
一种基于改进RT-MDNet的全景视频目标跟踪算法
2020-09-27 08:06王殿伟方浩宇伍世虔谢永军宋海军
哈尔滨工业大学学报 2020年10期
王殿伟,方浩宇,刘 颖,伍世虔,谢永军,宋海军
(1.西安邮电大学 通信与信息工程学院,西安 710121; 2.武汉科技大学 信息科学与工程学院,武汉 430081;3.中国科学院 西安光学精密机械研究所,西安 710119)
目标跟踪是在视频序列中给定第1帧目标位置信息后,能够估计之后视频帧中同一目标位置与尺度信息的算法,在智能交通系统、监控系统等领域都有广泛的应用[1].目标跟踪算法受相似背景干扰、目标遮挡、目标尺度变化等因素的影响,导致精度较差和适用性较差,因此,如何提高目标跟踪算法鲁棒性和准确性是一项挑战[2].
近些年来深度学习的运用,使计算机视觉领域的发展更为迅速.Nam等[3]提出了MDNet,使用了卷积神经网络结构,用于学习目标的通用特征表示.Yun等[4]结合监督学习和强化学提出ADNet,训练网络学习识别目标,通过强化学习预测目标的变化姿态及尺度,算法较好地解决了尺度变化的问题,但精度不佳.Li等[5]将Siamese FC与RPN网络相结合提出Siamese RPN,利用相关滤波的方法提升了跟踪精度,具有实时的性能,但算法易受到背景的干扰.Jung等[6]在MDNet的基础上提出RT-MDNet,设计损失函数和采用自适应的RoIAlign,简化特征提取网络结构,在保持了相同精度的同时,将速度提升了近25倍,但是算法对于目标尺度变化估计很局限,无法直接应用于全景视频图像的目标跟踪.
针对上述问题,本文提出了一种利用长短期记忆网络(Long Short-Term Memory, LSTM)改进RT-MDNet的目标跟踪算法,改进算法增大网络的输入以适应全景图像的输入特征,调整生成样本尺度,训练网络能更好地适应全景图像的目标形变,提高网络跟踪精度.在原有的网络结构中增加尺度变化模块,利用LSTM网络学习尺度变化过程,结合之前视频帧的位置信息,自适应地调整当前视频帧的尺度变化程度,以适应全景图像中目标跟踪的尺度变化和目标形变问题.算法很好地提高了跟踪精度,保持了一定的运算速度.
1 全景视频的目标跟踪
全景数据具有更高的分辨率,同时伴随着更复杂的场景和更高的计算要求,目标对象与摄像头相对运动时,距离的变化在跟踪中会以尺度变化的方式反映出来,当目标对象与摄像头距离越靠近,这种尺度变化程度会更严重[7].RT-MDNet算法对于尺度变化的映射较为简单,不能很好地适应全景视频中的变化幅度,训练RT-MDNet用于全景视频序列的目标跟踪时,实验结果如图1所示.
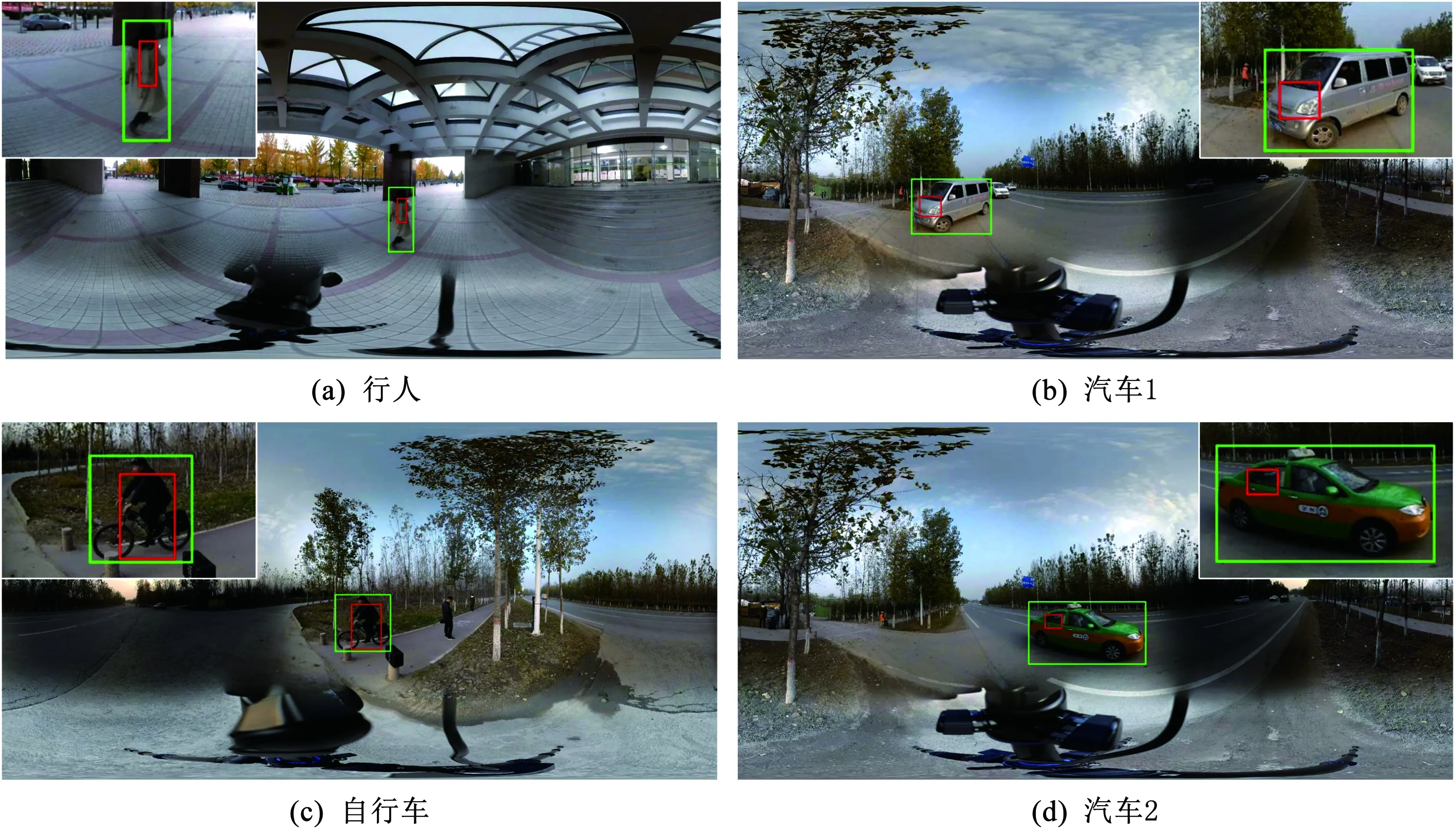
图1 不同场景下出现的尺度变化问题
图1中为原网络输出结果与真实值,实验结果覆盖的多个场景均出现了很大程度的尺度变化,而改进前原网络应对尺度变化的能力很弱,需要分析全景图像成像方式和数据特性,针对全景数据调整网络结构,使其具有更好的适用性和应对尺度变化的能力.
1.1 本文算法流程框架
RT-MDNet使用BoundingBox regression方法对边框进行调整,BoundingBox regression根据第1帧真实值和预选值做线性映射改善目标尺度变化.在全景视频中尺度随着目标的运动有规律的变化,在跟踪过程中仅使用第1帧做线性映射难以估计目标的尺度变化.针对已有算法应用于全景图像目标跟踪时,跟踪精度较低且尺度变化适应性差的问题,提出了一种基于改进RT-MDNet的全景视频目标跟踪算法.随着视频序列的移动,依据LSTM网络拥有长时间记忆单元的优势,结合不同频帧之间的尺度变化信息,利用神经网络学习数据集中尺度变化的方式,算法的整体流程如图2所示.
由图2可知输入图像经过共享的3个卷积层提取特征图,经过Adaptive RoIAlign提取出预选框特征送入全连接层区分前景背景,最后目标框经过LSTM网络自适应的选取目标框尺度,LSTM网络输出最终的改进结果.网络整体参数针对全景数据进行改进,使网络更加适用全景数据的特性,使用Adaptive RoIAlign进行特征提取降低了计算成本减少了卷积过程损耗,利用区域间的损失函数加强了网络对于相似目标的区分能力,提升了网络的跟踪精度.
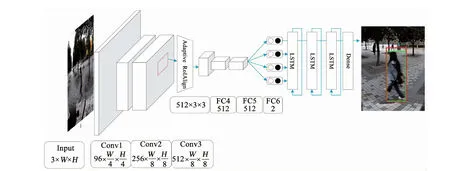
图2 本文算法整体网络框架
1.2 实例间区分的损失函数
RT-MDNet的损失函数引入了实例,在区分目标背景的同时,可较好地在特征空间中将不同视频序列的目标进行区分.RT-MDNet的最后一个全连接层根据输入的视频序列在线调整参数,输出网络得分,并通过Softmax区分目标对象与背景干扰,通过另一个Softmax区分不同视频域之间的目标类.整体的损失函数L为
L=Lcls+α·Linst,
(1)
式中Lcls和Linst分别为目标背景二分类和实例嵌入的损失函数,α是控制两个损失函数之间的超参数.
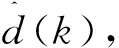
(2)
式中:yi∈{0,1}2×D是真实值的one-hot编码,对应在视频序列d中c个类别的输出为1或是0.实例间的损失函数由下式给出:
(3)
式中:+d为损失函数中实例嵌入的损失只由正样本给出,算法引入了当前序列的实例特征,使当前序列中的目标分数变大,其他序列目标分数变小,用以区分其他类似对象对目标的影响.
1.3 Adaptive RoIAlign
目标跟踪与目标检测中常用RoIPooling作为区域特征的映射方式[4,8],通过RoIPooling将目标预选区域通过卷积的方式映射到固定尺寸的特征图,然后进入全连接层进行分类和预选框回归操作.RoIPooling的局限性在于,映射的过程中会出现两次量化的过程,量化的过程会损失掉一部分特征信息.目标足够大的时候这种损失可以忽略,然而全景视频中由于其成像特性,距离稍远的目标会呈现得很小,在持续的目标跟踪中细小的误差将会持续累积,小目标出现频繁时这种损失对原有特征产生很大的影响从而导致目标丢失.
为了解决这一问题,MaskR-CNN[9]对RoIPooling改进,提出了RoIAlign,在遍历预选框时不再进行量化操作,而是通过双线性插值来得到近似特征,以实现对目标更精准地定位.RT-MDNet采用的Adaptive RoIAlign方式与MaskR-CNN相似,双线性插值的步长由输出的RoI feature的大小决定,显著提高了跟踪算法的性能.RoIAlign整体流程如图3所示.
图3中预选框经过卷积提取到的RoI尺度为W×H,预期经过RoIAlign得到的RoI尺度为W′×H′,[·]是舍入算子通过卷积操作得到最终的输出.Adaptive RoIAlign图层生成7×7的特征图,并在图层之后应用Maxpooling最终生成3×3的特征图.在本文算法中采用Adaptive RoIAlign方法映射特征图,加强算法对于全景视频中小目标跟踪的鲁棒性.
1.4 LSTM
Hochreiter等[10]于1997年在RNN网络基础上提出LSTM网络.LSTM通过引入更新门、遗忘门和输出门,同时考虑了时间序列的机制,解决了RNN网络中的梯度消失问题,LSTM网络已经在目标检测,目标跟踪领域中取得了很好的成果[11].在跟踪中对目标框进行调整时如果只知道当前输入,所输入的信息对尺度变化的估计是不够精确的,利用LSTM的记忆单元连接先前的信息结合到当前任务中,可以更好地调整原始网络的输出目标框尺度.
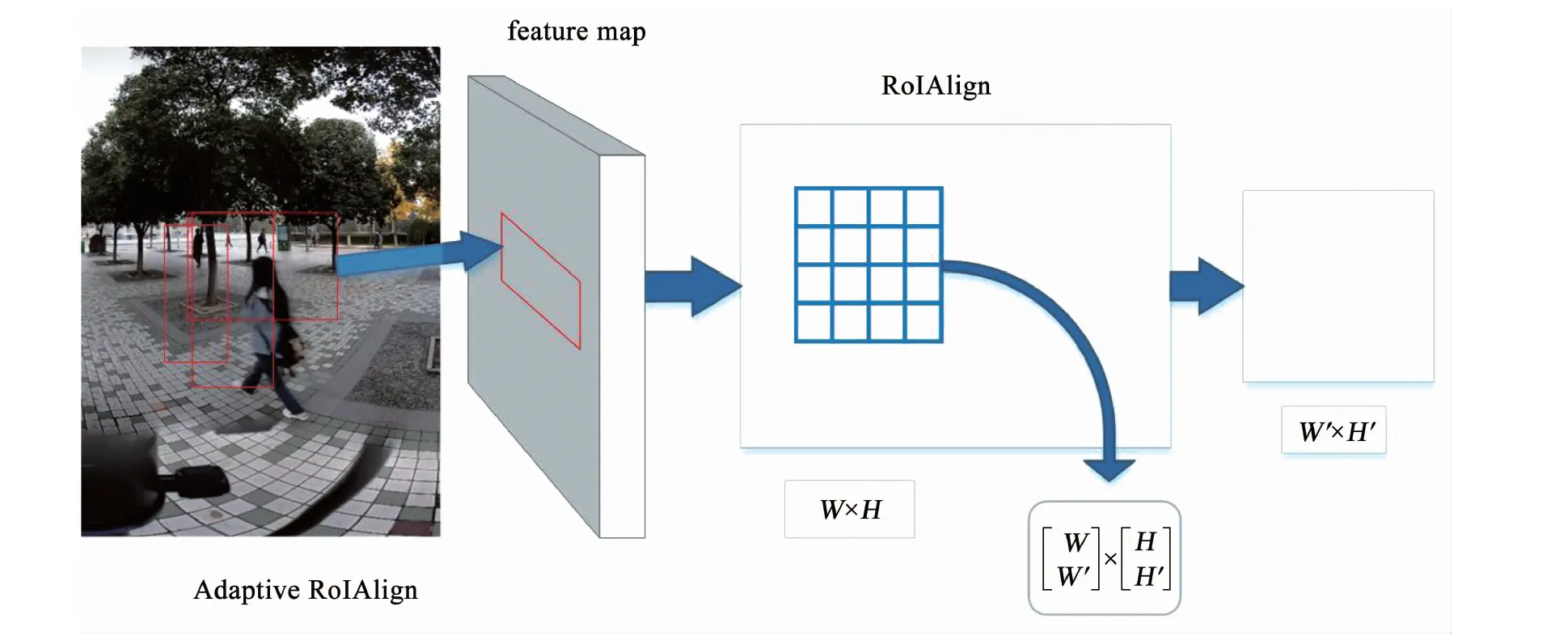
图3 Adaptive RoIAlign特征映射流程
LSTM在t时刻隐藏单元为:
Γu=σ(Wu[a〈t-1〉,x〈t〉]+bu),
(4)
Γf=σ(Wf[a〈t-1〉,x〈t〉]+bf),
(5)
Γo=σ(Wo[a〈t-1〉,x〈t〉]+bo).
(6)
式中:Γu、Γf和Γo分别为更新门、遗忘门和输出门,σ为sigmoid激活函数,a〈t-1〉为上一时刻的输出,x〈t〉为当前时刻的输入,Wu、Wf、Wo和bu、bf、bo分别是不同门的参数与偏差项.更新门和遗忘门控制记忆细胞的更新,更新门记录当前的尺度,遗忘门选择保留更显著的特征,在记忆细胞中保留之前视频帧的尺度变化,记忆细胞公式由下式给出:
(7)
(8)
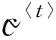
a〈t〉=Γo*tanhc〈t〉,
(9)
式中:c〈t〉是经过输出门Γo得到当前网络的输出a〈t〉.本文设计的网络结构由3层LSTM和1个全连接层组成,整体的预测网络结构如图4所示.
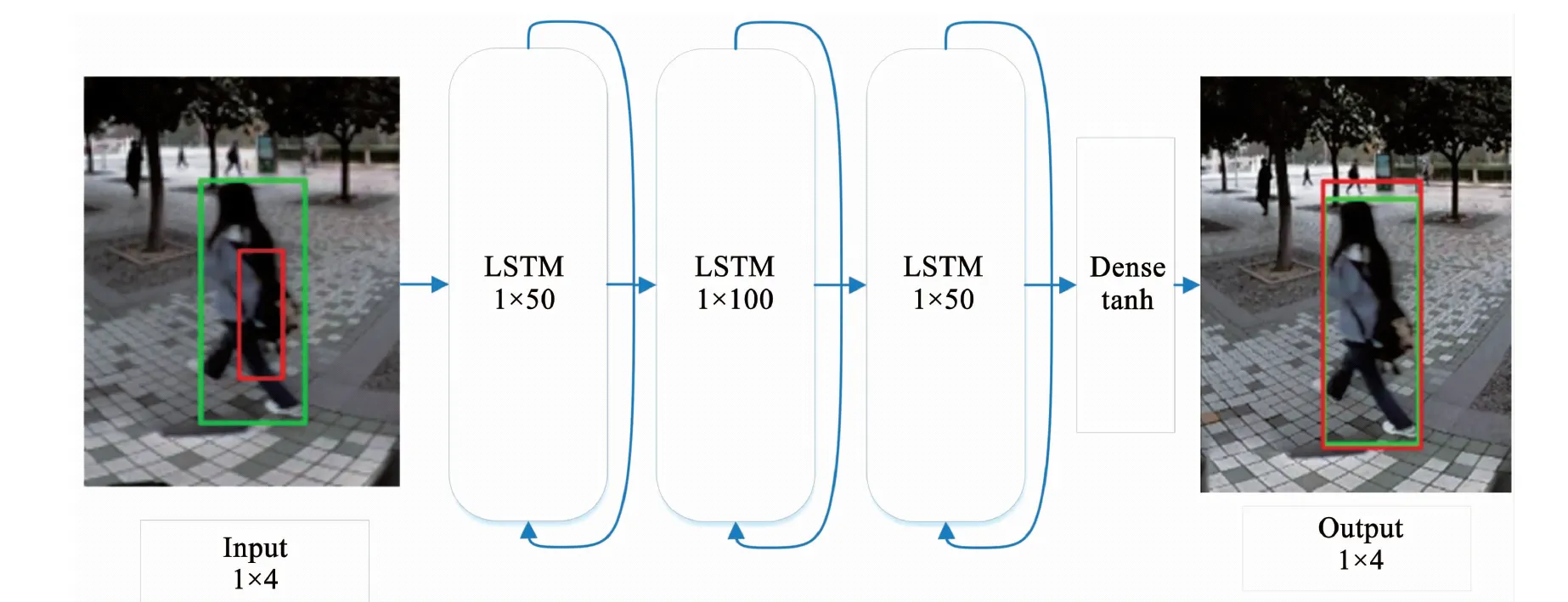
图4 LSTM网络结构
目标在全景视频中的尺度变化方式受其位置因素的影响,变化模式较为单一.深层次的LSTM网络利用多层的神经网络从多个不同维度理解尺度特征的变化,在多个层次中分解输入尺度特征,低维度输入映射到高维度相当于将低维特征分解到多个维度,再利用高维度的特征拟合全景视频尺度变化方式,在高维空间中学习运动规律,更容易学习并且能达到更高的准确率.随着视频帧的进行,LSTM学习在不同时刻多维度的尺度表达并将其特征保留在记忆细胞中,从高维度学习解决尺度变化的问题.
神经网络中增加网络层数可以拟合更加复杂的映射,因此增加神经网络深度是网络搭建中有效的优化方式.但是过深的神经网络不仅会造成过拟合,而且会造成计算资源的浪费.为平衡网络计算复杂度以及追踪的精度,本文设置3组实验来验证LSTM的层数选择,LSTM分别为2层、3层、4层.网络中使用尽可能少的神经元数量达到需求的准确率是搭建结构中的重点.在实验中采用Adam算法优化网络训练,针对归一化的数据采用tanh激活函数,在多次实验中衡量损失值的变化趋势调整学习率和训练批量,使损失值下降的更为平滑,并且梯度向最优方向迭代.通过实验对比网络节点数对精度的影响,本算法选择先分解输入特征再聚合的网络结构,最后通过全连接层输出目标框.图5为选取一部分实验数据进行网络预训练的实验结果图.
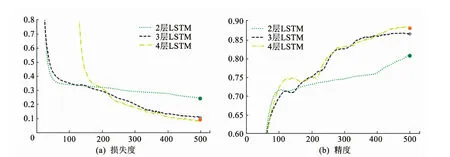
图5 不同网络层数损失值和精度结果对比
图5中分别代表2层、3层、4层LSTM网络在训练中的损失值与精度的变化曲线.3次实验中均选择相同的实验数据和网络参数,2层LSTM网络损失值局部收敛得更快一些,在精度和损失值趋于平缓时准确率并不理想.2层网络在训练中受深度的限制,精度提升缓慢原因在于提取的特征少,处于当前最优的情况,损失值不再下降.3层和4层的LSTM趋近于收敛后,可以达到更低的损失值和更高的准确率,3层的LSTM在达到准确率要求的同时运用了更少的计算资源.

表1 3种网络结构参数量对比
原网络输出每帧目标的位置信息和尺度信息,利用LSTM网络的记忆特性结合之前帧的位置信息和尺度信息,学习当前帧的目标尺度变化.输入经过3层LSTM网络得到输出a〈t〉,a〈t〉再经过全连接层得到当前网络的尺度变化.图6为改进后LSTM网络的目标框与原网络输出目标框的结果.

图6 原网络与改进网络实验结果对比
图6(a)为原网络输出结果,图6(b)为改进网络的输出结果.由图可知目标由近及远的过程中出现了大幅度的尺度变化问题,原网络难以适应尺度变化,经过改进的网络在跟踪中能自适应调整目标框尺度,取得更好的跟踪效果.
2 实验结果与分析
目前常用的目标跟踪算法都是基于公开数据集,如OTB[12],VOT[13]等数据集,尽管在公开数据集中可以获得特征表达,但由于数据集场景还是较为单一,导致在跟踪方面的有效性受到数据集的限制.为了在全景数据上有更佳的表现力,就需要可用于训练和测试的全景数据集.为了解决上述问题,本文建立了用于目标跟踪的全景数据集,该数据集包含标注了多个场景、不同时间(白天、夜晚)条件下的行人、车辆等数据,可以实现神经网络端到端的训练.所有训练及测试数据集均为泰科易720 Pro七目全景相机采集所得,分为4个类别进行了标注,处理后的图片分辨率2 000×1 000.
硬件配置为CPU Intel Xeon E5-2620v4×2,显卡GPU NVIDIA Titan XP×4.在Ubuntu系统中使用Python作为实验平台,训练的LSTM网络用Keras框架搭建.
2.1 主观分析
为了评估算法在全景图像中的有效性,本文选取了多个不同场景不同目标的全景视频作为测试数据,并与MDNet,ADNet,RT-MDNet和Siamese RPN算法的跟踪结果做主观和客观分析.实验结果中全景视频序列涵盖了目标变形,目标旋转,光照变化,长时间跟踪等诸多现实挑战情况,为了突出对比性能结果的好坏,对整幅全景图进行了截取,并选取出其中具有较复杂的尺度变化问题的视频序列.结果图中不同的线型代表不同的跟踪算法中的目标框,其主观结果如图7所示.

图7 4个不同场景下不同算法结果对比
图7(a)至(d)分别为自行车、汽车、夜晚和白天的行人视频序列,序列中均出现了较大程度的尺度变化和外观变化.在图7(a)序列中目标旋转和光照的影响比较大,MDNet和ADNet不能很好地应对这种变化,出现了跟踪丢失的情况,本文算法对受光照影响的目标跟踪效果较好.图7(b)序列中物体出现了剧烈的旋转和尺度变化,ADNet和Siamese RPN具有应对尺度变化的模块,在图7(b)中对于尺度变化的适应比RT-MDNet和MDNet稍好一些,但是在全景数据上依然很难达到很好的视觉效果,本文改进算法也能较好地适应这种情况.图7(c)中5种算法均有较好的准确率,图7(d)中Siamese RPN在受到具有相似特征的背景干扰时发生了目标丢失的情况,本文改进算法在准确跟踪目标的同时,目标框能够结合之前视频帧自适应的变化.图8、图9和图10为采用本文算法得到的完整实验结果与真实值对比及其跟踪目标的放大图.
由图8可见,全景视频序列中小目标较为普遍,小目标尺度变化程度不明显,本算法在应对全景视频中的小目标时,依然能够准确稳定地追踪,具有较好的鲁棒性.
由图9可见,在多个目标交叉运动时,虽然受多个相似目标的影响出现了小幅度的漂移,但在后续视频帧中仍然可以稳定跟踪目标对象.本算法在区分相似的群目标时,能持续跟踪选定目标,具有较好的自适应跟踪能力.

图8 小目标情况下的实验结果

图9 多个目标交叉运动的实验结果
图10中出现了目标遮挡的问题,对跟踪结果产生了一定的影响,但接下来的视频帧目标重新出现改进算法能够继续跟踪目标,本算法在应对遮挡问题上仍有不错的表现.
综上所述,RT-MDNet与MDNet都达到了很好的精度,但缺少对目标尺度变化的估计.ADNet和Siamese RPN具有应对尺度变化的能力,但是不能满足全景数据的目标变化.在速度上全景图像由于具有很高的分辨率所以很难达到实时的要求,本文算法在应对不同光照条件、不同目标时可以较好地应对目标的尺度变化,并提供了准确率和重叠率.

图10 目标遮挡情况下的实验结果
2.2 客观分析
为了评估算法性能,利用重叠率(Intersection over Union,IOU)和距离精度作为客观分析指标来评估算法.重叠率表示跟踪结果与真实值重叠部分与整体之间的比值,距离精度表示跟踪结果中心位置与真实值结果中心位置的欧氏距离.评估性能时须得到当前帧重叠率和距离精度,当大于一定阈值判定为预测准确,判定为预测准确的视频帧与整体视频帧的比率称之为成功率和精度.在全景图像数据集上试验得到预测结果IOU和目标框,可视化为曲线图11.计算两个标准中不同阈值所对应成功率和精度来生成这两个对比图,根据其中的成功率和准确率得分对跟踪器进行排名.
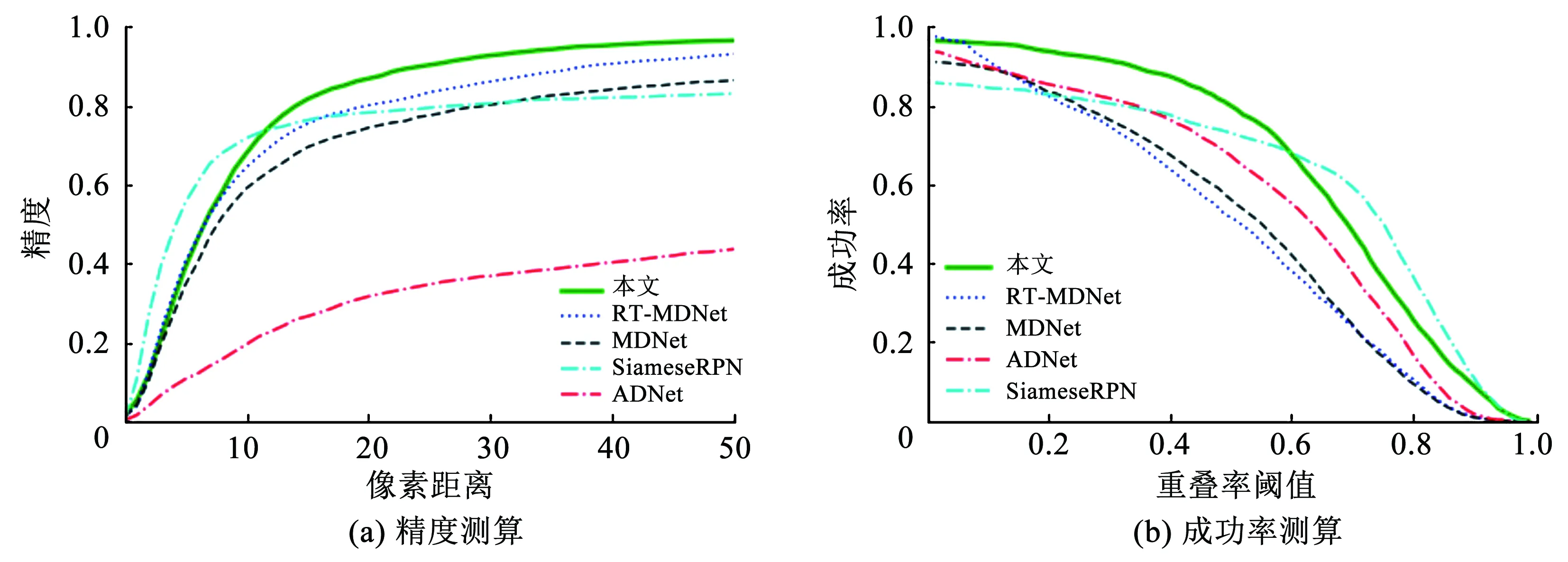
图11 4种算法在全景数据集上的测试结果
图11给出RT-MDNet、MDNet、ADNet和Siamese RPN,4种算法与本文改进算法精确率和成功率的比较.ADNet丢失目标的视频帧较多,所以在精度图中的表现较差,而在成功率图中IOU高于RT-MDNet和MDNet.Siamese RPN应对尺度变化的能力强于其他4种算法,但成功率略低于MDNet和RT-MDNet.从图11中可以看出本文改进算法在精度测算图和成功率测算图中对于原算法均有明显的提升.表2中给出各算法在欧氏距离阈值为20像素时跟踪器的精确率,IOU大于阈值0.5时跟踪器的成功率,数据集距离精度的平均值,即平均中心位置误差和基于全景数据集的平均FPS.
由表2可知,由于全景图像具有较大的分辨率,复杂的目标形变和尺度变化,导致RT-MDNET精确率只有80.1%,成功率只有51.6%,本文算法适应了全景数据特性,通过采用LSTM算法减少尺度变化对目标跟踪网络产生的影响,降低了跟踪难度,从而提升了算法跟踪性能.最终,本文算法精确率为86.9%,成功率为79.9%,速度也优于ADNet与MDNet.
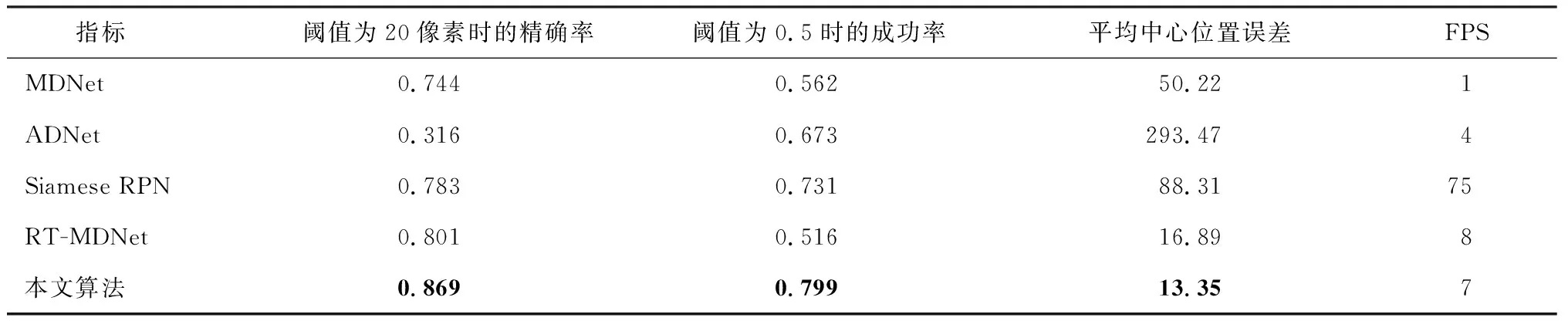
表2 各算法在不同指标下性能对比
综上所述,RT-MDNet与MDNet都达到了很好的精度,但在应对尺度问题时难以适应变化程度.ADNet在应对尺度变化的问题强于前者,但还是达不到对于全景数据的需求.Siamese RPN较好地应对了尺度变化的问题,但相关滤波方法容易受到相似特征背景的影响导致精确率较低.通过以上对比试验可以得出,经过LSTM网络的本文算法在主观标准和客观标准上均有很大的提升,在应对不同光照条件,不同目标时可以较好地应对目标的尺度变化和遮挡,并提高了在全景图像上的准确率和重叠率,跟踪效果明显提升.
3 结 论
为了解决基于全景数据集的目标跟踪的问题,本文提出了一种基于RT-MDNet和LSTM网络的全景图像跟踪算法,采用卷积神经网络提取特征,并利用RoIAlign方法来减少卷积过程中对特征区域的损耗,增强网络的鲁棒性;使用区分多视频序列间目标的损失函数,使网络可以更好的区分相似目标加强网络的适用性;设计LSTM网络自适应地选取边界框的尺度,针对数据集改进网络结构,以应对全景数据中出现的目标形变和尺度变化问题,最终输出目标位置信息.
实验结果表明,本文算法具有较高的跟踪精度,能够在目标扭曲、旋转剧烈、目标运动快、背景相似干扰等多种挑战下长期稳定地跟踪目标,在保持了精度的同时对全景数据的IOU得分实现了有效的提高.但是由于全景图像分辨率较大的原因,伴随着运算量大的问题,导致算法速度受到限制,目前还难以满足实时的需求.进一步裁剪网络、优化算法、实时处理将会是以后的重点研究方向.
猜你喜欢
一重技术(2021年5期)2022-01-18
家庭影院技术(2020年11期)2020-12-28
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
英美文学研究论丛(2018年1期)2018-08-16
电子制作(2018年11期)2018-08-04
家庭影院技术(2017年12期)2017-02-06
特别文摘(2016年21期)2016-12-05
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
