
基于BERT预训练语言模型的电网设备缺陷文本分类
2020-09-21 03:16刘海斌满志博毛存礼
南京理工大学学报 2020年4期
田 园,原 野,刘海斌,满志博,毛存礼
(1.云南电网有限责任公司信息中心,云南 昆明 650000;2.昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
利用信息技术实现智能电网设备故障分析具有十分重要的价值[1]。电网设备故障分析传统的方法主要有基于数据挖掘方法、基于分类的方法、基于聚类的方法。韩博闻[2]提出基于Apriori关联算法的配电网运行大数据关联分析模型,挖掘配电网运行维护中各运行因素与运行维护指标之间的显性或隐性关联。刘科研等[3]提出了基于数据挖掘的配电网故障关联因素分析与风险预警方法,有效提高了配电网风险预警的准确性。洪翠等[4]提出以故障分量均方根及欧氏距离为特征量,结合改进多分类支持向量机(Support vector machine,SVM)的配电网短路故障识别方法。张斌等[5]提出结合降维技术的电力负荷曲线集成聚类算法,解决电网中由于电力负荷过低引起的异常问题。然而,这些方法都是基于特征工程的方法,进行设备故障分类时很大程度上依赖于故障数据的数据集大小以及特征选取的准确性,由于电网中的故障数据无规律、关联程度小等特点,基于特征工程的方法受到了一定程度的局限。近年来,随着深度学习技术在图像处理、语音识别、自然语言处理等方面取得显著的效果[6-8],一些学者尝试将深度学习方法应用于设备故障任务中。朱元振等[9]提出基于深度学习直流闭锁判断的高风险连锁故障快速搜索方法,能够快速给出高风险交直流连锁故障的传播路径和故障概率,可用于在线安全预警和防控决策。孙宇嫣等[10]提出基于深度学习的智能变电站通信网络故障诊断与定位方法,仿真结果验证了所提故障诊断方法即使在通信网络部分信息不可信时仍能得到准确诊断结果,容错性能较好。
这些研究主要是针对设备是否可能存在故障进行分析,很少考虑根据电网设备缺陷文本识别电网设备缺陷部位,这是电网设备故障分析的一个关键环节。电网设备缺陷文本识别可以采用文本分类的方法来处理,但由于电网设备缺陷文本中词汇具有很强的领域特点。因此有效获取电网设备缺陷文本中有关设备、缺陷部位、故障表象等语义特征有助于提升缺陷部位文本分类的准确性。最新研究发现预训练语言模型在自然语言处理很多任务中表现出非常优秀的性能。为此,本文提出一种基于双向Transformers偏码表示(Bidirectional encoder representation from transformers,BERT)预训练语言模型的电网设备缺陷文本分类方法。首先,基于BERT预训练语言模型对电网设备缺陷文本进行预训练生成具有上下文特征的Word embedding向量作为模型输入。同时,为避免电网领域分词错误影响模型效果,把电网设备缺陷文本中由数字与字母组合的设备ID、设备名称以及由多个词汇构成的缺陷特征词汇作为领域词汇来处理,然后,利用BiLSTM网络对输入的电网设备缺陷文本向量进行双向编码提取表征缺陷文本的语义表征,并通过Attention机制增强电网设备缺陷文本中与缺陷部位相关的领域词汇的语义特征权重,进而得到有助于电网设备缺陷部位分类的语义特征向量。最后,通过模型的SoftMax层实现电网设备缺陷部位分类。
1 电网设备缺陷数据特点
电网设备具有类型多样、分类复杂等特点,如,常见的设备断路器可以分为中压断路器、SF6断路器、真空断路器、低压断路器、柱上断路器、油断路器等10余种类型,不同类型的设备具有不同的缺陷特征。本文以云南电网某生产域业务系统中收集的“SF6真空断路器”、“主变压器”这两种设备缺陷部位的结构化数据来构建用于模型训练的缺陷文本数据,图1展现了主变压器缺陷元数据逻辑结构及数据特征。
2 基于BERT预训练语言模型的电网设备缺陷文本分类模型
2.1 模型架构
基于BiLSTM-Attention的方法能够捕获文本中的深层语义特征,在文本分类任务中取得了较好的效果[11-13]。本文将电网领域设备缺陷部位识别过程看作文本分类任务,提出的基于BERT预训练语言模型的电网设备缺陷文本分类模型框架如图2所示,主要包括以下3个部分:
(1)输入层。为了得到电网设备缺陷文本表示,本文将记录电网设备故障数据的结构化特征及描述故障现象的非结构化特征构造为具有上下文信息的文本,同时,为避免分词错误造成的影响,本文将设备名称、设备缺陷类型、缺陷部位等结构化特征作为电网领域专业词汇。
(2)词嵌入层。将输入层构建的设备缺陷文本中的词汇进行Word embedding表示,并拼接生成表征文本的向量输入到网络模型中。Google在2018年提出的预训练语言模型BERT[14]是一种基于Transformer网络结构,能够根据当前的文本输入,分别计算Key、Query和Value向量,并基于上述向量对每个输入使用注意力机制,以获得当前输入与上下文语义的关系和自身所包含的信息,并通过多层累加和多头注意力机制,不断获取当前输入更为合适的向量表示,生成的词向量是一种动态的形式。为此,本文基于BERT预训练语言模型生成电网设备缺陷文本词汇Word embedding向量,不仅能够有效获取词汇的上下文信息,而且能够有效获取缺陷文本中领域词汇的语义特征。
(3)双向长短时记忆网络(Bi-directional long short-term memory,BiLSTM)。对输入的电网设备缺陷文本向量进行双向编码训练,获得前向和后向的电网领域设备信息的加和,生成具有上下文语义特征的电网故障文本向量。例如,电网设备主变压器缺陷数据“冷空箱端子排变色发热”。通过正向编码可以捕捉到“冷空箱”,“端子排”等信息,通过反向编码则可以捕捉到“变色发热”,采用双向网络编码可以捕捉更完整的语义表征。
(4)注意力(Attention)层。在文本分类任务中Attention机制能够捕捉到与分类任务相关的重要特征[15]。为此,本文通过Attention层来获取电网设备缺陷描述文本中有关缺陷部位词汇特征实现对BiLSTM层提取到的文本特征向量进行加权,进而得到电网设备缺陷文本的语义特征向量。
(5)输出层。将BiLSTM-Attention层获取到的电网设备缺陷文本语义向量输入SoftMax函数实现电网设备故障部位分类。
2.2 模型训练
(1)数据预处理。由于电网领域的数据特点,从故障设备记录中选取这些缺陷文本,这些文本中包含许多错误或者没有实际意义的符号组合,例如,设备名称中包含“36 kV负载器#¥%*&&”字符,其中,这些特殊符号“#¥%*&&”是错误的信息。为此,利用Python通过编写规则化的表达式将这些无意义的符号进行预处理删除。另外,这些设备故障的文本都是具有一定的整体性,这样的特点导致这些文本无法直接进行处理。如果直接利用分词工具或者分词接口会导致部分电网中的数据被切分为无意义的词语组合,例如,“更换分闸线圈”、“紧固螺栓后正常”、“分闸线圈烧坏已进行更换”、“经加油后正常投运”、“更换行程开关”、“申请紧急缺陷停电更换新元件”等这些缺陷文本中的电网故障词汇都是不能够直接通过分词拆分的。为了将这些电网专业领域的词汇信息保留最大化,本文将利用数据库中的电网故障设备的设备名称、缺陷部位、设备缺陷表象等结构化特征构建了电网领域词典,并且结合电网领域的词典及结巴(Jieba)分词工具实现设备缺陷文本分词预处理。
(2)基于BERT预训练的词嵌入层向量表示。输入一句给定的电网设备缺陷文本S:S缺陷文本=x1,x2,…,xT,其中,xi表示文本S中的第i个词汇,基于BERT预训练好的中文词向量包含三部分:基于当前词位置的表示转化为其词向量的表示为EL=el1,el2,…,elT,基于当前词的表示转化为其词向量的表示为EW=ew1,ew2,…,ewT,基于上下句信息的表示转化为其向量的表示为ES=es1,es2,…,esT,那么,基于BERT预训练后具有整体文本语义信息的故障设备词向量表示为
eberti=eWi+eLi+eSi
(1)
由不可拆分的结构化属性构成的电网领域专业词汇通常由多个词汇组合构成,应作为整体化处理,这些专业词汇的词向量表征为
e专业词汇=W专业词汇v专业词汇
(2)

对于输入模型的第i个词语ei的词向量表示分为两部分,分别是基于BERT生成的词向量eberti与专业词汇微量e专业词汇的拼接,如式(3)所示
ei=eberti+e专业词汇
(3)
根据式(3),句子S缺陷文本将被转化为一个具有特定的故障设备信息的实数矩阵:embs={e1,e2,…,eT},并传递给模型的下一层。
(3)双向LSTM(BiLSTM)神经网络层由两个部分构成:①自前向后的单层LSTM;②自后向前的单层LSTM。
文中,利用LSTM网络门控机制,具体公式为
it=σ(Wxixt+Whiht-1+Wcict-1+bi)
(4)
ct=(1-it)·ct-1+it·tanh(Wxcxt+Whcht-1+bc)
(5)
ot=σ(Wxoxt+Wh0ht-1+Wcoct+bo)
(6)
ht=ot·tanh(ct)
(7)

(8)
这样的正向和反向的状态结合,充分体现了BiLSTM的特点,结合电网设备缺陷文本从前至后又从后至前地将整句话中的重要信息,即考虑到了上下文中的语境,又做到通过整体的环境进行特征提取,保证特征不丢失的特点。将LSTM层输入的向量集合表示为H:[h1,h2,…,hT]。
(4)基于Attention机制的特征加权。如图2所示,在BiLSTM后生成了对应每个词嵌入对应的隐状态序列H:[h1,h2,…,hT],针对电网缺陷文本数据,例如,“冷空箱”,本文中对其进行结构化的构造,其得到的权重h1在Attention机制中得到的整体权重更大,可以更好的提取描述语句的特征。
在Attention模型中,实质是设备缺陷文本编码—设备缺陷部位解码的过程,可以看作是序列到序列的处理方式。具体如图3所示。
在电网设备缺陷部位解码的过程中,计算yk的公式表示为
yk=D(ck,y1,y2,…,yk-1)
(9)
式中:ck是通过输入的编码过程中设备缺陷文本的训练数据进行一个non-linear得到的值。那么,ck可表示为
(10)
式中:aik表示第i个数据输出的注意力分布,S(eT)表示模型中输入的相应的函数变化数值。
aik=F(hi,Hk)
(11)
式中:hi为i时刻的电网设备缺陷文本向量正向和反向隐状态的加和,Hk是输出数据yk在解码端的的隐状态,F为计算符合状态的概率和。
那么,在BiLSTM-Attention模型中,将LSTM层输入的向量集合表示为H:[h1,h2,…,hT]。
M=tanh(H)
(12)
式中:M表示由BiLSTM的设备缺陷文本的输出H对最终的状态的注意力概率分布。
α=softmax(wTM)
(13)
式中:wT表示训练过程中电网设备缺陷文本生成的权重参数,w={w1,w2,…,wn},w1表示“冷空箱”,这个专业词语在训练过程中生成的特征权重,本文通过Attention机制增强电网设备缺陷文本中与缺陷部位相关的领域词汇的意义特征权重。
其Attention层得到的权重矩阵r由式(14)得到
r=HαT
(14)
在该权重矩阵中,包含提取到的专业词的特征权重加权,利用BERT预训练生成的词向量表示更加加强了语义的特征。例如,w1表示“冷空箱”这个专业名词的特征权重,在预训练过程中,由BERT提供预训练的词向量,结合该句的上下文w={w1,w2,…,wn},w1与w2以及wn之间具有不可分割的语义关系。
最终用于分类的电网设备缺陷句子将表示为
h*=tanh(r)
(15)
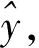
(16)
(17)
式中:S表示输入的设备缺陷语句,bs为训练过程中生成的随机参数。
(6)目标损失函数。在整个训练过程中,针对本文提出的电网领域缺陷文本的分类问题,是一个多分类的问题,经过归一化处理softmax输出后的标签的概率与真实的标签分布概率计算损失函数,具体如下
(18)
式中:m为电网设备缺陷部位标签的个数,t∈Rm为正样本的向量化表征,y∈Rm为softmax估计出的每个类别的概率,λ是正则化的超参数。
3 实验
3.1 实验环境及实验数据集
本实验基于Tensorflow框架进行实验,Tensorflow框架整合包含了大部分的深度学习中的神经网络模型。具体实验环境及其配置如表1所示。

表1 实验环境
在本文实验中使用了来自电网的设备缺陷数据信息,通过筛选、去除无用信息留下主变压器33 701个缺陷文本,SF6真空断路器50 139个缺陷文本,将两种数据按照1∶1∶8的比例进行模型的测试集、验证集以及训练集数据分配。
3.2 超参数设置及实验评价标准
3.2.1 超参数设置
本文涉及到的对比实验的相关参数设置为SVM分类器的核函数为线性核函数;FastText模型中,词向量的维度选择300维,训练轮次Epoch为20;BiLSTM模型中,词向量的维度选择300维,训练轮次Epoch为140;CNN模型中,词向量的维度选择300维,训练轮次Epoch为140。
本文方法在实验中模型的超参数设置如表2所示。

表2 实验超参数设置表
3.2.2 实验评价标准
精确率(Precision),即正确预测为正的占全部预测为正的比例。查准率,即设备缺陷文本真正正确的占设备缺陷文本所有预测为正的比例。
召回率(Recall),即正确预测为正的占全部实际为正的比例。查全率,即设备缺陷文本真正正确的占所有缺陷文本实际为正的比例。
F1值:精确率和召回率的调和均值。具体公式为
(19)
(20)
(21)
3.3 实验对比及结果分析
实验1不同方法设备缺陷文本分类效果对比。
为了验证本文提出的基于BERT预训练语言模型的电网设备缺陷文本分类的效果,设计对比试验结合两种设备缺陷(主变压器、SF6真空断路器)数据进行分析。
实验1中利用Word2Vec[16]训练电网设备缺陷文本集语料以及FastText预训练好的在中文词向量对本文实验的语料进行预处理[17]并进行缺陷文本分类处理。
对比模型:基于SVM的分类方式[18],基于卷积神经网络(Convolutional neural networks,CNN)提取到语句之间的特征分布的分类方法[19]以及利用LSTM(Long short-term memory,LSTM)处理文本之间任务[20]。利用不同的词向量生成方式,以及本文基于BERT预训练语言模型对电网设备缺陷文本的词向量生成方法,本文设计实验1的对比实验如表3、表4所示。对主变压器和SF6真空断路器这两种设备缺陷文本分类实验得出以下结论。

表3 主变压器:不同方法设备陷部文本分类结果对比
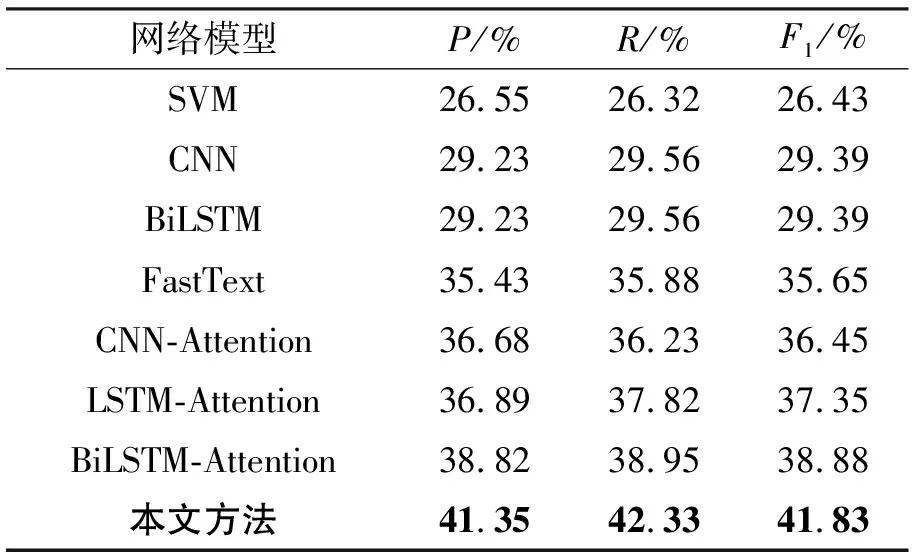
表4 SF6真空断路器:不同方法设备陷部文本分类结果对比
(1)在两种数据集中,本文方法都体现出较好的效果,两种数据集中的专业词汇的复杂程度与组合方式都不同,这样的组合方式在一定程度上会影响识别的准确性。例如,在主变压器中,大多的缺陷部位名称的特点是较为短且组合较少,“风机”、“冷却器”、“油位表”等,在SF6真空断路器中,大多的设备名称的特点组合较多,例如“瓷质绝缘子”、“密度继电器表盘”、“时间继电器”等。
(2)利用FastText的方法,不能更好地结合设备缺陷文本的数据特点进行训练,CNN着重提取数据特征,但这也有可能会忽略了模型局部重要的特征提取,单纯地使用BiLSTM在长文本上是不具有显著的特征的,在电网设备缺陷文本中有大量的长文本句子描述。LSTM的方法不能够前向以及后向捕捉语义的信息,文本不具有上下文的信息,效果较差。本文提出的方法不仅在模型输入的词嵌入层能够根据词汇在设备缺陷文本的上下文信息生成动态的word embedding向量,而且能够更好地结合Attention机制提取设备缺陷部位与文本中缺陷特征词汇之间的关系。
实验2预训练词向量对实验结果的影响。
为了验证不同词向量对实验结果的影响,本文对比了基于Word2Vec[16]、GloVe[21]、BERT[14]3种词向量生成方式下设备缺陷文本分类实验,在实验2中,本文将主变压器33 701个设备缺陷文本以及50 139个SF6真空断路器缺陷文本进行混合得到83 840个缺陷文本,将两种数据混合训练,进而验证本模型的通用性,对比结果如表5所示。
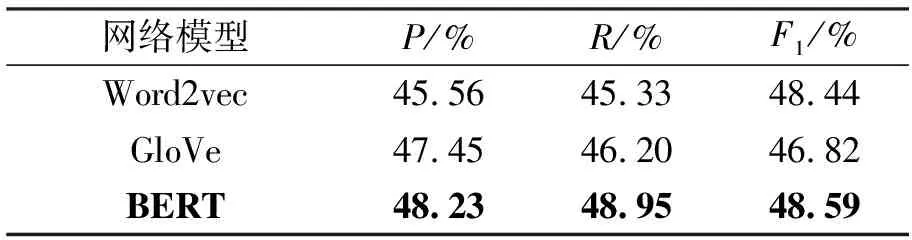
表5 不同词向量方式对实验结果的影响
从表5中的结果可以看出,基于Word2Vec的词向量生成方式分类效果最差,基于预训练BERT模型生成的词向量产生的分类效果明显高于另外两种。由此可见,本文提出的基于预训练语言模型的方式生成电网设备缺陷文本的词向量具有文本的上下文特征,更能准确地表征电网设备故障词汇的语义特征,尤其是针对故障缺陷文本中表征缺陷特征的专业词汇的词向量具有更好的效果,而基于Word2Vec的方式生成的词向量不考虑具体的上下文语义信息。
实验3领域词汇对实验结果的影响。
为验证电网设备缺陷文本中领域词汇特征对模型效果的影响。分别采用通用分词工具和领域分词对电网设备缺陷文本进行分词实验对比,其中,通用分词使用jieba分词工具,领域分词采用构建的领域词典+jieba分词,实验结果分别如表6、表7所示。
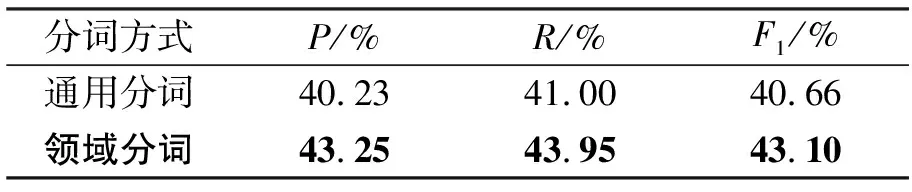
表6 领域词汇对主变压器实验结果的影响
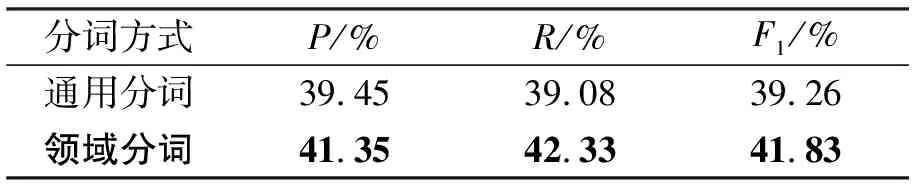
表7 领域词汇对主变压器实验结果的影响
从表6和7可以看出,采用领域分词的效果明显高于直接使用jieba分词的效果。本文将电网设备缺陷文本中由数字与字母组合的设备名称以及由多个词汇构成的缺陷特征词汇作为领域词汇来处理,如,“SF6真空断路器”,“瓷质绝缘子”,“CPU插件”,“空压机油乳化”,“信二次回路”“硅胶变色”等。这些词汇如果直接使用jieba分词后将导致具有完整语义的设备缺陷特征拆开后导致语义信息丢失,而作为领域词汇利用BERT进行词向量表征后能够有效获取到电网缺陷词汇的语义特征,更有利于通过Attention层进行捕捉。
4 结论
电网设备缺陷部位识别是设备故障分析的关键环节。针对这个问题,本文提出了一种基于BERT预训练语言模型的电网设备缺陷文本分类方法,该方法在基于BiSLTM-Attention的模型基础上考虑了电网领域的设备缺陷文本特点,结合BERT预训练语言模型的方法使生成的词向量具有缺陷文本的上下文信息,更好地将电网设备缺陷部位识别转换为文本分类任务。实验结果表明了提出的方法在主变压器、SF6真空断路器这两种设备缺陷数据集中,相比较于Baseline的F1值有明显提升,从而验证了本文方法的有效性。下一步,可以将该方法应用在类似领域中的相关设备缺陷分析任务中。
猜你喜欢
能源工程(2022年2期)2022-05-23
新高考·高一数学(2022年3期)2022-04-28
今日自动化(2022年1期)2022-03-07
数学大王·趣味逻辑(2021年11期)2021-12-03
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中华胰腺病杂志(2021年1期)2021-02-26
文理导航·趣味课堂(2016年5期)2016-07-21
文理导航·趣味课堂(2016年4期)2016-06-01
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
