在部分计算使用ARM处理器执行,在光束平差法的执行时间上,本文设计比x86平台要长.3种平台上Intel处理器实现的速度最快,但高功率不适合嵌入式终端使用.本文实现的FPGA设计相比Intel x86处理器和ARM处理器分别可以节省80.7%和68.7%的能量消耗,在高性能的同时也节约了能量消耗,使得该加速器在嵌入式设备上的续航更长.文献[14]中的BA硬件加速器,由于针对的是典型BA算法并且加速了舒尔消除步骤,在这5个数据集上的平均迭代时间为1.29s.本文加速器针对SLAM应用设备已知自身位姿的情况,优化了计算,提升了性能.SLAM开发者可以根据具体的应用场景选择相应的BA加速方案.
表4 光束平差法上的性能与功耗比较

Tab.4 Performance and energy consumption comparison of bundle adjustment
4 结 语
本文针对SLAM后端已知相机位姿建图问题提出了一种软件硬件结合的BA加速器,通过时分复用、猜测执行、并行计算等技术,实现了高能效的计算.本文的硬件加速器可以在资源、功率受限的嵌入式设备上在已知相机位姿的条件下高效地完成实时建图任务,实现机器人计算和视觉重建地本地化.
[1] 景子君. 运动法三维重建的研究与实现[D]. 合肥:中国科学技术大学,2018.
Jing Zijun. Study and Reality of 3D Reconstruction for SFM[D]. Hefei:University of Science and Technology of China,2018(in Chinese).
[2] 姚二亮,张合新,张国良,等. 基于Vision-IMU的机器人同时定位与地图创建算法[J]. 仪器仪表学报,2018,39(4):230-238.
Yao Erliang,Zhang Hexin,Zhang Guoliang,et al. Robot simultaneous localization and mapping algorithm based on vision and IMU[J]. Chinese Journal of Scientific Instrument,2018,39(4):230-238(in Chinese).
[3] Philip H S T,Andrew Z. Vision Algorithms:Theory and Practice[M]. Berlin:Springer Berlin Heidelberg,1999.
[4] Davison A J,Reid I D,Molton N D,et al. MonoSLAM:Real-time single camera SLAM[J]. IEEE Trans Pattern Anal Mach Intell,2007,29(6):1052-1067.
[5] 权美香,朴松昊,李 国. 视觉SLAM综述[J]. 智能系统学报,2016,11(6):768-776.
Quan Meixiang,Piao Songhao,Li Guo. An overview of visual SLAM[J]. CAAI Transactions on Intelligent Systems,2016,11(6):768-776(in Chinese).
[6] Cadena C,Carlone L,Carrillo H,et al. Past,present,and future of simultaneous localization and mapping:Toward the robust-perception age[J]. IEEE Transactions on Robotics,2016,32(6):1309-1332.
[7] Mur-Artal R,Montiel J M M,Tardos J D. ORB-SLAM:A versatile and accurate monocular SLAM system[J]. IEEE Transactions on Robotics,2015,31(5):1147-1163.
[8] 林辉灿,吕 强,王国胜,等. 鲁棒的非线性优化的立体视觉-惯导SLAM[J]. 机器人,2018,40(6):911-920.
Lin Huican,Lü Qiang,Wang Guosheng,et al. Robust stereo visual-inertial SLAM using nonlinear optimization[J]. Robot,2018,40(6):911-920(in Chinese).
[9] Strasdat H,Montiel J M M,Davison A J. Visual SLAM:Why filter?[J]. Image and Vision Computing,2012,30(2):65-77.
[10] Nikolic J,Rehder J,Burri M,et al. A synchronized visual-inertial sensor system with FPGA pre-processing for accurate real-time SLAM[C]// Proceedings of the 2014 IEEE International Conference on Robotics and Automation(ICRA). Piscataway,USA,2014:431-437.
[11] Boikos K,Bouganis C S. A high-performance system-on-chip architecture for direct tracking for SLAM[C]// Proceedings of the 2017 27th International Conference on Field Programmable Logic and Applications(FPL). Piscataway,USA,2017:1-7.
[12] Fang W,Zhang Y,Yu B,et al. FPGA-based ORB feature extraction for real-time visual SLAM[C]. Proceedings of the 2017 International Conference on Field Programmable Technology(ICFPT). Piscataway,USA,2017:275-278.
[13] 刘 康. 大尺度视觉SLAM的光束平差算法研究[D]. 北京:北京邮电大学,2018.
Liu Kang. Research on Bundle Adjustment for Visual SLAM Under Large-Scales Scence[D]. Beijing:Beijing University of Posts and Telecommunications,2018(in Chinese).
[14] Qin S,Liu Q,Yu B,et al. π-BA:Bundle adjustment acceleration on embedded FPGAs with co-observation optimization[C]//2019 IEEE 27th Annual International Symposium on Field-Programmable Custom Computing Machines(FCCM). Piscataway,USA,2019:100-108.
[15] Konolige K. Large-scale map-making[C]//Proceedings of the 19th National Conference on Artificial Intelligence. Palo Alto,USA,2004:457-463.
[16] Fioraio N,Di Stefano L. Joint detection,tracking and mapping by semantic bundle adjustment[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,USA,2013:1538-1545.
[17] 解则晓,周作琪. 基于运动恢复结构的空间点定位方法[J]. 激光与光电子学进展,2018,55(8):370-377. Xie Zexiao,Zhou Zuoqi. Method of space point positioning based on structure-from-motion[J]. Laser & Optoelectronics Progress,2018,55(8):370-377(in Chinese).
[18] Madsen K,Nielsen H B,Tingleff O. Methods for Non-Linear Least Squares Problems[EB/OL]. http://www2. imm.dtu.dk/pubdb/views/edoc_download.php/3215/pdf/imm3215.pdf,2004-07-14.
[19] Lourakis M L A,ArgyrosAA. Is Levenberg-Marquardt the most efficient optimization algorithm for implementing bundle adjustment?[C]//Tenth IEEE International Conference on Computer Vision (ICCV'05) Volume 1. Piscataway,USA,2005,2:1526-1531.
[20] Sameer Agarwal. Ceres Solver[EB/OL]. http://ceres-solver.org,2018-06-30.
[21] Agarwal S,Snavely N,Seitz S M,et al. Bundle adjustment in the large[C]//European Conference on Computer Vision. Berlin,Germany,2010:29-42.
An Embedded Bundle Adjustment Accelerator Design for SLAM
Liu Qiang1, 2,Qin Shuzhen1, 2,Yu Bo3,Liu Shaoshan3
(1. School of Microelectronics,Tianjin University,Tianjin 300072,China;2. Tianjin Key Laboratory of Imaging and Sensing Microelectronic Technology,Tianjin 300072,China;3. Shenzhen PerceptIn Technology Co.,Ltd.,Shenzhen 518000,China)
Bundle adjustment(BA)is an optimization algorithm widely used in the backend of visual SLAM systems,but it exhibits the problems of low real-time performance and high energy consumption in practice. This paper designs an embedded FPGA accelerator for BA with a known camera pose. The accelerator customizes hardware computing architectures for Jacobian matrix update and cost function calculation which are the most time-consuming parts of the BA. The bundle adjustment algorithm is first analyzed to remove redundant calculations,and then the pipelined and parallel processing unit is designed based on the algorithm’s data dependence. Using time division multiplexing,Jacobian matrix update and cost function calculation are implemented on the same hardware,and the speculative execution is incorporated into the algorithm to further improve computation speed. By doing so,the hardware resources are saved and the performance requirements are satisfied. The experimental results on Xilinx xc7z020 indicate that the accelerator has a 5.9 fold performance improvement,compared with the embedded ARM processor. At the same time,the accelerator can save 68.7% of energy.
bundle adjustment;field programmable gate array;simultaneous localization and mapping
TP368
A
0493-2137(2020)12-1281-07
10.11784/tdxbz201909072
2019-09-30;
2020-05-11.
刘 强(1978— ),男,博士,教授.
刘 强,qiangliu@tju.edu.cn.
国家自然科学基金资助项目(61974102).
Supported by the National Natural Science Foundation of China(No. 61974102).
(责任编辑:王晓燕)
猜你喜欢
现代装饰(2022年5期)2022-10-13
小哥白尼(趣味科学)(2022年5期)2022-08-15
汽车实用技术(2022年13期)2022-07-19
阅读(科学探秘)(2022年5期)2022-06-07
家庭影院技术(2021年7期)2021-08-14
少先队活动(2021年6期)2021-07-22
奥秘(2021年3期)2021-04-12
电子制作(2019年15期)2019-08-27
电子制作(2019年7期)2019-04-25
红领巾·探索(2014年1期)2015-03-16
