
基于Python的招聘岗位数据分析系统的设计与实现
2020-10-13 09:37边倩王振铎库赵云
微型电脑应用 2020年9期
边倩 王振铎 库赵云

摘 要: 目前,网上数据呈现几何级数的增长,人们获得有效、准确信息的难度增大。有必要对数据进行合理的采集和分析,尤其是与人们工作有关的招聘数据的真实性和有效性。为了解决在职人员和广大高校毕业生获取满意的招聘岗位信息,利用Python对该信息进行收集和分析,势在必行。首先、以某招聘为例,爬取招聘数据,其次,从地区、行业、专业、热门岗位等维度进行数据分析,最后,利用可视化技术,将有效的数据展示给用户。经测试表明,该系统能够正常运行,数据可靠,能够为求职者提供准确的数据。
关键词: 招聘; 爬虫; 数据分析; Python
中图分类号: TP311 文献标志码: A
Abstract: At present, there is a geometric increase in online data, which makes more difficult for people to obtain effective and accurate information. It is necessary to collect and analyze the data reasonably. In particular, the authenticity and validity of hiring data are related to peoples jobs. In order to solve the problem that the in-service personnel and the majority of college graduates obtain satisfactory recruitment post information, this paper presents to collect and analyze theinformation by using Python. Firstly, we take a certain recruitment as an example to crawl the recruitment data. Secondly, data analysis is conductedfrom the dimensions of region, industry, major and popular post. Finally, visualization technologyis used to display effective data to users. The test shows that the prototype system can work normally, the data arereliable and can provide accurate data for job seekers.
Key words: recruitment; crap; data analysis; Python
0 引言
随着互联网的迅猛发展,网络数据已经进入大数据时代。传统的搜索引擎尽管解决了信息搜索问题,但无法进行有效的数据分析和优质资源的获取。并且,人们的需求不同,数据的要求也不同。为了解决这一问题,定向抓取数据的爬虫诞生了。它的诞生把人们从重复性的劳动中解放出来,节约人们宝贵的时间。
对于毕业班的大学生以及想重新择业的人,上网快速找到合适的工作,无疑是急需的。而如今的招聘网站信息多,想要获取有效的信息需要的时间太长。针对以上不足,有必要通过爬虫技术,帮助求职者在杂乱无序的数据中寻找有用的数据,科学分析,缩短求职者找工作的时间成本,帮助求职者快速择业。笔者在参考文献[2-7]后,设计和开发了本系统。
1 网络爬虫的原理和步骤
1.1 爬虫的原理
网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。爬虫对某一站点访问,如果可以访问就下载其中的网页内容,并且通过爬虫解析模块解析得到的网页链接,把这些链接作为之后的抓取目标,并且在整个过程中完全不依赖用户,自动运行[1]。若不能访问则根据爬虫预先设定的策略进行下一个URL的访问。在整个过程中爬虫会自动进行异步处理数据请求,返回网页的抓取数据。在整个的爬虫运行之前,用户都可以自定义的添加代理,伪装请求头以便更好地获取网页数据。
1.2 爬虫的步骤
数据抓取的工作流程是:首先,通過Http向目标站点发送请求,在请求的时候,如果服务器返回200状态码,则表示可以进行数据抓取;继而根据预设的抓取规则将得到的内容进行解析保存处理。如果返回的是错误的状态码,系统就请求下一个链接。直到将URL LIST遍历完,工作流程如图1所示。
1.3 爬取策略
在爬虫系统中,因为涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。爬虫主要采取两种抓取策略,深度优先和广度优先。采用这两种策略得到的结果也不一样。
其中,深度优先主要是从一个链接开始一个一个的往里深入,直到整个的这一链接路线完成之后才进行下一层URL的爬取。这种采集方式主要强调的是,抓取数据的深度,抓取顺序1,2,3,4,5,6,7,如图2所示。
爬虫采用的广度优先算法主要是完成当前层的URL后才进行下一阶段的URL的获取。这种主要是为了更多的获取到多样的数据信息,数据的深度相对前者不够,顺序1,2,3,4,5,6,7,如图3所示。
2 系统设计
2.1 功能设计
本系统主要分为爬取数据、数据存储和WEB数据分析和显示三个模块,WEB模块依赖于爬虫模块。爬虫模块由许多页面处理模块组成,WEB模块在提取了爬虫数据后主要进行的是数据分析。本文的系统结构设计,如图4所示。
2.2 数据库设计
数据库设计主要包含用于数据分析的字段,在抓取数据过程中正则获取到数据库中所依赖的信息。数据库字段表如表1所示。
2.3 开发工具
系统开发平台:JetBrains PyCharm 5.0.3
程序语言:Python 3.7
框架:Scrapy1.5.1
系统运行环境:Windows10 64位
数据库:Mysql 5.5
3 招聘爬虫系统的实现
系统选择某招聘网站作为数据源。系统主要功能是实现对招聘岗位数据的爬取,主要涉及招聘信息中的所在城市、岗位名称、薪资、福利、公司名称、发布时间等信息。
3.1 网页数据的爬取
网页抓取模块可以说是爬虫的核心,它定义了爬虫的抓取规则,请求的数据参数以及在整个的抓取过程中页面的等待时间,页面的页数。其中,header定义了它的请求头,page定义了它的初始页数,start_requests函数定义了它的初始请求parse定义了它随后的抓取规则。抓取数据如图5所示。
3.2 数据存储模块
由于爬虫抓取的数据量较大,为了高效地进行数据分析,采用Excel,Json的方式效率明显降低。所以,采用数据库技术进行存储是必要的。数据存储模块主要完成将爬虫抓取数据持久化到MYSQL数据库中。
3.3 数据可视化
为了让数据更加的直观,系统采用ECharts图表方式,增强用户的视觉效果。ECharts是一款由百度前端技术部开发的,基于Javascript的数据可视化图表库,提供直观,生动,可交互,可个性化定制的数据可视化图表[8]。
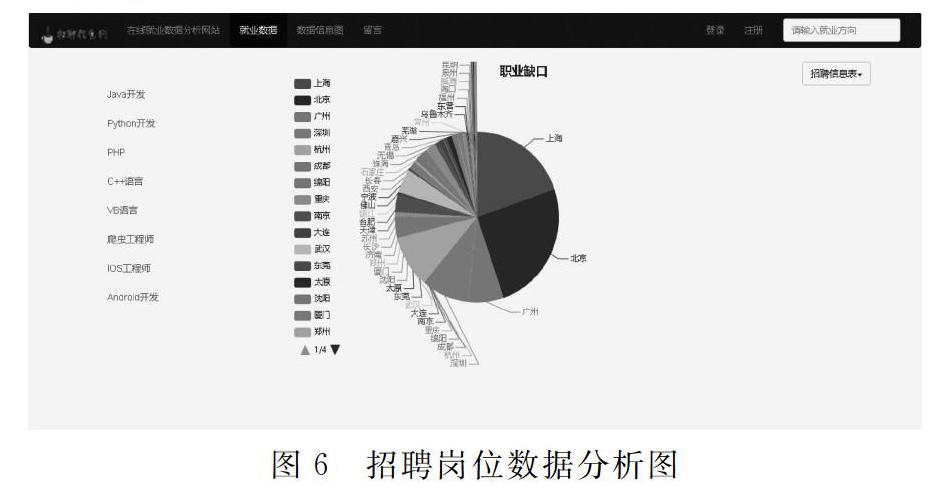
在系统前端数据可视化时,首先是将echarts.min.js放在static/js下的目录。然后在模板页中引用{% static 'js/echarts.min.js'%}。最后在页面中调用ECHARTS。通过集成ECHARTS可以很方便的去实现数据分析图表,直观的观察数据信息,得出更加真实的对比值。数据分析结果如图6所示。
4 总结
系统的设计,旨在为求职者提供有益的数据,帮助求职者更快的找到心仪的工作。从数据的爬取、存储和数据分析给出了设计和实现步骤,为相关爬虫项目提供了借鉴。
参考文献
[1] 王芳.基于Python的招聘网站信息爬取与数据分析[J].信息技术与网络安全,2019,38(8):42-46.
[2] 赵绿草,饶佳冬.基于python的二手房数据爬取及分析[J].电脑知识与技术,2019,15(19):1-3.
[3] 赵亮,赖研,仝鑫.基于Python的微博用户分析系统设计与实现[J].计算机产品与流通,2019(6):282-283.
[4] 廖勇毅,丁怡心.基于Python的股票定向爬蟲实现[J].电脑编程技巧与维护,2019(5):45-46.
[5] 檀冬宇.基于Python的大众点评网数据抓取技术研究[J].计算机产品与流通,2019(5):116.
[6] 程增辉,夏林旭,刘茂福.基于Python的健康数据爬虫设计与实现[J].软件导刊,2019,18(2):60-63.
[7] 崔玉娇,孙结冰,祁晓波,等.基于Python的51-job数据抓取程序设计[J].无线电通信技术,2018,44(4):416-419.
[8] 贺路路,阮晓龙.高校学生考试成绩的数据分析模式与可视化研究[J].计算机时代,2019(9):50-52.
(收稿日期: 2019.10.08)
猜你喜欢
现代信息科技(2021年21期)2021-05-07
计算机与网络(2020年11期)2020-07-29
智能计算机与应用(2018年5期)2018-10-20
电脑知识与技术·经验技巧(2018年1期)2018-05-30
经营者(2016年19期)2016-12-23
中国经贸(2016年20期)2016-12-20
中国市场(2016年36期)2016-10-19
商场现代化(2016年22期)2016-10-18
