
基于YOLO 算法的行人检测
2020-09-29 06:54付云霞
科学技术创新 2020年29期
付云霞
(成都理工大学,四川 成都610059)
1 概述
用于行人检测的算法由最初的传统目标检测算法慢慢演进到基于深度学习的方法,这些算法在检测方面都有不错的效果。目前常用的方法有:HOG[1]、SIFT[2]、R-CNN[3]、Fast R-CNN[4]、Faster R-CNN[5]、YOLO 系列等。由Redmon 等[6]提出的YOLO 和YOLOv2 算法,由于检测速度相对其他算法较快,从而被广泛的应用于行人检测中。即便如此,行人检测算法当下仍存在误检率较高、实时性比较差等问题。下图为一些在目标检测中常用的算法。

2 YOLO 算法
YOLOv1 在检测速度方面与其他算法相比有一定的提升,但缺陷也较多,主要体现在目标定位的准确度较低、针对小目标其检测效果相对较差、计算量大。YOLOv2 针对YOLOv1 的缺陷,进行了一些改进,在检测上有了一定的提升,但仍然不够。后YOLOv3 在YOLOv2 上做了进一步的改进,实现多尺度检测、修改了损失函数和anchor box 的数目,改进了基础特征提取网络。不仅保证了速度,还提高小目标的检测精度。
下图为文献[7]给出的网络结构图。
3 卷积神经网络
YOLO 主要依靠卷积神经网络[8]来完成。该网络是一个多隐层的人工神经网络,由大量卷积单元所组成的卷积层是卷积神经网络中的重要组成部件,大部分计算量由它承担,也是包含参数最多的地方。以下将对卷积层进行简介。
卷积层的目标特征借助卷积运算来提取,提取目标特征可理解为f 和g 生成第三个函数的数学算子,代表f 与g 的重叠面积,g 会经过翻转、平移,演算过程如下:

积分形式:

记图像为 f( x ,y) , 二维卷积函数为 g( x, y),输出图像(z x, y)可表示为:

该运算以卷积核作为计算参数实现图像的特征提取。卷积运算的表达式在二维图像输入时,如下:

积分形式:
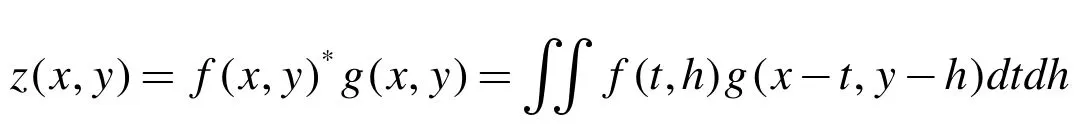

给定尺寸是m*n 的卷积核,那么:

4 YOLO 的改进
4.1 网络结构
借鉴YOLOv3 对YOLO 网络进行改进,将特征提取的网络改为62 层的ResNet[9]。使得YOLO 网络更深。同时为提高检测效果将特征金字塔结构进行了引入。池化层被步长为2 的卷积层所代替。输入图片由416x416 尺寸经过一系列操作最后输出尺寸为13x13。
4.2 空洞卷积的引入
假设输入层为5x5,卷积核为3x3,输出神经元的过程如下:

W 表示权重,I 表示输入,在激活函数 σ中输入上式所得值可获得输出值:

若图片三个通道输入如下:

卷积计算:

此时,

重复上面的计算过程,可得特征图。
4.3 损失函数
用交叉熵损失函数代替激活函数,边界框的尺寸误差在采用均方差函数的情况下表达式为:

进行归一化后的误差表达式:

中心坐标误差:

置信误差:

概率误差:


5 结论
通过对YOLO 算法的初步了解,以及改进发现其在行人识别的应用上有极大的改进空间。后续将对YOLO 算法做更加深入的理论分析,进一步的改进,在行人检测应用上进行实际测试。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
意林(2021年5期)2021-04-18
电子制作(2019年13期)2020-01-14
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2019年11期)2019-07-04
扬子江(2019年1期)2019-03-08
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
