
基于深度学习的入侵检测系统
2020-10-14 01:03董宁程晓荣
网络安全技术与应用 2020年10期
◆董宁 程晓荣
基于深度学习的入侵检测系统
◆董宁 程晓荣
(华北电力大学(保定)控制与计算机工程学院 河北 071000)
入侵检测作为一种主动防御系统能够有效阻止来自黑客的多种手段的攻击,随着机器学习和深度学习的发展,相关技术也开始应用到入侵检测中。本文在KDD-Cup 1999数据集的基础上,对其进行数据标准化和归一化,然后利用随机森林对数据集处理,计算每个特征的袋外数据误差(OOB),得到每个特征的重要性,提取出12个重要性最高的特征,并将数据集按照7/3随机划分为训练集与测试集,使用五层深度神经网络训练,三个隐藏层设置为100个节点,ReLU Leaky作为激活函数,使用Adam作为优化器,交叉熵作为代价函数,对处理后的数据集训练。以准确率(Accuracy),精确率(Precision),召回率(Recall)为模型的衡量指标,最终得到了精确率为94.87%,召回率为94.35%的模型。
深度学习;神经网络;入侵检测;KDD99
1 引言
入侵检测系统(IDS)是一种能够对网络中的流量和用户行为进行实时跟踪并审计,判断当前操作是否为可疑行为并能主动报警的网络安全设备。区别于其他网络安全设备,IDS是一种主动防御系统。根据信息的来源可以将入侵检测分为基于主机型与基于网络型。根据检测方法又可分为异常入侵检测型和误用入侵检测型。早期有些入侵检测系统[1]通过建立用户特征表,比较当前特征与已存储定型的以前特征,利用概率统计方法,从而判定是否为攻击行为。然而该方法的缺陷在于用户特征表需要手动更新,且判定是否入侵的参数的确定比较困难,容易造成过高的误报率和漏报率。
随着机器学习和深度学习技术的发展,有人提出了基于KNN(K最近邻分类算法)的入侵检测模型,通过将用户行为进行分类,来判定是否为入侵行为[5]。然而该方法随着用户访问量的增加,单次行为分类的时间可长达60秒,在实际使用中并不可取,尽管后期有人提出了优化的方案[2],然而当数量级达到百万时仍无法高速地对用户的行为进行响应和判断。到目前为止基于神经网络的入侵检测系统比较流行,本文则通过对KDD1999数据集经过处理后利用深度神经网络对数据进行训练,得到一个精确率和召回率都比较高的模型。
2 基于深度神经网络的KDD数据集训练
2.1 数据集数据处理
本文采用KDD1999数据集,该数据集每条记录由41个特征和一个标签组成。其中,41个特征由四个类型组成,包含TCP基本连接特征(九种,1-9)、TCP连接的内容特征(13种,10-22)、基于时间网络的流量统计特征(九种,23-31)和基于主机的流量统计特征(十种,32-41)。在41个特征中还存在一些非连续型特征,例如连接的服务和状态等。由于数据集各特征之间数据差异较大,且存在字符型数据,所以需要对数据集进行预处理,即字符型转为数字型,特征标准化,特征归一化。
字符型数据转为数字型可选用one-hot编码,然而在本文中为减小后续计算量,将所有可能值编入数组,根据数组中对应值的索引来将字符型数据转换为数字型。数据标准化与数据归一化用于将特征规范在特定区间内,防止差异过大。数据标准化如式1所示。
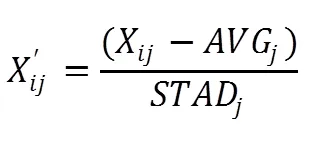
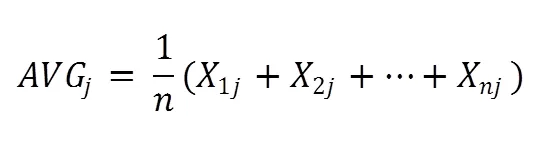
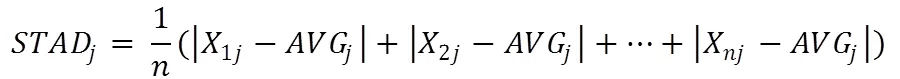
式2中AVG为平均值,式3中STAD为平均绝对偏差,比标准差对于孤立点具有更高的鲁棒性。
数据归一化如式4所示:
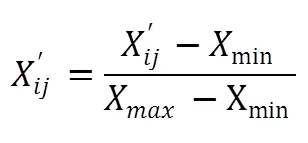
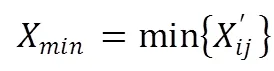
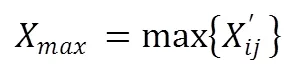
式5和6分别为提取出所有样本的最小值与最大值,并经过式4处理后得到处理后的样本。上述处理后所有特征区间均为[0-1]。在标签中,若一条连接记录正常,则标签为normal,否则为攻击的类型。KDD数据集攻击类型有4大类共32种,本文将其分为两类,即normal和attack,转为数字型即为01和10。
2.2 KDD数据集特征选择
由于KDD数据集共存在41个特征,部分特征值在大部分记录中均相同,对最终分类效果无太大影响,且增加了训练时间,所以本文采用随机森林对特征重要性进行排序,使用袋外数据错误率作为衡量指标,选出了12个重要性最高的特征,然后利用神经网络对数据访问记录进行分类。最终12个特征及权重如表1所示。
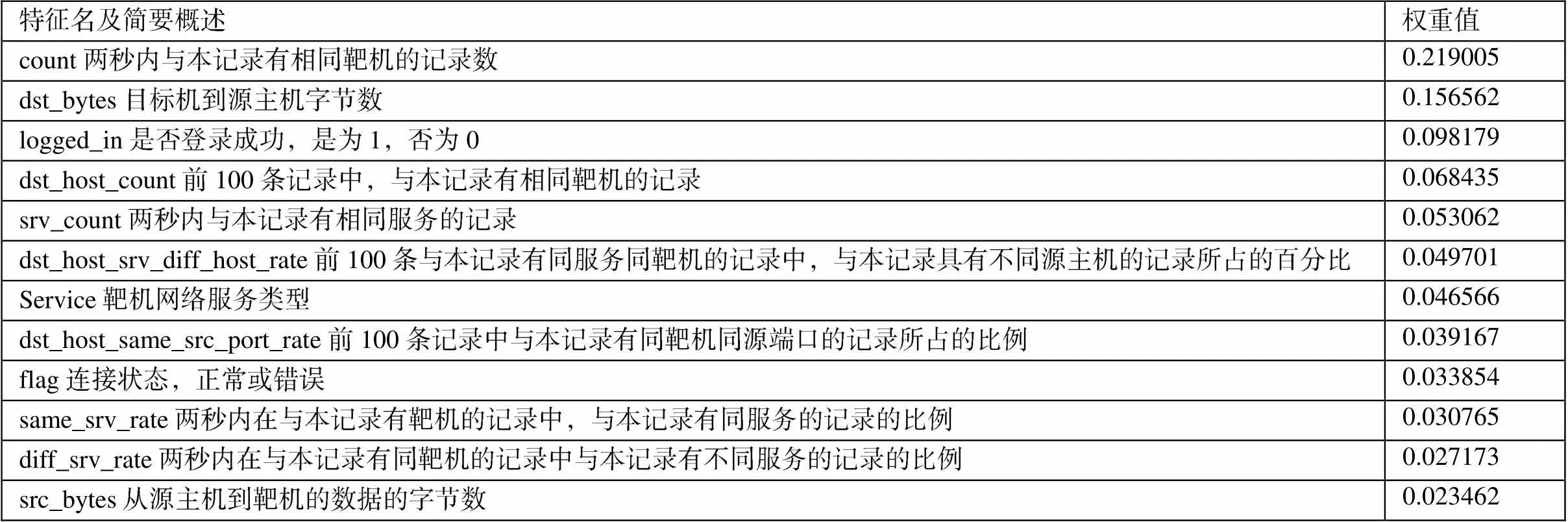
表1 特征选择后的十二个特征
2.3 深度神经网络设计
本文使用了深度神经网络,其中输入层为特征选择并处理后的12个值,中间为三个隐藏层,每个隐藏层有100个神经元。每个神经元在经过激活后均进行dropout处理,避免过拟合现象。最终输出为两个节点,并随后进行代价函数的计算。其中代价函数使用交叉熵计算,如式7所示。
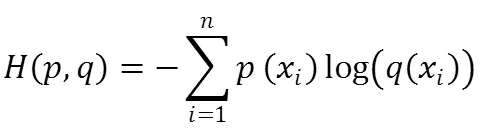
其中,为两个独立的概率分布,分别代表网络输出值与实际值。
网络结构如图1所示。第一列十二个圆为十二个输入神经元,中间三列每列为100个神经元,相邻列每个神经元之间都存在连接,最后一列为两个输出神经元。
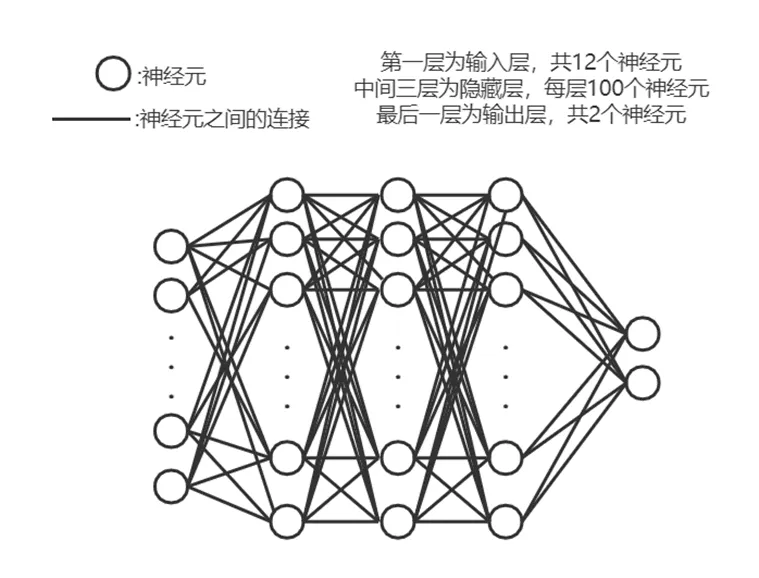
图1 网络结构
在实验设计初期,神经网络的激活函数为线性整流函数(ReLU),然而在训练过程中,经常出现损失函数不下降且神经网络中的参数得不到更新等情况。经排查后得知触发了Dying ReLU现象。在神经网络中,x为输入,w为神经网络的权重,神经元输出为z,经过ReLU后为a,H为损失函数,α为学习率。则神经网络的前向传播如式8,式9所示。x为来自上一层的经过激活后的神经元输出,w为当前隐藏层与下一层之间连接的权重。
z=w*x (8)
a=relu(z)=max(0,z) (9)
神经网络的反向传播中,需要求每层权重对应的梯度,并设置学习率不断调整权重。求梯度及权重的更新如式10,11。当一个巨大的梯度流过神经元且学习率较高时,会导致权重更新过大,造成对于任意输入x,网络的输出z小于0,经过激活函数后a为0,最终导致梯度恒为0,后期该权重都得不到更新,形成了神经元死亡的现象。
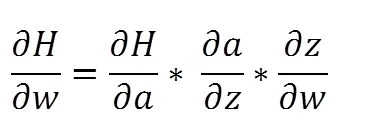
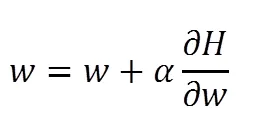
故经过多次失败后最终选用Leaky ReLU函数,不同于ReLU函数将所有小于0的输出设置为0,Leaky ReLU是给所有负值赋予一个斜率,从而保证后续的权重更新。
2.4 实验及数据分析
本次训练采用KDD1999 10%样本集,共40余万条,随机划分为3:7比例,分别为测试集与训练集。每次随机取100条记录为一个batch进行训练,并计算为一次迭代。由于样本集中正常访问与攻击的记录比例为2:8,并不平衡,故仅凭准确率无法有效评估模型的好坏。所以在训练中每达到一百次迭代,在测试集中随机抽取64条记录,进行一次准确率,精确率,召回率的计算。三个指标的计算公式如下所示:
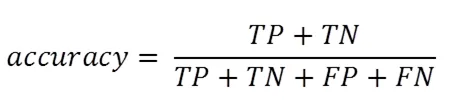
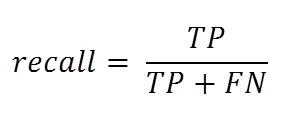
其中TP(True Positive)表示将正类预测为正类数,TN(True Negative)表示将负类预测为负类数,FP(False Positive)表示将负类预测为正类数,FN(False Negative)表示将正类预测为负类数。式12表示模型预测准确率,式13表示在预测为攻击的记录中,真实为攻击的比例,式14表示在所有标签为攻击的记录中,模型判定为攻击的记录数。如表2所示为训练的结果。

表2 训练结果
如图2、3、4、5所示为模型在训练过程中的准确率,精确率,召回率,损失函数曲线,其中横轴为迭代次数,纵轴为对应的指标。为了能更好的体现损失函数值的走势,损失函数进行了平滑处理,其中实线为平滑参数为0.5处理后的曲线,而虚线则为未经处理的曲线。从四张图可以看出召回率和精确率在开始时以较大幅度进行增长,在训练400次后开始缓慢增长,最终迭代2000次时,召回率和精确率均达到94%以上。而损失函数经过一次大幅度下降后便开始以小幅度变化,且总的趋势为减小最后趋近于不变。
在实际训练过程中,准确率,召回率等参数在开始时并非一直都为0.2左右,由于样本分布的不均匀,且训练开始时经过第一次神经网络后的一个batch通常表现为全部判定为攻击,或全部判定为正常访问,因此在训练开始时准确率有时会为20%左右,而有时为80%左右。然而即使训练开始准确率等参数为20%,模型的训练时间并没有太大的增加,事实上经多次验证,当训练开始准确率为20%左右时,在训练初期准确率会经过一段高速增长后会逐渐缓速增长。
(1)准确率曲线
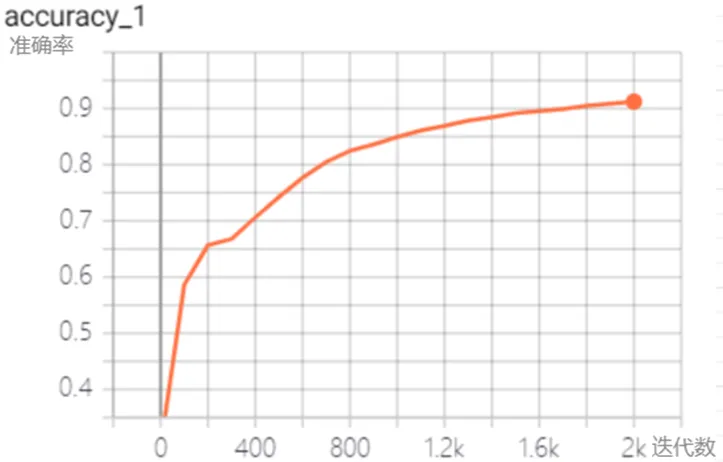
图2 准确率曲线
(2)精确率曲线
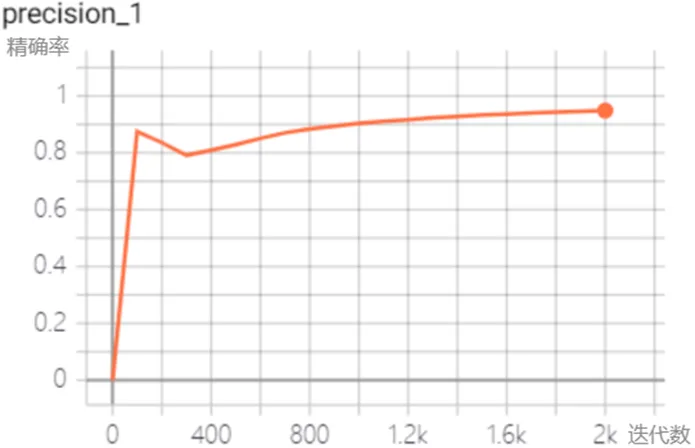
图3 精确率曲线
(3)召回率曲线
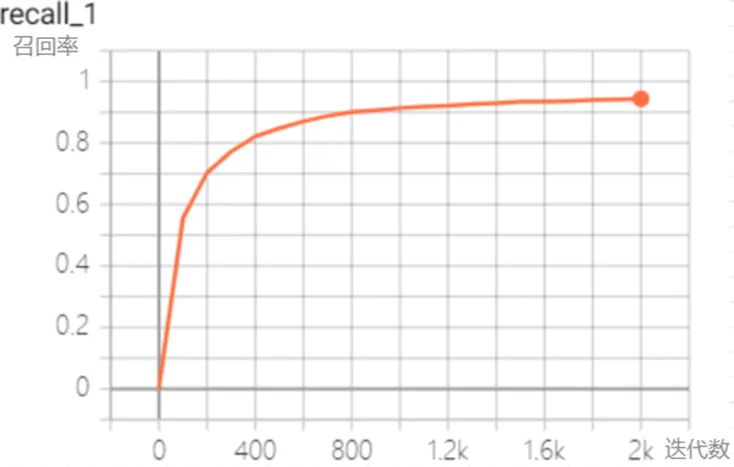
图4 召回率曲线
(4)损失函数曲线
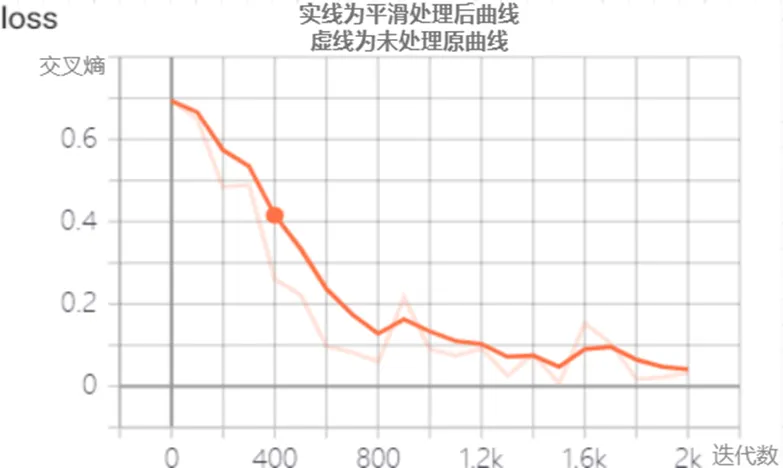
图5 损失函数曲线
3 结论
本文利用KDD1999数据集,对数据集中的数据进行标准化和归一化,通过该方法使数据集中所有数据的值都保持在0-1的范围内,避免了在后期训练过程中因特征值之间的差异过大而带来的问题。与此同时采用随机森林选出了12个权重最高的特征,大大减少了训练时间和运算量,同时在模型的实际应用中也减少了判断是否为恶意访问所需的时间。然后利用三层神经网络对数据进行了分类和预测,使用Leaky ReLU激活函数避免了大规模神经元死亡的结果,并使最终训练结果达到了较高的准确率和召回率。然而在构造随机森林进行特征选择时,由于数据集多,数量大,导致在特征选择时需要花费大量的时间。与此同时,在信息安全的实际应用中,攻击漏报的严重性要远高于攻击误报的严重性。因此在模型的训练过程中,需要刻意提高召回率,在保证高召回率的基础上对精确率进行提高。该问题涉及阈值的选择问题,在本实验中并未体现,是将来需要研究的问题之一。
[1]阮耀平,易江波,赵战生.计算机系统入侵检测模型与方法[J].计算机工程,1999(09):63-65.
[2]华辉有,陈启买,刘海,张阳,袁沛权.一种融合Kmeans和KNN的网络入侵检测算法[J].计算机科学,2016,43(03):158-162.
[3]杨昆朋. 基于深度学习的入侵检测[D].北京交通大学,2015.
[4]C. Xu,J. Shen,X. Du and F. Zhang,"An Intrusion Detection System Using a Deep Neural Network With Gated Recurrent Units," in IEEE Access,vol. 6,pp. 48697-48707, 2018.
[5]Z.Ma and A.Kaban,"K-Nearest-Neighbours with a novel similarity measure for intrusion detection," 2013 13th UK Workshop on Computational Intelligence (UKCI),Guildford, 2013,pp. 266-271.
猜你喜欢
现代电力(2022年2期)2022-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子产品世界(2021年8期)2021-01-16
健康体检与管理(2021年10期)2021-01-03
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
中国计算机报(2019年49期)2019-02-07
中国新闻周刊(2017年36期)2017-10-21
