
基于深度学习的家庭基站下行链路功率分配
2020-10-15 08:32:24吕亚平贾向东叶佩文
计算机工程 2020年10期
吕亚平,贾向东,2,路 艺,叶佩文
(1.西北师范大学 计算机科学与工程学院,兰州 730070; 2.南京邮电大学 江苏省无线通信重点实验室,南京 210003)
0 概述
据调查显示,在欧洲20%~40%的移动通话发生于室内,在美国为40%~50%,在中国则高达60%,同时,超过50%的语音服务和70%的数据流量服务发生于室内[1]。近年来出现的家庭基站技术,在增加无线网络容量、解决室内覆盖问题以及从宏基站上卸载流量等方面具有较大优势[2]。随着5G时代的到来以及智能终端设备的爆炸式增长,现有的室内无线通信网络已经很难满足移动用户对各种数据服务的需求。因此,如何提高室内无线网络的容量,为室内移动用户提供更好的数据服务变得十分重要。
室内无线通信是无线通信中不可或缺的一部分,目前室内无线通信的主要实现方式有家庭基站和WiFi 2种。在国外,室内通信使用家庭基站比较多,而在国内,室内通信大多使用WiFi,家庭基站更多用于商用。商用区域内家庭基站是处理室内无线网络容量和覆盖的重要技术,与WiFi相比,家庭基站在授权的频段内能提供较好的语音服务质量,并且更简单实用,有较好的安全性能。此外,其还具有功耗少、电池寿命长、不需要WiFi双模手机或其他设备等优点,同时还具有服务等同性,即支持多种服务在家庭基站上无缝工作。
为解决室内无线网络的容量问题,众多研究人员从不同角度对家庭基站进行了研究与分析。文献[3]提出一种功率控制和覆盖(Power Control and Coverage,PCC)算法,以增加网络效用和降低能量消耗,并建立了PPC算法对最优解的收敛性,但该算法在移动用户密集区域不一定适用。文献[4]提出带宽-功率模型来减少移动用户使用的带宽总和,并最大限度地降低噪声对传输速率的影响,但该算法并未考虑家庭基站密集部署的情况。文献[5-6]研究了双层毫微微蜂窝网络中的全双工通信,通过博弈理论共同考虑上下行优化问题,但没有考虑用户的移动性和用户密集聚集的情况。文献[7]使用Q学习算法来最大化宏小区和毫微微小区的网络容量。文献[8]通过减少干扰和平衡数据下载这两方面来最大化网络容量。文献[9]根据干扰和服务因素,调整主要家庭基站的传输功率,执行基于概率的资源分配算法,以安排每个家庭基站的传输时间和频率,进一步增强整体频谱重用。这样可以有效地避免相邻家庭基站之间的干扰,从而更好地满足服务质量连接,以提高网络的吞吐量。
尽管目前深度学习在无线通信领域尚处于初步探索阶段,但是已有众多学者对其进行研究并取得一些成果,文献[10]使用深度学习算法解决了状态空间连续与动作空间连续的问题,文献[11]使用深度学习算法达到了能效优化的目的,文献[12]使用深度强化学习有效地降低了用户的任务执行总时延,文献[13]使用强化学习算法解决了窄带物联网实时优化的问题。
受文献[7]和深度学习算法的启发,本文建立一个在办公区域密集部署家庭基站的系统模型,基于深度Q学习(Deep Q Learning,DQL)算法对家庭基站的下行链路功率分配方法进行设计,使其能够自适应网络变化,从而提高室内无线通信网络的吞吐量。
1 系统模型与假设
图1为在办公区域密集部署家庭基站的一个系统模型。该系统模型借用文献[14]的路径损耗模型。在该系统模型中,考虑家庭基站的下行传输。假设有N个家庭基站,M个移动用户;家庭基站的空间物理位置遵循空间位置强度为λ(λ=3/4×30/1003π)的泊松点过程;用户随机分布在该办公区域内;所有的家庭基站共享频谱带宽;一个移动用户只能与一个基站进行连接。考虑到实际情况,该网络模型中移动用户受到的干扰来自所有的家庭基站,如图1中实线箭头所示。
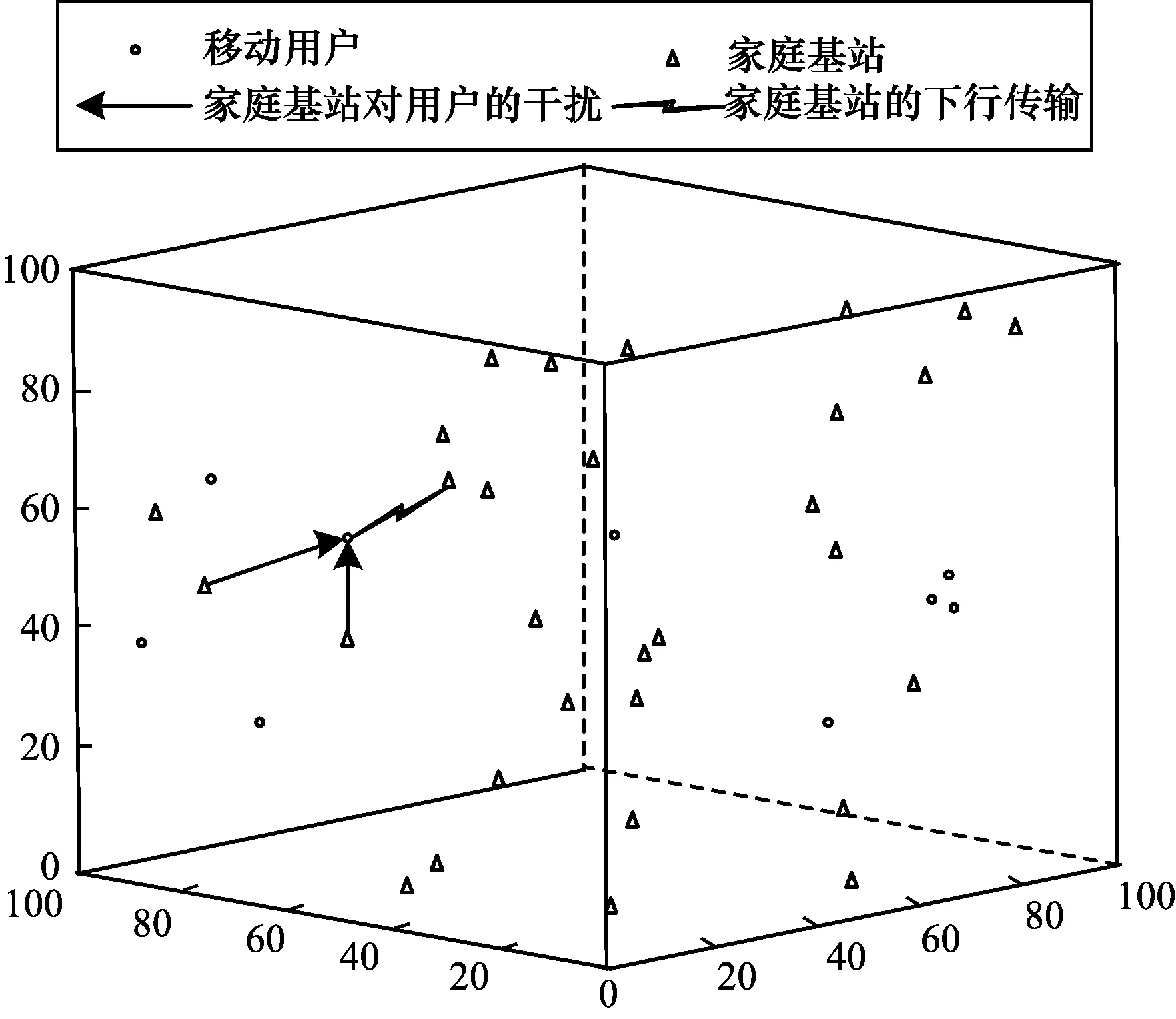
图1 办公区域家庭基站密集部署的网络模型Fig.1 Network model of intensive deployment of home base stations in office area
假设n={1,2,…,i,…,N}表示家庭基站的集合,m={1,2,…,j,…,M}表示办公区域内用户的集合。基站i与移动用户m通信时,受到的干扰信号为:
(1)
其中:Di,m表示移动用户m是否接入基站i,如果Di,m=0,则表示移动用户m成功接入基站i,反之则没有;Pi,m表示移动用户m与基站i通信时,基站i的发射功率;G表示移动用户与基站通信时的链路增益。G由下式所得:
(2)
其中,hn,m、Zn,m、φ分别是基站n与移动用户m通信时的多径衰落、阴影衰落以及路径损耗因子,而γn,m则代表基站n和移动用户m两者之间的距离。
假设移动用户与基站通信时接收的高斯白噪声的方差δ2是固定值,且信道状况已知,则系统的信号与干扰加噪声比(SINR)可表示为:
(3)
由香农公式可得系统的总吞吐量C为:
(4)
其中,B是家庭基站的带宽。
根据最大化网络吞吐量这一优化目标,家庭基站的发射功率必须不大于其最大发射功率,则目标优化问题可表述如下:
(5)
约束条件为:
Pn,m≤Pmax
∀n∈{1,2,…,i,…,N}, ∀m∈{1,2,…,j,…,M}
(6)
其中,Pmax是家庭基站的最大发射功率。
2 基于深度强化学习的功率分配算法
深度学习具有较强的感知能力,但是缺乏一定的决策能力;而强化学习具有决策能力,但是难以解决感知问题[15]。深度强化学习可以把深度学习的感知能力和强化学习的决策能力结合起来[16],优势互补,通过不断地试错,与环境进行交互,最大化累积奖赏从而获得最优策略[17]。因此,本文使用同时具备感知能力和决策能力的深度Q学习算法来解决家庭基站的下行链路功率分配问题 。
DQL算法是Q学习算法的一种变体,其利用深度卷积神经网络估计值函数、经验回放进行学习,并且设置了目标网络来独立处理时间差分算法中的时间差(Time Difference,TD)。图2展示了本文基于深度Q学习的功率分配算法框架。

图2 基于深度Q学习的功率分配算法框架Fig.2 Framework of power allocation algorithm based on deep Q learning
如图2所示,该框架包含回放记忆单元、当前值网络、目标值网络、环境和DQL误差函数五大模块。回放记忆单元存放经验回放,经验回放是指在代理与环境交互过程中,经验会以(s,a,r,s′)的形式存放在回放记忆单元中,每次训练会从回放记忆单元中随机抽取一批数据进行训练,可以在一定程度上消除样本之间的相关性。DQL中使用两个值网络:一个网络是当前值网络,与环境交互,并且不断更新;另一个网络是目标值网络,它既不与环境交互,也不在每个时间步进行更新,而是每隔一定时间步才会更新,每次更新都把当前值网络参数直接赋值给它。s是算法的观测,a表示在观测s下执行的动作,r表示动作a执行后得到的奖罚[18],s′为执行动作a后的观测值,a′为在观测值s′下执行的动作,θ表示网络的权重和偏置,θ-为θ的赋值。
本文所采用的深度Q学习算法是基于与环境不断实时交互的多代理(代理、状态、动作、奖励)算法。对多代理功能定义如下:
代理人:基站n,1≤n≤N。
状态:sn={Mn,Pn},Mn表示连接到基站n的移动用户数量,Pn表示基站n的发射功率。
动作:an={n,ΔPn},n表示基站,ΔPn表示基站n的发射功率调整值。
奖励函数:
(7)
当用户m与基站n连接时,rn,m表示对基站n的奖励,Cn,m表示基站n的吞吐量。每个代理经过不断的迭代学习来更新行为状态值函数,迭代式如下:
θt+1=θt+α[r+βa′maxQ(s′,a′;θ-)-
Q(s,a;θ)]Q(s,a;θ)
(8)
其中,α∈[0,1]是学习率,β∈(0,1)是折扣因子,Q(s,a;θ)是误差函数梯度。
深度神经网络(Deep Neural Network,DNN)是一种深度学习模型,拥有较高的准确度[19]。如图3所示,本文设计的DNN由输入层、2层隐藏层、输出层构成,并将DQN作为动作状态值函数Q(s,a;q)。

图3 DNN网络的基本架构Fig.3 Basic architecture of DNN network
在该深度神经网络中,输入层数据为[M1,M2,…,Mi,…MN,P1,1,P1,2,…Pi,j,…,Pn,m],隐藏层是为了优化网络的非线性,提高网络的拟合能力,输出层数据为基站n发射功率的调整值。为防止过拟合,隐藏层随机丢弃一些节点。深度神经网络的损失函数如下:
L=r+βa′maxQ(s′,a′;θ-)-Q(s,a;θ)
(9)
3 仿真结果及分析
对家庭基站的下行链路功率控制算法进行仿真与数值分析[20]。仿真参数设置如表1所示,其中的多径衰落和阴影衰落使用文献[14]所采用的参数值,分别服从指数分布和对数正态分布。

表1 仿真参数Table 1 Simulation parameters
分别使用贪婪算法、Q学习算法和DQL算法得到办公区域网络的总吞吐量C与迭代更新次数之间的关系,如图4所示。可以看出,Q学习算法和DQL算法的网络总吞吐量远大于贪婪算法,并且DQL算法的网络总吞吐量优于Q学习算法。

图4 3种算法的网络吞吐量的比较Fig.4 Comparison of network throughput of three algorithms
图5对比了Q学习算法和DQL算法的收敛速度。可以看出,随着更新迭代次数的增加,DQL算法的收敛速度逐渐加快,且始终优于Q学习算法。这是因为对于每次迭代以及用户的移动,Q学习算法需要重新计算网络总吞吐量和收敛。虽然DQL算法也存在波动,但相较于Q学习算法是更稳定的。此外,随着深度神经网络的不断强化,深度Q学习算法显著地提高了网络总吞吐量。

图5 Q学习算法和DQL算法的收敛速度对比Fig.5 Comparison of convergence rates between Q learning algorithm and Deep Q learning algorithm
4 结束语
为提高在办公区域密集部署的家庭基站网络的无线通信质量,本文提出基于深度Q学习算法的网络模型,用以对家庭基站的下行链路进行功率分配,最大化系统吞吐量。仿真实验表明,与贪婪算法和Q学习算法相比,DQL算法具有更高的网络吞吐量和更快的收敛速度,验证了本文模型的有效性。下一步将在不影响用户服务质量的前提下,基于深度Q学习算法研究宏基站覆盖下家庭基站的下行链路发射功率问题。
猜你喜欢
无线互联科技(2017年24期)2018-01-22 10:39:24
中国管理信息化(2017年18期)2018-01-04 18:41:52
集装箱化(2016年11期)2017-03-29 16:15:48
集装箱化(2016年12期)2017-03-20 08:32:27
物联网技术(2017年2期)2017-03-15 17:18:11
现代商贸工业(2016年22期)2016-12-27 11:08:49
电脑知识与技术(2016年25期)2016-11-16 12:52:39
金融理财(2015年7期)2015-07-15 08:29:02
集装箱化(2014年2期)2014-03-15 19:00:33
通信学报(2013年2期)2013-10-26 09:10:12
