
科学合作网络姓名消歧问题研究*
2020-10-09 01:12:26王曼玲宗晓丽韩红旗
甘肃科技 2020年16期
张 龙 ,付 媛 ,王曼玲 ,宗晓丽 ,韩红旗
(1.甘肃省科学技术情报研究所,甘肃 兰州 730000;2.中国科学技术信息研究所,北京 海淀100038;3.西北师范大学,甘肃 兰州 730070;4.甘肃政法学院,甘肃 兰州 730070)
1 概述
目前,使用搜索引擎查询自己所需要的信息已经成为现代人工作和生活必不可少的一部分,而从海量数据中高效快速地返回用户感兴趣的内容成为信息检索的重要挑战,同时用户对搜索引擎的查准率和查全率也提出了更高的要求。搜索人物姓名相关信息是用户搜索的重要方式之一,也是用户在互联网搜索的主要目的之一,据统计在搜索引擎查询中对人名的搜索和查询请求约占5%~10%,是信息查找的关键点。然而,据美国人口调查报告显示,有10亿人却仅仅用了90000个不同的名字。在我国,重名现象也非常严重,全国公民身份信息系统中姓名为“张伟”的就有299025人。重名现象的普遍性导致了互联网文本中姓名歧义现象严重,搜索结果并未对有歧义的人名进行有效的信息组织,用户需要花费大量时间从重名人物中筛选出自己感兴趣的人物信息。如何挖掘到包含有相同姓名文本之间的联系,有效地解决姓名歧义问题,并提供可视化展示,是大数据时代人工智能领域里自然语言处理所面临的重要挑战。为此,姓名消歧成为了近年来国内外学者的研究热点之一[1]。当前科研文献数据量急速增长,如何有效地消除文献著者中文姓名歧义尤为重要。
2 姓名消歧方案设计
2.1 消歧方案基本流程
文献著者姓名消歧是将同名作者发表的文献对应到相应人物实体的过程,该过程也是一篇文献被若干个同名作者认领的过程,最终目的是每个作者认领各自的作品,对于无人认领的作品,在数据库中新增该同名作者。从文献特征消歧顺序和语义指纹的认领决策两个方面进行优化,设计了以下基于语义指纹的姓名消歧方案,基本流程如图1所示。

图1 姓名消歧方案基本流程
2.2 语义指纹生成方案设计
以文本特征为基础,将高维的对象转换为二进制码,相似对象拥有相似的指纹信息,其中Charikar提出的SimHash算法被认为是生成指纹最好的算法[2]。SimHash算法把文本特征转化为二进制指纹值,指纹距离的大小除了能表示原始内容是否相等的信息外,还能通过指纹距离大小判断原始文本的相似度,进行文本相似度计算,降维得到的64位指纹的相似度能够同原始文本特征的相似度保持一致,体现了语义指纹的语义性。语义指纹生成流程如图2所示,输入PDF格式的文献文本,输出二进制指纹值,指纹生成过程主要包括6个步骤:格式转换、中文分词、求Hash值、Hash值加权、结果合并、降维,SimHash算法原理如图3所示。
中文分词:对文献全文文本进行分词,去除停用词,作为文本特征,得到有效的特征向量,并根据TF-IDF确定特征词的权重,词语的权重代表词的重要程度,权重越大代表词越重要。
求Hash值:对每一个特征,利用Hash函数计算特征向量的Hash值,得到二进制数表示的32位或64位签名,将字符串转化为二进制数。
Hash值加权:对特征向量的Hash值加权,如果64位二进制哈希值的某一位数为1,则这一位Hash值加权为正权值,如果64位二进制哈希值的某一位数为0,则这一位Hash值加权为负权值,得到每个特征向量的Hash值加权。
合并:将各个特征向量的Hash值加权结果进行累加,得到一个序列串。
降维:对特征向量的Hash值加权累加结果的序列串进行降维,每一位如果大于0,则置为1,否则变为0,从而得到该文本的SimHash指纹值。

图2 语义指纹生成方案设计

图3 SimHash算法原理
2.3 指纹比较方案设计
选择合著者特征、作者机构特征和文本语义指纹特征,融合设计了指纹比较器。在综合特征姓名消歧指纹比较器中,语义指纹相似性通过海明距离度量,即两个指纹值相差的位数[3];文献合著者和作者机构通过字符串匹配;新论文的指纹fi与库中已分类的作者指纹fx作对比,并合成一个H(i,x)三元组,前两个分量分别为合著者相似度、作者单位相似度,分量的值在0与1之间,0表示合著者或者作者单位不同,1表示有相同的合著者,作者单位相同,第三个分量为文本语义指纹距离。指纹比较器如图4所示,工作步骤如下:
1)当两篇同名作者的文献有相同姓名的合著者时,这两篇文献确定为同一个作者,将该论文分配给该作者;
2)当两篇同名作者的文献无相同的合著者但作者单位具有较大的相似性时,比较两篇文献的指纹距离,当指纹距离小于δ3时,这两篇文献确定为同一个作者,将该论文分配给该作者;
3)当两篇文献既无相同的合著者,也不属于同一个作者单位时,则通过两篇文献的指纹相似度来判断,当指纹距离小于δ1时,这两篇文献确定为同一个作者,将该论文分配给该作者,当指纹距离在(δ1,δ2)之间,则无法确定为同一个作者,需要进行下一步的认领决策。

图4 指纹比较方案设计
2.4 认领决策方案设计
一篇新的论文指纹与同名作者的N篇文献的指纹作对比后得到了N个指纹距离,认领决策器开始工作,图5为一篇新论文找一个作者认领的过程。
1)当比较结果指纹距离小于δ1时,两篇文献确定为同一个作者,将该论文分配给该作者;
2)比较结果指纹距离输出值 H(x)在(δ1,δ2)(δ1,δ2为设定的阈值,本研究实验中 δ1=18,δ2=25)的个数为 n,若 n/N>24%,则决策器输出为Yes,则该论文被该作者认领;
3)否则,决策器输出为No。

图5 认领决策方案设计
2.5 作品指派方案设计
一篇新的文献在每一个作者认领后,可能存在如下结果,如图6所示:
1)当只有一位作者认领时,将该论文指派为该作者的作品;
2)当存在两位或两位以上作者认领该文献时,由争议仲裁器仲裁,仲裁后将该论文指派给其中的一位作者;
3)当无人认领该文献时,该文献是一位新的同名作者的作品,将其指派给新的作者。
当一篇文献同时被几位作者认领,出现争议时,争议仲裁器工作过程如下:
当存在多个认领作者时,仲裁器才起作用,不失一般性,假设作者a1和a2竞争,考察两个作者的决策器中各比较器的输出值,各个指纹距离和的平均值[4]。若∑H(a1)/Na1<∑H(a2)/Na2,则将该论文指派给作者a1,否则指派给a2。

图6 作品指派方案设计
3 消歧实验数据构建
文献数据库中海量的文献数据,并不适合直接用来测试消歧方法,需要选取有代表性的部分文献数据,构建文献测试数据样本集,来评价姓名消歧方法的有效性,本研究的文献数据来源于万方数据。文献中一般包含标题、作者、合著者、作者机构、期刊、日期、摘要、关键词、作者邮箱、全文等特征,但并非所有特征都适应于姓名消歧,需要筛选出具有较强消歧能力的特征[5]。为了验证姓名消歧方法的有效性,需构建一个包含待消歧作者姓名的文献数据集,应该具有以下特征:
1)首先选取重名较多的常用作者名的文献,同时也要包含使用频率较少的作者名的文献;
2)不同作者发表的文献数不同,既包含发表文献数量多的作者,也包含发表文献数量较少的作者;
3)需要涵盖全面的合著类型文献,既要包含合著文献,也要包含作者独著文献;
4)需要涵盖不同的作者单位类型,有的作者所属单位只有一个,有的作者在多个单位就职,发表的多篇文献中的所属单位可能有多个;
5)作者发表文献领域的分布,有的作者所发表的文献属于一个研究领域,而有的作者发表的文献涉及多个领域。
综合上述条件,构建了具有代表性的文献数据集。在万方数据中选取作者名为“李建军”、“李军”、“王琳”等7个名字,下载全文PDF格式数据845条。每个作者名代表了一类型的作者,如“李建军”代表的是重名作者较多的一类,本数据集中共包含该姓名的实际作者数为14,且包括了合著者文献和作者独著文献。“王伟”也是重名作者较多的一类,本数据集中共包含该姓名的实际作者数为9人,其中同属于大连理工大学的就有3人,其中的一个作者“王伟”同时在同济大学土木工程防灾国家重点实验室、上海岩石工程勘察设计研究院以及上海市闵行区建设工程安全质量监督站兼职,是一个作者属于多个机构的类型。“吴雁林”代表个性化的辨识度较高的重名较少作者名,本测试集中仅包含该姓名的实际作者数为3,三人文献数比较均衡。“张强”代表了少数作者包含较多文献,其余重名作者所占文献数较少的类型,本测试集中属于该姓名的实际作者数为10人,北京理工大学的张强老师的文献所占比例高达1/4,属于文献占比不均衡的一类。本研究构建的文献数据样本共标注了7个不同名字,分属于68个不同的作者,见表1。

表1 文献数据测试样本集
文献数据测试样本集分为六个类型:重名较多型、生僻名型、文献占比不均型、文献占比均衡型、同一机构型、文献稀疏型。文献占比不均型指少数作者所占文献占大多数,其余作者占少数文献,在文献数据库中大多数重名都属于这种情况。文献占比均衡型指属于每个作者的文献数占比均匀。同一机构型指重名的不同作者属于同一机构。有的作者包含多种类型,如“张强”同时属于重名较多型和文献占比不均型。如图7为各个类型所占比例。

图7 数据类型比例
4 姓名消歧实验及结论
实验数据源为之前构建的文献数据集的测试数据,本实验在Windows7操作系统下开发,各模块采用Java编程语言编写,编译环境为eclipse,JDK1.8,利用MySQL数据库存储,并使用了较权威的汉语分词系统NLPIR进行分词,所有文献以PDF格式存储。采用准确率、召回率和F值对基于语义指纹的综合特征姓名消歧方法进行评估。实验结果见表2,综合特征和单特征消歧对比如图8所示。
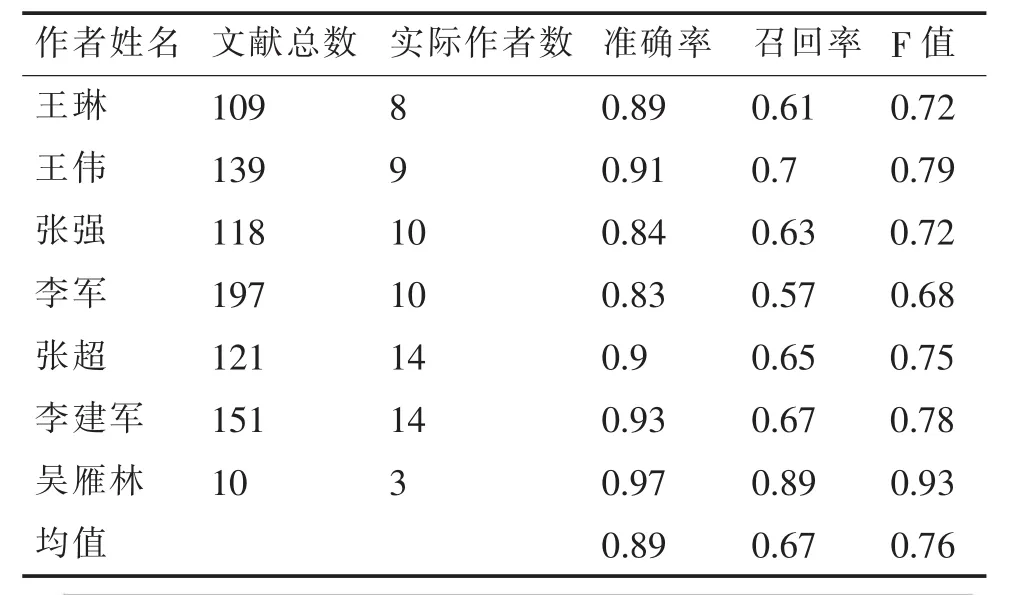
表2 基于语义指纹的综合特征姓名消歧实验结果

图8 综合特征和单特征姓名消歧对比
由图8可知,基于语义指纹的综合特征姓名消歧方法在整体效果上明显好于独立特征的姓名消歧方法,主要表现在综合特征消歧的较高召回率上。虽然合著者特征和作者单位特征在可以达到较高的准确率,但是召回率却很低,整体消歧效果并不好。
指纹单特征姓名消歧的准确率较低而召回率较高,前者是将属于一个作者的多篇文献分为多个作者,而后者是将几个不同作者的文献归为一个作者,所以几个特征可以进行优势互补。基于语义指纹的文献著者姓名消歧方法使整体效果有所提升和改善,但准确率比合著者单特征和作者单位单特征消歧低。综合特征姓名消歧,避免了只从合著者、作者单位、语义指纹,单方面的局限性,造成的消歧结果出现较低的召回率或者较低的准确率,同时融合了独立特征的消歧结果,有效地提高了姓名消歧的召回率,也确保了相对较高的准确率。
猜你喜欢
计算机与数字工程(2021年12期)2022-01-15 06:24:02
智能制造(2021年4期)2021-11-04 08:54:28
建材发展导向(2021年6期)2021-06-09 05:57:14
装备制造技术(2020年9期)2021-01-26 00:15:30
艺术品鉴(2020年11期)2020-12-28 01:36:56
哈尔滨工程大学学报(2020年8期)2020-11-13 01:53:32
下一代英才(酷炫少年)(2018年4期)2018-04-28 08:29:31
电脑与电信(2018年12期)2018-03-23 02:37:20
初中生世界·九年级(2017年8期)2017-09-06 09:40:36
海外英语(2013年1期)2013-08-27 09:36:04
