
融合语义激光与地标信息的SLAM技术研究
2020-09-15 04:48何炜婷
计算机工程与应用 2020年18期
杨 爽,曾 碧,何炜婷
广东工业大学 计算机学院,广州 510006
1 引言
重定位是指由于外界因素的影响,移动机器人会丢失其实际位置,需要重新定位以修正其错误位姿,依赖即时定位与地图构建(SLAM)技术中定位算法的自适应能力。目前在SLAM 的实际应用中包含多种定位算法。比如Hanten[1]和Wang 等人[2]提出的自适应蒙特卡罗定位算法,对传统基于粒子滤波原理的蒙特卡罗定位算法[3]耗时较长、应用环境单一等缺陷进行改进,提高了它们在定位过程中的自适应能力。但其对里程计(记录速度、位移等运动量的相关方法)信息依赖程度过高,观测灵敏度也不够。在变化频繁的动态环境中,碰到位置漂移,机器人定位被劫持这些意外情况时,该类算法的容错性并不高,定位仍存在问题。文献[4-5]则是针对SLAM中的扫描匹配过程进行了改进,不仅减少了观测匹配和位姿估计的时间,还降低了算法对环境特征的依赖,但由于其基础算法本身易受环境因素的影响,在特征稀少的动态场景中,重定位效果依然不好。
目前基于深度图像信息的视觉SLAM 方法发展迅速,见文献[6]。本文依赖地标物体准确的位置信息来进行重定位,而在视觉SLAM算法[7]的研究应用中,已经有很多学者提出了把地标作为参照物,用来修正机器人位姿的算法,如主流的ORB-SLAM[8]和LSD-SLAM[9]算法。除此之外,Frintrop等人在文献[10]中提出的位姿图优化算法,以及地标的自动识别与配准方法[11],都是在区域内人为使用(设定)少量的地标,丰富该区域的特征信息进行图优化,提高匹配对比的准确性,达到优化定位精度的目的。因为对于这类算法,观测信息越可靠,位姿估计也就更加准确。
这些利用地标信息的视觉SLAM 算法均能通过后端优化来重新修正错误位姿。一些方法[12-14]在此基础上引入了IMU传感器,进行数据融合,把视觉和惯性测量信息紧密耦合在一起,就能进一步提高定位精度,缩小偏差。但从长远的趋势上来看,机器人的位姿漂移现象仍然存在。所以张玉龙等人基于此在文献[15]中提出了一种闭环检测算法,用于修正位姿漂移,重新找回初始定位。Kasyanov等人也提出了一种KBV(IKey frame Based on Visual Inertia)算法[16],在整个SLAM过程中,采用闭环检测方法,在过去的关键帧中找到与当前关键帧的最佳匹配,以此来优化机器人的运动轨迹,不仅如此,在机器人丢失位置之后,也能通过这种关键帧匹配方法重新定位。该算法的重定位性能良好,但由于使用的视觉传感器在获取深度和角度信息时,易受光线、观测方位等多方面因素影响,位姿修正结果往往不如人意。
2018 年,Zhang 等人[17]专门为环境信息中的地标提出了一种概念——设立及识别自然地标,并建立自然地标库。通过对地标图像进行特征检测与匹配,完成对自然地标的准确识别,从而达到提高机器人定位精度的目的。
机器人在室内环境中导航,基于多传感器数据融合的SLAM 技术[18]是目前较为热门的研究方向。激光信息测距十分准确,而视觉传感器获取的图像信息则更为丰富,为了结合两种数据的特性,本实验室曹军等人在文献[19]提出了一种将离散的激光点聚类成激光簇的方法(本文将该算法简称为C-Clustering),用于加强环境特征,缩小了重定位的检测范围,在文献[20]中提出了一种视觉信息与激光数据融合的方法(本文将该算法简称为C-Fusion)。通过这两种方法可以给激光数据赋予语义标签,因而本文利用此研究基础,在SLAM 过程中,基于语义激光数据和地标物体提出了一种重定位方法(Relocation based Semantic Laser and Landmark Information,RLSLALI),该方法借助激光感知与视觉识别融合后的语义激光信息,结合地图环境中的地标物体搭建地标数据库,建立位姿转化模型,修正机器人错误定位。在室内动态场景中,其定位健壮性高,可在标准硬件设备上正常运行且不易受环境等因素影响。
2 一种基于语义激光与地标信息的机器人重定位算法
人类在日常行车过程中,即使有全球定位工具,在经过一些复杂、偏僻的路段时,依然容易迷失,往往需要借助路边的指示牌或者标志性建筑物来确认自身所处位置。由此,本文提出一种利用语义激光及地标信息进行重定位的方法,用激光传感器获取距离、位置等定量信息,而分类、名称等语义信息则使用视觉传感器得到。这样既避免了由于激光数据太相似导致的误识别与误匹配,又能减少光线、角度等影响视觉检测的因素所带来的数据误差,适合室内动态环境。算法整体结构见图1。

图1 重定位算法结构图
2.1 搭建地标数据库系统
2.1.1 云地标库的建立
本文之所以提出建立地标数据库,是因为并不是所有的物体都能设为地标,要依赖相关权限进行授权。而云地标库就相当于授权者、各机器人在不同的环境中,均可通过查找匹配云地标库中的数据内容,初定当前环境中的候选地标,所以也可将云地标库称作候选地标库。在构建云地标库的过程中,最为关键的部分就是筛选条件的设定,用于判断物体是否有成为地标的资格,设定原则如下:
(1)物体的图像特征要明显,如色彩鲜艳、样式丰富等,或自身就具有可辨识的标志。
(2)物体形状尽量扁平化,就能保证在多个角度识别到地标时,也不会存在明显的位置偏差;如果是形状或位置会变化的物体,则拒绝,以此保证基础数据的准确性。
基于此,在本文的实验测试中,在云地标库中录入了两大类物体,一种是类似于高速公路上指示牌,一种是贴在墙壁上的壁画。可将本文地标数据库系统表示为图2。

图2 地标数据库系统
2.1.2 有效地标库的建立
在建图过程中,通过查找云地标库中的数据内容,可在识别出的物体中筛选出候选地标。但这样还不够,除云地标库外,还需建立多个有效地标库,见图2。那是因为通过云地标库筛选出的候选地标,很难达到算法的实际要求,需要针对每个运行场景,单独成库,利用各候选地标的相对位置关系进行判断,筛选出在当前环境下可用的地标物体。
相对位置关系的约束条件设置为:
(1)地标的位置尽量挑选在不常访问的地方(靠墙或者角落等)。
(2)如果一个地图环境中存在多个地标,则各个地标的位置不能太过稠密,要分散选择,尽量做到地图环境的全覆盖。
这样便可初步建立有效地标库,再结合2.2.1 小节融合视觉信息与激光数据的方法,获取每个地标物体在地图上的位置坐标,就能顺利完成有效地标库的搭建,详见2.2.2小节。
2.2 创建地标名称与位置坐标的关联映射表
建图过程中,本文算法在融合激光感知与视觉识别的基础上,根据地标库系统的约束条件,筛选并确定当前环境中的可用地标;在有效地标库中创建地标名称与全局位置坐标的关联映射表。对应流程见图3。

图3 创建映射表流程
2.2.1 融合视觉信息与激光数据
首先通过C-Clustering 算法对激光数据进行聚类,可得到每个激光扫描点的聚类标签,对应每个扫描点的类别信息为{c1,c2,…,cn} ,由于激光雷达的工作原理是在极坐标系下每隔一定角度(角度分辨率)θ发射和接收激光信息,获得测量距离d,假设所使用的激光传感器每帧测量数据包括了n个扫描点,则激光雷达数据可用公式(1)表示,L中每个元素 (θi,di)表示第i个激光扫描点在激光雷达极坐标系下的角度和距离。

通常激光扫描点的信息可以转换到直角坐标系(2)下表示,D中每个元素表示第i个激光扫描点的笛卡尔坐标,其中l 代表local,是指以激光雷达中心为原点构建的局部坐标系。

接着根据C-Fusion 算法给聚类激光与物体语义进行融合,赋予每个激光扫描点语义标签。同一类的激光数据可聚类成一个激光簇,对于每个激光簇j,将对应物体的标签及标签概率赋予激光簇内每个激光扫描点,所以激光扫描点可能存在多个标签及标签概率。最终联合可得式(3):

其中,Sj={(li,p′ij):p′ij >0}。li表示第i个物体的标签,p′ij表示第j个激光簇属于视觉检测结果中第i个物体的概率。
在此过程中,利用YOLOv3算法获取地标等物体的语义信息。通常情况下,当运行环境中存在较多符合云地标库约束的物体时,仅通过coco公开数据集预训练好的模型便可完成物体的识别分类,实现成本相对较低。但是当环境中的物体较少且具有特殊性,或者重复物体过多时,信息的获取难度加大,此时视觉检测模型的性能并不能满足本文算法的需求。为了保证机器人在运行过程中,能够稳定获取准确的基础数据,首先要确保视觉识别的有效性。所以就需要针对当前运行环境,进一步训练调优视觉检测模型。该部分的前期工作大致可分为三步。第一步是要添加当前环境对应的目标检测数据集,并对它们进行数据增强。这一步尤其重要,首先在距离远近、背景简单与复杂、亮度高低这几种条件下对环境中的物体实拍400(50×2×2×2)样张图片。紧接着使用工具程序对这400张图片进行随机类型(增强类型有调节饱和度、亮度、对比度、左右翻转、旋转0~30°等)的数据增强。对整个样张集反复增强5次,得到包含2 000张图片(400×5)的有效数据集,通过这些数据的训练,就能降低识别过程中随机性的影响;第二步是结合实际环境中的物体,在视觉检测模型中重新设定分类(以本文实验为例,虽然有多个指示牌,但是本文将其分为指示牌1 类、指示牌2 类等);第三步则是要利用k-means函数根据第一步得到的数据集计算出9种类型的初始候选框尺寸,以此提高识别准确率。然后自行确定检测模型中几个基本参数的初始值(学习率、衰退率等)。基于此,便可利用该有效数据集,继续训练模型,达到算法适应特殊环境的目的。而激光数据的获取相对简单,通过激光雷达扫描周围环境,并获取环境中各物体的位置信息。基于此,经过以上方法,即可完成视觉检测结果与激光雷达信息的融合,产生语义激光数据。语义激光数据Z中每个元素不仅包含原始激光扫描点位置信息,还包含聚类标签和物体标签及其对应的标签概率,模拟运行过程见图4。

图4 赋予地标语义标签示意图
2.2.2 设置有效地标
采用以上融合方法可得到场景中物体的语义激光数据,因此本文利用该方法设置有效地标(既能识别出地标的分类,又能记录其对应的位置信息)。这样机器人在后续的导航过程中,就可依赖准确的地标信息来修正自身位姿偏差。在2.2.1 小节的融合过程中,通过标定参数使相机和激光雷达的探测范围一致。激光聚类,可使识别出的每一个物体都对应一束激光簇,一束激光簇中又包含多个激光数据点,对应多个位置坐标,而同一个物体又无法用多个坐标定位,所以C-Fusion算法中有个特定的约束,选取激光簇中心激光点记录的坐标代表对应物体的位置,视觉识别出的物体分类信息也就可以看做是其中心激光点的语义标签。所以利用式(3)和SLAM 技术中gmapping 建图算法将各物体相对激光雷达的局部坐标转换成当前地图的全局坐标。同时获取物体的语义标签及标签概率,将每个物体的标签结合它的标签概率与2.1节建立的云地标数据库中的数据内容匹配对比出候选地标,再根据各候选地标在运行场景中的位置约束,自适应地确定当前环境中最终可使用的地标物体,并存入有效地标库,作为用于修正错误定位的有效地标。所以在位姿转换模型中,可将每个地标物体看作一个点,一个语义名称对应一个坐标点,联合可推得下式:

其中,g 代表global,是指以世界地图中心为原点构建的全局坐标系;mm表示当前环境包含有效地标的数量,表示第mm个地标在全局笛卡尔坐标系下的横坐标,表示其纵坐标,Kmm表示第mm个地标的语义名称。
由此,可在有效地标数据库中通过式(4)创建地标名称和地标全局位置坐标的关联映射表,见表1。

表1 地标名称与位置坐标的关联映射表
在后续修正定位的过程中,与此部分一致,机器人可能会从不同视角、方位观测到地标物体,但不论哪种情况,只要能识别出地标的语音名称即可,具体进行位姿推导时,是将每个地标物体当作地图上的一个点,获取其全局位置和局部位置,不受机器人观测位置和观测角度的影响,满足实际情形中可能会遇到的各类情况,详见2.4节。
这部分的研究工作是为了在当前构建的地图上设置地标物体,搭建有效地标库,并给这些地标赋予语义名称,同时记录其(其中心激光点)在地图上的全局坐标,创建地标名称-位置坐标的关联映射表,为位姿推导模型提供数据支持。传统方法中,通常是人为设定地标物体,不仅需要花费大量的人力、时间成本去完成设置,还需要在算法中预先输入地标位置的定值、可变性差,前期准备工作繁琐。而通过本文方法搭建地标库,仅需要针对运行环境,完成视觉检测模型训练调优的前期工作,机器人便可根据各类条件自主设定地标,并将相关信息在算法中动态更新,即使地标发生改变,也能通过重新建图自主更新地标库。不仅如此,所有使用者还能为云地标库提供负反馈,提交库中缺少的地标种类,让本文算法自适应各类实际运行环境。
2.3 获取各类数据
2.3.1 获取地标物体的全局坐标
由上可知,完成地图与有效地标库的建立工作后,利用式(4)创建的映射表可以直接得到地标物体在地图上的全局坐标,但是在映射表中可能存在多个地标物体,不能盲目地选择一个用于求解,必须要让机器人认清周围是哪个地标,所以必须通过地标名称来筛选查找。
模拟人类用眼睛分辨物体信息,本文基于视觉传感器,采用目前主流的深度学习方法进行视觉识别,得到被识别物体的语义信息。比较各种物体检测算法,发现它们在实时性和准确率这两方面不能同时满足本文需求。由于机器人在导航时处于运动状态,对运算实时性要求较高,所以在此优先考虑了YOLOv3-Tiny 检测模型,经过实验验证,在运动过程中,YOLOv3-Tiny虽然识别物体速度能达到本文需求,但正确率较低,特别是在复杂环境下识别较远位置的地标时,检测效果很不理想。
针对以上问题,本文在YOLOv3-Tiny物体检测模型研究的基础上提出了Acc-YOLOv3(Accurate YOLOv3)算法。首先,由于YOLOv3-Tiny只有13×13特征尺寸图(对应候选框为(116×90),(156×198),(373×326))和26×26 特征尺寸图(对应候选框为(30×61),(62×45),(59×119))两种特征图尺寸。所以在其基础上加上52×52特征尺寸图(对应候选框为(10,13),(16,30),(33,23)),来增加远距离小物体识别的正确率。原理见图5,特征图尺寸越小,对应候选框越大,识别的是较大目标;特征尺寸图越大,对应候选框越小,识别的是较小目标。例如:图5(a)与(b)是较小的特征尺寸3×3 和对应较大的候选框;图5(c)与(d)是较大的特征尺寸6×6 和对应较小的候选框。所以,加上52×52 特征尺寸图(对应候选框为(10,13),(16,30),(33,23)),可以提高小目标物体的识别正确率。

图5 候选框选择原理示意图
加入了52×52 特征尺寸图后,检测速度基本不变,但准确率并没有达到期望效果,反而还有些许下降。分析整体架构可知,其提取特征的基础网络层数太少太浅(一共15层),导致用来提取52×52特征尺寸图候选框的网络层太靠近输入端,即候选框中采用的52×52特征尺寸图所在的网络层太浅(第7 层),提取的细粒度还不够,特征还未被提取完就进行识别,导致准确率下降。
所以,参考Darknet19,进一步把YOLO3-Tiny 的基础网络在其基础上分别增加一层52×52和两层26×26尺寸的卷积层,见图6,加强特征提取。

图6 增加卷积层示例
经过实验测试,识别准确率提升到85%以上,识别响应时间基本没受影响,只增加了0.01 s左右,效果可达到本文需求。
基于此,可获取当前运行环境的各物体语义,再通过语义信息查找匹配有效地标库,则可得到地标物体在世界地图上的全局坐标。
2.3.2 获取地标物体的局部坐标
为保证数据来源的准确性,本文RLSLALI 算法使用激光雷达获取地标的局部坐标,避免视觉传感器受光线等环境因素的影响产生偏差。将激光雷达与机器人的安装位置统一,并且在算法中确定了它们的相对关系之后,激光雷达所建立的局部坐标系就与机器人的基坐标系保持一致。
以本文实验所用的rplidar-a2 激光雷达为例,雷达扫描激光数据点间隔设置为0.5°(分辨率),扫描范围设置为正前方的180°,可扫描361个数据点。而雷达的测量数据点是按角度顺序排列的,可知第i个地标物体激光簇中心点对应的第j个数据点在以雷达为中心的极坐标系中的角度θj为:

见图7,假定Ri是机器人附近的第i个地标,对应的第j个激光点,根据激光雷达测距及式(1)可知第i个地标物体在局部坐标系下的笛卡尔坐标为:


图7 以机器人为原点的局部坐标系及其位置关系
2.3.3 获取机器人的偏转角
IMU(惯性测量单元)是一种记录加速度、角速度等运动量信息的工具,其中包含的陀螺仪可以记录机器人运动的转动速度及航向角,但是其值很容易受其他因素的影响,不同环境下的同一个陀螺仪测量值都相差甚大,所以必须针对当前使用场景,对所使用的IMU进行校正标定,使其适配环境。标定完成后,IMU 计算出来机器人偏转角精度高,且健壮性好,因此本文采用IMU作为一种数据源来获取机器人的偏转角α。
2.4 创建位姿推导模型
2.4.1 构建全局坐标与局部坐标的转换关系
导航过程中,当机器人位姿估计产生偏差时,本文RLSLALI算法的理念是以准确的地标信息推算机器人的实时位置,所以必须要在世界坐标系中,建立地标全局位置、地标局部位置及机器人实时位置相互转换的数学模型,图8给出了全局坐标系与局部坐标系的相对关系以及其中的位置坐标转换。图8 中O为世界地图(全局坐标系)的原点。O′为机器人的实时位置,以其为原点构建一个局部坐标系。其中位置关系转换的计算信息如图8中标注,α为机器人相对全局坐标系的偏转角,机器人的实时位置坐标设为(x0,y0),通过转换关系可推得:

其中,lx1,lx2,ly1,ly2可根据地标R的局部坐标以及角度α推导而得,可将转换关系式整理为:

其中,地标相对于全局坐标系的位置坐标,可根据视觉识别结果查找地标名称-位置坐标映射表得到,地标相对于局部坐标系的位置坐标,可根据式(6)、(7)推得。

图8 相对坐标系及各位置坐标转换模型
2.4.2 修正位姿偏差完成重定位
由2.4.1 小节中的式(10)及式(11)理论上可推算机器人当前位姿,图8 给出的是第一象限的坐标转换关系。但是由于实际情况的多样性,比如考虑到机器人及地标物体不可能只处于坐标系的第一象限,机器人有可能运动到全局坐标系的其他象限,地标物体也有可能在机器人局部坐标系的其他象限,所以分析各类场景中的不同情况,可排列组合出64种情况,对每种情况进行推导验算,并完成多组实验测试与分析,可将机器人实际位置的推导式总结为:

通过本文提出的算法,根据多类传感器数据及地标物体信息,可以快速准确地推算出机器人的实时位置坐标(x0,y0)及它的航向角α,从而修正其位姿偏差,完成重定位。机器人修正其错误定位的过程可见示意图9。
综上,本文算法只需要输入视觉信息与激光数据,就能借助地标物体,完成正确位姿的推导,修正其错误定位。伪代码如下:
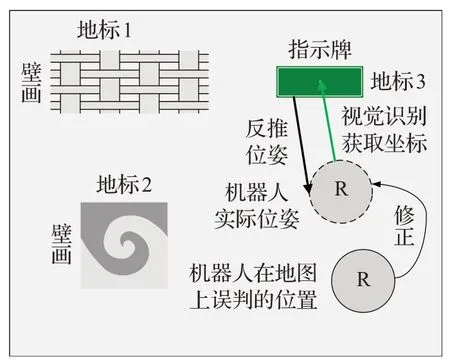
图9 机器人利用地标修正位姿示意图

3 实验分析
3.1 实验平台及实验环境的搭建
为了验证本文RLSLALI 算法的有效性及创新性,搭建了相应的实验平台及实验环境,见图10。本文的实验平台是由PC、相机、激光雷达、IMU 和移动底座这几部分组成。采用ROS 机制下的通信方式进行数据传输,主要算法由PC决策运行。

图10 实验平台及实验环境
其中相机为kinect v1,分辨率:640×480;PC的CPU为i7-8750H,显卡为GeForce GTX 1060;移动底座为Kobuki;IMU为L3G4200D型号的3轴数字陀螺仪;激光雷达为RPLIDAR A2,测距分辨率可达0.5 mm。
为了更好地证明RLSLALI 算法的先进性,验证其更好的定位效果,本文设置了一个室内动态场景作为实验环境:8×7 m2大小,多种障碍物随机摆放,并且在运行过程中有动态人流变化;同时也会人为改变室内光照强度和环境物体摆放的位置等等。
3.2 验证算法的定位性能
本文首先要对比文献[2]、文献[8]与文献[16]中算法的定位性能,验证RLSLALI 算法是否具有有效性与先进性,所以设计机器人在当前环境自主导航6 h,重复航行轨迹12 次,测量72 个误差值(每5 min 记录一次误差值),利用机器人在地图上显示的位置(x,y)与其实际位置 (x′,y′) 的欧式距离表示其误差,在6 h的运行过程中,各算法的定位误差随时间的变化情况见图11。计算误差值的均值,用来说明算法修正定位的精度;计算误差值的方差,用来说明算法在场景中各个位置和各时间段修正定位的稳定性,得到表2的对比数据。图12为各类算法定位性能对比。
3.3 “绑架机器人”后的算法重定位效果对比
为了进一步评估本文算法在3.2节中的实验结果是否准确可靠,本节将通过算法的重定位效果对其分析验证。在当前已知的地图环境中,人为“劫持”机器人一段距离,观察机器人在地图中能否定位到新的位置,及时更新自己的实时位姿。所以本文就人为模拟了“机器人绑架”情况,在SLAM 过程中,把机器人腾空提起,直接搬离至另一个位置,对比RLSLALI 算法与其他算法的重定位效果。

图11 运行过程中各算法的定位误差变化

表2 各类算法定位性能对比表

图12 各类算法定位性能对比
图13 及图14 是环境特征较为明显时文献[2]中AMCL定位算法与本文RLSLALI算法的重定位效果对比,其中黑色和灰色所围成的部分是当前环境的地图表示,黑色圆圈O表示的是当前时刻机器人在地图上显示的位姿,也就是误判位姿,而绿边白色圆圈N 表示的是机器人在当前环境的实际位姿。图13是文献[2]中AMCL算法的重定位效果,其中的图13(a)代表t时刻人为把机器人从黑圆O 位置搬离到白圆位置,图13(b)代表t+1 时刻机器人的位姿更新状态,在地图上观察到机器人还是在原来位置的周围,并未进行明显的位姿更新,而图13(c)则是t+2 时刻机器人左右各旋转一圈后的位姿状态,机器人在地图上重定位到白圆位置N 周围,也就是其实际位姿。而图14是本文RLSLALI算法的重定位效果,其中的图14(a)表示的是t时刻将机器人从当前位置O 强行搬离到一个新的位置N,图14(b)则代表在t+1 时刻时,机器人已经在地图上重定位到白圆N(实际位置)的附近。

图13 环境多特征情况下AMCL算法的重定位效果

图14 环境多特征情况下RLSLALI算法的重定位效果
进行多组实验,结果表明,对比本文RLSLALI 算法,传统的AMCL定位算法不仅耗时较长,要求较高(需要机器人的其他观测行为),成功率也不理想,在本文实验测试中仅为72%,而这还是在搬离到特征较为明显的位置时所产生的结果,如果是将机器人搬离到一个环境特征低的位置(比如墙角,周围墙壁环境类似等),传统的AMCL定位算法就会几乎无法完成重定位,而本文算法依然可以利用地标物体实时修正位姿,不受其影响,实验测试效果见图15 及图16,AMCL 算法无法将机器人从黑圆位置O更新到白圆位置N,而使用本文RLSLALI算法却能有效重定位。
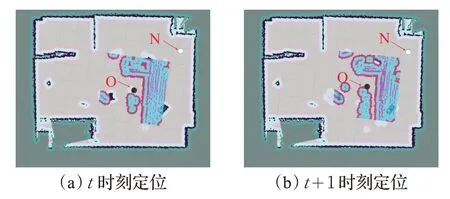
图15 环境低特征情况下AMCL算法的重定位效果

图16 环境低特征情况下RLSLALI算法的重定位效果
不仅如此,还要将本文RLSLALI算法与视觉SLAM算法[8]的重定位效果进行对比,见图17及图18。

图17 ORB-SLAM算法的重定位效果
其中图17表示视觉SLAM算法的重定位效果,图17(a)代表SLAM过程中算法正在获取当前环境地图特征点,图17(b)是将机器人从蓝边倒三角位置O搬离到了绿边倒三角N 的位置,而图17(c)则是下一个时刻机器人在地图上的进行位置更新,重新定位到绿边倒三角N位置的附近,并形成一定的位姿轨迹,准确性较高。图18则与之前的几组实验相似,表示的是本文RLSLALI 算法将机器人在地图上黑圆O 的位置顺利更新到绿边白圆N位置(实际位置)的周围。

图18 RLSLALI算法的重定位效果
3.4 物体检测模型的识别效果
由于本文算法中所用的地标全局坐标是通过视觉识别地标,查找匹配关联映射表来获取的,所以为了适配本文重定位算法对实时性和准确率的需求,提出了Acc-YOLOv3 算法。为了验证本文Acc-YOLOv3 识别算法的可行性,分别在亮光条件(300以上lux)和暗光条件(200 以下lux)对应的远近距离(1.5 m 与3.5 m)进行实验验证,识别效果见图19与图20。

图19 近距离物体检测效果图

图20 远距离物体检测效果图
图19 中的(a)是模拟暗光条件下(200 lux 以下)近距离对地标物体(模拟指示牌)的识别结果;(b)是模拟亮光条件下(300 lux以上)近距离对地标物体(模拟指示牌)的识别结果。将其框住并赋予语义标签。
图20 中的(a)是模拟暗光条件下(200 lux 以下)远距离对地标物体(模拟指示牌)的识别结果;(b)是模拟亮光条件下(300 lux以上)远距离对地标物体(模拟指示牌)的识别结果。将其框住并赋予语义标签。
通过与其他识别算法在当前实验场景中实验效果对比,可以得到表3的实验数据,性能对比见图21。

表3 各类物体检测算法实验结果对比表

图21 各识别算法的性能对比
对比实验结果可知,虽然本文Acc-YOLOv3算法不能在检测速度和准确率上同时做到最佳,但却可以在只多消耗一点时间的情况下大幅度提升检测的准确率,从而适配本文RLSLALI算法的运行需求。
4 结论和展望
本文提出的重定位算法是在当前主流SLAM 算法的基础上,对它们的定位效果加以优化和改进。本文RLSLALI 算法利用视觉传感器模拟人的眼睛,用来识别机器人周围物体及地标;利用激光和IMU 来获取位置、距离、角度等准确度要求较高的信息。巧妙地结合激光测距的准确性与视觉信息的丰富性,用来构建本文创新的地标数据库与位姿推导模型。使机器人能够根据环境中的地标信息,自主地完成重定位。从实验结果对比来看,本文算法取得了较好的重定位效果,算法修正每一次的错误定位之后,总的定位偏差均值约为10.2 cm,方差约为10.1 cm,可见本文提出的基于语义激光与地标信息的机器人重定位算法具有先进性、有效性以及健壮性。
本文算法不仅是对目前SLAM 技术中定位方法的改进与补充,也是对某些人为设置地标优化定位精度算法的加强与优化。一般情况下,通过本文算法搭建的地标数据库系统,能够让机器人在运行环境中自主筛选和设置有效地标,无需为设置地标做大量的前期繁杂工作,减少了人为干预步骤。当然,本文算法也存在待改进的地方,就是过于依赖自然地标,如果环境中符合地标条件的物体太少甚至没有的话,就必须通过增加数据集对模型继续训练调优和设置人为地标来实现算法,这也是本文作者以后继续研究的一大重点。
致谢 感谢本实验室曹军的前期研究工作,给本文RLSLALI算法研究提供了前期数据支持,在他的研究基础上,本文顺利地将地标概念引入后端重定位算法中。
猜你喜欢
光学精密工程(2022年22期)2022-11-28
浙江海洋大学学报(自然科学版)(2020年5期)2020-06-19
开放教育研究(2020年2期)2020-03-31
中学生数理化·高一版(2020年1期)2020-02-20
电子技术与软件工程(2019年6期)2019-04-26
中学生数理化·八年级物理人教版(2018年10期)2018-12-06
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
长江学术(2016年4期)2016-03-11
科普童话·百科探秘(2015年4期)2015-05-14
