
辽阳市参考作物腾发量预测
2020-10-12 12:07李选彧
黑龙江水利科技 2020年9期
李选彧
(辽宁省辽阳水文局,辽宁 辽阳 111000)
参考作物腾发量(ET0)的精确预测将直接影响着灌溉方案的设计和植物的生长,对促进区域农业发展发挥着关键作用。对此,国内外学者从不同角度开展了大量研究,如常用的灰色系统、时间序列和回归分析等定量预测方法。其中,所需资料较少的灰色系统法,实际应用时其预测精度较低;时间序列法预测未来变化趋势的主要依据为已有的ET0数据,其预测精度差且无法反映预测结果受外部因素的影响;回归分析法的建模比较困难且运算量大,一般不适用于非线性系统。目前,普遍采用的计算方法是经典Peman-Monteith公式,然而该方法的运算过程十分复杂,加之准确获取相关气象数据的难度较大,使得其实用性不高[1]。
近年来,计算机模拟技术的快速发展推动了神经网络理论的研究,形成的BP神经网络模型现已广泛应用于ET0的预测分析。然而,实际应用过程中该算法存在阈值和初始权重过于敏感的现象,并且收敛速度较为缓慢的情况比较常见。相对而言,对于全局的寻优PSO算法表现出明显的优势,其计算过程简单且无需过多的参数设置。为更好的优化BP网络的初始连接权重诸多学者引入了PSO算法,从而增强网络的自适应学习能力和泛化能力。例如,吴复昌等以灌区输水调度为例,提出了能够快速获取全局最优解的PSO算法,通过模型预测保证灌溉效率的提升;张志政等以西安地区数据为例,构建了预测参考作物腾发量的PSO-BP神经网络模型,通过排列不同的影响因素,探究了预测精度与多种因素组合方式的相互关系。然而,传统的PSO算法受其自身条件限制,通常存在过早收敛和预测结果精度偏低的情况[2-4]。
为降低PSO算法易陷入局部极值的概率提出一种非线性权重递减策略,并以辽阳地区为例验证了改进PSO-BP算法的实用性,结果显示与PSO-BP模型、BP模型相比ADAPPSO-BP模型具有更高的ET0预测精度。
1 PSO-BP预测模型
1.1 改进的PSO算法
一般条件下,在迭代运算过程中PSO算法的每个粒子均会不断聚集于整个群体及其自身纪录的最优历史位置,从而快速出现粒子群趋同效应。该条件下,极易发生停滞、过早收敛和局部极值的现象。针对此类问题,标准PSO算法可利用线性递减的惯性权重有效应对这种情况,选用以下公式反映随迭代次数W的变化,即:
(1)
式中:Wmin、Wmax为惯性权重最小和最大值;t、tmax为PSO算法的实际次数和最大运行次数。
通常情况下,在Wmin取0.4、Wmax取0.9时能够达到效果最优。实际上,对于自身收敛能力的调节线性递减PSO算法发挥着一定成效,若该算法在计算初期未能确定最佳点,则其局部收敛能力随着W值的持续下降不断增强,很容易产生局部最优的现象[5-7]。此外,若可以准确的探测次好点,并且算法初期的W值取小,则其最佳点也能快速的确定,然而算法的收敛速度会随W长期的线性递减趋势而延缓。所以,考虑利用非线性递减函数自适应动态调整W,从而解决易陷入早熟收敛的全局寻优问题,对此利用公式(2)求解惯性权重,即:
W=Wmax-(t/tmax)2×0.3
(2)
由上式可知,在一定程度上非线性递减函数可以减缓惯性权重于算法初期持续减小的概率,以此维持较长时间内惯性权重取较大值,从而实现更广区域的探索,最大程度的降低出现局部极值的概率。W值在算法后期也会快速下降,并显著增强粒子的搜索能力,全局最优值的寻优概率也会进一步的提升[8-10]。
1.2 自适应PSO-BP优化网络
为解决传统PSO算法存在的局限性问题以及增强BP网络的预测精度,结合改进的PSO算法建立ADAPPSO-BP模型,并预测分析区域ET0变化特征,其实现流程为:
步骤1:粒子群维数的初始化。结合BP网络的自身结构确定PSO粒子群的待优化维数,即:
D=(m+1)n+(n+1)p
(3)
式中:m、n、p为BP神经网络的输入层、隐含层和输出层所含节点数。
步骤2:初始化粒子群有关参数。设定粒子数N取20,将BP网络的权阈值上、下浮动50%确定粒子的位置范围,并以位置的限制区域作为粒子速度的约束条件;此外,设定学习因子Wmax取0.7、tmax取100,c1=c2=2,设W的取值区间0.4-0.7。
(4)
步骤4:粒子速度与位置的更新。采用适应度函数对比个体极值与粒子值,若粒子自身的预测值更小则作为新的极值;然后比较全局极值与个体极值,若小于该极值则视为全局新的极值。粒子的位置与速度更新利用下式实现,其表达式为:
Xt+1=Xt+Vt+1
(5)
Vt+1=WVt+c1r1(pbest-Xt)+c2r2(gbest-Xt)
(6)
式中:Vt、Xt代表粒子的速度与实际位置;r1=r2代表区间[0,1]内的随机数,其它字母含义同上。
步骤5:终止条件的判断。若算法满足判别条件,则所求的全局最优解位置就是BP网络的最佳权重及其阈值。最终,在BP神经网络中输入最佳权重及其阈值,完成网络的预测模拟并搭建优化的APAPPSO-BP模型,其整体实现流程见图1。
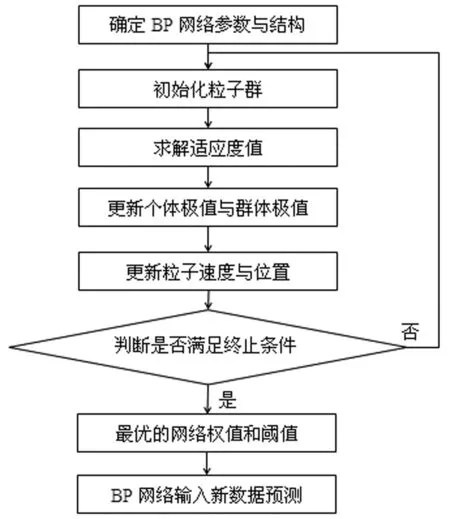
图1 模型的运算流程
2 结果与分析
2.1 数据来源
文章实验数据包括平均相对湿度、日照时长、逐日风速、最低、最高和平均气温6个气象资料,数据来源于2016.01.01-2018.06.16辽阳站地面气候资料日值数据,中国气象数据网提供初始数据,并对参考作物腾发量(ET0)利用修正的Peman-Monteith公式确定,数据资料如表1。
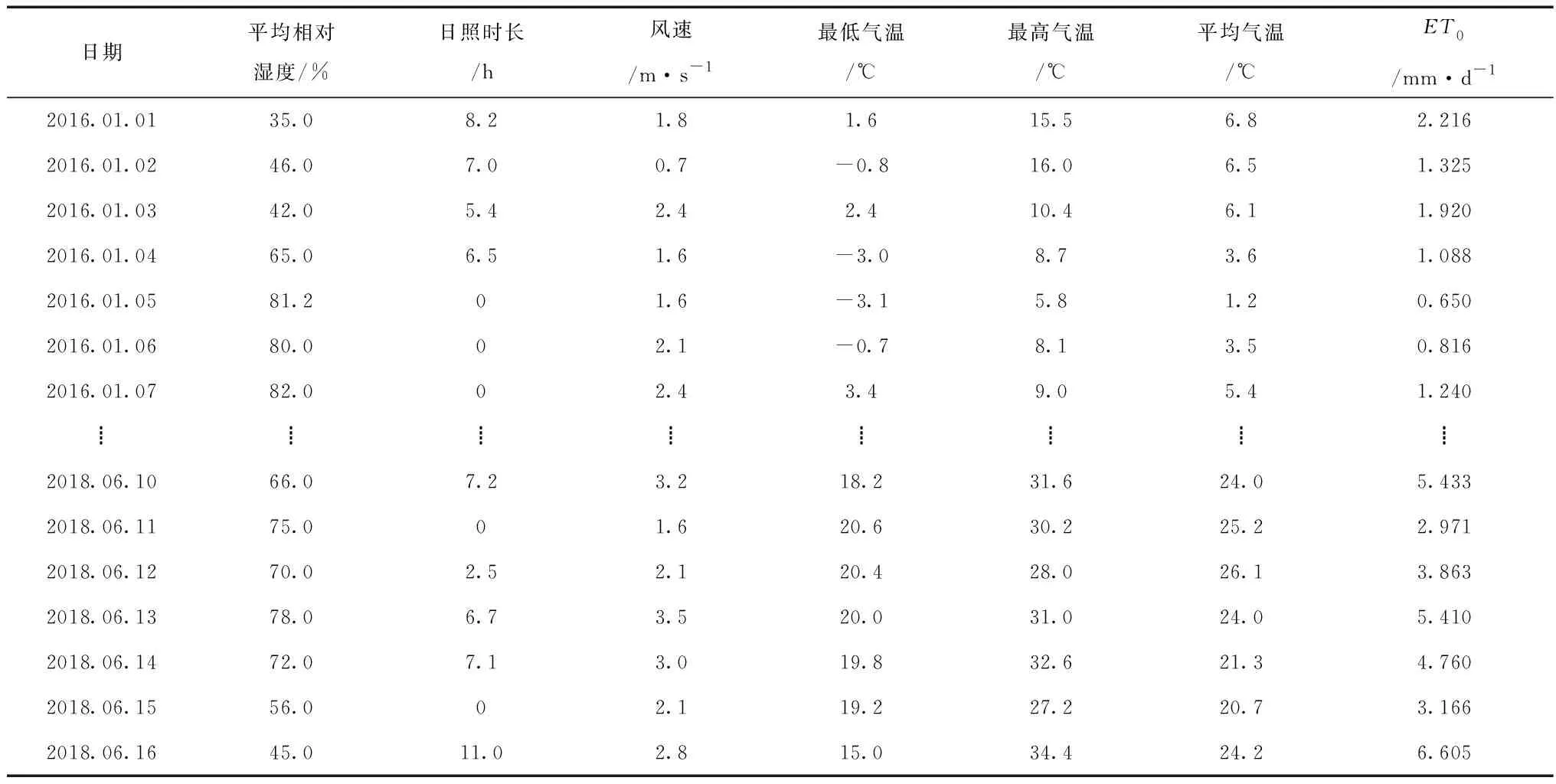
表1 辽阳地区气象数据与参考作物腾发量(ET0)
2.2 特征值筛选变量
对ET0利用修正的Peman-Monteith公式计算时涉及的参数较多,且不同参数之间具有彼此相关的信息,且独立性较差,BP网络模型不宜直接模拟预测。文章考虑将BP神经网络与平均影响值(MIV)相耦合,建模时选择能够显著影响ET0的参数[11-13]。
观察不同变量在网络模型训练中发生的改变,这也是MIV确定预测结果受参数影响程度的主要依据,其主要流程为:①采用训练好的BP网络输入全部的变量,并以减少10%和增加10%调整每个变量,由此获取2个新变量A1、A2。②向训练好的神经网络输入新的数据A1、A2,并生成B1、B2两组预测值,二者之和、之差即为平均影响值(MIV)与影响变化值(IV)。其中,MIV的正负代表影响的方向,绝对值大小代表较因变量各类参数实际产生的影响程度,该条件下的建模参数应具有较大的MIV绝对值,由此完成自变量的合理选择[14-16]。根据MIV变量筛选流程对6个影响ET0的变量进行分析,如表2所示。

表2 变量的MIV特征值
参数变量对网络实际输出的影响程度随MIV绝对值的增大而增加,从表2看出平均相对湿度、平均气温、风速对ET0预测结果的影响显著,这3项参数的贡献率达到91.26%。因此,网络模型的输入变量选择此3个参数,并将网络输出变量设定为ET0。
2.3 BP网络结构
根据以上分析结果BP网络的输入和输出变量有3个、1个,而隐含层节点数的确定迄今尚未形成明确的方法。一般地,采用经验公式粗略的划分隐层节点数,并逐一验证网络模型的适用性,选择的隐含层节点数应具有最小的预测误差,经验公式如下:
(1)
式中:m、n为隐含层节点数和输入变量的个数;a取值范围为[0,1]。将隐含层阶段数m利用公式(7)确定,其取值区间为[2,12],通过实验逐一验证此区间的整数值,其误差输出见图2。研究表明,隐含层节点数取6时BP神经网络的误差最小,从而构造3-6-1的BP网络结构[17]。

图2 模拟预测误差分析
2.4 PSO-BP的ET0预测
充分考虑区域实际情况,对参考作物腾发量(ET0)利用ADAPPSO-BP、PSO-BP和BP模型预测。其中,BP模型的隐含层和输出层传递函数选用tansig、purelin函数,网络结构为3-6-1,设定迭代运算次数1000次,学习速率0.01。模型的训练样本和检验样本选择前675组、后225组实验数据,由此验证模型预测情况。参考作物腾发量(ET0)实际结果与3种模型预测结果,其对比图如图3。另外,为更好的突出不同模型的预测效果,采用均方误差(MSE)、平均绝对误差(MAE)、平均相对误差(MRE)、决定系数(R2)4项指标作为模型评价标准,其表达式为:

(8)

(9)

(10)

(11)
参考作物腾发量(ET0)预测曲线,见图3。
从图3可知,整体上最接近参考作物腾发量(ET0)真实值的为ADAPPSO-BP模型预测值,预测结果最差的为BP模型,PSO-BP模型的精准度居中。可见,对于提高BP模型预测精度PSO算法发挥着明显成效,但受其自身条件限制,使得真实值与预测的突变结果存在很大的偏差,对于此类问题ADAPPSO-BP算法能够较好的解决。

图3 参考作物腾发量(ET0)预测曲线
不同模型的评价指标对比,见表3。
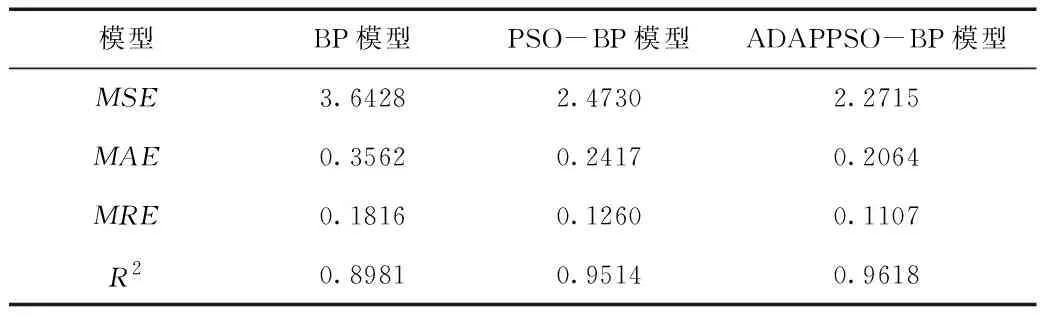
表3 不同模型的评价指标对比
由表3可知,PSO-BP模型、BP模型的MRE、MAE、MSE均大于ADAPPSO-BP模型的0.1107、0.2064、2.2715,并且PSO-BP模型、BP模型的R2均值小于ADAPPSO-BP模型的0.9618,可见这3种模型中ADAPPSO-BP模型具有最小的预测误差和最高的拟合度。与PSO-BP算法相比ADAPPSO-BP模型的MRE、MAE、MSE减少了12.14%、14.60%、8.15%,由此表明较传统的PSO算法改进的算法能够显著提升预测精度。
3 结 论
对于实际应用过程中标准PSO算法易陷入局部极值的问题,结合相关资料提出了一种能够减少陷入局部极值概率的非线性递减权重策略(ADAPPSO),并对影响ET0的主要因素利用平均影响值法筛选,并构建能够准确预测ET0的ADAPPSO-BP模型。结果表明,较PSO-BP算法ADAPPSO-BP模型可进一步提高ET0预测精度,在ET0预测过程中能够克服BP神经网络精度较低的缺陷,可为新型、高效、节能灌溉技术的开发提供科学指导。
猜你喜欢
心理学报(2022年5期)2022-05-16
昆明医科大学学报(2022年1期)2022-02-28
新世纪智能(数学备考)(2021年10期)2021-12-21
新世纪智能(数学备考)(2021年10期)2021-12-21
新世纪智能(数学备考)(2020年10期)2021-01-04
当代陕西(2020年17期)2020-10-28
语数外学习·高中版中旬(2020年10期)2020-09-10
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
人大建设(2018年5期)2018-08-16
