
基于特征融合与冗余剔除的普洱茶种类电子鼻识别方法
2020-09-24 03:14徐赛张倩倩
江苏农业科学 2020年16期
徐赛 张倩倩
摘要:为更好地维护普洱茶的产业秩序,拟探究1种用电子鼻识别普洱茶种类的方法。采用电子鼻对7种普洱古树茶(拨玛、贺开、老班章、老曼峨、帕莎、那卡和易武)和1种普洱台地茶(易武)进行电子鼻采样后,先用线性判别分析(LDA)初步探究电子鼻传感器响应不同特征(最大值、平均值、平均微分值、稳定值和融合特征)对普洱茶种类的分类效果(将传感器R1~R10的特征按照最大值、平均值、平均微分值、稳定值的重复顺序进行提取,用编号1~40表示),再用简单相关分析(SCA)和互信息理论(MIT)结合偏最小二乘回归(PLSR)进行分析,揭示并剔除融合特征中的冗余特征,对去冗余数据进行归一化处理后,通过LDA、k-最近邻分析(KNN)和概率神经网络(PNN)建立普洱茶种类的识别模型。结果表明,多特征融合比单一特征提取的LDA普洱茶种类识别结果更佳,但识别精度仍有待提高。剔除冗余特征前,PLSR对普洱茶种类识别训练集、测试集的R2分别为0.864 5、0.834 5;采用SCA-PLSR剔除弱相关特征31、35、24、39、36、33后,PLSR對训练集、测试集识别的R2分别为0.885 2、0.864 3;采用MIT结合PLSR剔除重复信息特征6、7、14、18、22、25后,PLSR对训练集、测试集识别的R2分别为0.918 7、0.896 5。对去除冗余特征的融合特征数据进行归一化处理,再结合LDA可有效识别各普洱茶种类,结合KNN、PNN对普洱茶种类训练集的回判正确率分别为96.67%、97.50%,对测试集的识别正确率均为90.00%,可较好地识别普洱茶种类。试验结果可为普洱茶种类的识别及电子鼻传感响应特征的提取提供参考。
关键词:普洱茶;种类;电子鼻;特征融合;冗余剔除
中图分类号:TP212.9
文献标志码:A
文章编号:1002-1302(2020)16-0222-06
普洱茶是世界名茶,由于其风味上佳且具有保健功效,因此深受消费者喜爱[1]。普洱茶是中国国家地理标志产品(GB/T 22111—2008《地理标志产品 普洱茶》),对土壤、气候等环境条件有需求,只有种植在云南省普洱市才能较好地形成其特有的风味[2]。按照种植地域(普洱市的不同县)划分,普洱茶可分为拨玛、贺开、老班章、老曼峨、帕莎、那卡和易武等种类[3];按照茶树的树龄划分,普洱茶可分为古树茶与台地茶[4]。洱古树茶是最为昂贵与稀少的品种,其风味是经过上百年形成的。台地茶为新种植的普洱茶树,价格较便宜,满足了更多消费者的需求。由于不同种类普洱茶之间的价格差异较大,市场上出现了一些“以假乱真、以次充好”的现象[5-6]。因此,探究一种普洱茶种类的快速识别方法,对于维持普洱茶产业秩序具有重要意义。
电子鼻检测是一种模拟生物嗅觉系统的仿生检测手段,主要是通过其内置的气敏传感器阵列与被测样本的气体挥发物发生瞬时响应,获取样本信息[7]。有研究已经证明,电子鼻可有效获取茶品质信息,从而对茶品种[8]、贮藏时间[9]、贮藏地[10]等信息进行识别。但是,相对于不同茶品种而言,同一品种的茶(如普洱茶)在不同种类(同市异县、树龄)间的差异较小,使其识别难度较大。目前,关于电子鼻能否有效识别普洱茶种类尚未见有关报道。
本试验采用电子鼻对8种不同普洱茶进行采样,采用线性判别分析(LDA)初步探究电子鼻响应数据的最大值、平均值、平均微分值、稳定值和融合特征对普洱茶种类的分类效果,再用简单相关分析(SCA)和互信息理论(MIT)结合偏最小二乘回归(PLSR)验证,揭示并剔除融合特征中的弱相关特征与重复信息特征。最后,对去冗余融合特征进行归一化处理,采用LDA、k-最近邻分析(KNN)和概率神经网络(PNN)建立普洱茶种类识别模型。本研究结果可为普洱茶种类识别及电子鼻传感响应特征的提取提供参考。
1 材料与方法
1.1 试验材料
本试验所选择的普洱茶样本包括7种古树茶(拨玛、贺开、老班章、老曼峨、帕莎、那卡和易武)和1种台地茶(易武),均为2017年产于云南的普洱生茶烘干茶饼。各种类均重复试验20次,每个重复包含5 g普洱茶。为了保证试验样本的气味均匀、充分地散发,将试验样本于29 000 r/min磨碎2 min。
1.2 电子鼻信号的获取
用PEN 3电子鼻(AIR SENSE公司,德国)采集普洱茶样本的气体挥发物“指纹”图谱,该电子鼻主要由采样与清洗通道、气敏传感器阵列和模式识别单元构成。其中,气敏传感器阵列包含10个对不同类型气体挥发物质敏感的金属氧化物气敏传感器,使整个电子鼻系统能够识别不同的气味。各气敏传感器的主要性能如下[11]:传感器W1C(R1)对芳香成分敏感,传感器W5S(R2)对氮氧化合物敏感,传感器W3C(R3)对氨水、芳香成分敏感,传感器W6S(R4)对氢气敏感,传感器W5C(R5)对烷烃芳香成分敏感,传感器W1S(R6)对甲烷敏感,传感器W1W(R7)对硫化物敏感,传感器W2S(R8)对乙醇敏感,传感器W2W(R9)对芳香成分和有机硫化物敏感,传感器W3S(R10)对烷烃敏感。
将各试验样本均置于200 mL玻璃烧杯中,用双层塑料膜密封,静置30 min后,用电子鼻采集顶空气体。烧杯使用前均洗净、于阴凉无异味的室内环境中晾干。电子鼻的采样参数设置如下:采样时间间隔为1 s,传感器自动清洗时间为60 s,传感器归零时间为10 s,分析采样时间为100 s,进样准备时间为5 s,进气速度为240 mL/min。
1.3 特征提取方法
参考相关研究结果[12-13],采用最大值、平均值、平均微分值、稳定值4种常用的电子鼻数据提取方法对普洱茶电子鼻响应数据的特征进行提取。其中最大值为电子鼻各传感器响应曲线的最大值,平均值为电子鼻各传感器响应曲线的平均值,平均微分值为电子鼻各传感器响应曲线各数据点微分值的平均值,稳定值为电子鼻各传感器响应曲线趋于稳定后的响应值(本研究采用第95秒的值)。
1.4 简单相关分析
简单相关分析是研究变量之间关系紧密程度的一种统计方法,它反映了当控制其中1种变量的取值后另1种变量的变异程度,其主要目的是研究变量之间关系的密切程度,其显著特点是变量不分主次,被置于同等的地位[14]。
1.5 互信息理论
互信息理论是衡量变量间相互依赖程度的指标,表示变量间所拥有共同信息的量,不仅能描述变量间的线性相关关系,还能描述变量间的非线性相关关系[15]。互信息值(MI)的定义域为[0,1],其值越大,表明变量之间的共有信息越多,反之,则表示变量之间的共有信息越少。本试验采用互信息来衡量特征之间存在的重复信息量。
1.6 模式识别算法
1.6.1 线性判别分析 线性判别分析是一种运用降维进行模式识别的线性识别方法。线性判别分析能从所有传感器中收集数据信息,每个种类通过1个特殊的向量化变换得到,使得样本内凝聚而样本间疏远[16]。
1.6.2 偏最小二乘回归 偏最小二乘回归分析是一种多元回归分析,它根据变量的不同权重来计算各变量的回归系数,进而建立回归方程,再根据回归方程计算出预测结果[17]。
1.6.3 k-最近邻分析 k-最近邻算法是根据考察待识别样本的k个最近邻样本,在这k个最近邻样本中哪一类样本最多,该考察样本就属于哪一类,为避免近邻数相等,k通常采用奇数[18]。
1.6.4 概率神经网络 概率神经网络由输入层、隐含层、求和层和输出层组成。输入层的作用函数为线性函数,用于接收来自训练样本的值,将数据转化为输入信号传递给隐含层,神经元数量与输入长度相等。隐含层与输入层之间通过权值Wij相连,其传递函数为g(zi)=exp[(zi-1)/σ2]。式中:zi为该层第i个神经元的输入值(传感器特征),σ为均方差。求和层神经元数量与拟分类的模式数量相同,具有线性求和功能。输出层具有判决功能,其神经元输出为离散值1或-1(或0),分别代表输入模式的不同种类[19]。
2 结果与分析
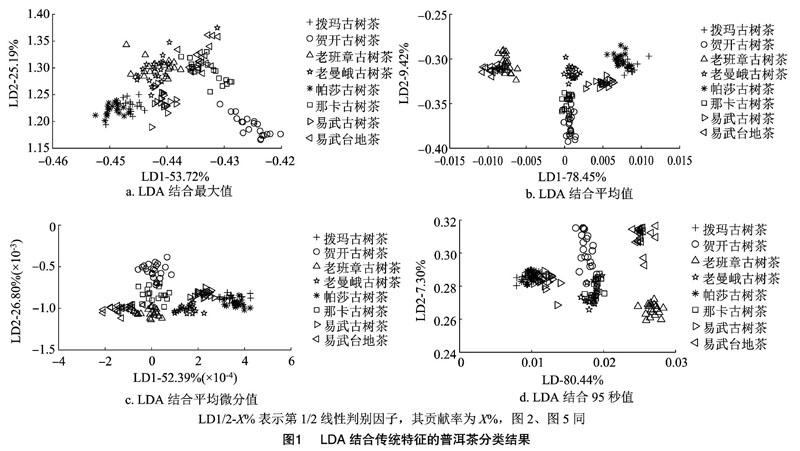
2.1 基于不同特征的普洱茶种类LDA分类
采用最大值、平均值、平均微分值和95秒值等4种常用的电子鼻特征提取方法,结合LDA,对普洱茶的种类进行分类。由图1-a可以看出,采用LDA结合最大值对普洱茶种类进行分类时,贺开古树茶的数据点与其他种类间无重叠现象,可以被较好地区分开,其他种类普洱茶的数据点间均存在重叠现象,无法进行分类。由图1-b可以看出,采用LDA结合平均值对普洱茶种类进行分类时,各普洱茶种类数据点间均存在重叠,无法区分开,但与LDA结合最大值对普洱茶种类的分类结果(图1-a)相比,各数据点的聚类性更佳。由图1-c可以看出,采用LDA结合平均微分值对普洱茶种类进行分类时,除拨玛古树茶、帕莎古树茶的样本数据点重叠外,其他种类间均能区分开,但样本数据点较近,实际分类已发生混淆。由图1-d可以看出,采用LDA结合95秒值对普洱茶种类进行分类时,老班章古树茶、易武台地茶可以较好地被区分,其他种类的分类效果不佳。
由此可见,采用不同特征的提取方法是从不同角度对样本信息进行表征的,均有各自的优势和缺点。在实际分类识别的过程中,要提高分类识别的精度,就要充分提取采样信号中的有益信息[20]。因此,本试验采用多特征融合的方式进行进一步的分类识别。
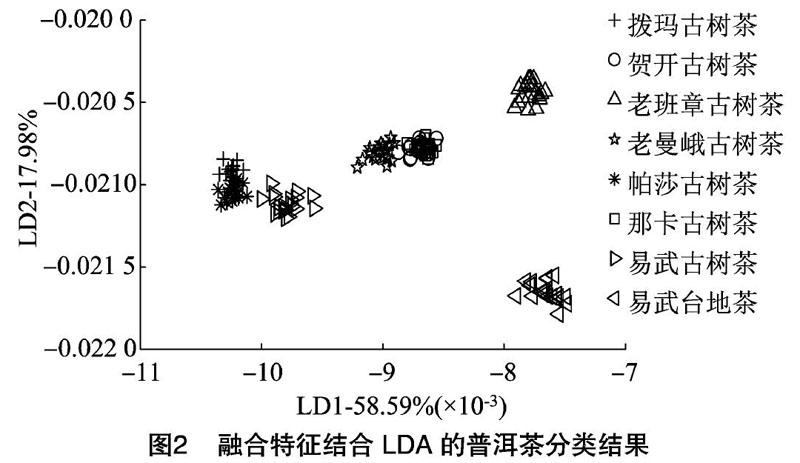
2.2 基于融合特征的普洱茶种类LDA分类
采用最大值、平均值、平均微分值和95秒值组成融合特征,对普洱茶种类进行LDA分类的结果如图2所示。融合特征结合LDA的分类结果保留了LDA结合95秒值分类结果的优点(图1-d),可以将老班章古树茶与易武台茶地较好地区分开,同时保留了LDA结合平均值分类结果的优点(图1-b),可以将易武古树茶与老曼峨古树茶区分开,但与其他种类样本的数据点较近,区分效果较图1-b差。然而,贺开古树茶与那卡古树茶能被最大值区分的优点未能在融合特征的分类结果中体现,拨玛古树茶与帕莎古树茶样本数据点有一定区域的重叠,识别精度有待进一步提升。由此可见,特征融合可以更加全面地整合样本的综合特征,具有提高识别精度的能力。研究发现,在基于多特征信息融合的过程中,并非所有融合特征均为分类识别的有益特征,若引入过多冗余特征,形成的噪声信号无疑会降低识别精度[21]。由此可见,多特征融合在使用过程中存在一定风险,合理的信息融合是将其提高识别精度作用最大化的关键,需要进一步探究。
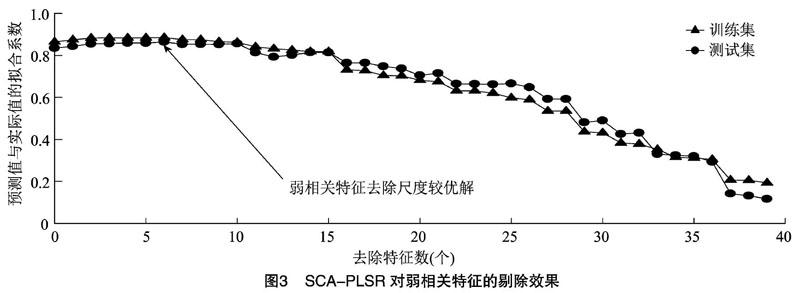
2.3 SCA-PLSR对弱相关特征的剔除
部分弱相关特征与普洱茶种类的相关性极小,
对分类识别的干扰大于贡献,需要剔除。本试验中的融合特征包含40个独立特征(10个传感器×4种特征提取方法=40个),为更好地表述各特征,本试验将传感器R1~R10的特征按照最大值、平均值、平均微分值、穩定值的重复顺序进行提取,并用编号1~40表示。采用SCA-PLSR方法对融合特征中的弱相关特征进行剔除,拨玛古树茶、贺开古树茶、老班章古树茶、老曼峨古树茶、帕莎古树茶、那卡古树茶、易武古树茶、易武台地茶8种普洱茶的分类输出标签分别用数字1~8表示。从各种类20个样本中随机选择15个样本作为训练集,剩下的5个样本作为测试集。得到的训练集样本数为120个,测试集样本数为40个。SCA-PLSR步骤如下:首先通过SCA得出各特征与分类输出标签之间的皮尔逊相关系数(r);再将特征按照|r|从小到大的顺序依次进行剔除,记录每次特征剔除后的PLSR对普洱茶种类的预测结果,根据预测种类与实际种类的拟合相关系数(R2),判断特征剔除的必要性。|r|、R2的定义域均为[0,1],|r|(或R2)越接近1,相关性越强,越接近0,相关性越弱。
SCA-PLSR形成的融合特征弱相关特征剔除对分类识别的影响趋势如图3所示。当去除特征数为0时,融合特征训练集、预测集的R2分别为0.864 5、0.834 5。按相关程度由低到高剔除弱相关特征31、35、24、39、36、33的过程中,训练集、测试集的R2不断增大,分别达到0.885 2、0.864 3。此后继续剔除特征,R2开始呈降低的趋势。由此可以推测,当|r|小于0.039 6(特征33与普洱茶种类之间的|r|)时,特征不包含分类识别的有效特征;当|r|大于0.039 6时,特征包含一定分类识别的有效信息。此外,去除特征33之前的特征后,训练集与预测集的识别精度均连续上升,因此予以去除。虽然特征33后也存在少量去除后预测集识别精度提升的特征,但是训练集识别精度无明显的同时提升,且随着相关性的提高,无法判断为无效特征,为了防止有效信息误删,给予保留。
2.4 MI-PLSR对重复信息特征的揭示与剔除
在剩余的34个特征中,需要进一步探究特征之间是否存在重复信息,重复信息特征通常会影响模型的运算效率,干扰模型的运算准确度,本试验采用互信息理论对重复信息进行揭示与剔除。如图4所示,特征6与16之间的MI最大,其次为7与17之间的MI,再次为7与27之间的MI,其余特征之间的MI相对较小。由此可以推测,相同传感器提取的特征之间易形成较多的重复信息。
为了进一步了解特征之间的重复信息情况,将互信息值在0.81以上的特征分为5个等级进行统计,详见表1。记录各阶段范围内形成重复信息的特征组,以初步获得与其他特征形成重复信息的特征,并对这些特征进行单个去除,结合PLSR分析验证其去除的必要性与提升识别精度的能力。得到的单个去除便可以提高识别精度的特征分别为特征6、7、8、14、18、11、22、25和27。此外,随着MI值逐渐减小,对应特征去除对识别精度的提高效果也逐渐降低,去除MI区间[0.81,0.82]锁定的特征8和11后,对精度的提高效果已不大。因此,下文不再讨论MI小于0.81的互信息特征。
然而,锁定的单个特征之间也存在互信息较大的现象,如特征7和27、特征18和8等,若全部去除可能会造成过多的重复删除,使得剩余信息中部分有效特征大幅度减少甚至丢失,从而降低识别精度。因此,本试验按照出现在较大MI值区间的特征优先删除、存在互信息的特征通过PLSR对比验证后删除的原则,最终确定去除特征6、7、14、18、22和25。去除上述重复信息后,PLSR训练集、预测集预测结果的R2分别为0.918 7、0.896 5,有效提高了普洱茶种类的识别精度。
2.5 普洱茶种类的建模识别
由于不同传感器的敏感程度不同,数据的归一化处理可以使数据中的各数据向量具有相同的长度,从而达到去除一定噪声干扰的目的,进一步提高识别精度[22]。本研究将去除冗余信息后的融合特征进行归一化处理,并采用LDA、KNN和PNN进行建模识别。
2.5.1 LDA结合去冗余融合特征的种类识别 如图5所示,通过LDA结合去冗余融合特征对普洱茶种类进行识别,各普洱茶种类均能得到较好的区分,拨玛古树茶和帕莎古树茶的数据点距离较近;相比于单独特征提取及未去冗余信息的融合特征,去除冗余信息的融合特征可以显著提高普洱茶种类的识别精度。
2.5.2 KNN结合去冗余融合特征的种类识别 采用KNN对8种普洱茶进行识别,每个种类检测20个样本。从各种类中随机选择15个样本作为训练集,剩下的5个样本作为测试集。本试验得到的训练集样本数为120个,测试集样本数为40个。在进行KNN分析时,近邻样本数k的选择对分类识别效果的影响较大。经过反复分析,设置k的数量为5个。建立KNN分类识别模型后,模型对训练样本的回判正确率为96.67%,对测试集的识别正确率为90.00%,具有较好的分类识别效果。
2.5.3 PNN结合去冗余融合特征的种类识别 采用PNN对普洱茶种类进行识别,共包含8个不同种类,每个种类检测20个样本。从各种类中随机选择15个样本作为训练集,剩下的5个样本作为测试集。本试验得到的训练集样本数为120个,测试集样本数为40个。在进行PNN分析时,Spread值的大小对模型的判别结果具有一定影响。Spread表示PNN的扩散速度,默认值为0.1,如果其值趋近于0,则网络相当于最邻分类器,其值越大,越接近线性函数。经过反复训练,设置Spread值为2×10-3。该PNN模型对训练集样本的回判正确率为97.50%,对测试集的识别正确率为90.00%,具有较好的分类识别效果。
3 结论
多特征融合比最大值、平均值、平均微分值和95秒值4种单一特征提取的普洱茶种类LDA识别效果更佳,但仍识别精度仍有待提高。冗余特征剔除前,PLSR对普洱茶品种识别训练集、测试集的R2分别为0.864 5、0.834 5;采用SCA-PLSR法剔除弱相关特征31、35、24、39、36、33后,PLSR对训练集、测试集识别的R2分别为0.885 2、0.864 3;采用MI结合PLSR剔除重复信息特征6、7、14、18、22和25后,PLSR对训练集、测试集识别的R2分别为 0.918 7、0.896 5。对去除冗余特征的特征融合数据进行归一化处理,结合LDA可有效地对普洱茶种类进行区分,结合KNN、PNN对普洱茶种类训练集的回判正确率分别为96.67%、97.50%,对测试集的识别正确率均为90.00%,可以較好地识别普洱茶种类。
参考文献:
[1]杨崇仁,陈可可,张颖君. 茶叶的分类与普洱茶的定义[J]. 茶叶科学技术,2006(2):37-38.
[2]刘本英,李友勇,唐一春,等. 云南茶树资源遗传多样性与亲缘关系的ISSR分析[J]. 作物学报,2010,36(3):391-400.
[3]薇 薇. 云南普洱茶产区地图[J]. 普洱,2017(5):71.
[4]吕海鹏,谷记平,林 智,等. 普洱茶的化学成分及生物活性研究进展[J]. 茶叶科学,2007,27(1):8-18.
[5]Bandana D,Mahipal S. Molecular detection of cashew husk (Anacardium occidentale) adulteration in market samples of dry tea (Camellia sinensis)[J]. Planta Medica,2003,69(9):882-884.
[6]Cebi N,Yilmaz M T,Sagdic O. A rapid ATR-FTIR spectroscopic method for detection of sibutramine adulteration in tea and coffee based on hierarchical cluster and principal component analyses[J]. Food chemistry,2017,229(15):517-526.
[7]Hong M,Yan S,Jiao Y N,et al. Electronic nose sensors data feature mining:a synergetic strategy for the classification of beer[J]. Analytical Methods,2018,10:2016-2025.
[8]潘玉成,宋莉莉,叶乃兴,等. 电子鼻技术及其在茶叶中的应用研究[J]. 食品与机械,2016,32(9):213-218,224.
[9]杨春兰,薛大为. 基于电子鼻技术的茶叶贮藏时间检测方法[J]. 兰州文理学院学报(自然科学版),2016,30(5):51-54.
[10]何鲁南,赵苗苗,蔡昌敏,等. 电子鼻技术对不同贮藏地的普洱茶香气分析[J]. 西南农业学报,2018,31(4):717-724.
[11]潘磊庆,唐 琳,詹 歌,等. 电子鼻对芝麻油掺假的检测[J]. 食品科学,2010,31(20):318-321.
[12]Brudzewski K,Osowski S,Dwulit A. Recognition of coffee using differential electronic nose[J]. IEEE Transactions on Instrumentation and Measurement,2012,61(6):1803-1810.
[13]Wei Z B,Wang J,Zhang W L. Detecting internal quality of peanuts during storage using electronic nose responses combined with physicochemical methods[J]. Food Chemistry,2015,177:89-96.
[14]Sysoev V V,Button B K,Wepsiec K,et al. Toward the nanoscopic “electronic nose”:hydrogen vs carbon monoxide discrimination with an array of individual metal oxide nano- and mesowire sensors[J]. Nano Letters,2006,6(8):1584-1588.
[15]Yang Z R,Zwolinski M. Mutual information theory for adaptive mixture models[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2001,23(4):396-403.
[16]Jia X M,Meng Q H,Jing Y Q,et al. A new method combining KECA-LDA with ELM for classification of chinese liquors using electronic nose[J]. IEEE Sensors Journal,2016,16(22):8010-8017.
[17]Qiu S S,Wang J. The prediction of food additives in the fruit juice based on electronic nose with chemometrics[J]. Food Chemistry,2017,230:208-214.
[18]Wang Z,Sun X Y,Miao J C,et al. Conformal prediction based on K-nearest neighbors for discrimination of ginsengs by a home-made electronic nose[J]. Sensors,2017,17:1-12.
[19]Bhattacharyya N,Metla A,Bandyopadhyay R,et al. Incremental PNN classifier for a versatile electronic nose[C]// IEEE. 3rd International Conference on Sensing Technology. Taiwan,2008.
[20]黃 鹍,陈森发,孙 燕,等. 基于小波网络和证据理论的多源信息融合系统研究[J]. 数据采集与处理,2003,18(4):434-439.
[21]段志梅,程加堂. 基于多源信息融合的异步电机故障诊断[J]. 煤矿机械,2014,35(2):235-237.
[22]唐向阳,张 勇,丁 锐,等. 电子鼻技术的发展及展望[J]. 机电一体化,2006,12(4):11-15.
猜你喜欢
广东茶业(2019年2期)2019-06-18
中医眼耳鼻喉杂志(2019年3期)2019-04-13
妇女生活(2018年2期)2018-02-27
科技资讯(2017年11期)2017-06-09
现代电子技术(2017年7期)2017-04-14
百科探秘·航空航天(2016年6期)2016-12-01
小主人报(2015年1期)2015-11-06
食品工业科技(2014年15期)2014-03-11
四川生理科学杂志(2014年1期)2014-02-28
食品科学(2013年8期)2013-03-11
